Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration de la simultanéité provisionnée pour une fonction
Dans Lambda, la simultanéité est le nombre de demandes en vol que votre fonction traite en même temps. Il existe deux types de contrôles de la simultanéité disponibles :
-
Concurrence réservée — Cela définit à la fois le nombre maximum et minimum d'instances simultanées allouées à votre fonction. Lorsqu’une fonction dispose de la simultanéité réservée, aucune autre fonction ne peut utiliser cette simultanéité. La simultanéité réservée est utile pour garantir que vos fonctions les plus critiques disposent toujours d’une simultanéité suffisante pour traiter les requêtes entrantes. En outre, la simultanéité réservée peut être utilisée pour limiter la simultanéité afin d'éviter de surcharger les ressources en aval, telles que les connexions aux bases de données. La simultanéité réservée agit à la fois comme une limite inférieure et une limite supérieure : elle réserve la capacité spécifiée exclusivement à votre fonction tout en l'empêchant de dépasser cette limite. Il n’y a pas de frais supplémentaires pour la configuration de la simultanéité réservée pour une fonction.
-
La simultanéité provisionnée est le nombre d’environnements d’exécution pré-initialisés alloués à votre fonction. Ces environnements d’exécution sont prêts à répondre immédiatement aux demandes de fonctions entrantes. La simultanéité provisionnée est utile pour réduire les latences de démarrage à froid des fonctions et est conçue pour rendre les fonctions disponibles avec des temps de réponse à deux chiffres en millisecondes. En général, ce sont les charges de travail interactives qui tirent le meilleur parti de cette fonctionnalité. Il s’agit des applications dont les utilisateurs lancent des requêtes, telles que les applications Web et mobiles, et qui sont les plus sensibles à la latence. Les charges de travail asynchrones, telles que les pipelines de traitement des données, sont souvent moins sensibles à la latence et ne nécessitent donc généralement pas de provisionnement simultané. La configuration de la simultanéité provisionnée entraîne des frais supplémentaires pour votre. Compte AWS
Cette rubrique explique comment gérer et configurer la simultanéité provisionnée. Pour une présentation conceptuelle de ces deux types de contrôles de simultanéité, consultez Simultanéité réservée et simultanéité provisionnée. Pour plus d’informations sur la configuration de la simultanéité réservée, consultez Configuration de la simultanéité réservée pour une fonction.
Note
Les fonctions Lambda liées à un mappage des sources d’événements Amazon MQ ont une simultanéité maximale par défaut. Pour Apache Active MQ, le nombre maximum d’instances simultanées est de 5. Pour Rabbit MQ, le nombre maximum d’instances simultanées est de 1. La définition d’une simultanéité réservée ou provisionnée pour votre fonction ne modifie pas ces limites. Pour demander une augmentation de la simultanéité maximale par défaut lors de l’utilisation d’Amazon MQ, contactez Support.
Sections
Estimation précise de la simultanéité provisionnée requise pour une fonction
Optimisation du code de fonction lors de l’utilisation de la simultanéité provisionnée
Comprendre le comportement de journalisation et de facturation avec la simultanéité provisionnée
Utilisation d’Application Auto Scaling pour automatiser la gestion de la simultanéité provisionnée
Configuration de la simultanéité provisionnée
Vous pouvez configurer les paramètres de simultanéité provisionnés pour une fonction à l’aide de la console Lambda ou de l’API Lambda.
Pour allouer de la simultanéité provisionnée pour une fonction (console)
Ouvrez la page Functions
(Fonctions) de la console Lambda. -
Sélectionnez la fonction pour laquelle vous souhaitez allouer de la simultanéité provisionnée.
-
Sélectionnez Configuration, puis Concurrency (Simultanéité).
-
Sous Provisioned concurrency configurations (Configurations de simultanéité provisionnée), sélectionnez Add configuration (Ajouter une configuration).
-
Choisissez le type de qualificateur, ainsi que l’alias ou la version.
Note
Vous ne pouvez pas utiliser la simultanéité provisionnée avec la $LATEST version d’une fonction.
