Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Servicios globales
Además de los AWS servicios regionales y zonales, hay un pequeño conjunto de AWS servicios cuyos planos de control y de datos no existen de forma independiente en cada región. Como sus recursos no son específicos de una región, suelen denominarse globales. AWS Los servicios globales siguen el patrón de AWS diseño convencional de separar el plano de control y el plano de datos para lograr la estabilidad estática. La diferencia significativa para la mayoría de los servicios globales es que su plano de control está alojado en un único plano Región de AWS, mientras que su plano de datos está distribuido globalmente. Existen tres tipos diferentes de servicios globales y un conjunto de servicios que pueden parecer globales en función de la configuración seleccionada.
En las siguientes secciones se identificará cada tipo de servicio global y la forma en que se separan sus planos de control y de datos. Puede usar esta información como guía para crear mecanismos confiables de alta disponibilidad (HA) y recuperación ante desastres (DR) sin necesidad de depender de un plano de control de servicios global. Este enfoque ayuda a eliminar los puntos únicos de fallo de su arquitectura y evita posibles impactos entre regiones, incluso cuando opera en una región diferente de la que está alojado el plano de control de servicios global. También le ayuda a implementar de forma segura mecanismos de conmutación por error que no dependen de planos de control de servicios globales.
Servicios globales que son únicos por partición
Existen algunos AWS servicios globales en cada partición (denominados en este paper servicios particionales). Los servicios particionales proporcionan su plano de control en un solo plano. Región de AWS Algunos servicios particionales, como AWS Network Manager, son únicamente del plano de control y organizan el plano de datos de otros servicios. Otros servicios particionales, por ejemploIAM, tienen su propio