Scénario 4 : détection et notification en temps réel des anomalies de capteurs
La société ABC4Logistics transporte des produits pétroliers hautement inflammables tels que de l'essence, du propane liquide (GPL) et du naphte depuis le port vers différentes villes. Des centaines de véhicules sont équipés de plusieurs capteurs pour surveiller des éléments tels que la localisation, la température du moteur, la température à l'intérieur du conteneur, la vitesse de conduite, la localisation de stationnement, l'état des routes, etc. Une des exigences d'ABC4Logistics consiste à surveiller les températures du moteur et du conteneur en temps réel et à alerter le conducteur et l'équipe de surveillance de la flotte en cas d'anomalie. Pour détecter de telles conditions et générer des alertes en temps réel, ABC4Logistics a mis en œuvre l'architecture suivante sur AWS.
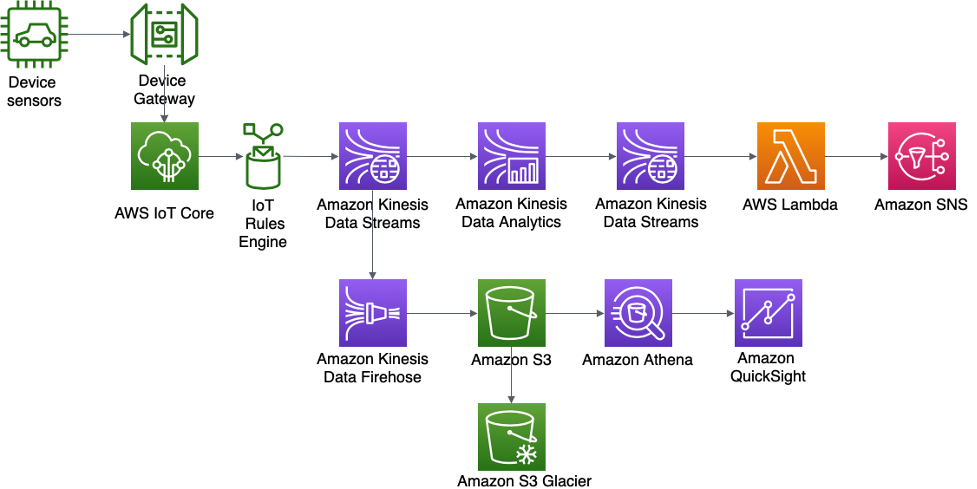
Architecture de détection des anomalies de capteur et de notifications en temps réel pour ABC4Logistics
Les données des capteurs sont ingérées par AWS IoT Gateway, où le moteur de règles AWS IoT rend les données en streaming disponibles dans Amazon Kinesis Data Streams. Avec Kinesis Data Analytics, ABC4Logistics peut effectuer des analyses en temps réel sur les données en streaming dans Kinesis Data Streams.
Avec Kinesis Data Analytics, ABC4Logistics peut détecter si les relevés de température des capteurs s'écartent des relevés normaux sur une période de dix secondes, et ingérer l'enregistrement sur une autre instance Kinesis Data Streams, en identifiant les enregistrements anormaux. Amazon Kinesis Data Streams appelle ensuite des fonctions Lambda, qui peuvent envoyer les alertes au conducteur et à l'équipe de surveillance de la flotte via Amazon SNS.
Les données de Kinesis Data Streams sont également transférées vers Amazon Kinesis Data Firehose. Amazon Kinesis Data Firehose conserve ces données dans Amazon S3, ce qui permet à ABC4Logistics d'effectuer des analyses par lots ou en temps quasi réel sur les données des capteurs. ABC4Logistics utilise Amazon Athena
Les composants importants de cette architecture sont décrits en détail ci-après.
Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics
Avec Amazon Kinesis Data Analytics, vous pouvez interroger de manière interactive des données de streaming à l'aide de plusieurs options, notamment le langage SQL standard, des applications Apache Flink en Java, Python et Scala, et créer des applications Apache Beam en Java pour analyser les flux de données.