Si votre fonction possède une source d’événement, assurez-vous que la source d’événement pointe vers le bon alias ou la bonne version de la fonction. Sinon, votre fonction n’utilisera pas les environnements de simultanéité provisionnés.
-
Saisissez un nombre sous Simultanéité provisionnée.
-
Choisissez Enregistrer.
Vous pouvez configurer jusqu’à la simultanéité du compte non réservé dans votre compte, moins 100. Les 100 unités de simultanéité restantes concernent les fonctions qui n’utilisent pas la simultanéité réservée. Par exemple, si votre compte a une limite de simultanéité de 1 000 et que vous n’avez pas attribué de simultanéité réservée ou provisionnée à l’une de vos autres fonctions, vous pouvez configurer un maximum de 900 unités de simultanéité provisionnées pour une seule fonction.
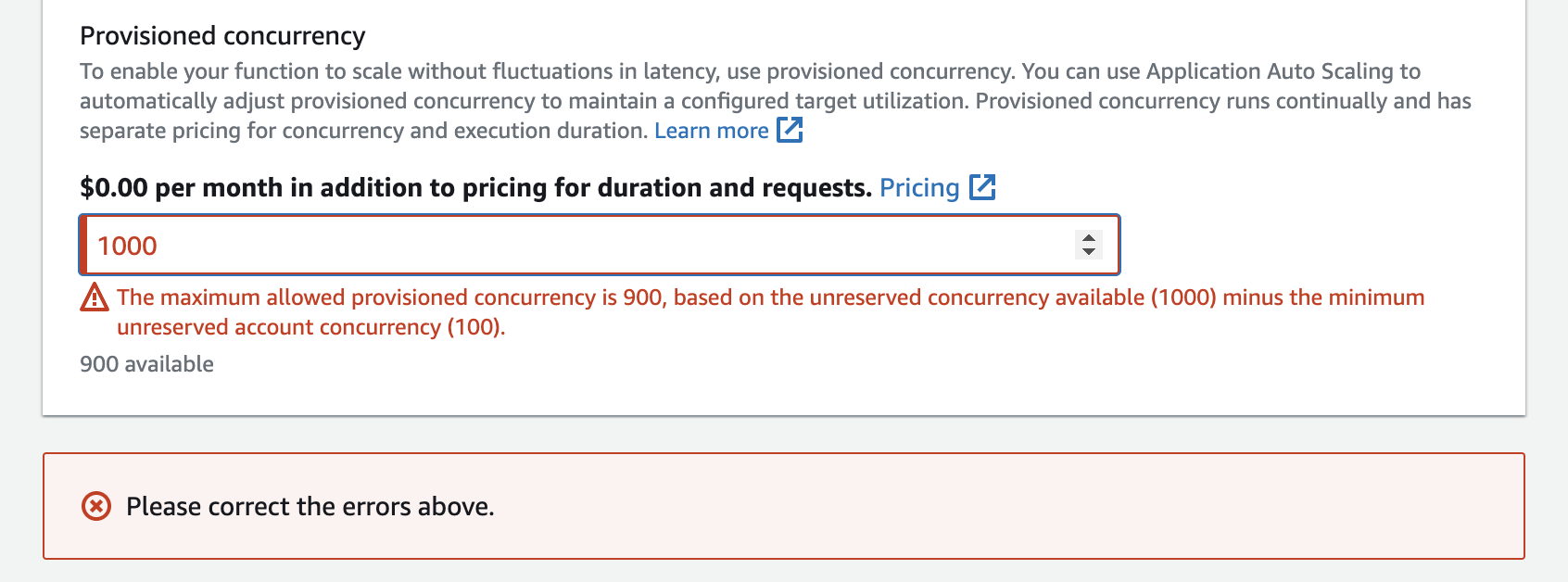
La configuration de la simultanéité provisionnée pour une fonction a des conséquences sur le groupe de simultanéité disponible pour d’autres fonctions. Par exemple, si vous configurez 100 unités de simultanéité provisionnée pour function-a, les autres fonctions de votre compte doivent partager les 900 unités de simultanéité restantes. Et ce même si function-a n’utilise pas les 100 unités.