plano de datos que está aislado y distribuido en toda la partición. Regiones de AWS Los errores en un servicio particional no afectan a las demás particiones. En la aws partición, el plano de control del IAM servicio está en la us-east-1 región, con planos de datos aislados en cada región de la partición. Los servicios particionales también tienen planos de control y de datos independientes en las aws-cn particiones aws-us-gov y. La separación entre el plano de control y el plano de datos IAM se muestra en el siguiente diagrama.
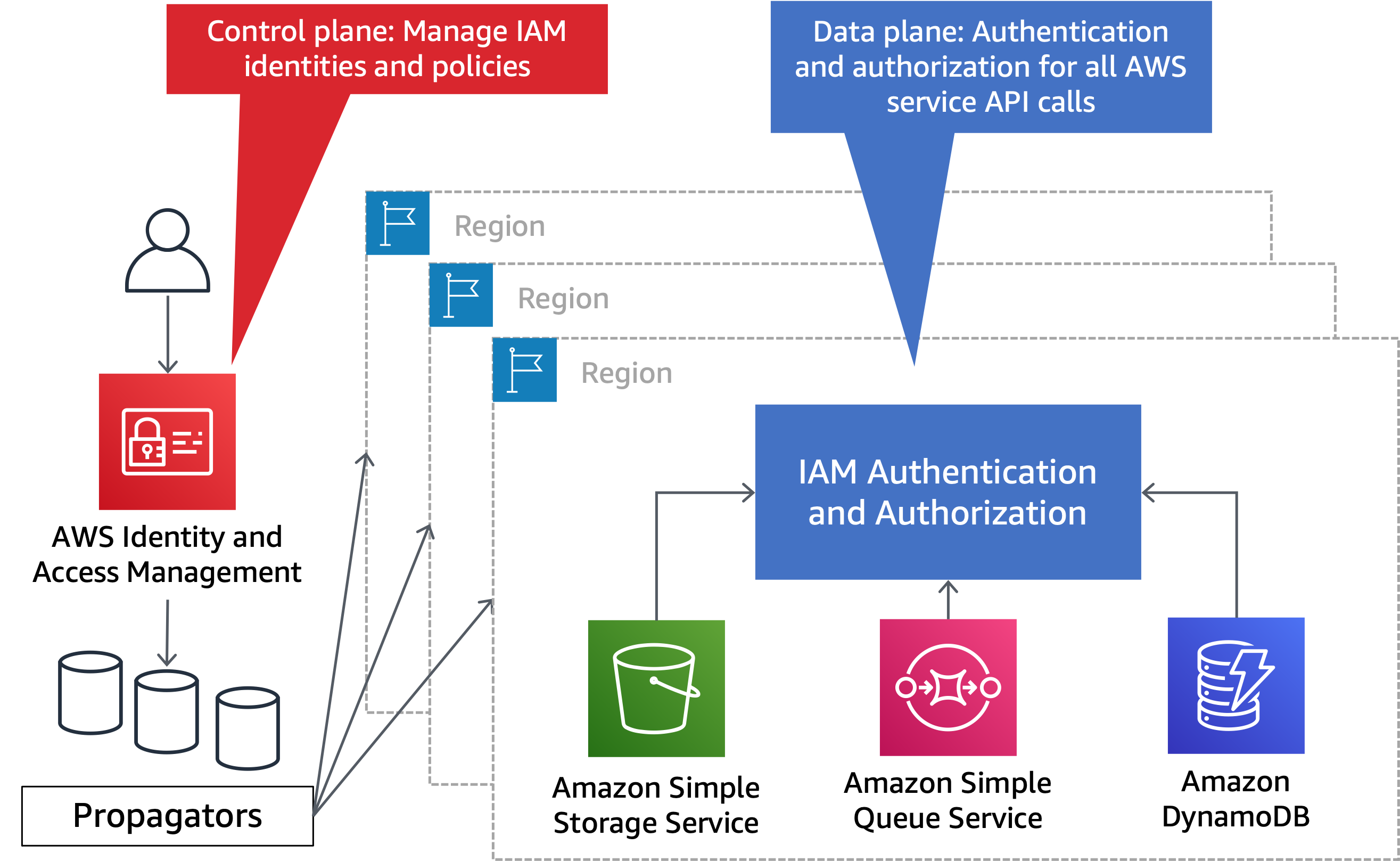
IAMtiene un plano de control único y un plano de datos regionalizado
A continuación se muestran los servicios particionales y su ubicación en el plano de control en la aws partición:
-
AWS IAM (
us-east-1) -
AWS Organizations (
us-east-1) -
AWS Administración de cuentas ()
us-east-1 -
Controlador de recuperación de aplicaciones Route 53 (ARC
us-west-2) (): este servicio solo está presente en laawspartición -
AWS Administrador de red (
us-west-2) -
Ruta 53 Privada DNS (
us-east-1)
Si alguno de estos aviones de control de servicio sufre un incidente que afecte a la disponibilidad, es posible que no pueda utilizar las operaciones de CRUDL tipo que ofrecen estos servicios. Por lo tanto, si su estrategia de recuperación depende de estas operaciones, si la disponibilidad se ve afectada en el plano de control o en la región en la que se encuentra el plano de control, se reducirán sus probabilidades de lograr una recuperación satisfactoria. Apéndice A: Guía de servicios particionalesproporciona estrategias para eliminar las dependencias de los planes de control de servicios globales durante la recuperación.
Recomendación
No confíe en los planos de control de los servicios particionales en su ruta de recuperación. En su lugar, confíe en las operaciones del plano de datos de estos servicios. Consulte Apéndice A: Guía de servicios particionales para obtener detalles adicionales sobre cómo debe diseñar los servicios particionales.
