Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créer un journal d'activité à l'aide de la CloudTrail console
Un parcours peut être appliqué à toutes Régions AWS les zones activées dans votre Compte AWS région ou peut être appliqué à une seule région. Un parcours qui s'applique à tous ceux Régions AWS qui sont activés dans votre compte Compte AWS est appelé parcours multirégional. À titre de bonne pratique, nous vous recommandons de créer un parcours multirégional, car il capture l'activité dans toutes les régions activées. Tous les journaux de suivi créés à l'aide de la CloudTrail console sont des journaux de suivi multi-régions. Vous ne pouvez créer un journal de suivi à région unique qu'à l'aide de l'opération AWS CLI d'CreateTrailAPI ou.
Note
Après avoir créé un journal de suivi, vous pouvez configurer d'autres Services AWS pour approfondir l'analyse et agir sur les données d'événements collectées dans CloudTrail les journaux. Pour de plus amples informations, veuillez consulter AWS intégrations de services avec journaux CloudTrail .
Créer un journal d'activité à l'aide de la console
Utilisez la procédure suivante pour créer un journal de suivi multi-régions. Pour journaliser les événements dans une région unique (non recommandé), utilisez l' AWS CLI.
Pour créer un CloudTrail parcours à l'aide du AWS Management Console
Connectez-vous à la CloudTrail console AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/cloudtrail/
. -
Sur la page d'accueil du CloudTrail service, sur la page des sentiers ou dans la section des sentiers de la page du tableau de bord, choisissez Créer un parcours.
-
Sur la page Créer un journal de suivi, tapez un nom pour votre journal de suivi dans la zone Nom du journal de suivi. Pour de plus amples informations, veuillez consulter Exigences de dénomination pour les CloudTrail ressources, les compartiments S3 et les clés KMS.
-
S'il s'agit d'un AWS Organizations journal de suivi d'organisation, vous pouvez activer le journal de suivi pour tous les comptes de votre organisation. Pour voir cette option, vous devez vous connecter à la console avec un utilisateur ou un rôle dans le compte de gestion ou d'administrateur délégué. Pour créer avec succès le journal de suivi d’une organisation, assurez-vous que l’utilisateur ou le rôle dispose d’autorisations suffisantes. Pour plus d'informations, consultez Création d'un journal de suivi pour une organisation.
-
Sous Emplacement de stockage, choisissez Créer un nouveau compartiment S3 pour créer un nouveau compartiment. Lorsque vous créez un compartiment, CloudTrail crée et applique les stratégies nécessaires. Si vous choisissez de créer un nouveau compartiment S3, votre politique IAM doit inclure une autorisation pour l'
s3:PutEncryptionConfigurationaction, car le chiffrement côté serveur est activé par défaut pour le compartiment.Note
Si vous avez choisi Utiliser un compartiment S3 existant, spécifiez un compartiment dans Nom du compartiment des journaux de suivi, ou sélectionnez Parcourir pour choisir un compartiment. Si vous voulez utiliser un compartiment dans un autre compte, vous devez spécifier le nom du compartiment. La politique de compartiment doit accorder une CloudTrail autorisation d'écriture. Pour en savoir plus sur la modification manuelle de la politique de compartiment, consultez Politique relative aux compartiments Amazon S3 pour CloudTrail.
Pour faciliter la recherche de vos journaux, créez un nouveau dossier (également appelé prefix (préfixe) dans un compartiment existant pour stocker vos CloudTrail journaux. Saisir le préfixe dans Préfixe.
-
Sous Log file SSE-KMS encryption (Chiffrement SSE-KMS des fichiers journaux), choisissez Enabled (Activé) si vous souhaitez chiffrer vos fichiers journaux et digérer les fichiers avec SSE-KMS plutôt qu'avec SSE-S3. La valeur par défaut est Activé. Si vous n'activez pas le chiffrement SSE-KMS, vos fichiers journaux et vos fichiers de valeur de hachage sont chiffrés à l'aide du chiffrement SSE-S3. Pour plus d'informations sur le chiffrement SSE-KMS, consultez Utilisation du chiffrement côté serveur avec AWS Key Management Service (SSE-KMS). Pour plus d'informations sur SSE-S3, consultez Utilisation du chiffrement côté serveur avec les clés de chiffrement gérées par Amazon S3 (SSE-S3).
