Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration à l'aide des espaces de table transportables Oracle
Vous pouvez utiliser la fonctionnalité d'espaces de table transportables Oracle pour copier un ensemble d'espaces de table à partir d'une base de données Oracle sur site vers une instance de base de données RDS for Oracle. Au niveau physique, vous transférez les fichiers de données source et les fichiers de métadonnées vers votre instance de base de données cible à l'aide d'Amazon EFS ou d'Amazon S3. La fonctionnalité d'espaces de table transportables utilise le package. rdsadmin.rdsadmin_transport_util Pour la syntaxe et la sémantique de ce package, consultez. Transport des espaces de table
Pour les articles de blog expliquant comment transporter des espaces disque logiques, consultez les sections Migrer les bases de données Oracle vers des tablespaces transportables et Amazon RDS for Oracle Transportable Tablespaces à l' AWS aide
Rubriques
Vue d'ensemble des espaces de table transportables Oracle
Un ensemble d'espaces de table transportables se compose de fichiers de données pour l'ensemble d'espaces de table en cours de transport et d'un fichier de vidage d'exportation contenant les métadonnées des espaces de table. Dans une solution de migration physique telle que les espaces de table transportables, vous transférez des fichiers physiques : fichiers de données, fichiers de configuration et fichiers de vidage Data Pump.
Rubriques
Avantages et inconvénients des espaces de table transportables
Nous vous recommandons d'utiliser des espaces de table transportables lorsque vous devez migrer un ou plusieurs espaces de table volumineux vers RDS avec un minimum de temps d'arrêt. Les espaces de table transportables offrent les avantages suivants par rapport à la migration logique :
-
Les temps d'arrêt sont inférieurs à ceux de la plupart des autres solutions de migration Oracle.
-
Comme la fonctionnalité des espaces de table transportables copie uniquement les fichiers physiques, elle évite les erreurs d'intégrité des données et la corruption logique qui peuvent survenir lors d'une migration logique.
-
Aucune licence supplémentaire n'est requise.
-
Vous pouvez migrer un ensemble d'espaces de table entre différentes plateformes et différents types d'endianisme, par exemple d'une plateforme Oracle Solaris vers Linux. Toutefois, le transport des espaces de table vers et depuis des serveurs Windows n'est pas pris en charge.
Note
Linux est entièrement testé et pris en charge. Toutes les variantes UNIX n'ont pas été testées.
Si vous utilisez des espaces de table transportables, vous pouvez transporter les données à l'aide d'Amazon S3 ou d'Amazon EFS :
-
Lorsque vous utilisez EFS, vos sauvegardes restent dans le système de fichiers EFS pendant toute la durée de l'importation. Vous pouvez ensuite supprimer les fichiers. Dans cette technique, vous n'avez pas besoin de provisionner le stockage EBS pour votre instance de base de données. C'est pourquoi nous vous recommandons d'utiliser Amazon EFS plutôt que S3. Pour de plus amples informations, veuillez consulter EFSIntégration avec Amazon.
-
Lorsque vous utilisez S3, vous téléchargez des sauvegardes RMAN sur le stockage EBS attaché à votre instance de base de données. Les fichiers restent dans votre stockage EBS pendant l'importation. Après l'importation, vous pouvez libérer cet espace, qui reste alloué à votre instance de base de données.
Le principal inconvénient des espaces de table transportables est que vous nécessitez une connaissance relativement avancée d'Oracle Database. Pour plus d'informations, consultez Transport des espaces de table entre bases de données
Limitations applicables aux espaces de table transportables
Les limitations Oracle Database pour les espaces de table transportables s'appliquent lorsque vous utilisez cette fonctionnalité dans RDS for Oracle. Pour plus d'informations, consultez Limitations relatives aux espaces de table transportables
-
Ni la base de données source ni la base de données cible ne peuvent utiliser Standard Edition 2 (SE2). Seule Enterprise Edition est prise en charge.
-
Vous ne pouvez pas utiliser une base de données Oracle Database 11g comme source. La fonctionnalité d'espaces de table transportables multiplateformes RMAN repose sur le mécanisme de transport RMAN, qu'Oracle Database 11g ne prend pas en charge.
-
Vous ne pouvez pas migrer des données depuis une instance de base de données RDS for Oracle en utilisant des espaces de table transportables. Vous pouvez uniquement utiliser des espaces de table transportables pour migrer des données vers une instance de base de données RDS for Oracle.