Servicios globales en la red perimetral
El siguiente conjunto de AWS servicios globales tiene un plano de control en la aws partición y aloja sus planos de datos en la infraestructura de puntos de presencia (PoP) globales (y posiblemente Regiones de AWS también). Se PoPs puede acceder a los planos de datos alojados desde los recursos de cualquier partición, así como desde Internet. Por ejemplo, Route 53 opera su plano de control en la us-east-1 región, pero su plano de datos está distribuido en cientos de países de todo el PoPs mundo, así como DNS en cada uno de ellos Región de AWS (para dar soporte a las rutas públicas y privadas de la región). Las comprobaciones de estado de Route 53 también forman parte del plano de datos y se realizan desde ocho Regiones de AWS puntos de la aws partición. Los clientes pueden resolverlo DNS utilizando las zonas alojadas públicas de Route 53 desde cualquier lugar de Internet GovCloud, incluidas otras particiones, así como desde una nube privada AWS
virtual (VPC). A continuación se muestran los servicios de red perimetral global y su ubicación en el plano de control en la aws partición:
-
Ruta 53 pública DNS (
us-east-1) -
Amazon CloudFront (
us-east-1) -
AWS WAF Clásico para CloudFront (
us-east-1) -
AWS WAF para CloudFront (
us-east-1) -
Amazon Certificate Manager (ACM) para CloudFront (
us-east-1) -
AWSAcelerador global (AGA) (
us-west-2) -
AWS Shield Advanced (
us-east-1)
Si utilizas comprobaciones de AGA estado para EC2 las instancias o direcciones IP elásticas, estas utilizan las comprobaciones de estado de Route 53. La creación o actualización de las comprobaciones de AGA estado dependería del plano de control de Route 53 en el que se encuentreus-east-1. La ejecución de las comprobaciones de AGA estado utiliza el plano de datos de las comprobaciones de estado de Route 53.
Si se produce un fallo que afecte a la región en la que se encuentran los aviones de control de estos servicios, o si se produce un fallo que afecte al propio plano de control, es posible que no pueda utilizar las operaciones del CRUDL tipo que ofrecen estos servicios. Si ha utilizado estas operaciones en su estrategia de recuperación, es menos probable que esa estrategia tenga éxito que si se basa únicamente en el plano de datos de estos servicios.
Recomendación
No confíe en el plano de control de los servicios de red perimetrales de su ruta de recuperación. En su lugar, confíe en las operaciones del plano de datos de estos servicios. Consulte Apéndice B: Guía de servicio global de redes periféricas para obtener detalles adicionales sobre cómo diseñar servicios globales en la red perimetral.
Operaciones globales de una sola región
La última categoría se compone de operaciones específicas del plano de control dentro de un servicio que tienen un alcance de impacto global, y no de servicios completos como en las categorías anteriores. Al interactuar con los servicios zonales y regionales de la región que especifique, algunas operaciones tienen una dependencia subyacente de una sola región que es diferente de donde se encuentra el recurso. Son diferentes de los servicios que solo se proporcionan en una sola región; consulte Apéndice C: Servicios de una sola región para obtener una lista de esos servicios.
Si se produce un error que afecte a la dependencia global subyacente, es posible que no pueda utilizar las acciones de CRUDL tipo «-» propias de las operaciones dependientes. Si ha utilizado estas operaciones en su estrategia de recuperación, es menos probable que esa estrategia tenga éxito que si se basa únicamente en el plano de datos de estos servicios. Debe evitar depender de estas operaciones en su estrategia de recuperación.