Si vous activez le chiffrement SSE-KMS, sélectionnez Nouveau ou Existant. AWS KMS key Dans AWS KMS Alias, spécifiez un alias, au format
alias/MyAliasName. Pour plus d'informations, consultezMise à jour d'une ressource pour qu'elle utilise votre clé KMS avec la console. CloudTrail prend également en charge les Clés AWS KMS multi-régions. Pour plus d’informations, consultez la section Utilisation de clés multi-régions dans le Guide du développeur AWS Key Management Service .Note
Vous pouvez également saisir l’ARN d’une clé à partir d’un autre compte. Pour de plus amples informations, veuillez consulter Mise à jour d'une ressource pour qu'elle utilise votre clé KMS avec la console. La politique de clés doit autoriser CloudTrail l'utilisation de la clé pour chiffrer vos fichiers journaux et vos fichiers de valeur de hachage, et autoriser les utilisateurs que vous indiquez à lire les fichiers journaux ou à digérer les fichiers sous forme non chiffrée. Pour en savoir plus sur la modification manuelle de la politique de clés, consultez Configurer les politiques AWS KMS clés pour CloudTrail.
-
Sous Paramètres supplémentaires, configurez les événements suivants.
-
Sous Validation du fichier journal, choisissez Activé pour que les fichiers de valeur de hachage soient livrés dans votre compartiment S3. Vous pouvez utiliser les fichiers de valeur de hachage pour vérifier que vos fichiers journaux n'ont pas changé après leur CloudTrail livraison. Pour de plus amples informations, veuillez consulter Validation de l' CloudTrail intégrité du fichier journal.
-
Pour la livraison de notifications SNS, choisissez Enabled (Activé) pour recevoir une notification chaque fois qu'un journal est livré dans votre compartiment. CloudTrail stocke plusieurs événements dans un fichier journal. Des notifications SNS sont envoyées pour chaque fichier journal, non pour chaque événement. Pour plus d'informations, consultez Configuration des notifications Amazon SNS pour CloudTrail.
Si vous activez les notifications SNS, pour Créer une nouvelle rubrique SNS, choisissez Nouveau pour créer une rubrique, ou Existant, pour utiliser une rubrique existante. Si vous créez un journal de suivi multi-régions, les notifications SNS relatives à la livraison de fichiers journaux de toutes les régions activées sont envoyées à la rubrique SNS unique que vous créez.
Si vous choisissez New (Nouveau), CloudTrail spécifie un nom pour la nouvelle rubrique ou vous pouvez taper un nom vous-même. Si vous choisissez Existant, choisissez une rubrique SNS dans la liste déroulante. Vous pouvez également saisir l'ARN d'une rubrique provenant d'une autre région ou d'un compte disposant des autorisations appropriées. Pour plus d'informations, consultez Politique relative aux rubriques Amazon SNS pour CloudTrail.
Si vous créez une rubrique, vous devez vous abonner à la rubrique pour être averti de l'envoi de fichiers journaux. Vous pouvez vous abonner à partir de la console Amazon SNS. En raison de la fréquence des notifications, nous vous recommandons de configurer l'abonnement pour pouvoir utiliser une file d'attente Amazon SQS afin de gérer les notifications par programmation. Pour plus d'informations, consultez Prise en main d'Amazon SNS dans le Guide du développeur Amazon Simple Notification Service.
-
-
Vous pouvez éventuellement configurer CloudTrail pour envoyer des fichiers CloudWatch journaux à Logs en choisissant Enabled in CloudWatch Logs. Pour de plus amples informations, veuillez consulter Envoi d'événements à CloudWatch Logs.
-
Si vous activez l'intégration avec CloudWatch les journaux, choisissez New (Nouveau) pour créer un nouveau groupe de journaux, ou Existing (Existant) pour utiliser un groupe existant. Si vous choisissez New (Nouveau), CloudTrail spécifie un nom pour le nouveau groupe de journaux, ou vous pouvez taper un nom vous-même.
-
Si vous choisissez Existant, choisissez un groupe de journaux dans la liste déroulante.
-
Choisissez New (Nouveau) pour créer un nouveau rôle IAM pour obtenir les autorisations d'envoyer des CloudWatch journaux à Logs. Choisir Existant pour choisir un rôle IAM existant dans la liste déroulante. L’instruction de politique pour le rôle nouveau ou existant s’affiche lorsque vous déroulez Document de politique. Pour plus d'informations sur ce rôle, consultez Document de politique de rôle pour l'utilisation CloudTrail des CloudWatch journaux à des fins de surveillance.
Note
-
Lorsque vous configurez un journal de suivi, vous pouvez choisir un compartiment S3 et une rubrique SNS qui appartiennent à un autre compte. Toutefois, si vous souhaitez CloudTrail transmettre des événements à un groupe de CloudWatch journaux journaux, vous devez choisir un groupe de journaux qui existe dans votre compte actuel.