-
Le système d'exploitation Windows n'est pas pris en charge.
-
Vous ne pouvez pas transporter des espaces de table vers une base de données à un niveau de version inférieur. La base de données cible doit être à un niveau de version égal ou supérieur à celui de la base de données source. Par exemple, vous ne pouvez pas transporter des espaces de table d'Oracle Database 21c vers Oracle Database 19c.
-
Vous ne pouvez pas transporter des espaces de table administratifs tels que
SYSTEMetSYSAUX. -
Vous ne pouvez pas transporter d'objets autres que des données tels que des packages PL/SQL, des classes Java, des vues, des déclencheurs, des séquences, des utilisateurs, des rôles et des tables temporaires. Pour transporter des objets autres que des données, créez-les manuellement ou utilisez l'exportation et l'importation de métadonnées Data Pump. Pour plus d'informations, consultez la note de support My Oracle 1454872.1
. -
Vous ne pouvez pas transporter des espaces de table chiffrés ou qui utilisent des colonnes chiffrées.
-
Si vous transférez des fichiers à l'aide d'Amazon S3, la taille de fichier maximale prise en charge est de 5 Tio.
-
Si la base de données source utilise des options Oracle telles que Spatial, vous ne pouvez pas transporter des espaces de table à moins que les mêmes options soient configurées sur la base de données cible.
-
Vous ne pouvez pas transporter des espaces de table vers une instance de base de données RDS for Oracle dans une configuration de réplicas Oracle. Pour contourner ce problème, vous pouvez supprimer tous les réplicas, transporter les espaces de table, puis recréer les réplicas.
Prérequis pour les espaces de table transportables
Avant de commencer, effectuez les tâches suivantes :
-
Passez en revue les exigences en matière d'espaces de table transportables, décrites dans les documents suivants figurant dans My Oracle Support :
-
Réduire les temps d'arrêt des espaces de table transportables en utilisant la sauvegarde incrémentielle multiplateforme (ID de document 2471245.1)
(langue française non garantie) -
Restrictions et limites relatives aux espaces de table transportables (TTS) : détails, référence et version, le cas échéant (ID de document 1454872.1)
(langue française non garantie) -
Note principale concernant les espaces de table transportables (TTS) -- Questions et problèmes courants (ID de document 1166564.1)
(langue française non garantie)
-
-
Prévoyez la conversion de l'endianisme. Si vous spécifiez l'identifiant de la plateforme source, RDS for Oracle convertit automatiquement l'endianisme. Pour savoir comment trouver une plateforme IDs, consultez Data Guard Support for Heterogenous Primary and Physical Standbys in Same Data Guard configuration (Doc ID
413484.1). -
Assurez-vous que la fonctionnalité des espaces de table transportables est activée sur votre instance de base de données cible. Cette fonctionnalité est activée uniquement si vous n'obtenez pas une erreur
ORA-20304lorsque vous exécutez la requête suivante :SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files);Si la fonctionnalité des espaces de table transportables n'est pas activée, redémarrez votre instance de base de données. Pour de plus amples informations, veuillez consulter Redémarrage d'une instance de base de données.
-
Assurez-vous que le fichier de fuseau horaire est le même dans les bases de données source et cible.
-
Assurez-vous que les jeux de caractères des bases de données source et cible répondent à l'une des exigences suivantes :
-
Les jeux de caractères sont les mêmes.
-
Les jeux de caractères sont compatibles. Pour obtenir la liste des exigences de compatibilité, consultez la section Limitations générales relatives au transport de données
dans la documentation de la base de données Oracle.
-
-
Si vous envisagez de transférer des fichiers à l'aide d'Amazon S3, procédez comme suit :
-
Assurez-vous qu'un compartiment Amazon S3 est disponible pour les transferts de fichiers et qu'il se trouve dans la même AWS région que votre instance de base de données. Pour plus d'informations, veuillez consulter Créer un compartiment dans le Guide de démarrage d'Amazon Simple Storage Service.
-
Préparez le compartiment Amazon S3 pour l'intégration d'Amazon RDS en suivant les instructions fournies dans Configuration des autorisations IAM pour l'intégration de RDS for Oracle à Amazon S3.
-
-
Si vous envisagez de transférer des fichiers à l'aide d'Amazon EFS, assurez-vous d'avoir configuré EFS conformément aux instructions fournies dans EFSIntégration avec Amazon.
