Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résoudre les problèmes liés aux pilotes PV sur les instances Windows
Vous trouverez ci-dessous des solutions aux problèmes que vous pourriez rencontrer avec les anciennes EC2 images Amazon et les anciens pilotes PV.
Table des matières
Windows Server 2012 R2 perd la connectivité au réseau ou à l’unité de stockage après le redémarrage d’une instance
Important
Ce problème se produit uniquement AMIs s'il est disponible avant septembre 2014.
Windows Server 2012 R2 Amazon Machine Images (AMIs) mises à disposition avant le 10 septembre 2014 peuvent perdre la connectivité réseau et de stockage après le redémarrage d'une instance. L'erreur dans le journal du AWS Management Console système indique : « Difficulté à détecter les détails du pilote PV pour la sortie de console ». La perte de connectivité est causée par la fonction de nettoyage Plug and Play. Cette fonction recherche et désactive les périphériques système inactifs tous les 30 jours. La fonctionnalité identifie incorrectement le périphérique EC2 réseau comme étant inactif et le supprime du système. Le cas échéant, l’instance perd la connectivité au réseau après un redémarrage.
Pour les systèmes que vous soupçonnez d’être vulnérables à ce problème, vous pouvez télécharger et exécuter une mise à niveau de pilote sur place. Si vous ne parvenez pas à effectuer la mise à jour du pilote sur place, vous pouvez exécuter un script d’assistant. Ce script détermine si le problème affecte votre instance. S'il est concerné et que le périphérique EC2 réseau Amazon n'a pas été retiré, le script désactive le scan Plug and Play Cleanup. Si le périphérique réseau a été supprimé, le script le répare, désactive l’analyse de la fonctionnalité de nettoyage Plug and Play et laisse l’instance redémarrer avec la connectivité réseau activée.
Sommaire
Choisir comment résoudre les problèmes
Deux méthodes vous permettent de restaurer la connectivité au réseau et au stockage d’une instance affectée par ce problème. Choisissez l’une des méthodes suivantes :
| Méthode | Prérequis | Présentation de la procédure |
|---|---|---|
| Méthode 1 - Mise en réseau améliorée | La mise en réseau améliorée est disponible uniquement dans un Virtual Private Cloud (VPC) nécessitant un type d’instance C3. Si le serveur n’utilise pas le type d’instance C3 actuellement, vous devez le modifier temporairement. | Vous modifiez le type d’instance du serveur pour une instance C3. La mise en réseau améliorée vous permet de vous connecter à l’instance affectée pour résoudre le problème. Une fois le problème résolu, vous modifiez à nouveau l’instance pour revenir au type d’instance original. Cette méthode est généralement plus rapide que la Méthode 2 et risque moins entraîner des erreurs d’utilisateur. Des frais supplémentaires seront facturés tant que l’instance C3 sera en cours d’exécution. |
| Méthode 2 - Configuration du registre | Capacité à créer ou à accéder à un second serveur. Capacité à modifier les paramètres du registre. | Démontez et détachez le volume racine à partir de l’instance affectée, attachez-le à une autre instance et effectuez les modifications dans le registre. Des frais supplémentaires seront facturés tant que le serveur supplémentaire sera en cours d’exécution. Cette méthode est plus lente que la Méthode 1, mais elle a fonctionné dans certaines situations dans lesquelles la Méthode 1 a échoué à résoudre le problème. |
Méthode 1 - Mise en réseau améliorée
-
Ouvrez la EC2 console Amazon à l'adresse https://console.aws.amazon.com/ec2/
. -
Dans le panneau de navigation, choisissez Instances.
-
Recherchez l’instance concernée. Sélectionnez l’instance, État de l’instance, puis Arrêter l’instance.
Avertissement
Lorsque vous arrêtez une instance, les données contenues sur les volumes de stockage d’instances sont effacées. Pour conserver les données provenant des volumes de stockage d’instances, sauvegardez-les sur un stockage permanent.
-
Une fois l’instance arrêtée, créez une sauvegarde. Sélectionnez l’instance, puis Actions, Image et modèles, et enfin Créer une image.
-
Modifiez le type d’instance avec un n’importe quel type d’instance C3.
-
Démarrez l’instance.