Seul le compte de gestion peut configurer un groupe de CloudWatch journaux journaux pour un journal de suivi d'organisation en utilisant la console. L'administrateur délégué peut configurer un groupe de CloudWatch journaux Logs à l'aide des opérations AWS CLI CloudTrail
CreateTrailou deUpdateTraill'API.
-
-
-
Sous Tags (Identifications), vous pouvez ajouter jusqu'à 50 paires clé-valeur d'identifications pour vous aider à identifier, trier et contrôler l'accès à votre journal d'activité. Les identifications peuvent vous aider à identifier à la CloudTrail fois vos journaux de suivi et les compartiments Amazon S3 contenant des fichiers CloudTrail journaux. Vous pouvez ensuite utiliser les groupes de ressources pour vos CloudTrail ressources. Pour plus d’informations, consultez AWS Resource Groups et Balises.
-
Sur la page Choisir des événements du journal, choisissez les types d’événements que vous souhaitez consigner. Sous Événements de gestion, procédez comme suit.
-
Pour Activité d’API, indiquez si vous souhaitez que votre journal de suivi journalise les événements en événements Lecture ou en événements Écriture, ou les deux. Pour de plus amples informations, veuillez consulter Événements de gestion.
-
Choisissez Exclude (Exclure AWS KMS) des AWS KMS événements pour filtrer les événements AWS Key Management Service () de votre journal d'activité. Le paramètre par défaut consiste à inclure tous les AWS KMS événements.
L'option de journalisation ou d'exclusion AWS KMS des événements n'est disponible que si vous journalisez les événements de gestion sur votre journal de suivi. Si vous choisissez de ne pas journaliser les événements de gestion, les AWS KMS événements ne sont pas journalisés, et vous ne pouvez pas modifier paramètres de journalisation des AWS KMS événements.
AWS KMS actions telles que
EncryptDecrypt, et génèrentGenerateDataKeygénéralement un volume important (plus de 99 %) d'événements. Ces actions sont désormais journalisées en tant qu’événements Lecture. Les AWS KMS actions pertinentes de faible volume, telles queDisableDelete, etScheduleKey(qui représentent généralement moins de 0,5 % du volume des événements) sont journalisées en tant qu' AWS KMS événements Write (Écriture).Pour exclure les événements de volume important tels que
Encrypt, etDecryptGenerateDataKey, tout en continuant de journaliser les événements pertinents tels queDisable,DeleteetScheduleKey, choisissez de journaliser les événements de gestion Write (Écriture) et effacez la case à cocher pour Exclure les AWS KMS événements. -
Choisissez Exclure les événements API de données Amazon RDS pour filtrer les événements d’API de données Amazon Relational Database Service Data hors de votre journal de suivi. Le paramètre par défaut consiste à inclure tous les événements d'API de données Amazon RDS. Pour plus d’informations sur les événements d’API Amazon RDS Data API, consultez Journalisation des appels d’API de données avec AWS CloudTrail dans le Guide de l’utilisateur Amazon RDS pour Aurora.
-
-
Pour journaliser les événements de données, choisissez Événements de données. Des frais supplémentaires s'appliquent pour la journalisation des événements de données. Pour plus d’informations, consultez Tarification d’AWS CloudTrail
. -
Important
Les étapes 12 à 16 concernent la configuration des événements de données à l'aide de sélecteurs d'événements avancés, ce qui est le cas par défaut. Les sélecteurs d'événements avancés vous permettent de configurer davantage de types de ressources et de contrôler avec précision les événements de données capturés par votre journal de suivi. Si vous avez choisi d'utiliser des sélecteurs d'événements de base, suivez les étapes décrites dans Configurer les paramètres des événements de données à l’aide de sélecteurs d’événements de base, puis revenez à l'étape 17 de cette procédure.
Pour Type de ressource, choisissez le type de ressource sur lequel vous souhaitez journaliser les événements de données. Pour plus d'informations sur les types de ressources disponibles, consultezÉvénements de données.
-
Choisissez un modèle de sélecteur de journal. Vous pouvez choisir un modèle prédéfini ou choisir Personnalisé pour définir vos propres conditions de collecte d'événements.
Sélectionnez parmi les modèles prédéfinis suivants :
-
Enregistrer tous les événements : choisissez ce modèle pour enregistrer tous les événements.
-
Consigner uniquement les événements en lecture : choisissez ce modèle pour enregistrer uniquement les événements en lecture. Les événements en lecture seule sont des événements qui ne modifient pas l'état d'une ressource, tels que les
Get*événements.Describe* -
Enregistrer uniquement les événements d'écriture : choisissez ce modèle pour consigner uniquement les événements d'écriture. Les événements d'écriture ajoutent, modifient ou suppriment des ressources, des attributs ou des artefacts, tels que les événements
Put*,Delete*, ouWrite*. -
Enregistrer uniquement AWS Management Console les événements : choisissez ce modèle pour enregistrer uniquement les événements provenant du AWS Management Console.