-
Nous vous recommandons vivement d'activer les sauvegardes automatiques dans votre instance de base de données cible. Comme l'étape d'importation des métadonnées peut échouer, il est important de pouvoir restaurer votre instance de base de données dans son état d'avant l'importation, afin d'éviter d'avoir à sauvegarder, transférer et importer à nouveau vos espaces de table.
Phase 1 : Configuration de votre hôte source
Au cours de cette étape, vous copiez les scripts de transport des espaces de table fournis par My Oracle Support et configurez les fichiers de configuration nécessaires. Dans les étapes suivantes, l'hôte source exécute la base de données qui contient les espaces de table à transporter vers votre instance cible.
Pour configurer votre hôte source
-
Connectez-vous à votre hôte source en tant que propriétaire de votre répertoire de base Oracle.
-
Assurez-vous que vos variables d'environnement
ORACLE_HOMEetORACLE_SIDpointent vers votre base de données source. -
Connectez-vous à votre base de données en tant qu'administrateur et vérifiez que la version de fuseau horaire, le jeu de caractères de base de données et le jeu de caractères national sont identiques à ceux de votre base de données cible.
SELECT * FROM V$TIMEZONE_FILE; SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); -
Configurez l'utilitaire d'espace de table transportable comme décrit dans la note de support Oracle 2471245.1
(langue française non garantie). La configuration inclut la modification du fichier
xtt.propertiessur votre hôte source. L'exemple de fichierxtt.propertiessuivant spécifie les sauvegardes de trois espaces de table dans le répertoire/dsk1/backups. Il s'agit des espaces de table que vous souhaitez transporter vers votre instance de base de données cible. Il spécifie également l'identifiant de la plateforme source pour convertir automatiquement l'endianisme.Note
Pour une plate-forme valide IDs, consultez Data Guard Support pour les systèmes de secours primaires et physiques hétérogènes dans la même configuration Data Guard (Doc ID
413484.1). #linux system platformid=13#list of tablespaces to transport tablespaces=TBS1,TBS2,TBS3#location where backup will be generated src_scratch_location=/dsk1/backups#RMAN command for performing backup usermantransport=1
Phase 2 : Préparation de la sauvegarde complète des espaces de table
Au cours de cette phase, vous sauvegardez vos espaces de table pour la première fois, vous transférez les sauvegardes vers votre hôte cible, puis vous les restaurez à l'aide de la procédure rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces. Lorsque cette phase est terminée, les sauvegardes initiales des espaces de table résident sur votre instance de base de données cible et peuvent être mises à jour avec des sauvegardes incrémentielles.
Rubriques
Étape 1 : Sauvegarder les espaces de table sur votre hôte source
Au cours de cette étape, vous utilisez le script xttdriver.pl pour effectuer une sauvegarde complète de vos espaces de table. La sortie de xttdriver.pl est stockée dans la variable d'environnement TMPDIR.
Pour sauvegarder vos espaces de table
-
Si vos espaces de table sont en mode lecture seule, connectez-vous à votre base de données source en tant qu'utilisateur disposant du privilège
ALTER TABLESPACEet placez vos espaces de table en mode lecture/écriture. Sinon, passez à l'étape suivante.L'exemple suivant place
tbs1,tbs2ettbs3en mode lecture/écriture.ALTER TABLESPACE tbs1 READ WRITE; ALTER TABLESPACE tbs2 READ WRITE; ALTER TABLESPACE tbs3 READ WRITE; -
Sauvegardez vos espaces de table à l'aide du script
xttdriver.pl. Vous pouvez éventuellement spécifier--debugpour exécuter le script en mode débogage.export TMPDIR=location_of_log_filescdlocation_of_xttdriver.pl$ORACLE_HOME/perl/bin/perl xttdriver.pl --backup
Étape 2 : Transférer les fichiers de sauvegarde vers votre instance de base de données cible
Au cours de cette étape, copiez les fichiers de sauvegarde et de configuration à partir de votre emplacement zéro vers votre instance de base de données cible. Choisissez l’une des options suivantes :
-
Si les hôtes source et cible partagent un système de fichiers Amazon EFS, utilisez un utilitaire de système d'exploitation tel que
cppour copier vos fichiers de sauvegarde et le fichierres.txtà partir de votre emplacement zéro vers un répertoire partagé. Passez ensuite à Étape 3 : Importer les espaces de table dans votre instance de base de données cible. -
Si vous devez organiser vos sauvegardes vers un compartiment Amazon S3, procédez comme suit.
