Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Importation et exportation de bases de données SQL Server à l'aide de la sauvegarde et de la restauration natives
Amazon RDS prend en charge les sauvegarde et restauration natives pour les bases de données Microsoft SQL Server à l'aide de fichiers de sauvegarde complète (fichiers .bak). Lorsque vous utilisez RDS, vous accédez aux fichiers stockés dans Amazon S3 au lieu d'utiliser le système de fichiers local sur le serveur de base de données.
Par exemple, vous pouvez créer une sauvegarde complète depuis votre serveur local, la stocker sur S3, puis la restaurer sur une instance de base de données Amazon RDS existante. Vous pouvez également créer des sauvegardes à partir de RDS, les stocker sur S3, puis les restaurer chaque fois que vous le souhaitez.
La sauvegarde et la restauration natives sont disponibles dans toutes les AWS régions pour les instances de base de données mono-AZ et multi-AZ, y compris les instances de base de données multi-AZ avec des répliques de lecture. Les sauvegarde et restauration natives sont disponibles pour toutes les éditions de Microsoft SQL Server prises en charge sur Amazon RDS.
Le schéma suivant illustre les scénarios pris en charge.
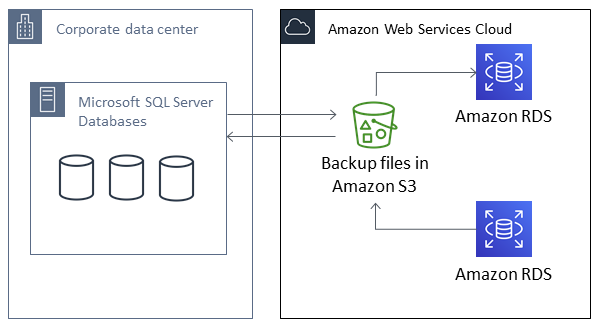
L'utilisation de fichiers .bak natifs pour sauvegarder et restaurer des bases de données est généralement le moyen le plus rapide de sauvegarder et de restaurer des bases de données. Il existe de nombreux avantages supplémentaires à l'utilisation des sauvegarde et restauration natives. Par exemple, vous pouvez effectuer les opérations suivantes :
-
Migrer des bases de données vers ou depuis Amazon RDS.
-
Déplacer des bases de données entre des instances de base de données RDS for SQL Server.
-
Migrer des données, des schémas, des procédures stockées, des déclencheurs et tout autre code de base de données dans des fichiers .bak.
-
Sauvegarder et restaurer des bases de données uniques, au lieu de la totalité d'instances de base de données.
-
Créer des copies de bases de données à des fins de développement, de test, de formation et de démonstration.
-
Stocker et transférer des fichiers de sauvegarde avec Amazon S3, pour offrir une couche de protection supplémentaire pour la reprise après sinistre.
-
Créez des sauvegardes natives de bases de données sur lesquelles Transparent Data Encryption (TDE) est activé, puis restaurez ces sauvegardes sur des bases de données sur site. Pour de plus amples informations, veuillez consulter Support pour le chiffrement transparent des données sur le SQL serveur.
-
Restaurez les sauvegardes natives des bases de données sur site sur lesquelles TDE est activé sur des instances de base de données RDS for SQL Server. Pour de plus amples informations, veuillez consulter Support pour le chiffrement transparent des données sur le SQL serveur.
Table des matières
Utilisation des sauvegarde et restauration natives
Importation et exportation de données SQL Server à l'aide d'autres méthodes
Utilisation de l'utilitaire BCP de Linux pour importer et exporter des données
Limitations et recommandations
Voici quelques limitations quant à l'utilisation des sauvegarde et restauration natives :
-
Vous ne pouvez pas effectuer de sauvegarde ou de restauration depuis un compartiment Amazon S3 situé dans une AWS région différente de celle de votre instance de base de données Amazon RDS.
-
Vous ne pouvez pas restaurer une base de données qui porte le même nom qu'une base de données existante. Les noms de base de données sont uniques.
-
Nous vous recommandons vivement de ne pas restaurer de fichiers de sauvegarde d'un fuseau horaire dans un autre fuseau horaire. Si vous restaurez des sauvegardes d'un fuseau horaire dans un autre, vous devez auditer vos requêtes et vos applications afin de déterminer les effets du changement de fuseau horaire.