-
Exclure les événements Service AWS initiés : choisissez ce modèle pour exclure les Service AWS événements dotés d'un caractère
eventTypede etAwsServiceEventles événements initiés avec des rôles Service AWS liés à -linked (SLRs).
Note
Le fait de choisir un modèle prédéfini pour les compartiments S3 active la journalisation des événements de données pour tous les compartiments actuellement dans votre AWS compte, ainsi que pour tous les compartiments que vous pourriez définir après la création du journal de suivi. Cela active également la journalisation de l'activité des événements de données effectuée par n'importe quelle identité IAM de votre AWS compte, même si cette activité est effectuée sur un compartiment qui appartient à un autre AWS compte.
Si le journal de suivi s’applique à une seule région, le fait de choisir un modèle prédéfini qui journalise tous les compartiments S3 permet la journalisation des événements de données pour tous les compartiments situés dans la même région que votre journal de suivi et tous les compartiments que vous créerez ultérieurement dans cette région. Il ne va pas journaliser pas d'événements de données pour les compartiments Amazon S3 situés dans d'autres régions de votre AWS compte.
Si vous créez un journal de suivi multirégion, le fait de choisir un modèle prédéfini pour les fonctions Lambda active la journalisation des événements de données pour toutes les fonctions se trouvant actuellement dans AWS votre compte et pour toute fonction Lambda que vous êtes susceptible de créer dans n'importe quelle région après avoir achevé la création du journal de suivi. Si vous créez un journal de suivi pour une région unique, (en utilisant le AWS CLI), cette sélection active la journalisation des événements de données pour toutes les fonctions de cette région se trouvant actuellement dans votre AWS compte et pour toute fonction Lambda que vous êtes susceptible de créer dans cette région après avoir achevé la création du journal de suivi. Cela n’active pas la journalisation des événements de données pour les fonctions Lambda créées dans d’autres régions.
La journalisation des événements de données pour toutes les fonctions active également la journalisation de l'activité des événements de données effectuée par n'importe quelle identité IAM de votre AWS compte, même si cette activité est effectuée sur une fonction qui appartient à un autre AWS compte.
-
-
(Facultatif) Dans Nom du sélecteur, saisissez un nom pour identifier votre sélecteur. Le nom du sélecteur est un nom descriptif pour un sélecteur d'événements avancé, tel que « Journaliser les événements de données pour deux compartiments S3 uniquement ». Le nom du sélecteur est répertorié comme
Namedans le sélecteur d'événements avancé et est visible si vous développez la Vue JSON. -
Si vous avez sélectionné Personnalisé, dans les sélecteurs d'événements avancés, créez une expression basée sur les valeurs des champs des sélecteurs d'événements avancés.
Note
Les sélecteurs ne prennent pas en charge l'utilisation de caractères génériques tels que.
*Pour associer plusieurs valeurs à une seule condition, vous pouvez utiliserStartsWith,EndsWithNotStartsWith, ouNotEndsWithfaire correspondre explicitement le début ou la fin du champ d'événement.-
Choisissez parmi les options suivantes.
-
readOnly-readOnlypeut être défini pour être égal à une valeur detrueoufalse. Les événements de données en lecture seule sont des événements qui ne modifient pas l'état d'une ressource, tels que les événementsGet*ouDescribe*. Les événements d'écriture ajoutent, modifient ou suppriment des ressources, des attributs ou des artefacts, tels que les événementsPut*,Delete*, ouWrite*. Pour journaliser les deux événementsreadetwrite, n'ajoutez pas de sélecteurreadOnly. -
eventName-eventNamepeut utiliser n’importe quel opérateur. Vous pouvez l'utiliser pour inclure ou exclure tout événement de données enregistré CloudTrail, tel quePutBucketGetItem, ouGetSnapshotBlock. -
eventSource— La source de l'événement à inclure ou à exclure. Ce champ peut utiliser n'importe quel opérateur. -
EventType — Type d'événement à inclure ou à exclure. Par exemple, vous pouvez définir ce champ sur une valeur différente
AwsServiceEventpour l'exclureService AWS événements. Pour une liste des types d'événements, voir eventTypedansCloudTrail enregistrer le contenu des événements relatifs à la gestion, aux données et à l'activité du réseau. -
sessionCredentialFromConsole — Incluez ou excluez les événements issus d'une AWS Management Console session. Ce champ peut être défini sur égal ou non égal avec une valeur de
true. -
UserIdentity.ARN — Incluez ou excluez des événements pour les actions entreprises par des identités IAM spécifiques. Pour de plus amples informations, veuillez consulter Élément CloudTrail userIdentity.