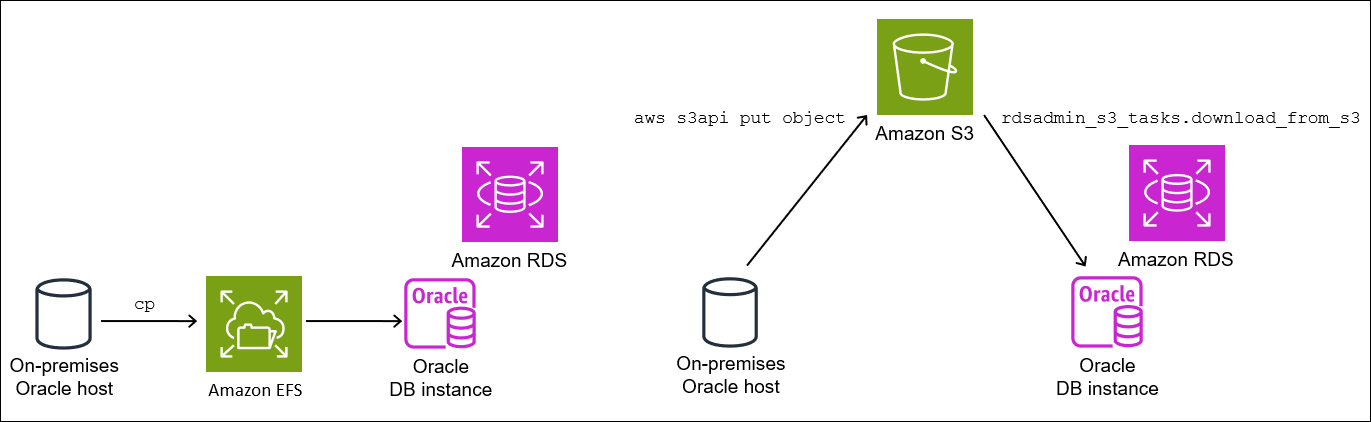
Étape 2.2 : Charger les sauvegardes dans votre compartiment Amazon S3
Chargez vos sauvegardes et le fichier res.txt depuis votre répertoire zéro vers votre compartiment Amazon S3. Pour plus d'informations, consultez Chargement d'objets dans le Guide de l'utilisateur Amazon Simple Storage Service.
Étape 2.3 : Télécharger les sauvegardes depuis votre compartiment Amazon S3 vers votre instance de base de données cible
Au cours de cette étape, vous utilisez la procédure rdsadmin.rdsadmin_s3_tasks.download_from_s3 pour télécharger vos sauvegardes dans votre instance de base de données RDS for Oracle.
Pour télécharger vos sauvegardes depuis votre compartiment Amazon S3
-
Lancez SQL*Plus ou Oracle SQL Developer et connectez-vous à votre instance de base de données RDS for Oracle.
-
Téléchargez les sauvegardes depuis le compartiment Amazon S3 vers votre instance de base de données cible en utilisant la procédure Amazon RDS
rdsadmin.rdsadmin_s3_tasks.download_from_s3. L'exemple suivant télécharge tous les fichiers d'un compartiment Amazon S3 nomméamzn-s3-demo-bucketDATA_PUMP_DIREXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'res.txt'); SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'amzn-s3-demo-bucket', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;L'instruction
SELECTrenvoie l'ID de la tâche dans un type de donnéesVARCHAR2. Pour de plus amples informations, veuillez consulter Téléchargement des fichiers d'un compartiment Amazon S3 vers une instance de base de données Oracle.
Étape 3 : Importer les espaces de table dans votre instance de base de données cible
Pour restaurer vos espaces de table sur votre instance de base de données cible, suivez la procédure. rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces Cette procédure convertit automatiquement les fichiers de données au format endian approprié.
Si vous importez depuis une plate-forme autre que Linux, spécifiez la plate-forme source à l'aide du paramètre p_platform_id lorsque vous appelezimport_xtts_tablespaces. Assurez-vous que l'identifiant de plate-forme que vous spécifiez correspond à celui indiqué dans le xtt.properties fichier dansÉtape 2 : Exporter les métadonnées d'espace de table sur votre hôte source.