-
Connectez-vous à l'instance à l'aide de Remote Desktop, puis téléchargez
le package AWS PV Drivers Upgrade sur l'instance. -
Extrayez le contenu du dossier, puis exécutez
AWSPVDriverSetup.msi.Après avoir exécuté le MSI, l’instance redémarre automatiquement puis met à niveau les pilotes. L’instance ne sera pas disponible pendant 15 minutes.
-
Une fois la mise à niveau terminée et l'instance passée les deux tests de santé dans la EC2 console Amazon, connectez-vous à l'instance à l'aide de Remote Desktop et vérifiez que les nouveaux pilotes ont été installés. Dans le Gestionnaire de périphériques, sous Contrôleurs de stockage, recherchez Carte hôte AWS PV Storage. Vérifiez que la version du pilote est identique à la version la plus récente répertoriée dans l’historique des versions de pilote. Pour plus d’informations, consultez AWS Historique du package de pilotes PV.
-
Arrêtez l’instance et modifiez-la à nouveau pour revenir à son type d’instance original.
-
Démarrez l’instance et reprenez une utilisation normale.
Méthode 2 - Configuration du registre
-
Ouvrez la EC2 console Amazon à l'adresse https://console.aws.amazon.com/ec2/
. -
Dans le panneau de navigation, choisissez Instances.
-
Recherchez l’instance concernée. Sélectionnez l’instance, État de l’instance, puis Arrêter l’instance.
Avertissement
Lorsque vous arrêtez une instance, les données contenues sur les volumes de stockage d’instances sont effacées. Pour conserver les données provenant des volumes de stockage d’instances, sauvegardez-les sur un stockage permanent.
-
Sélectionnez Lancer des instances et créez une instance Windows Server 2008 ou Windows Server 2012 dans la même zone de disponibilité que l’instance affectée. Ne créez pas d’instance Windows Server 2012 R2.
Important
Si vous ne créez pas l’instance dans la même zone de disponibilité que l’instance affectée, vous ne pourrez pas attacher le volume racine de celle-ci à la nouvelle instance.
-
Dans le panneau de navigation, choisissez Volumes.
-
Recherchez le volume racine de l’instance affectée. Détachez le volume et attachez-le à l’instance temporaire que vous avez créée précédemment. Attachez-le avec le nom du périphérique par défaut (xvdf).
-
Utilisez les services Bureau à distance pour vous connecter à l’instance temporaire, puis utilisez l’utilitaire Gestion des disques pour rendre le volume disponible.
-
Sur l’instance temporaire, ouvrez la boîte de dialogue Run (Exécuter), tapez
regeditet appuyez sur Entrée. -
Dans le volet de navigation de l’Editeur du Registre, choisissez HKEY_Local_Machine, puis dans le menu File (Fichier), choisissez Load Hive (Charger Hive).
-
Dans la boîte de dialogue Load Hive (Charger Hive), accédez à Affected Volume (Volume affecté)\Windows\System32\config\System et tapez un nom temporaire dans a boîte de dialogue Key Name (Nom de la clé). Par exemple, saisissez OldSys.
