Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Procédure de traitement par Lambda des enregistrements provenant de sources d’événements basées sur des flux et des files d’attente
Un mappage des sources d’événements est une ressource Lambda qui lit des éléments à partir de services basés sur des flux et des files d’attente et qui invoque une fonction avec des lots d’enregistrements. Dans le cadre d’un mappage des sources d’événements, des ressources appelées sondeurs d’événements interrogent activement les nouveaux messages et invoquent des fonctions. Par défaut, Lambda adapte automatiquement les sondeurs d’événements, mais pour certains types de sources d’événements, vous pouvez utiliser le mode alloué pour contrôler le nombre minimum et maximum de sondeurs d’événements dédiés votre mappage des sources d’événements.
Les services suivants utilisent des mappages des sources d’événements pour invoquer des fonctions Lambda :
Avertissement
Les mappages des sources d’événements Lambda traitent chaque événement au moins une fois, et le traitement des enregistrements peut être dupliqué. Pour éviter les problèmes potentiels liés à des événements dupliqués, nous vous recommandons vivement de rendre votre code de fonction idempotent. Pour en savoir plus, consultez Comment rendre ma fonction Lambda idempotente
Différence entre les mappages de sources d’événements et les déclencheurs directs
Certains Services AWS peuvent appeler directement des fonctions Lambda à l'aide de déclencheurs. Ces services envoient des événements à Lambda, et la fonction est invoquée aussitôt que l’événement spécifié se produit. Les déclencheurs sont adaptés aux événements discrets et au traitement en temps réel. Lorsque vous créez un déclencheur à l'aide de la console Lambda, celle-ci interagit avec le AWS service correspondant pour configurer la notification d'événement sur ce service. Le déclencheur est en fait stocké et géré par le service qui génère les événements, et non par Lambda. Voici quelques exemples de services qui utilisent des déclencheurs pour invoquer des fonctions Lambda :
-
Amazon Simple Storage Service (Amazon S3) : invoque une fonction lorsqu’un objet est créé, supprimé ou modifié dans un compartiment. Pour de plus amples informations, veuillez consulter Didacticiel : utilisation d’un déclencheur Amazon S3 pour invoquer une fonction Lambda.
-
Amazon Simple Notification Service (Amazon SNS) : invoque une fonction lorsqu’un message est publié dans une rubrique SNS. Pour de plus amples informations, veuillez consulter Tutoriel : Utilisation AWS Lambda avec Amazon Simple Notification Service.
-
Amazon API Gateway : invoque une fonction lorsqu’une requête d’API est envoyée à un point de terminaison spécifique. Pour de plus amples informations, veuillez consulter Invocation d’une fonction Lambda à l’aide d’un point de terminaison Amazon API Gateway.
Les mappages des sources d’événements sont des ressources Lambda créées et gérées au sein du service Lambda. Les mappages des sources d’événements sont conçus pour traiter de gros volumes de données en streaming ou de messages provenant de files d’attente. Le traitement par lots des enregistrements d’un flux ou d’une file d’attente est plus efficace que le traitement individuel des enregistrements.
Comportement de traitement par lots
Par défaut, un mappage de source d’événements regroupe des enregistrements dans une même charge utile que Lambda envoie à votre fonction. Pour affiner le comportement du traitement par lots, vous pouvez configurer une fenêtre de traitement par lots (MaximumBatchingWindowInSeconds) et une taille de lot (BatchSize). Une fenêtre de traitement par lots représente l’intervalle de temps maximal pour collecter des enregistrements dans une même charge utile. La taille d’un lot est le nombre maximal d’enregistrements dans un même lot. Lambda invoque votre fonction en présence de l’un des trois critères suivants :
-
La fenêtre de traitement par lots atteint sa valeur maximale. Le comportement par défaut de la fenêtre de traitement par lots varie selon la source d’événement spécifique.