Pour importer les espaces de table dans votre instance de base de données cible
-
Démarrez un client Oracle SQL et connectez-vous en tant qu'utilisateur principal à votre instance de base de données RDS for Oracle cible.
-
Exécutez la procédure
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesen spécifiant les espaces de table à importer et le répertoire contenant les sauvegardes.L'exemple suivant importe les tablespaces
TBS1TBS2, etTBS3depuis le répertoire.DATA_PUMP_DIRLa plate-forme source est AIX Based Systems (64 bits), dont l'ID de6plate-forme est. Vous pouvez trouver la plateforme IDs enV$TRANSPORTABLE_PLATFORMinterrogeant.VAR task_id CLOB BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces( 'TBS1,TBS2,TBS3', 'DATA_PUMP_DIR', p_platform_id => 6); END; / PRINT task_id -
(Facultatif) Surveillez la progression en interrogeant la table
rdsadmin.rds_xtts_operation_info. La colonnextts_operation_stateindique la valeurEXECUTING,COMPLETEDouFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;Note
Pour les opérations de longue durée, vous pouvez également interroger
V$SESSION_LONGOPS,V$RMAN_STATUSetV$RMAN_OUTPUT. -
Consultez le journal de l'importation terminée en utilisant l'ID de tâche issu de l'étape précédente.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Assurez-vous de la réussite de l'importation avant de passer à l'étape suivante.
Phase 3 : Création et transfert de sauvegardes incrémentielles
Dans cette phase, vous effectuez et transférez régulièrement des sauvegardes incrémentielles pendant que la base de données source est active. Cette technique réduit la taille de la sauvegarde finale de vos espaces de table. Si vous effectuez plusieurs sauvegardes incrémentielles, vous devez copier le fichier res.txt après la dernière sauvegarde incrémentielle afin de pouvoir l'appliquer à l'instance cible.
Les étapes sont les mêmes que dans Phase 2 : Préparation de la sauvegarde complète des espaces de table, si ce n'est que l'étape d'importation est facultative.
Phase 4 : Transport des espaces de table
Dans cette phase, vous sauvegardez vos espaces de table en lecture seule et exportez les métadonnées Data Pump, transférez ces fichiers vers votre hôte cible et importez à la fois les espaces de table et les métadonnées.
Rubriques
Étape 1 : Sauvegarder vos espaces de table en lecture seule
Cette étape est identique à Étape 1 : Sauvegarder les espaces de table sur votre hôte source, mais présente une différence clé : vous placez vos espaces de table en mode lecture seule avant de les sauvegarder pour la dernière fois.
L'exemple suivant place tbs1, tbs2 et tbs3 en mode lecture seule.
ALTER TABLESPACE tbs1 READ ONLY; ALTER TABLESPACE tbs2 READ ONLY; ALTER TABLESPACE tbs3 READ ONLY;
Étape 2 : Exporter les métadonnées d'espace de table sur votre hôte source
Exportez les métadonnées de vos espaces de table en exécutant l'utilitaire expdb sur votre hôte source. L'exemple suivant exporte des tablespaces TBS1TBS2, et TBS3 vers un fichier de sauvegarde xttdump.dmp dans un répertoire. DATA_PUMP_DIR
expdpusername/pwd\ dumpfile=xttdump.dmp\ directory=DATA_PUMP_DIR\ statistics=NONE \ transport_tablespaces=TBS1,TBS2,TBS3\ transport_full_check=y \ logfile=tts_export.log
S'il s'DATA_PUMP_DIRagit d'un répertoire partagé dans Amazon EFS, passez directement àÉtape 4 : Importer les espaces de table dans votre instance de base de données cible.
Étape 3 : (Amazon S3 uniquement) Transférer les fichiers de sauvegarde et d'exportation vers votre instance de base de données cible
Si vous utilisez Amazon S3 pour organiser vos sauvegardes d'espaces de table et votre fichier d'exportation Data Pump, procédez comme suit.
Étape 3.1 : Charger les sauvegardes et le fichier de vidage depuis votre hôte source dans votre compartiment Amazon S3
Chargez vos fichiers de sauvegarde et de vidage depuis votre hôte source dans votre compartiment Amazon S3. Pour plus d'informations, consultez Chargement d'objets dans le Guide de l'utilisateur Amazon Simple Storage Service.