-
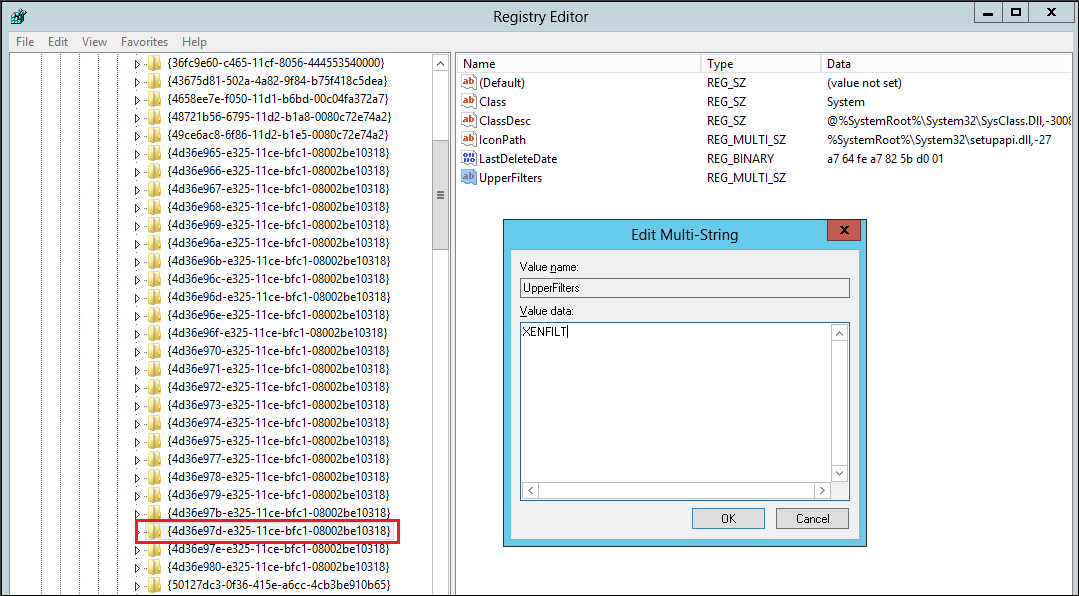
Dans le volet de navigation de l’Editeur du registre, recherchez les clés suivantes :
HKEY_LOCAL_MACHINE \ \ ControlSet 001 \ Control \ Class
your_temporary_key_name\ 4d36e97d-e325-11ce-bfc1-08002be10318HKEY_LOCAL_MACHINE \ \ ControlSet 001 \ Control \ Class
your_temporary_key_name\ 4d36e96a-e325-11ce-bfc1-08002be10318 -
Pour chaque clé, double-cliquez UpperFilters, entrez la valeur XENFILT, puis choisissez OK.
-
Recherchez les clés suivantes :
HKEY_LOCAL_MACHINE \ \ ControlSet 001 \ Services
your_temporary_key_name\ XENBUS \ Paramètres -
Créez une nouvelle chaîne (REG_SZ) avec le nom ActiveDevice et la valeur suivants :
PCI\VEN_5853&DEV_0001&SUBSYS_00015853&REV_01
-
Recherchez les clés suivantes :
HKEY_LOCAL_MACHINE \ \ 001 \ Services
your_temporary_key_name\ XENBUS ControlSet -
Remplacez la valeur Nombre de 0 à 1.
-
Recherchez et supprimez les clés suivantes :
HKEY_LOCAL_MACHINE \ \ ControlSet 001 \ Services \
your_temporary_key_namexenvbd \ StartOverrideHKEY_LOCAL_MACHINE \ \ ControlSet 001 \ Services \
your_temporary_key_namexenfilt \ StartOverride -
Dans le volet de navigation de l’Editeur du Registre, choisissez la clé temporaire que vous avez créée lorsque vous avez ouvert pour la première fois l’Editeur du Registre.
-
Dans le menu File (Fichier), choisissez Unload Hive (Décharger Hive).
-
Dans l’utilitaire Gestion des disques, choisissez le lecteur que vous avez attaché précédemment, ouvrez le menu contextuel (clic droit) et choisissez Hors connexion.
-
Dans la EC2 console Amazon, détachez le volume concerné de l'instance temporaire et attachez-le à nouveau à votre instance Windows Server 2012 R2 avec l'appareil name /dev/sda 1. Vous devez spécifier ce nom de périphérique pour désigner le volume en tant que volume racine.
-
Démarrez l’instance.
-
Connectez-vous à l'instance à l'aide de Remote Desktop, puis téléchargez
le package AWS PV Drivers Upgrade sur l'instance. -
Extrayez le contenu du dossier, puis exécutez
AWSPVDriverSetup.msi.Après avoir exécuté le MSI, l’instance redémarre automatiquement puis met à niveau les pilotes. L’instance ne sera pas disponible pendant 15 minutes.
-
Une fois la mise à niveau terminée et l'instance passée les deux tests de santé dans la EC2 console Amazon, connectez-vous à l'instance à l'aide de Remote Desktop et vérifiez que les nouveaux pilotes ont été installés. Dans le Gestionnaire de périphériques, sous Contrôleurs de stockage, recherchez Carte hôte AWS PV Storage. Vérifiez que la version du pilote est identique à la version la plus récente répertoriée dans l’historique des versions de pilote. Pour plus d’informations, consultez AWS Historique du package de pilotes PV.
-
Supprimez ou arrêtez l’instance temporaire que vous avez créée au cours de cette procédure.