La siguiente es una lista de los servicios de los que pueden depender otros servicios, que tienen un alcance global:
-
Ruta 53
Varios AWS servicios crean recursos que proporcionan un DNS nombre o nombres específicos para cada recurso. Por ejemplo, cuando aprovisiona un Elastic Load Balancer (ELB), el servicio crea DNS registros públicos y comprobaciones de estado en Route 53 para el. ELB Esto se basa en el plano de control de Route 53 en
us-east-1. Es posible que otros servicios que utilice también necesiten aprovisionarELB, crear DNS registros públicos de Route 53 o crear comprobaciones de estado de Route 53 como parte de sus flujos de trabajo en el plano de control. Por ejemplo, el aprovisionamiento de un REST API recurso de Amazon API Gateway, una base de datos del Amazon Relational Database Service (RDSAmazon) o un dominio de OpenSearch Amazon Service implica la DNS creación de registros en Route 53. La siguiente es una lista de servicios cuyo plano de control depende del plano de control de Route 53us-east-1para crear, actualizar o eliminar DNS registros, zonas alojadas o crear controles de estado de Route 53. Esta lista no es exhaustiva; su objetivo es destacar algunos de los servicios más utilizados cuyas acciones del plano de control para crear, actualizar o eliminar recursos dependen del plano de control de Route 53:-
Amazon API Gateway REST y HTTP APIs
-
RDSInstancias de Amazon
-
Bases de datos de Amazon Aurora
-
Equilibradores ELB de carga de Amazon
-
AWS PrivateLink VPCpuntos finales
-
AWS Lambda URLs
-
Amazon ElastiCache
-
OpenSearch Servicio Amazon
-
Amazon CloudFront
-
Amazon MemoryDB
-
Amazon Neptune
-
Amazon DynamoDB Accelerator () DAX
-
AGA
-
Amazon Elastic Container Service (AmazonECS) con Service Discovery DNS basado (que lo utiliza AWS Cloud Map API para administrar Route 53DNS)
-
Plano de control de Amazon EKS Kubernetes
Es importante tener en cuenta que el VPC DNS servicio, por EC2ejemplo, los nombres de host, existen de forma independiente en cada uno de ellos Región de AWS y no dependen del plano de control de Route 53. Registros que se AWS crean para las EC2 instancias del VPC DNS servicio, como
ip-10-0-10.ec2.internalip-10-0-1-5.compute.us-west-2.compute.internal, yi-0123456789abcdef.ec2.internali-0123456789abcdef.us-west-2.compute.internal, no se basan en el plano de control de Route 53.us-east-1Recomendación
No confíe en la creación, actualización o eliminación de recursos que requieran la creación, actualización o eliminación de registros de recursos, zonas alojadas o comprobaciones de estado de Route 53 en su ruta de recuperación. Aprovisione previamente estos recursos, por ejemploELBs, para evitar que su ruta de recuperación dependa del plano de control de Route 53.
-
-
Amazon S3
Las siguientes operaciones del plano de control de Amazon S3 tienen una dependencia subyacente
us-east-1en laawspartición. Un fallo que afecte a Amazon S3 o a otros serviciosus-east-1podría provocar que las acciones de estos planos de control se vean afectadas en otras regiones:PutBucketCorsDeleteBucketCorsPutAccelerateConfigurationPutBucketRequestPaymentPutBucketObjectLockConfigurationPutBucketTaggingDeleteBucketTaggingPutBucketReplicationDeleteBucketReplicationPutBucketEncryptionDeleteBucketEncryptionPutBucketLifecycleDeleteBucketLifecyclePutBucketNotificationPutBucketLoggingDeleteBucketLoggingPutBucketVersioningPutBucketPolicyDeleteBucketPolicyPutBucketOwnershipControlsDeleteBucketOwnershipControlsPutBucketAclPutBucketPublicAccessBlockDeleteBucketPublicAccessBlockEl plano de control de los puntos de acceso multirregionales (MRAP) de Amazon S3 está alojado únicamente en esa región
us-west-2y las solicitudes para crear, actualizar o eliminar se MRAPs dirigen directamente a esa región. El plano de control MRAP también tiene dependencias subyacentes con respecto a AGA laus-west-2entrada, Route 53 y cada ACM región desde la que MRAP está configurado para ofrecer contenido.us-east-1No debe depender de la disponibilidad del plano de MRAP control en su ruta de recuperación ni en los planos de datos de sus propios sistemas. Esto es distinto de los controles de MRAP conmutación por error, que se utilizan para especificar el estado de enrutamiento activo o pasivo de cada uno de los depósitos del. MRAP APIsSe alojan en cinco unidades Regiones de AWS y se pueden utilizar para desplazar el tráfico de forma eficaz mediante el plano de datos del servicio.Además, los nombres de los buckets de Amazon S3 son únicos a nivel mundial
CreateBuckety todas las llamadas a laawspartición yDeleteBucketAPIs dependenus-east-1de ellas para garantizar la exclusividad del nombre, aunque la API llamada se dirija a la región específica en la que desee crear el bucket. Por último, si tiene flujos de trabajo críticos para la creación de cubos, no debe depender de la disponibilidad de una ortografía específica para el nombre de un bucket, especialmente de aquellos que siguen un patrón discernible.Recomendación
No confíe en eliminar o crear nuevos buckets de S3 ni en actualizar las configuraciones de los buckets de S3 como parte de su proceso de recuperación. Aprovisione previamente todos los depósitos de S3 necesarios con las configuraciones necesarias para no tener que realizar cambios para recuperarse de un error. Este enfoque también se aplica aMRAPs.