-
resources.ARN- Vous pouvez utiliser n'importe quel opérateurresources.ARN, mais si vous utilisez égal ou non, la valeur doit correspondre exactement à l'ARN d'une ressource valide du type que vous avez spécifié dans le modèle comme valeur deresources.type.Note
Vous ne pouvez pas utiliser le
resources.ARNchamp pour filtrer les types de ressources qui n'en ont pas ARNs.Pour plus d'informations sur les formats ARN des ressources d'événements de données, consultez Actions, ressources et clés de condition Services AWS dans le Guide d'autorisation de service.
-
-
Pour chaque champ, choisissez + Conditions pour ajouter autant de conditions que vous le souhaitez, jusqu'à un maximum de 500 valeurs spécifiées pour toutes les conditions. Par exemple, pour exclure les événements de données de deux compartiments S3 des événements de données journalisés sur votre entrepôt de données d'événement (il est possible de définir le champ sur Ressources ARN), définissez l'opérateur sur Ne commence pas par, puis collez dans un ARN de compartiment S3 pour lequel vous ne souhaitez pas journaliser les événements.
Pour ajouter le deuxième compartiment S3, choisissez + Conditions, puis répétez l'instruction précédente, en collant dans l'ARN ou en recherchant un compartiment différent.
Pour plus d'informations sur le mode CloudTrail d'évaluation de plusieurs conditions, consultezComment CloudTrail évaluer plusieurs conditions pour un champ.
Note
Il est possible de définir un maximum de 500 valeurs pour tous les sélecteurs d'un entrepôt de données d'événement. Cela inclut des tableaux de valeurs multiples pour un sélecteur tel que
eventName. Si vous avez défini des valeurs uniques pour tous les sélecteurs, il est possible d’ajouter un maximum de 500 conditions à un sélecteur. -
Choisir + champ pour ajouter des champs supplémentaires au besoin. Pour éviter les erreurs, il convient de ne pas définir de valeurs conflictuelles ou en double pour les champs. Par exemple, ne spécifiez pas un ARN dans un sélecteur pour être égal à une valeur, puis spécifiez que l'ARN n'est pas égal à la même valeur dans un autre sélecteur.
-
-
Pour ajouter un autre type de ressource sur lequel journaliser les événements de données, choisissez Ajouter un type d'événement de données. Répétez les étapes 12 à cette étape pour configurer les sélecteurs d'événements avancés pour le type de ressource.
-
Pour enregistrer les événements d'activité réseau, sélectionnez Événements d'activité réseau. Les événements d'activité réseau permettent aux propriétaires de points de terminaison VPC d'enregistrer les appels d' AWS API effectués à l'aide de leurs points de terminaison VPC depuis un VPC privé vers le. Service AWS Des frais supplémentaires s'appliquent pour la journalisation des événements d'activité sur le réseau. Pour plus d’informations, consultez Tarification d’AWS CloudTrail
. Pour journaliser les événements d'activité du réseau, procédez comme suit :
-
Dans Source des événements d'activité réseau, choisissez la source des événements d'activité réseau.
-
Dans Modèle de sélecteur de journaux, choisissez un modèle. Vous pouvez choisir de consigner tous les événements liés à l'activité réseau, de consigner tous les événements liés à l'activité réseau auxquels l'accès est refusé ou de choisir Personnaliser pour créer un sélecteur de journal personnalisé afin de filtrer sur plusieurs champs, tels que
eventNameetvpcEndpointId. -
(Facultatif) Saisissez un nom pour identifier le sélecteur. Le nom du sélecteur est répertorié comme Name dans le sélecteur d'événements avancé et est visible si vous développez la Vue JSON.
-
Dans les sélecteurs d'événements avancés, les sélecteurs créent des expressions en choisissant des valeurs pour Champ, Opérateur et Valeur. Vous pouvez ignorer cette étape si vous utilisez un modèle de journal prédéfini.
-
Pour exclure ou inclure les événements d'activité réseau, vous pouvez choisir l'un des champs suivants de la console.
-
eventName— Vous pouvez utiliser n'importe quel opérateur aveceventName. Vous pouvez l'utiliser pour inclure ou exclure tout événement, tel queCreateKey. -
errorCode— Vous pouvez l'utiliser pour filtrer un code d'erreur. Actuellement, le seul pris en chargeerrorCodeestVpceAccessDenied. -
vpcEndpointId— Identifie le point de terminaison VPC par lequel l'opération est passée. Vous pouvez utiliser n'importe quel opérateur avecvpcEndpointId.