Il est possible d’allouer à la fois de la simultanéité réservée et de la simultanéité provisionnée pour la même fonction. Dans de tels cas, la simultanéité provisionnée ne peut pas dépasser la simultanéité réservée.
Cette limite s’applique aux versions de fonctions. La simultanéité provisionnée maximale que vous pouvez allouer à une version de fonction spécifique est égale à la simultanéité réservée de la fonction moins la simultanéité provisionnée sur les autres versions de fonction.
Pour configurer la simultanéité provisionnée avec l’API Lambda, utilisez les opérations d’API suivantes.
Par exemple, pour configurer la simultanéité provisionnée avec la ( AWS Command Line Interface CLI), utilisez la put-provisioned-concurrency-config commande. La commande suivante alloue 100 unités de simultanéité provisionnée pour l’alias BLUE d’une fonction nommée my-function :
aws lambda put-provisioned-concurrency-config --function-name my-function \ --qualifier BLUE \ --provisioned-concurrent-executions 100
Vous devriez voir une sortie semblable à la suivante :
{ "Requested ProvisionedConcurrentExecutions": 100, "Allocated ProvisionedConcurrentExecutions": 0, "Status": "IN_PROGRESS", "LastModified": "2023-01-21T11:30:00+0000" }
Estimation précise de la simultanéité provisionnée requise pour une fonction
Vous pouvez consulter les mesures de simultanéité de n'importe quelle fonction active à l'aide de CloudWatch métriques. Plus précisément, la métrique ConcurrentExecutions vous montre le nombre d’invocations simultanées pour les fonctions de votre compte.
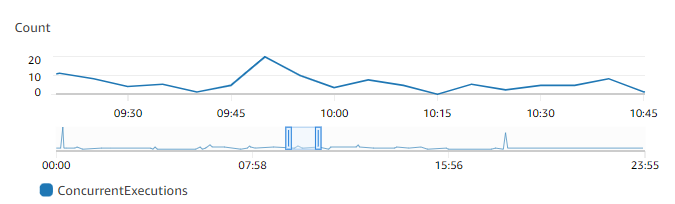
Le graphique précédent indique que cette fonction répond à une moyenne de 5 à 10 demandes simultanées à tout moment, et qu’elle atteint un pic de 20 demandes. Supposons qu’il y ait beaucoup d’autres fonctions dans votre compte. Si cette fonction est essentielle à votre application et que vous avez besoin d’une réponse à faible latence à chaque invocation, configurez au moins 20 unités de simultanéité provisionnée.
Rappelez-vous que vous pouvez également calculer la simultanéité à l’aide de la formule suivante :
Concurrency = (average requests per second) * (average request duration in seconds)
Pour estimer le niveau de simultanéité dont vous avez besoin, multipliez le nombre moyen de demandes par seconde par la durée moyenne des demandes en secondes. Vous pouvez estimer les demandes moyennes par seconde à l’aide de la métrique Invocation, et la durée moyenne des demandes en secondes à l’aide de la métrique Duration.
Lors de la configuration de la simultanéité provisionnée, Lambda suggère d’ajouter un tampon de 10 % en plus de la quantité de simultanéité dont votre fonction a généralement besoin. Par exemple, si votre fonction atteint habituellement un pic de 200 demandes simultanées, définissez votre simultanéité provisionnée à 220 (200 demandes simultanées + 10 % = 220 simultanéités provisionnées).
Optimisation du code de fonction lors de l’utilisation de la simultanéité provisionnée
Si vous utilisez la simultanéité provisionnée, pensez à restructurer votre code de fonction pour optimiser la faible latence. Pour les fonctions utilisant la simultanéité provisionnée, Lambda exécute n’importe quel code d’initialisation (c’est-à-dire le chargement de bibliothèques et l’instanciation de clients) au moment de l’allocation. Il est donc conseillé de déplacer un maximum d’initialisation en dehors du gestionnaire de la fonction principale pour éviter d’avoir un impact sur la latence lors des invocations à la fonction. En revanche, l’initialisation de bibliothèques ou l’instanciation de clients dans le code de votre gestionnaire principal signifie que votre fonction doit l’exécuter à chaque fois qu’elle est invoquée (que vous utilisiez ou non la simultanéité provisionnée).