-
CloudFront
Amazon API Gateway proporciona puntos de enlace optimizados desde el punto de vista periférico API. La creación de estos puntos de enlace depende del plano de CloudFront control utilizado
us-east-1para crear la distribución frente al punto de enlace de la puerta de enlace.Recomendación
No confíe en la creación de nuevos puntos finales API Gateway optimizados desde el punto de vista periférico como parte de su proceso de recuperación. Aprovisione previamente todos los puntos finales de Gateway necesarios. API
Todas las dependencias analizadas en esta sección son acciones del plano de control, no acciones del plano de datos. Si sus cargas de trabajo están configuradas para ser estáticamente estables, estas dependencias no deberían afectar a su ruta de recuperación, teniendo en cuenta que la estabilidad estática requiere trabajo o servicios adicionales para implementarlas.
Servicios que utilizan puntos finales globales predeterminados
En algunos casos, los AWS servicios proporcionan un punto final global predeterminado, como AWS Security Token Service (AWS STS). Otros servicios pueden usar este punto final global predeterminado en su configuración predeterminada. Esto significa que un servicio regional que esté utilizando podría tener una dependencia global de un solo servicio Región de AWS. En los siguientes detalles se explica cómo eliminar las dependencias no deseadas en los puntos finales globales predeterminados, lo que le ayudará a utilizar el servicio de forma regional.
AWS STS: STS es un servicio web que le permite solicitar credenciales temporales con privilegios limitados para IAM los usuarios o para los usuarios que autentique (usuarios federados). STSel uso del kit de desarrollo de AWS software (SDK) y la interfaz de línea de comandos () se establece de forma predeterminada en. CLI us-east-1 El STS servicio también proporciona puntos finales regionales. Estos puntos finales están habilitados de forma predeterminada en las regiones que también están habilitadas de forma predeterminada. Puede aprovecharlos en cualquier momento configurando sus puntos de conexión regionalizados SDK o CLI siguiendo estas instrucciones: Puntos de enlace AWS STSregionalizados. El uso de SiGV4a también requiere credenciales temporales solicitadas a un punto final regional. STS No puede utilizar el STS punto final global para esta operación.
Recomendación
Actualice su CLI configuración SDK y utilice los STS puntos finales regionales.
Inicio de sesión en Security Assertion Markup Language (SAML): todos SAML los servicios están disponibles. Regiones de AWS Para usar este servicio, elija el SAML punto de enlace regional apropiado, como https://us-west-2.signin.aws.amazon.com/saml
Si utiliza un IdP que también está alojado en AWS, existe el riesgo de que también se vea afectado durante un evento de AWS error. Esto podría provocar que no pueda actualizar la configuración de su IdP o que no pueda federarse por completo. Debe aprovisionar previamente a los usuarios «break-glass» en caso de que su IdP esté averiado o no esté disponible. Consulte Apéndice A: Guía de servicios particionales para obtener más información sobre cómo crear usuarios de break-glass de una forma estable desde el punto de vista estático.