Exécuter le script de correction
Si vous ne pouvez pas exécuter une mise à niveau du pilote sur place ou migrer vers une instance plus récente, vous pouvez exécuter le script de correction pour corriger les problèmes causés par la tâche de nettoyage Plug and Play.
Pour exécuter le script de correction
-
Ouvrez la EC2 console Amazon à l'adresse https://console.aws.amazon.com/ec2/
. -
Dans le panneau de navigation, choisissez Instances.
-
Sélectionnez l’instance pour laquelle vous souhaitez exécuter le script de correction. Sélectionnez État de l’instance, puis Arrêter l’instance.
Avertissement
Lorsque vous arrêtez une instance, les données contenues sur les volumes de stockage d’instances sont effacées. Pour conserver les données provenant des volumes de stockage d’instances, sauvegardez-les sur un stockage permanent.
-
Une fois l’instance arrêtée, créez une sauvegarde. Sélectionnez l’instance, puis Actions, Image et modèles et enfin Créer une image.
-
Sélectionnez État de l’instance, puis Démarrer l’instance.
-
Connectez-vous à l'instance à l'aide de Remote Desktop, puis téléchargez
le dossier RemediateDriverIssue .zip sur l'instance. -
Extrayez le contenu du dossier.
-
Exécutez le script de correction en fonction des instructions contenues dans le fichier Readme.txt. Le fichier se trouve dans le dossier dans lequel vous avez extrait le fichier RemediateDriverIssue .zip.
Transfert de la charge TCP
Important
Ce problème ne s'applique pas aux instances exécutant des pilotes réseau AWS PV ou Intel.
Par défaut, le déchargement TCP est activé pour les pilotes PV Citrix sous Windows. AMIs Si vous rencontrez des problèmes au niveau du transport ou de la transmission de paquets (comme indiqué sur Windows Performance Monitor), par exemple, lorsque vous exécutez certaines charges de travail SQL, vous pouvez devoir désactiver cette fonction.
Avertissement
La désactivation du transfert de la charge TCP peut réduire les performances réseau de votre instance.
Pour désactiver le transfert de la charge TCP pour Windows Server 2012 et 2008
-
Connectez-vous à votre instance en tant qu’administrateur local.
-
Si vous utilisez Windows Server 2012, appuyez sur Ctrl+Échap pour accéder à l’écran Démarrer, puis cliquez sur Panneau de configuration. Si vous utilisez Windows Server 2008, cliquez sur Démarrer et sélectionnez Panneau de configuration.
-
Choisissez Réseau et Internet, puis Centre Réseau et partage.
-
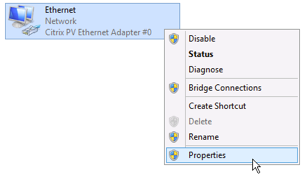
Cliquez sur Modifier les paramètres de la carte.
-
Cliquez avec le bouton droit sur Carte Ethernet PV Citrix #0, puis cliquez sur Propriétés.
-
Dans la boîte de dialogue Propriétés de la connexion au réseau local, cliquez sur Configurer pour ouvrir la boîte de dialogue Propriétés de la carte Ethernet PV Citrix #0.
-
Sous l’onglet Advanced (Avancé), désactivez chacune des propriétés, à l’exception de Correct TCP/UDP Checksum Value (Corriger la valeur de la somme de contrôle TCP/UDP). Pour désactiver une propriété, sélectionnez-la dans Property (Propriété) et choisissez Disabled (Désactivé) dans Value (Valeur).
-
Choisissez OK.
-
A partir d’une fenêtre d’invite de commande, exécutez les commandes suivantes :
netsh int ip set global taskoffload=disablednetsh int tcp set global chimney=disablednetsh int tcp set global rss=disablednetsh int tcp set global netdma=disabled -
Redémarrez l’instance.
Synchronisation du temps
Avant l’édition du 13/02/2013 de l’AMI Windows, l’agent invité Citrix Xen pouvait définir l’heure de manière incorrecte. Cela peut entraîner l’expiration du bail DHCP. En cas de problème pour vous connecter à votre instance, vous pouvez avoir besoin de mettre à niveau l’agent.