Pour les appels à la demande, Lambda peut avoir besoin de réexécuter votre code d’initialisation chaque fois que votre fonction démarre à froid. Pour de telles fonctions, vous pouvez choisir de différer l’initialisation d’une fonctionnalité spécifique jusqu’à ce que la fonction ait besoin d’elle. Par exemple, prenons le flux de contrôle suivant pour un gestionnaire Lambda :
def handler(event, context): ... if ( some_condition ): // Initialize CLIENT_A to perform a task else: // Do nothing
Dans l’exemple précédent, au lieu d’initialiser CLIENT_A en dehors du gestionnaire principal, le développeur a initialisé dans l’instruction if. Ainsi, Lambda n’exécute ce code que si some_condition est satisfaite. Si vous initialisez CLIENT_A en dehors du gestionnaire principal, Lambda exécute ce code à chaque démarrage à froid. Cela peut augmenter le temps de latence global.
Vous pouvez mesurer les démarrages à froid à mesure que Lambda prend de l’ampleur en ajoutant la surveillance X-Ray à votre fonction. Une fonction utilisant la simultanéité provisionnée ne présente pas de comportement de démarrage à froid puisque l'environnement d'exécution est préparé avant l'invocation. Cependant, la simultanéité provisionnée doit être appliquée à une version ou à un alias spécifique d'une fonction, et non à la version $LATEST. Dans les cas où le comportement de démarrage à froid persiste, assurez-vous que vous invoquez la version de l'alias avec la configuration de la simultanéité provisionnée.
Utilisation de variables d’environnement pour visualiser et contrôler le comportement de simultanéité provisionnée
Il est possible que votre fonction utilise la totalité de sa simultanéité provisionnée. Lambda utilise des instances à la demande pour gérer tout trafic excédentaire. Pour déterminer quel type d’initialisation Lambda a utilisé pour un environnement particulier, vérifiez la valeur de la variable d’environnement AWS_LAMBDA_INITIALIZATION_TYPE. Cette variable a deux valeurs possibles : provisioned-concurrency ouon-demand. La valeur de AWS_LAMBDA_INITIALIZATION_TYPE est immuable et reste constante pendant toute la durée de vie de l’environnement. Pour vérifier la valeur d’une variable d’environnement dans le code de votre fonction, consultez Récupération de variables d’environnement Lambda.
Si vous utilisez le runtime .NET 8, vous pouvez configurer la variable d'AWS_LAMBDA_DOTNET_PREJITenvironnement pour améliorer la latence des fonctions, même si elles n'utilisent pas la simultanéité provisionnée. Le runtime .NET compile et initialise lentement chaque bibliothèque que votre code appelle pour la première fois. Par conséquent, la première invocation d’une fonction Lambda peut prendre plus de temps que les invocations suivantes. Pour atténuer ce problème, vous pouvez choisir l’une des trois valeurs AWS_LAMBDA_DOTNET_PREJIT :
-
ProvisionedConcurrency: Lambda effectue une compilation ahead-of-time JIT pour tous les environnements en utilisant la simultanéité provisionnée. C’est la valeur par défaut. -
Always: Lambda effectue une compilation ahead-of-time JIT pour chaque environnement, même si la fonction n'utilise pas la simultanéité provisionnée. -
Never: Lambda désactive la compilation ahead-of-time JIT pour tous les environnements.
Comprendre le comportement de journalisation et de facturation avec la simultanéité provisionnée
Pour les environnements de simultanéité provisionnée, le code d’initialisation de votre fonction s’exécute pendant l’allocation et périodiquement lorsque Lambda recycle les instances actives de votre environnement. Lambda vous facture l'initialisation même si l'instance d'environnement ne traite jamais de demande. La simultanéité provisionnée s’exécute en continu et est facturée séparément des coûts d’initialisation et d’invocation. Pour plus d’informations, consultez Tarification AWS Lambda
Lorsque vous configurez une fonction Lambda avec une simultanéité provisionnée, Lambda pré-initialise cet environnement d'exécution afin qu'il soit disponible avant les demandes d'invocation. Lambda enregistre le champ Init Duration de la fonction dans un événement de journal Platform-InitReport au format de journalisation JSON chaque fois que l'environnement est initialisé. Pour voir cet événement de journal, configurez votre niveau de journal JSON sur au moinsINFO. Vous pouvez également utiliser l'API de télémétrie pour consulter les événements de plateforme dans lesquels le champ Init Duration est indiqué.
