Escenario 4: detección de anomalías y notificaciones en tiempo real de sensores de dispositivo
La empresa ABC4Logistics transporta productos petrolíferos muy inflamables como gasolina, propano líquido (GLP) y nafta desde el puerto a varias ciudades. Hay centenares de vehículos que tienen varios sensores instalados para supervisar aspectos como la ubicación, la temperatura del motor, la temperatura en el contenedor, la velocidad de conducción, la ubicación en el estacionamiento, las condiciones de la carretera, etc. Uno de los requisitos que tiene ABC4Logistics es supervisar las temperaturas del motor y del contenedor en tiempo real y avisar al conductor y al equipo de supervisión de la flota en caso de cualquier anomalía. Para detectar dichas condiciones y generar alertas en tiempo real, ABC4Logistics implementó la siguiente arquitectura en AWS.
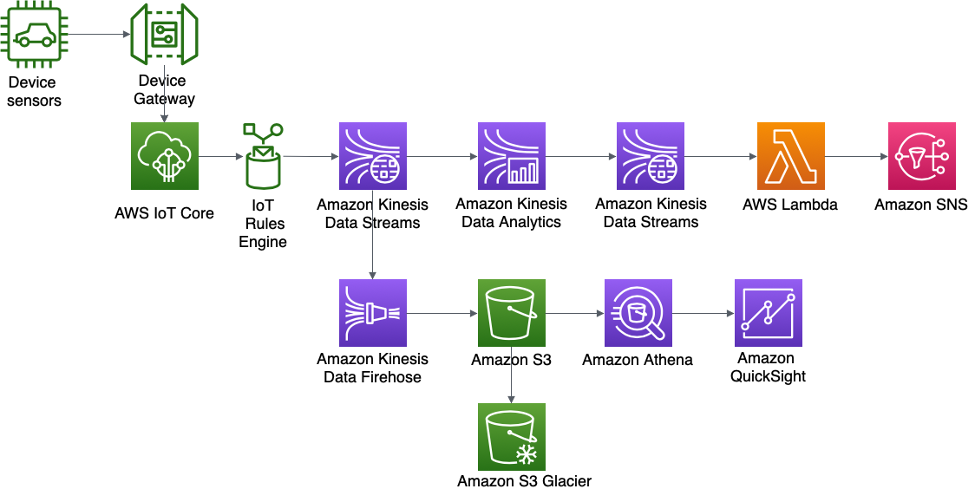
Arquitectura de notificaciones y detección de anomalías en tiempo real de sensores de dispositivo de ABC4Logistics
AWS IoT Gateway incorpora los datos de los sensores de dispositivo, donde el motor dereglas de AWS IoT hará que los datos de streaming estén disponibles en Amazon Kinesis Data Streams. Con Kinesis Data Analytics, ABC4Logistics puede realizar los análisis en tiempo real de los datos de streaming en Kinesis Data Streams.
Con Kinesis Data Analytics, ABC4Logistics puede detectar si las lecturas de temperatura de los sensores se desvían de las lecturas normales durante un período de diez segundos e incorporar el registro en otra instancia de Kinesis Data Streams, por lo que se pueden identificar los registros anómalos. Después, Amazon Kinesis Data Streams invoca las funciones Lambda, que pueden enviar las alertas al conductor y al equipo de supervisión de flotas a través de Amazon SNS.
Los datos de Kinesis Data Streams también se envían a Amazon Kinesis Data Firehose. Amazon Kinesis Data Firehose conserva estos datos en Amazon S3, lo que permite a ABC4Logistics realizar análisis por lotes o casi en tiempo real de los datos de sensor. ABC4Logistics utiliza Amazon Athena
A continuación, se detallan los componentes importantes de esta arquitectura.
Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics
Con Amazon Kinesis Data Analytics, puede consultar datos de streaming de forma interactiva con múltiples opciones, como SQL estándar, aplicaciones de Apache Flink en Java, Python y Scala, y crear aplicaciones de Apache Beam mediante Java para analizar las secuencias de datos.
Estas opciones le proporcionan la flexibilidad de usar un enfoque específico según el nivel de complejidad de la aplicación de streaming y la compatibilidad de origen/destino. En la siguiente sección se describe la opción Kinesis Data Analytics para aplicaciones de Flink.
Amazon Kinesis Data Analytics para aplicaciones de Apache Flink
Apache Flink
Con Amazon Kinesis Data Analytics for Apache Flink, puede crear y ejecutar código en orígenes de transmisión para realizar análisis de series temporales, alimentar paneles en tiempo real y crear métricas en tiempo real sin administrar el complejo entorno distribuido de Apache Flink. Puede usar las funciones de programación de Flink de alto nivel de la misma manera que las usa cuando aloja la infraestructura de Flink por su cuenta.
Kinesis Data Analytics for Apache Flink le permite crear aplicaciones en Java, Scala, Python o SQL para procesar y analizar datos de streaming. Una aplicación Flink típica lee los datos del flujo de entrada o la ubicación o el origen de datos, transforma/filtra o une los datos mediante operadores o funciones, y almacena los datos en la secuencia de salida o la ubicación de los datos, o receptor.