-
-
Pour chaque champ, choisissez + Conditions pour ajouter autant de conditions que vous le souhaitez, jusqu'à un maximum de 500 valeurs spécifiées pour toutes les conditions.
-
Choisir + champ pour ajouter des champs supplémentaires au besoin. Pour éviter les erreurs, il convient de ne pas définir de valeurs conflictuelles ou en double pour les champs.
-
-
Pour ajouter une autre source d'événements pour laquelle vous souhaitez enregistrer les événements d'activité réseau, choisissez Ajouter un sélecteur d'événements d'activité réseau.
-
Vous pouvez également développer Affichage JSON pour afficher vos sélecteurs d’événements avancés sous forme de bloc JSON.
-
-
Choisissez Insights events (Événements Insights) si vous souhaitez que votre journal de suivi journalise CloudTrail les événements Insights.
Dans Type d’événement, sélectionnez Événements Insights. Vous devez journaliser les événements de gestion Écriture pour journaliser les événements Insights afin de connaître le Taux d'appels d'API. Vous devez journaliser les événements de gestion Lecture ou Écriture pour journaliser les événements Insights afin de connaître le Taux d'erreur de l'API.
CloudTrail Insights analyse les événements de gestion pour une activité inhabituelle, et consigne les événements lorsque des anomalies sont détectées. Par défaut, les journaux de suivi ne journalisent pas les événements Insights. Pour plus d'informations sur les événements Insights, consultez Travailler avec CloudTrail Insights. Des frais supplémentaires s’appliquent pour la journalisation des événements Insights. Pour les CloudTrail tarifs, consultez la section AWS CloudTrail Tarification
. Les événements Insights sont envoyés dans un autre dossier nommé
/CloudTrail-Insightdans le même compartiment S3 spécifié dans la zone Emplacement de stockage de la page de détails du journal de suivi. CloudTrailcrée le nouveau préfixe pour vous. Par exemple, si votre compartiment S3 de destination actuel se nommeamzn-s3-demo-bucket/AWSLogs/CloudTrail/, le nom du compartiment S3 avec un nouveau préfixe se nommeraamzn-s3-demo-bucket/AWSLogs/CloudTrail-Insight/. -
Après avoir sélectionné les types d’événements à journaliser, choisissez Suivant.
-
Sur la page Vérifier et créer, vérifiez vos choix. Choisissez Modifier dans une section pour modifier les paramètres de journal de suivi affichés dans cette section. Lorsque vous êtes prêt à créer votre journal de suivi, choisissez Créer un journal de suivi.
-
Le nouveau journal de suivi s’affiche sur la page Journaux de suivi. Après cinq minutes environ, CloudTrail publie les fichiers journaux qui répertorient les appels d' AWS API effectués dans votre compte. Les fichiers journaux se trouvent dans le compartiment S3 que vous avez spécifié.
Si vous avez activé les événements Insights pour un parcours, le lancement de ces événements CloudTrail peut prendre jusqu'à 36 heures, à condition qu'une activité inhabituelle soit détectée pendant cette période.
Note
CloudTrail livre généralement des journaux dans un délai moyen d'environ cinq minutes après un appel d'API. Ce délai n’est pas garanti. Pour plus d’informations, consultez le Contrat de niveau de service (SLA)AWS CloudTrail
. Si vous configurez mal votre journal de suivi (par exemple, si le compartiment S3 est inaccessible), CloudTrail tentera de retransmettre les fichiers journaux à votre compartiment S3 pendant 30 jours, et ces attempted-to-deliver événements seront soumis aux frais standard. CloudTrail Pour éviter des frais sur un journal de suivi mal configuré, vous devez supprimer le journal de suivi.
Configurer les paramètres des événements de données à l’aide de sélecteurs d’événements de base
Vous pouvez utiliser des sélecteurs d'événements avancés pour configurer tous les types d'événements de données ainsi que les événements liés à l'activité du réseau. Les sélecteurs d'événements avancés vous permettent de créer des sélecteurs précis pour enregistrer uniquement les événements qui vous intéressent.
Si vous utilisez des sélecteurs d'événements de base pour journaliser les événements de données, vous êtes limité à la journalisation des événements de données pour les compartiments Amazon S3, les AWS Lambda fonctions et les tables Amazon DynamoDB. Vous ne pouvez pas filtrer sur le eventName terrain à l'aide de sélecteurs d'événements de base. Vous ne pouvez pas non plus enregistrer les événements liés à l'activité du réseau.