Pour déterminer si vous avez l’agent invité Citrix Xen mis à jour, vérifiez que le fichier C:\Program Files\Citrix\XenGuestAgent.exe date de mars 2013. Si la date sur le fichier est antérieure, mettez à jour le service d’agent invité Citrix Xen. Pour plus d’informations, consultez Mettre à niveau votre service d’agent invité Citrix Xen.
Les charges de travail qui exploitent plus de 20 000 IOPS disque subissent une dégradation due aux goulots d’étranglement du processeur
Vous pouvez être affecté par ce problème si vous utilisez des instances Windows exécutant des pilotes PV AWS
qui exploitent plus de 20 000 IOPS et que vous rencontrez un code de vérification des bogues 0x9E: USER_MODE_HEALTH_MONITOR.
Les lectures et écritures sur disque (IOs) dans les pilotes AWS PV se déroulent en deux phases : préparation des E/S et achèvement des E/S. Par défaut, la phase de préparation s’exécute sur un cœur arbitraire unique. La phase d’achèvement s’exécute sur le cœur 0. La quantité de calcul requise pour traiter une opération d’IO varie en fonction de sa taille et d’autres propriétés. Certains IOs utilisent davantage de calculs dans la phase de préparation, d'autres dans la phase d'achèvement. Lorsqu’une instance gère plus de 20 000 IOPS, la phase de préparation ou d’achèvement peut entraîner un goulot d’étranglement, lorsque le processeur sur lequel elle s’exécute est à 100 % de sa capacité. Le fait que la phase de préparation ou d'achèvement devienne un goulot d'étranglement dépend des propriétés du produit IOs utilisé par l'application.
À partir de la version 8.4.0 des pilotes AWS photovoltaïques, la charge de la phase de préparation et de la phase d'achèvement peut être répartie sur plusieurs cœurs, éliminant ainsi les goulots d'étranglement. Chaque application utilise des propriétés d’IO différentes. Par conséquent, l’application de l’une des configurations suivantes peut augmenter, diminuer ou ne pas affecter les performances de votre application. Après avoir appliqué l’une de ces configurations, surveillez l’application pour vérifier qu’elle enregistre les performances souhaitées.
-
Prérequis
Avant de commencer cette procédure de dépannage, vérifiez que les prérequis suivants sont respectés :
-
Votre instance utilise des pilotes AWS PV version 8.4.0 ou ultérieure. Pour effectuer une mise à niveau, consultez Mettre à niveau les pilotes PV sur EC2 les instances Windows.
-
Vous disposez d’un accès RDP à l’instance. Pour vous connecter à votre instance Windows à l’aide de RDP, consultez Connectez-vous à votre instance Windows à l’aide d’un client RDP.
-
Vous disposez d’un accès administrateur à l’instance.
-
-
Observer la charge processeur sur votre instance
Vous pouvez utiliser le Gestionnaire des tâches Windows pour afficher la charge sur chaque processeur afin de déterminer les goulots d’étranglement potentiels pour les IO disque.
-
Vérifiez que votre application est en cours d’exécution et gère un trafic similaire à votre charge de travail de production.
-
Connectez-vous à votre instance à l’aide de RDP.
-
Accédez menu Start (Démarrer) de votre instance.
-
Saisissez
Task Managerdans le menu Start (Démarrer) pour ouvrir le Gestionnaire des tâches. -
Si le Gestionnaire des tâches affiche la vue récapitulative, choisissez More details (Plus de détails) pour développer la vue détaillée.
-
Sélectionnez l’onglet Performance.
-
Sélectionner CPU (processeur) dans le volet gauche.
-
Cliquez avec le bouton droit de la souris sur le graphique dans le volet principal et sélectionnez Change graph to>Logical processors (Changer le graphique en > processeurs logiques) pour afficher chaque cœur individuel.
-
Selon le nombre de cœurs sur votre instance, vous pouvez voir des lignes affichant la charge processeur au fil du temps, ou vous pouvez simplement voir un nombre.
-
Si vous voyez des graphiques illustrant la charge au fil du temps, recherchez les CPUs endroits où le cadre est presque entièrement ombré.
-
Si vous voyez un nombre sur chaque cœur, recherchez les cœurs qui affichent systématiquement 95 % ou plus.
-
-
Notez si le cœur
0ou un autre cœur subit une charge lourde.