Pour les sources d’événements Kinesis, DynamoDB et Amazon SQS : la fenêtre de traitement par lot par défaut est de 0 seconde. Cela signifie que Lambda invoque votre fonction dès que des enregistrements sont disponibles. Pour définir une fenêtre de traitement par lots, configurez
MaximumBatchingWindowInSeconds. Vous pouvez configurer ce paramètre à n’importe quelle valeur comprise entre 0 et 300 secondes par incréments d’1 seconde. Si vous configurez une fenêtre de traitement par lots, la fenêtre suivante commence dès que l’invocation de fonction précédente est terminée.Pour les sources d’événements Amazon MSK, Apache Kafka autogérées, Amazon MQ et Amazon DocumentDB : la fenêtre de traitement par lots par défaut est de 500 ms. Vous pouvez configurer
MaximumBatchingWindowInSecondsà n’importe quelle valeur comprise entre 0 et 300 secondes par incréments de secondes. En mode provisionné pour les mappages des sources d’événements Kafka, lorsque vous configurez une fenêtre de traitement par lots, la fenêtre suivante commence dès que le lot précédent est terminé. Dans les mappages des sources d’événements Kafka non provisionnés, si vous configurez une fenêtre de traitement par lots, la fenêtre suivante commence dès que l’invocation de fonction précédente est terminée. Pour minimiser la latence lors de l’utilisation des mappages des sources d’événements Kafka en mode provisionné, définissezMaximumBatchingWindowInSecondssur 0. Ce paramètre garantit que Lambda commencera à traiter le lot suivant immédiatement après avoir terminé l’invocation de fonction en cours. Pour plus d’informations sur le traitement à faible latence, consultez Apache Kafka à faible latence.-
Pour les sources d’événements Amazon MQ et Amazon DocumentDB : la fenêtre de traitement par lots par défaut est de 500 ms. Vous pouvez configurer
MaximumBatchingWindowInSecondsà n’importe quelle valeur comprise entre 0 et 300 secondes par incréments de secondes. Une fenêtre de traitement par lots commence dès l’arrivée du premier registre.Note
Étant donné que vous ne pouvez modifier
MaximumBatchingWindowInSecondsque par incréments de secondes, vous ne pouvez pas revenir à la fenêtre de traitement par lots par défaut de 500 ms après l’avoir modifiée. Pour restaurer la fenêtre de traitement par lots par défaut, vous devez créer un mappage de source d’événement.
-
La taille du lot est atteinte. La taille minimale du lot est de 1. La taille par défaut et la taille maximale du lot dépendent de la source d’événement. Pour plus d’informations sur ces valeurs, consultez la spécification BatchSize pour l’opération de l’API
CreateEventSourceMapping. -
La taille de la charge utile atteint 6 Mo. Vous ne pouvez pas modifier cette limite.
Le diagramme suivant illustre ces trois conditions. Supposons qu’une fenêtre de traitement par lots commence à t = 7 secondes. Dans le premier scénario, la fenêtre de traitement par lots atteint son maximum de 40 secondes à t = 47 secondes après avoir accumulé 5 enregistrements. Dans le second scénario, la taille du lot atteint 10 avant l’expiration de la fenêtre de traitement par lots, de sorte que la fenêtre de traitement par lots se termine plus tôt. Dans le troisième scénario, la taille maximale de la charge utile est atteinte avant l’expiration de la fenêtre de traitement par lots, de sorte que la fenêtre de traitement par lots se termine plus tôt.