Recomendación
Actualice sus políticas de confianza de IAM roles para aceptar SAML inicios de sesión desde varias regiones. En caso de error, actualice la configuración de su IdP para usar un SAML punto final regional diferente si su punto final preferido está dañado. Cree un usuario rompe-cristal en caso de que su IdP esté averiado o no esté disponible.
AWS IAMIdentity Center: Identity Center es un servicio basado en la nube que facilita la administración centralizada del acceso mediante inicio de sesión único a las aplicaciones de un cliente y en la nube. Cuentas de AWS Identity Center debe implementarse en la única región que elija. Sin embargo, el comportamiento predeterminado del servicio es utilizar el SAML punto final global (https://signin.aws.amazon.com/samlus-east-1. Si ha implementado Identity Center en otro Región de AWS, debe actualizar el estado de retransmisión de cada conjunto URL de permisos para que se dirija al mismo punto final de la consola regional que utilizó en su implementación de Identity Center. Por ejemplo, si implementó Identity Center enus-west-2, debe actualizar el estado de retransmisión de sus conjuntos de permisos para usar https://us-west-2.console.aws.amazon.com.us-east-1 de Identity Center.
Además, dado que IAM Identity Center solo se puede implementar en una sola región, debe aprovisionar previamente a los usuarios más avanzados en caso de que su despliegue se vea afectado. Consulte Apéndice A: Guía de servicios particionales para obtener más información sobre cómo crear usuarios rompe-glass de una forma estable desde el punto de vista estático.
Recomendación
Establezca el estado URL de retransmisión de sus conjuntos de permisos en IAM Identity Center para que coincida con la región en la que está desplegado el servicio. Cree un usuario innovador en caso de que la implementación de su Centro de IAM Identidad no esté disponible.
Amazon S3 Storage Lens: Storage Lens proporciona un panel predeterminado llamado default-account-dashboard. La configuración del panel y sus métricas asociadas se almacenan enus-east-1. Puede crear paneles adicionales en otras regiones especificando la región de origen para la configuración del panel y los datos de las métricas.
Recomendación
Si necesita datos del panel de control predeterminado de S3 Storage Lens durante un fallo que afecte al servicious-east-1, cree un panel adicional en una región de origen alternativa. También puede duplicar cualquier otro panel personalizado que haya creado en otras regiones.
Resumen de los servicios globales
Los planos de datos para los servicios globales aplican principios de aislamiento e independencia similares a los de los AWS servicios regionales. Una falla que afecte al plano de datos IAM de una región no afectará al funcionamiento del plano de IAM datos en otra Región de AWS. Del mismo modo, una falla que afecte al plano de datos de la Ruta 53 en un PoP no afectará al funcionamiento del plano de datos de la Ruta 53 en el resto de la región. PoPs Por lo tanto, lo que debemos tener en cuenta son los eventos de disponibilidad del servicio que afecten a la región en la que opera el plano de control o que afecten al propio plano de control. Como solo hay un plano de control para cada servicio global, una falla que afecte a ese plano de control podría tener efectos interregionales en las operaciones de CRUDL tipo regional (que son las operaciones de configuración que se utilizan normalmente para establecer o configurar un servicio, en lugar del uso directo del servicio).
La forma más eficaz de diseñar las cargas de trabajo para utilizar los servicios globales de forma resiliente es utilizar la estabilidad estática. En caso de fallo, diseñe su carga de trabajo de forma que no sea necesario realizar cambios con un plano de control para mitigar el impacto o la conmutación por error a una ubicación diferente. Consulte Apéndice A: Guía de servicios particionales y obtenga una guía prescriptiva sobre cómo utilizar este tipo de servicios globales Apéndice B: Guía de servicio global de redes periféricas para eliminar las dependencias del plano de control y eliminar los puntos únicos de fallo. Si necesita los datos de una operación del plano de control para la recuperación, almacene en caché estos datos en un almacén de datos al que se pueda acceder a través de su plano de datos, como un parámetro del Almacén de parámetros de AWS Systems ManagerDescribeCluster API operación.