-
Amazon S3 a une limite de taille de 5 To par fichier. Pour les sauvegardes natives de bases de données plus volumineuses, vous pouvez utiliser la sauvegarde multifichier.
-
La taille maximale de la base de données pouvant être sauvegardée sur S3 dépend de la mémoire disponible, du processeur, des I/O et des ressources réseau sur l'instance de base de données. Plus la base de données est grande, plus l'agent de sauvegarde consomme de la mémoire.
-
Vous ne pouvez pas effectuer une sauvegarde ou une restauration à partir de plus de 10 fichiers de sauvegarde simultanément.
-
Une sauvegarde différentielle est basée sur la dernière sauvegarde complète. Pour que les sauvegardes différentielles fonctionnent, vous ne pouvez prendre un instantané entre la dernière sauvegarde complète et la sauvegarde différentielle. Si vous souhaitez faire une sauvegarde différentielle, mais qu'il existe un instantané manuel ou automatique, créez une autre sauvegarde complète avant de créer la sauvegarde différentielle.
-
Les restaurations différentielles et de journaux ne sont pas prises en charge pour les bases de données possédant des fichiers dont l'identifiant unique file_guid est défini sur
NULL. -
Vous pouvez exécuter jusqu'à deux tâches de sauvegarde ou restauration simultanément.
-
Vous ne pouvez pas effectuer de sauvegardes natives de journaux à partir de SQL Server sur Amazon RDS.
-
RDS prend en charge les restaurations natives de bases de données jusqu'à 64 TiB. Les restaurations natives des bases de données sur SQL Server Express Edition sont limitées à 10 Go.
-
Vous ne pouvez pas sauvegarder une base de données pendant la fenêtre de maintenance, ou à tout moment où Amazon RDS prend un instantané de la base de données. Si une tâche de sauvegarde native se chevauche avec la fenêtre de sauvegarde quotidienne RDS, la tâche de sauvegarde native est annulée.
-
Sur des instances de base de données multi-AZ, vous pouvez uniquement restaurer nativement des bases de données sauvegardées en utilisant le modèle de restauration « Full ».
-
La restauration à partir de sauvegardes différentielles sur instances multi-AZ n'est pas prise en charge.
-
L'appel des procédures RDS pour la sauvegarde/restauration au sein d'une transaction n'est pas pris en charge.
-
Utilisez un chiffrement symétrique AWS KMS key pour chiffrer vos sauvegardes. Amazon RDS ne prend pas en charge les clés KMS asymétriques. Pour plus d'informations, consultez Création de clés KMS de chiffrement symétriques dans le Guide du développeur AWS Key Management Service .
-
Les fichiers de sauvegarde natifs sont chiffrés avec la clé KMS spécifiée à l'aide du mode cryptographique « Chiffrement seul ». Lorsque vous restaurez des fichiers de sauvegarde chiffrés, gardez à l'esprit qu'ils ont été chiffrés à l'aide du mode cryptographique « Chiffrement seul ».
-
Vous ne pouvez pas restaurer une base de données contenant un groupe de fichiers FILESTREAM.
-
Le chiffrement côté serveur Amazon S3 avec AWS KMS (SSE-KMS) n'est actuellement pas pris en charge. Lorsque vous fournissez une clé KMS à une procédure stockée, toutes les sauvegardes et restaurations natives sont chiffrées et déchiffrées côté client à l'aide de la clé KMS. AWS stocke les sauvegardes dans le compartiment S3 avec SSE-S3.
Nous vous recommandons d'utiliser les sauvegarde et restauration natives pour migrer votre base de données vers RDS si votre base de données peut être hors connexion pendant que le fichier de sauvegarde est créé, copié et restauré. Si votre base de données locale ne peut pas être hors ligne, nous vous recommandons d'utiliser le AWS Database Migration Service pour migrer votre base de données vers Amazon RDS. Pour plus d'informations, voir Qu'est-ce que c'est AWS Database Migration Service ?
Les sauvegarde et restauration natives ne visent pas à remplacer les fonctionnalités de récupération des données de la fonction de copie d'instantané entre régions. Nous vous recommandons d'utiliser la copie instantanée pour copier l'instantané de votre base de données dans une autre AWS région afin de permettre une reprise après sinistre entre régions sur Amazon RDS. Pour de plus amples informations, veuillez consulter Copier un instantané de base de données pour Amazon RDS.