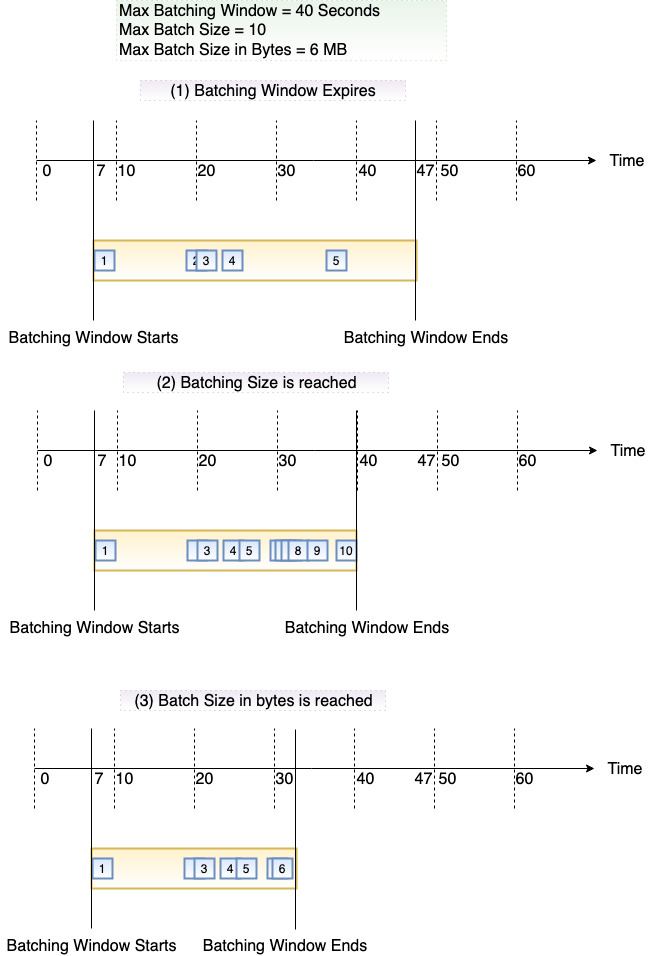
Nous vous recommandons de tester différentes tailles de lots et d’enregistrements afin que la fréquence d’interrogation de chaque source d’événement soit adaptée à la rapidité avec laquelle votre fonction est en mesure d’accomplir sa tâche. Le CreateEventSourceMappingBatchSizeparamètre contrôle le nombre maximum d'enregistrements qui peuvent être envoyés à votre fonction à chaque appel. Une taille de lot plus grande peut souvent absorber plus efficacement l’invocation sur un plus large ensemble d’enregistrements, ce qui accroît votre débit.
Lambda envoi le prochain lot pour traitement sans attendre que les extensions configurées soient terminées. En d’autres termes, vos extensions peuvent continuer à s’exécuter pendant que Lambda traite le prochain lot d’enregistrements. Cela peut causer des problèmes de limitation si vous enfreignez l’un des paramètres ou l’une des limites de simultanéité de votre compte. Pour détecter s’il s’agit d’un problème éventuel, surveillez vos fonctions et vérifiez si vous observez des métriques de simultanéité plus élevées que prévu pour votre mappage des sources d’événements. En raison de la brièveté des intervalles entre les invocations, Lambda peut brièvement signaler une utilisation simultanée supérieure au nombre de partitions. Cela peut être vrai même pour les fonctions Lambda sans extensions.
Par défaut, si votre fonction renvoie une erreur, le mappage de la source d’événements retraite l’ensemble du lot jusqu’à ce que la fonction réussisse ou que les éléments du lot arrivent à expiration. Pour s’assurer d’un traitement dans l’ordre, le mappage de la source d’événement met en pause le traitement dans la partition concernée jusqu’à la résolution de l’erreur. Pour les sources de flux (DynamoDB et Kinesis), vous pouvez configurer le nombre maximal de tentatives que Lambda effectue lorsque votre fonction renvoie une erreur. Les erreurs de service ou les limitations où le lot n’atteint pas votre fonction ne comptent pas dans les tentatives de réessai. Vous pouvez également configurer le mappage des sources d’événements pour qu’il envoie un enregistrement d’invocation à une destination lorsqu’il rejette un lot d’événements.
Mode alloué
Les mappages des sources d’événements Lambda utilisent des sondeurs d’événements pour interroger votre source d’événements à la recherche de nouveaux messages. Par défaut, Lambda gère le dimensionnement automatique de ces sondeurs en fonction du volume des messages. Lorsque le trafic de messages augmente, Lambda augmente automatiquement le nombre de sondeurs d’événements pour gérer la charge, et le réduit lorsque le trafic diminue.
En mode provisionné, vous pouvez affiner le débit du mappage de vos sources d'événements en définissant des limites minimales et maximales pour les ressources de sondage dédiées qui restent prêtes à gérer les modèles de trafic attendus. Ces ressources évoluent automatiquement 3 fois plus vite pour faire face aux pics soudains de trafic d'événements et fournissent une capacité 16 fois supérieure pour traiter des millions d'événements. Cela vous permet de créer des charges de travail hautement réactives axées sur les événements avec des exigences de performance strictes.