-
-
Choisir la configuration à appliquer
Nom de la configuration Quand appliquer cette configuration Remarques Default configuration La charge de travail entraîne moins de 20 000 IOPS, ou d’autres configurations n’ont pas amélioré les performances ou la stabilité. Pour cette configuration, les IO se produisent sur quelques cœurs, ce qui peut bénéficier à des charges de travail plus petites en augmentant la localité du cache et en réduisant le basculement de contexte.
Allow driver to choose whether to distribute completion La charge de travail entraîne plus de 20 000 IOPS et une charge modérée ou élevée est observée sur le cœur 0.Cette configuration est recommandée pour toutes les instances Xen utilisant PV 8.4.0 ou une version ultérieure et exploitant de plus de 20 000 IOPS, que des problèmes soient rencontrés ou non. Distribute both preparation and completion La charge de travail entraîne plus de 20 000 IOPS, et soit permettre au pilote de choisir la distribution n’a pas amélioré les performances, soit un cœur autre que 0connaît une charge élevée.Cette configuration permet la distribution à la fois de la préparation et de l’achèvement des IO. Note
Nous vous recommandons de ne pas distribuer la préparation des IO sans distribuer également l’achèvement des IO (ne pas définir
DpcRedirectionsans définirNotifierDistributed), car la phase d’achèvement est sensible à la surcharge par la phase de préparation lorsque la phase de préparation est exécutée en parallèle.Valeurs clés de registre
-
NotifierDistributed
Valeur
0ou aucune valeur — La phase d’achèvement se déroulera sur le cœur0.Valeur
1— Le pilote choisit d’exécuter la phase d’achèvement sur le cœur0ou sur un cœur supplémentaire par disque connecté.Valeur
2— Le pilote exécute la phase d’achèvement sur un cœur supplémentaire par disque connecté. -
DpcRedirection
Valeur
0ou aucune valeur — La phase de préparation se déroulera sur un cœur unique et arbitraire.Valeur
1— La phase de préparation est répartie sur plusieurs cœurs.
Configuration par défaut
Appliquez la configuration par défaut avec les versions du pilote AWS PV antérieures à la version 8.4.0, ou si une dégradation des performances ou de la stabilité est observée après l'application de l'une des autres configurations de cette section.
-
Connectez-vous à votre instance à l’aide de RDP.
-
Ouvrez une nouvelle invite de PowerShell commande en tant qu'administrateur.
-
Exécutez les commandes suivantes pour supprimer les clés de registre
NotifierDistributedetDpcRedirection.Remove-ItemProperty -Path HKLM:\System\CurrentControlSet\Services\xenvbd\Parameters -Name NotifierDistributedRemove-ItemProperty -Path HKLM:\System\CurrentControlSet\Services\xenvbd\Parameters -Name DpcRedirection -
Redémarrez votre instance.
Autoriser le pilote à choisir s’il doit distribuer l’achèvement
Définissez la clé de registre
NotiferDistributedpour permettre au pilote de stockage PV de choisir de distribuer ou non l’achèvement des IO.-
Connectez-vous à votre instance à l’aide de RDP.
-
Ouvrez une nouvelle invite de PowerShell commande en tant qu'administrateur.
-
Exécutez la commande suivante pour ajouter la clé de registre
NotiferDistributed.Set-ItemProperty -Type DWORD -Path HKLM:\System\CurrentControlSet\Services\xenvbd\Parameters -Value 0x00000001 -Name NotifierDistributed -
Redémarrez votre instance.
Distribuer la préparation et l’achèvement
Définissez les clés de registre
NotifierDistributedetDpcRedirectionpour toujours distribuer les phases de préparation et d’achèvement.-
Connectez-vous à votre instance à l’aide de RDP.
-
Ouvrez une nouvelle invite de PowerShell commande en tant qu'administrateur.
-
Exécutez les commandes suivantes pour définir les clés de registre
NotifierDistributedetDpcRedirection.Set-ItemProperty -Type DWORD -Path HKLM:\System\CurrentControlSet\Services\xenvbd\Parameters -Value 0x00000002 -Name NotifierDistributedSet-ItemProperty -Type DWORD -Path HKLM:\System\CurrentControlSet\Services\xenvbd\Parameters -Value 0x00000001 -Name DpcRedirection -
Redémarrez votre instance.
-