El siguiente es un resumen de algunos de los errores de configuración o antipatrones más comunes que introducen dependencias en los planos de control de los servicios globales:
-
Realizar cambios en los registros de Route 53, como actualizar el valor de un registro A o cambiar las ponderaciones de un conjunto de registros ponderado, para realizar una conmutación por error.
-
Crear o actualizar IAM recursos, incluidas las IAM funciones y las políticas, durante una conmutación por error. Por lo general, esto no es intencional, pero puede ser el resultado de un plan de conmutación por error no probado.
-
Confiar en IAM Identity Center para que los operadores accedan a los entornos de producción en caso de fallo.
-
Confíe en la configuración predeterminada de IAM Identity Center para utilizar la consola
us-east-1cuando haya implementado Identity Center en una región diferente. -
Si se realizan cambios en las ponderaciones AGA del tráfico, se realiza una conmutación por error regional de forma manual.
-
Actualizar la configuración de origen de una CloudFront distribución para evitar errores en un origen defectuoso.
-
Aprovisionamiento de recursos de recuperación ante desastres (DR), como ELBs RDS instancias durante una falla, que dependen de la creación de DNS registros en Route 53.
A continuación, se presenta un resumen de las recomendaciones que se proporcionan en esta sección para utilizar los servicios globales de forma resiliente y ayudar a prevenir los antipatrones habituales que solían producirse anteriormente.
Resumen de las recomendaciones
No confíe en los planos de control de los servicios particionales en su proceso de recuperación. En su lugar, confíe en las operaciones del plano de datos de estos servicios. Consulte Apéndice A: Guía de servicios particionales para obtener detalles adicionales sobre cómo debe diseñar los servicios particionales.
No confíe en el plano de control de los servicios de red perimetrales en su ruta de recuperación. En su lugar, confíe en las operaciones del plano de datos de estos servicios. Consulte Apéndice B: Guía de servicio global de redes periféricas para obtener detalles adicionales sobre cómo diseñar servicios globales en la red perimetral.
No confíe en la creación, actualización o eliminación de recursos que requieran la creación, actualización o eliminación de registros de recursos, zonas alojadas o comprobaciones de estado de Route 53 en su ruta de recuperación. Aprovisione previamente estos recursos, por ejemploELBs, para evitar que su ruta de recuperación dependa del plano de control de Route 53.
No confíe en eliminar o crear nuevos buckets de S3 ni en actualizar las configuraciones de los buckets de S3 como parte de su ruta de recuperación. Aprovisione previamente todos los depósitos de S3 necesarios con las configuraciones necesarias para no tener que realizar cambios para recuperarse de un error. Este enfoque también se aplica aMRAPs.
No confíe en la creación de nuevos terminales API Gateway optimizados desde el punto de vista periférico como parte de su proceso de recuperación. Aprovisione previamente todos los puntos finales de Gateway necesarios. API
Actualice su CLI configuración SDK y para usar los puntos de conexión regionalesSTS.
Actualice sus políticas de confianza de IAM roles para aceptar SAML inicios de sesión desde varias regiones. En caso de error, actualice la configuración de su IdP para usar un SAML punto final regional diferente si su punto final preferido está dañado. Cree usuarios rompe-cristal en caso de que su IdP esté dañado o no esté disponible.
Configure el estado URL de retransmisión de sus conjuntos de permisos en IAM Identity Center para que coincida con la región en la que está desplegado el servicio. Cree un usuario innovador en caso de que la implementación de su Centro de Identidad no esté disponible.
Si necesita datos del panel de control predeterminado de S3 Storage Lens durante una falla que afecte al servicious-east-1, cree un panel adicional en una región de origen alternativa. También puede duplicar cualquier otro panel personalizado que haya creado en otras regiones.