Dans Lambda, un sondeur d'événements est une unité de calcul dont les capacités de débit varient selon le type de source d'événements. Pour Amazon MSK et Apache Kafka autogéré, chaque sondeur d'événements peut gérer jusqu'à 5 % MB/sec du débit ou jusqu'à 5 appels simultanés. Par exemple, si votre source d'événement produit une charge utile moyenne de 1 Mo et que la durée moyenne de votre fonction est de 1 seconde, un seul sondeur d'événements Kafka peut prendre en charge 5 MB/sec débits et 5 appels Lambda simultanés (en supposant qu'il n'y ait aucune transformation de charge utile). Pour Amazon SQS, chaque sondeur d'événements peut gérer jusqu'à 1 % MB/sec du débit ou jusqu'à 10 appels simultanés. L'utilisation du mode provisionné entraîne des coûts supplémentaires en fonction de l'utilisation de votre sondeur d'événements. Pour plus d’informations sur la tarification, consultez Tarification AWS Lambda
Le mode provisionné est disponible pour les sources d'événements Amazon MSK, Apache Kafka autogérées et Amazon SQS. Alors que les paramètres de simultanéité vous permettent de contrôler la mise à l’échelle de votre fonction, le mode alloué vous permet de contrôler le débit de votre mappage des sources d’événements. Pour garantir des performances optimales, vous devrez peut-être ajuster les deux paramètres indépendamment.
Le mode provisionné est idéal pour les applications en temps réel nécessitant une latence constante pour le traitement des événements, telles que les sociétés de services financiers traitant les flux de données du marché, les plateformes de commerce électronique fournissant des recommandations personnalisées en temps réel et les sociétés de jeux gérant les interactions avec les joueurs en direct.
Chaque sondeur d'événements prend en charge une capacité de débit différente :
-
Pour Amazon MSK et Apache Kafka autogéré : jusqu'à 5 % MB/sec du débit ou jusqu'à 5 appels simultanés
-
Pour Amazon SQS : jusqu'à 1 % MB/sec de débit ou jusqu'à 10 appels simultanés ou jusqu'à 10 appels d'API d'interrogation SQS par seconde.
Pour les mappages de sources d'événements Amazon SQS, vous pouvez définir le nombre minimum de sondeurs entre 2 et 200 avec une valeur par défaut de 2, et le nombre maximum entre 2 et 2 000 avec une valeur par défaut de 200. Lambda adapte le nombre de sondeurs d'événements entre le minimum et le maximum configurés, en ajoutant rapidement jusqu'à 1 000 appels simultanés par minute afin de fournir un traitement cohérent et à faible latence de vos événements.
Pour les mappages de sources d'événements Kafka, vous pouvez définir le nombre minimum de sondeurs entre 1 et 200 avec une valeur par défaut de 1, et le nombre maximum entre 1 et 2 000 avec une valeur par défaut de 200. Lambda adapte le nombre de sondeurs d'événements entre le minimum et le maximum configurés en fonction de votre historique d'événements dans votre rubrique afin de garantir un traitement à faible latence de vos événements.
Notez que pour les sources d'événements Amazon SQS, le paramètre de simultanéité maximale ne peut pas être utilisé en mode provisionné. Lorsque vous utilisez le mode provisionné, vous contrôlez la simultanéité par le biais du paramètre Nombre maximal de sondeurs d'événements.
Pour plus d’informations sur la configuration du mode alloué, reportez-vous aux sections suivantes :
Pour minimiser le temps de latence en mode provisionné, définissez ce paramètre MaximumBatchingWindowInSeconds sur 0. Ce paramètre garantit que Lambda commencera à traiter le lot suivant immédiatement après avoir terminé l’invocation de fonction en cours. Pour plus d’informations sur le traitement à faible latence, consultez Apache Kafka à faible latence.
Après avoir configuré le mode alloué, vous pouvez observer l’utilisation des sondeurs d’événements pour votre charge de travail en surveillant la métrique ProvisionedPollers. Pour de plus amples informations, veuillez consulter Métriques de mappage des sources d’événements.
API de mappage de la source d’événement
Pour gérer une source d’événement à l’aide de la AWS Command Line Interface (AWS CLI) ou d’un AWS SDK