Utilisation d’Application Auto Scaling pour automatiser la gestion de la simultanéité provisionnée
Vous pouvez utiliser Application Auto Scaling pour gérer la simultanéité provisionnée selon une planification ou en fonction de l’utilisation. Si vous observez des schémas prévisibles de trafic vers votre fonction, utilisez la mise à l’échelle programmée. Si vous souhaitez que votre fonction maintienne un pourcentage d’utilisation spécifique, utilisez une politique de mise à l’échelle de suivi cible.
Note
Si vous utilisez Application Auto Scaling pour gérer la simultanéité provisionnée de votre fonction, assurez-vous de configurer d’abord une valeur de simultanéité provisionnée initiale. Si votre fonction ne possède pas de valeur de simultanéité provisionnée initiale, Application Auto Scaling risque de ne pas gérer correctement la mise à l’échelle des fonctions.
Mise à l’échelle planifiée
Avec Application Auto Scaling, vous pouvez définir votre propre planification de mise à l’échelle en fonction des changements de charge prévisibles. Pour plus d'informations et des exemples, consultez les sections Scheduled Scaling for Application Auto Scaling dans le Guide de l'utilisateur d'Application Auto Scaling et Scheduling AWS Lambda Provisioned Concurrency pour les pics d'utilisation récurrents
Suivi de la cible
Grâce au suivi des cibles, Application Auto Scaling crée et gère un ensemble d' CloudWatch alarmes en fonction de la façon dont vous définissez votre politique de dimensionnement. Lorsque ces alarmes sont activées, Application Auto Scaling ajuste automatiquement la quantité d’environnements alloués à l’aide de la simultanéité provisionnée. Le suivi des cibles est idéal pour les applications dont les modèles de trafic ne sont pas prévisibles.
Pour mettre à l’échelle la simultanéité provisionnée à l’aide du suivi des cibles, utilisez les opérations de l’API Application Auto Scaling RegisterScalableTarget et PutScalingPolicy. Par exemple, si vous utilisez la AWS Command Line Interface (CLI), procédez comme suit :
-
Enregistrez l’alias d’une fonction en tant que cible de mise à l’échelle. L’exemple suivant enregistre l’alias BLUE d’une fonction nommée
my-function:aws application-autoscaling register-scalable-target --service-namespace lambda \ --resource-id function:my-function:BLUE --min-capacity 1 --max-capacity 100 \ --scalable-dimension lambda:function:ProvisionedConcurrency -
Ensuite, appliquez une stratégie de mise à l’échelle à la cible. L’exemple suivant configure Application Auto Scaling afin d’ajuster la configuration de simultanéité provisionnée pour un alias de façon à maintenir l’utilisation proche de 70 %, mais vous pouvez appliquer n’importe quelle valeur comprise entre 10 % et 90 %.
aws application-autoscaling put-scaling-policy \ --service-namespace lambda \ --scalable-dimension lambda:function:ProvisionedConcurrency \ --resource-id function:my-function:BLUE \ --policy-name my-policy \ --policy-type TargetTrackingScaling \ --target-tracking-scaling-policy-configuration '{ "TargetValue": 0.7, "PredefinedMetricSpecification": { "PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization" }}'
Vous devriez obtenir un résultat du type suivant :
{ "PolicyARN": "arn:aws:autoscaling:us-east-2:123456789012:scalingPolicy:12266dbb-1524-xmpl-a64e-9a0a34b996fa:resource/lambda/function:my-function:BLUE:policyName/my-policy", "Alarms": [ { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7" }, { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66" } ] }
Application Auto Scaling crée deux alarmes dans CloudWatch. La première alarme se déclenche lorsque l’utilisation de la simultanéité provisionnée dépasse systématiquement 70 %. Lorsque cela se produit, Application Auto Scaling alloue davantage de simultanéité approvisionnée afin de réduire l’utilisation. La deuxième alarme se déclenche lorsque l’utilisation est constamment inférieure à 63 % (90 % de la cible de 70 %). Lorsque cela se produit, Application Auto Scaling réduit la simultanéité approvisionnée de l’alias.