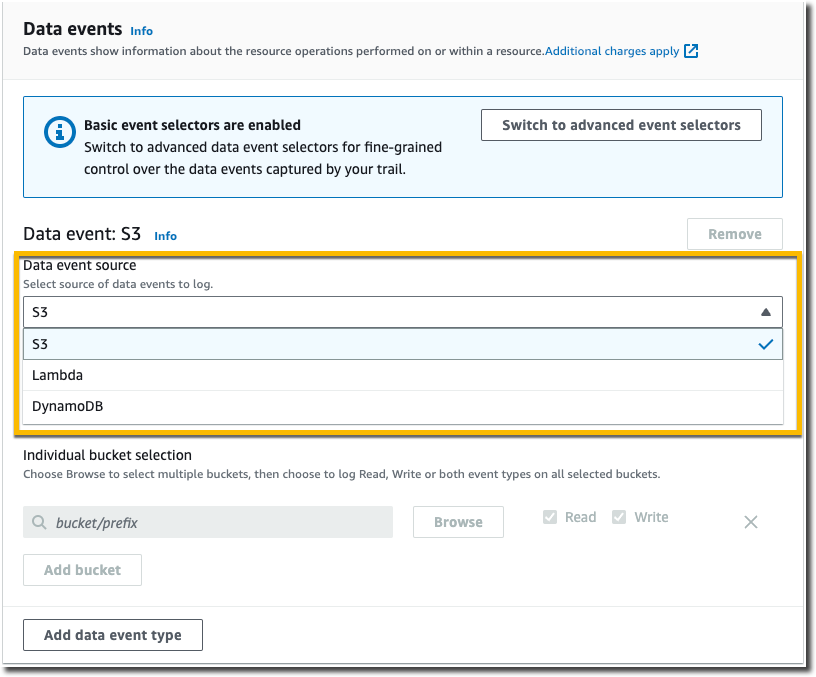
Utilisez la procédure suivante afin de configurer les paramètres des événements de données à l'aide de sélecteurs d'événements de base.
Pour configurer les paramètres des événements de données à l'aide de sélecteurs d'événements de base
-
Dans Événements, sélectionnez Événements de données pour journaliser les événements de données. Des frais supplémentaires s'appliquent pour la journalisation des événements de données. Pour plus d’informations, consultez Tarification d’AWS CloudTrail
. -
Pour les compartiments Amazon S3 :
-
Pour Data event source (Source d'événements de données), choisissez S3.
-
Il est possible de choisir de journaliser Tous les compartiments S3 actuels et futurs ou de spécifier des compartiments ou fonctions individuels. Par défaut, les événements de données sont journalisés pour tous les compartiments S3 actuels et futurs.
Note
Le fait de maintenir l'option par défaut Tous les compartiments S3 actuels et futurs active la journalisation des événements de données pour tous les compartiments actuellement dans votre AWS compte, ainsi que pour tous les compartiments que vous pourriez créer après la création du journal d'activité. Cela active également la journalisation de l'activité des événements de données effectuée par n'importe quelle identité IAM de votre AWS compte, même si cette activité est effectuée sur un compartiment qui appartient à un autre AWS compte.
Si vous créez un journal de suivi qui s'applique à une région unique, (en utilisant le AWS CLI), le fait de sélectionner l'option Select all S3 buckets in your account (Sélectionner tous les compartiments S3 de votre compte) permet de journaliser les événements de données pour tous les compartiments situés dans la même région que votre journal de suivi et tous les compartiments que vous créerez ultérieurement dans cette région. Il ne va pas journaliser pas d'événements de données pour les compartiments Amazon S3 situés dans d'autres régions de votre AWS compte.
-
Si vous laissez l’option par défaut, Tous les compartiments S3 actuels et futurs, choisissez de journaliser les événements de lecture, les événements d’écriture, ou les deux.
-
Pour sélectionner des compartiments individuels, il convient de vider les boîtes de dialogue Lecture et Écriture pour Tous les compartiments S3 actuels et futurs. Dans Sélection du compartiment individuel, recherchez un compartiment sur lequel journaliser les événements de données. Recherchez des compartiments spécifiques en tapant un préfixe de compartiment pour le compartiment souhaité. Vous pouvez sélectionner plusieurs compartiments dans cette fenêtre. Choisissez Ajouter un compartiment pour journaliser les événements de données pour d’autres compartiments. Choisissez de journaliser les événements Lecture tels que
GetObject, les événements Écriture tels quePutObject, ou les deux.Ce paramètre est prioritaire par rapport aux paramètres que vous définissez pour les compartiments individuels. Par exemple, si vous spécifiez la journalisation des événements Read (Lecture) pour tous les compartiments S3, puis choisissez d'ajouter un compartiment spécifique pour la journalisation des événements de données, Read (Lecture) est déjà sélectionné pour le compartiment que vous avez ajouté. Vous ne pouvez pas effacer la sélection. Vous pouvez uniquement configurer l’option pour Écriture.