Étape 3.2 : Télécharger les sauvegardes et le fichier de vidage depuis votre compartiment Amazon S3 vers votre instance de base de données cible
Au cours de cette étape, vous utilisez la procédure rdsadmin.rdsadmin_s3_tasks.download_from_s3 pour télécharger vos sauvegardes et le fichier de vidage vers votre instance de base de données RDS for Oracle. Suivez les étapes de Étape 2.3 : Télécharger les sauvegardes depuis votre compartiment Amazon S3 vers votre instance de base de données cible.
Étape 4 : Importer les espaces de table dans votre instance de base de données cible
Utilisez la procédure rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces pour restaurer les espaces de table. Pour la syntaxe et la sémantique de cette procédure, consultez Importation des espaces de table transportés dans votre instance de base de données
Important
Une fois l'importation finale de vos espaces de table terminée, l'étape suivante consiste à importer les métadonnées Oracle Data Pump. Si l'importation échoue, il est important de rétablir l'état de votre instance de base de données avant l'échec. Nous vous recommandons donc de créer un instantané de base de données de votre instance de base de données en suivant les instructions fournies dans Création d'un instantané de base de données pour une instance de base de données mono-AZ pour Amazon RDS. Cet instantané contiendra tous les espaces de table importés. Ainsi, si l'importation échoue, vous n'avez pas besoin de répéter le processus de sauvegarde et d'importation.
Si les sauvegardes automatiques de votre instance de base de données cible sont activées et qu'Amazon RDS ne détecte pas qu'un instantané valide a été lancé avant que vous importiez les métadonnées, RDS tente de créer un instantané. En fonction de l'activité de votre instance, cet instantané peut réussir ou non. Si aucun instantané valide n'est détecté ou si un instantané ne peut pas être lancé, l'importation des métadonnées se termine avec des erreurs.
Pour importer les espaces de table dans votre instance de base de données cible
-
Démarrez un client Oracle SQL et connectez-vous en tant qu'utilisateur principal à votre instance de base de données RDS for Oracle cible.
-
Exécutez la procédure
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesen spécifiant les espaces de table à importer et le répertoire contenant les sauvegardes.L'exemple suivant importe les tablespaces
TBS1TBS2, etTBS3depuis le répertoire.DATA_PUMP_DIRBEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces('TBS1,TBS2,TBS3','DATA_PUMP_DIR'); END; / PRINT task_id -
(Facultatif) Surveillez la progression en interrogeant la table
rdsadmin.rds_xtts_operation_info. La colonnextts_operation_stateindique la valeurEXECUTING,COMPLETEDouFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;Note
Pour les opérations de longue durée, vous pouvez également interroger
V$SESSION_LONGOPS,V$RMAN_STATUSetV$RMAN_OUTPUT. -
Consultez le journal de l'importation terminée en utilisant l'ID de tâche issu de l'étape précédente.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Assurez-vous de la réussite de l'importation avant de passer à l'étape suivante.
-
Prenez un instantané de base de données manuel en suivant les instructions fournies dans Création d'un instantané de base de données pour une instance de base de données mono-AZ pour Amazon RDS.
Étape 5 : Importer les métadonnées d'espace de table dans votre instance de base de données cible
Au cours de cette étape, vous importez les métadonnées d'espace de table transportable dans votre instance de base de données RDS for Oracle en utilisant la procédure rdsadmin.rdsadmin_transport_util.import_xtts_metadata. Pour la syntaxe et la sémantique de cette procédure, consultez Importation des métadonnées d'espaces de table transportables dans votre instance de base de données. Pendant l'opération, le statut de l'importation est indiqué dans la table rdsadmin.rds_xtts_operation_info.
Important
Avant d'importer les métadonnées, nous vous recommandons vivement de confirmer qu'un instantané de base de données a bien été créé après l'importation de vos espaces de table. Si l'étape d'importation échoue, restaurez votre instance de base de données, corrigez les erreurs d'importation, puis retentez l'importation.
Pour importer les métadonnées Data Pump dans votre instance de base de données RDS for Oracle
-
Démarrez votre client Oracle SQL et connectez-vous en tant qu'utilisateur principal à votre instance de base de données cible.
-
Créez les utilisateurs propriétaires des schémas dans vos espaces de table transportés, si ces utilisateurs n'existent pas encore.
CREATE USERtbs_ownerIDENTIFIED BYpassword; -
Importez les métadonnées en spécifiant le nom du fichier de vidage et l'emplacement du répertoire.