Note
Lambda émet la ProvisionedConcurrencyUtilization métrique uniquement lorsque votre fonction est active et reçoit des demandes. Pendant les périodes d'inactivité, aucune métrique n'est émise et vos alarmes d'auto-scaling entrent dans INSUFFICIENT_DATA l'état. Par conséquent, Application Auto Scaling ne sera pas en mesure d'ajuster la simultanéité provisionnée de votre fonction. Cela peut entraîner une facturation imprévue.
Dans l’exemple suivant, une fonction adapte son échelle entre une quantité minimum et maximum de simultanéité approvisionnée en fonction de l’utilisation.
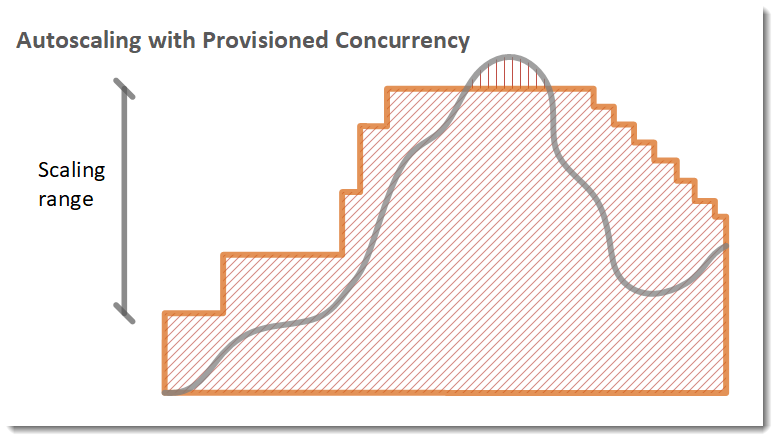
Légende
-
 Instances de la fonction
Instances de la fonction -
 Demandes ouvertes
Demandes ouvertes -
 Simultanéité provisionnée
Simultanéité provisionnée -
 Simultanéité standard
Simultanéité standard
Quand le nombre de demandes ouvertes augmente, Application Auto Scaling augmente la simultanéité provisionnée par échelons jusqu’à ce qu’elle atteigne le maximum configuré. Une fois le maximum atteint, la fonction peut continuer à se mettre à l’échelle en fonction de la simultanéité standard, non réservée, si votre compte n’a pas atteint sa limite de simultanéité. Lorsque l’utilisation chute et reste constamment faible, Application Auto Scaling réduit la simultanéité provisionnée par échelons périodiques plus petits.
Les deux alarmes gérées par Application Auto Scaling utilisent la statistique moyenne par défaut. Les fonctions qui subissent des rafales de trafic peuvent ne pas déclencher ces alarmes. Par exemple, supposons que votre fonction Lambda s’exécute rapidement (c’est-à-dire entre 20 et 100 ms) et que votre modèle de trafic se produise sous forme de rafales rapides. Dans ce cas, le nombre de demandes dépasse la simultanéité allouée pendant la rafale. Cependant, Application Auto Scaling nécessite que la charge en rafale soit maintenue pendant au moins 3 minutes afin de provisionner des environnements supplémentaires. De plus, les deux CloudWatch alarmes nécessitent 3 points de données atteignant la moyenne cible pour activer la politique de dimensionnement automatique. Si votre fonction connaît des pics de trafic rapides, l’utilisation de la statistique Maximum au lieu de la statistique Average peut être plus efficace pour mettre à l’échelle la simultanéité provisionnée afin de minimiser les démarrages à froid.
Pour plus d’informations sur l’utilisation des politiques de mise à l’échelle du suivi des cibles, consultez Politiques de mise à l’échelle du suivi des cibles pour Application Auto Scaling.