El siguiente diagrama de arquitectura muestra algunas de los orígenes y los receptores compatibles para la aplicación Flink de Kinesis Data Analytics. Además de los conectores preintegrados para origen/receptor, también puede incorporar conectores personalizados a diferentes orígenes/receptores para las aplicaciones Flink en Kinesis Data Analytics.
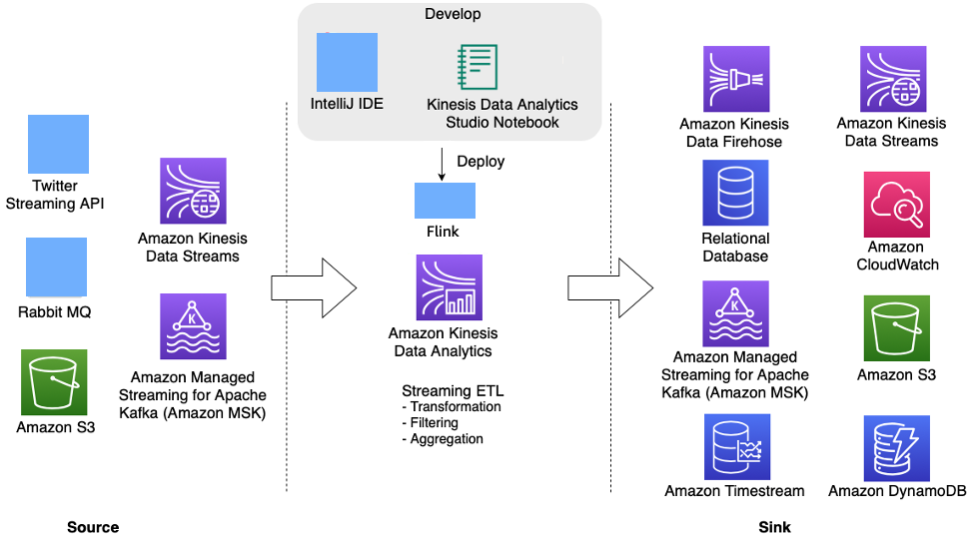
Aplicación Apache Flink en Kinesis Data Analytics para el procesamiento de secuencias en tiempo real
Los desarrolladores pueden usar su IDE preferido para desarrollar aplicaciones Flink e implementarlas en Kinesis Data Analytics desde AWS Management Console
Amazon Kinesis Data Analytics Studio
Como parte del servicio Kinesis Data Analytics, ya está disponible Kinesis Data Analytics Studio
Con el cuaderno de Studio, tiene la capacidad de desarrollar el código de la aplicación Flink en un entorno de cuadernos, ver los resultados de su código en tiempo real y visualizarlo en su cuaderno. Puede crear un cuaderno de Studio con tecnología de Apache Zeppelin y Apache Flink con un solo clic desde la consola de Kinesis Data Streams y Amazon MSK, o lanzarlo desde la consola de Kinesis Data Analytics.
Una vez que desarrolle el código de forma iterativa como parte de Kinesis Data Analytics Studio, puede implementar un cuaderno como una aplicación de análisis de datos de Kinesis para que se ejecute en modo streaming de forma continua, lea los datos de sus fuentes, escriba en sus destinos, mantenga el estado de la aplicación de larga ejecución y escale automáticamente en función del rendimiento de las secuencias de origen. Anteriormente, los clientes utilizaban Kinesis Data Analytics for SQL Applications para realizar análisis interactivos de los datos de streaming en tiempo real en AWS.
Kinesis Data Analytics para aplicaciones SQL aún está disponible, pero para proyectos nuevos, AWS recomienda utilizar el nuevo Kinesis Data Analytics Studio
Para hacer que la aplicación de Kinesis Data Analytics Flink sea tolerante a errores, puede utilizar puntos de control e instantáneas, como se describe en Implementación de tolerancia a errores en Kinesis Data Analytics para Apache Flink.
Las aplicaciones Flink de Kinesis Data Analytics son útiles para escribir aplicaciones de análisis de streaming complejas, como aplicaciones con exactamente una sola semántica
Después de procesar los datos de streaming en la aplicación Flink, puede conservar los datos en varios receptores o destinos, como Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, Amazon DynamoDB, Amazon OpenSearch Service, Amazon Timestream, Amazon S3, etc. La aplicación Flink de Kinesis Data Analytics también ofrece garantías de rendimiento en menos de un segundo.
Aplicaciones Apache Beam para Kinesis Data Analytics
Apache Beam
Puede utilizar el marco de Apache Beam con su aplicación de análisis de datos de Kinesis para procesar los datos de streaming. Las aplicaciones de Kinesis Data Analytics que usan Apache Beam utilizan el sistema de ejecución de Apache Flink
Resumen
Al utilizar los servicios de streaming de AWS Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics y Amazon Kinesis Data Firehose,
ABC4Logistics puede detectar patrones anómalos en las lecturas de temperatura y notificar al conductor y al equipo de administración de la flota en tiempo real, lo que evita accidentes graves como averías completas del vehículo o incendios.