BEGIN rdsadmin.rdsadmin_transport_util.import_xtts_metadata('xttdump.dmp','DATA_PUMP_DIR'); END; / -
(Facultatif) Interrogez la table d'historique des espaces de table transportables pour voir le statut de l'importation des métadonnées.
SELECT * FROM rdsadmin.rds_xtts_operation_info;Une fois l'opération terminée, vos espaces de table sont en mode lecture seule.
-
(Facultatif) Affichez le fichier journal.
L'exemple suivant répertorie le contenu du répertoire BDUMP, puis interroge le journal d'importation.
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'BDUMP')); SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-import_xtts_metadata-2023-05-22.01-52-35.560858000.log'));
Phase 5 : Validation des espaces de table transportés
Au cours de cette étape facultative, vous validez vos espaces de table transportés à l'aide de la procédurerdsadmin.rdsadmin_rman_util.validate_tablespace, puis vous placez vos espaces de table en mode lecture/écriture.
Pour valider les données transportées
-
Lancez SQL*Plus ou SQL Developer et connectez-vous en tant qu'utilisateur principal à votre instance de base de données cible.
-
Validez les espaces de table à l'aide de la procédure
rdsadmin.rdsadmin_rman_util.validate_tablespace.SET SERVEROUTPUT ON BEGIN rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS1', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS2', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS3', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); END; / -
Placez vos espaces de table en mode lecture/écriture.
ALTER TABLESPACETBS1READ WRITE; ALTER TABLESPACETBS2READ WRITE; ALTER TABLESPACETBS3READ WRITE;
Phase 6 : Nettoyage des fichiers restants
Au cours de cette étape facultative, vous supprimez tous les fichiers inutiles. Utilisez la procédure rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files pour répertorier les fichiers de données devenus orphelins après une importation d'espace de table, puis utilisez la procédure rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files pour les supprimer. Pour la syntaxe et la sémantique de ces procédures, consultez Établissement de la liste des fichiers orphelins après une importation d'espace de table et Suppression des fichiers de données devenus orphelins après une importation d'espace de table.
Pour nettoyer les fichiers restants
-
Supprimez les anciennes sauvegardes
DATA_PUMP_DIRcomme suit :-
Répertoriez les fichiers de sauvegarde en exécutant
rdsadmin.rdsadmin_file_util.listdir.SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); -
Supprimez les sauvegardes une par une en appelant
UTL_FILE.FREMOVE.EXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'backup_filename');
-
-
Si vous avez importé des espaces de table mais n'avez pas importé de métadonnées pour ces espaces de table, vous pouvez supprimer les fichiers de données orphelins comme suit :
-
Répertoriez les fichiers de données orphelins que vous devez supprimer. L'exemple suivant exécute la procédure
rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files.SQL> SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files); FILENAME FILESIZE -------------- --------- datafile_7.dbf 104865792 datafile_8.dbf 104865792 -
Supprimez les fichiers orphelins en exécutant la procédure
rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import.BEGIN rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import('DATA_PUMP_DIR'); END; /L'opération de nettoyage génère un fichier journal qui utilise le format de nom
rds-xtts-delete_xtts_orphaned_files-dans le répertoireYYYY-MM-DD.HH24-MI-SS.FF.logBDUMP. -
Lisez le fichier journal généré à l'étape précédente. L'exemple suivant lit le journal
rds-xtts-delete_xtts_orphaned_files-.2023-06-01.09-33-11.868894000.logSELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-delete_xtts_orphaned_files-2023-06-01.09-33-11.868894000.log')); TEXT -------------------------------------------------------------------------------- orphan transported datafile datafile_7.dbf deleted. orphan transported datafile datafile_8.dbf deleted.
-
-
Si vous avez importé des espaces de table et importé des métadonnées pour ces espaces de table, mais que vous avez rencontré des erreurs de compatibilité ou d'autres problèmes liés à Oracle Data Pump, nettoyez les fichiers de données partiellement transportés comme suit :
-
Répertoriez les espaces de table qui contiennent des fichiers de données partiellement transportés en interrogeant
DBA_TABLESPACES.SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES WHERE PLUGGED_IN='YES'; TABLESPACE_NAME -------------------------------------------------------------------------------- TBS_3 -
Supprimez les espaces de table et les fichiers de données partiellement transportés.
DROP TABLESPACETBS_3INCLUDING CONTENTS AND DATAFILES;
-