Pour supprimer un compartiment de la journalisation, choisissez X.
-
-
Pour ajouter un autre type de ressource sur lequel journaliser les événements de données, choisissez Ajouter un type d'événement de données.
-
Pour les fonctions Lambda :
-
Pour Data event source (Source d'événement de données), choisissez Lambda.
-
Dans Fonction Lambda, choisissez Toutes les régions pour journaliser toutes les fonctions Lambda, ou Fonction d’entrée en tant qu’ARN, pour consigner les événements de données sur une fonction spécifique.
Pour consigner les événements de données de toutes les fonctions Lambda de votre AWS compte, sélectionnez Log all current and future functions (Journaliser tous les fonctions actuelles et futures). Ce paramètre est prioritaire par rapport aux paramètres que vous définissez pour les fonctions individuelles. Toutes les fonctions sont journalisées, même si elles ne sont pas toutes affichées.
Note
Si vous créez un journal de suivi multirégional, cette sélection active la journalisation des événements de données pour toutes les fonctions se trouvant actuellement dans votre AWS compte et pour toute fonction Lambda que vous êtes susceptible de créer dans n'importe quelle région après avoir achevé la création du journal de suivi. Si vous créez un journal de suivi pour une région unique, (en utilisant le AWS CLI), cette sélection active la journalisation des événements de données pour toutes les fonctions de cette région se trouvant actuellement dans votre AWS compte et pour toute fonction Lambda que vous êtes susceptible de créer dans cette région après avoir achevé la création du journal de suivi. Cela n’active pas la journalisation des événements de données pour les fonctions Lambda créées dans d’autres régions.
La journalisation des événements de données pour toutes les fonctions active également la journalisation de l'activité des événements de données effectuée par n'importe quelle identité IAM de votre AWS compte, même si cette activité est effectuée sur une fonction qui appartient à un autre AWS compte.
-
Si vous choisissez Fonction d’entrée en tant qu’ARN, saisissez l’ARN d’une fonction Lambda.
Note
Si vous disposez de plus de 15 000 fonctions Lambda dans votre compte, il n'est pas possible de voir ou de sélectionner toutes les fonctions dans la CloudTrail console lors de la création d'un journal de suivi. Vous pouvez toujours sélectionner l’option de journalisation de toutes les fonctions, même si elles ne sont pas affichées. Si vous souhaitez journaliser les événements de données de fonctions spécifiques, vous pouvez ajouter manuellement une fonction si vous connaissez son ARN. Vous pouvez également terminer la création du journal de suivi dans la console, puis utiliser la AWS CLI et la pour configurer la put-event-selectors journalisation d'événements de données pour des fonctions Lambda spécifiques. Pour de plus amples informations, veuillez consulter Gérer les sentiers avec le AWS CLI.
-
-
Pour Tables DynamoDB :
-
Pour Data event source (Source d'événement de données), choisissez DynamoDB.
-
Dans Sélection d’une table DynamoDB, choisissez Parcourir pour sélectionner une table ou coller dans l’ARN d’une table DynamoDB à laquelle vous avez accès. Un ARN de table DynamoDB utilise le format suivant :
arn:partition:dynamodb:region:account_ID:table/table_namePour ajouter une autre table, choisissez Ajouter une ligne, puis recherchez un tableau ou collez dans l’ARN d’une table à laquelle vous avez accès.
-
-
Pour configurer les événements Insights et d’autres paramètres pour votre piste, revenez à la procédure précédente dans cette rubrique, Créer un journal d'activité à l'aide de la console.
Étapes suivantes
Après avoir créé le journal de suivi, vous pouvez le modifier:
-
Si vous ne l'avez pas encore fait, vous pouvez configurer CloudTrail pour qu'il envoie les fichiers CloudWatch journaux à Logs. Pour de plus amples informations, veuillez consulter Envoi d'événements à CloudWatch Logs.
-
Créez une table et utilisez-la pour exécuter une requête dans Amazon Athena afin d'analyser l'activité de vos services AWS . Pour plus d'informations, consultez la section Création d'une table pour les CloudTrail journaux dans la CloudTrail console dans le guide de l'utilisateur d'Amazon Athena.
-
Ajoutez des identifications personnalisées (paires clé-valeur) pour le journal de suivi.
-
Pour créer un autre journal de suivi, ouvrez la page Journaux de suivi et choisissez Créer un journal de suivi.