Ces options vous offrent la flexibilité d'utiliser une approche spécifique en fonction du niveau de complexité de l'application de streaming et de la prise en charge source/cible. La section suivante traite de l'option Kinesis Data Analytics pour les applications Flink.
Amazon Kinesis Data Analytics pour applications Apache Flink
Apache Flink
Avec Amazon Kinesis Data Analytics pour Apache Flink, vous pouvez créer et exécuter du code contre des sources de streaming pour effectuer des analyses de séries chronologiques, alimenter des tableaux de bord en temps réel et créer des métriques en temps réel sans avoir à gérer l'environnement distribué complexe d'Apache Flink. Vous pouvez utiliser les fonctions de programmation de haut niveau Flink de la même manière que vous les utilisez lorsque vous hébergez vous-même l'infrastructure Flink.
Kinesis Data Analytics pour Apache Flink vous permet de créer des applications en Java, Scala, Python ou SQL afin de traiter et d'analyser des données de streaming. Une application Flink classique lit les données à partir du flux d'entrée, de l'emplacement ou de la source des données, transforme, filtre ou joint les données à l'aide d'opérateurs ou de fonctions, et stocke les données sur un flux de sortie ou un emplacement de données, ou récepteur.
Le diagramme d'architecture suivant montre certaines des sources et des récepteurs pris en charge pour l'application Flink sur Kinesis Data Analytics. Outre les connecteurs prégroupés pour source/récepteur, vous pouvez également intégrer des connecteurs personnalisés à une variété d'autres sources/récepteurs pour les applications Flink sur Kinesis Data Analytics.
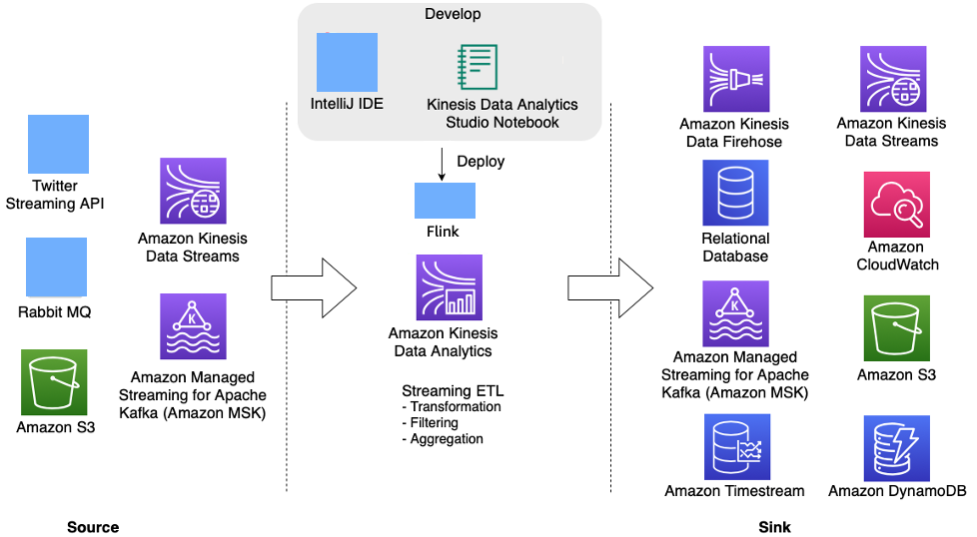
Application Apache Flink sur Kinesis Data Analytics pour le traitement des flux en temps réel
Les développeurs peuvent utiliser leur IDE préféré pour développer des applications Flink et les déployer sur Kinesis Data Analytics à partir d'AWS Management Console
Amazon Kinesis Data Analytics Studio
Dans le cadre du service Kinesis Data Analytics, Kinesis Data Analytics Studio
Le notebook Studio vous permet de développer votre code d'application Flink dans un environnement de notebook, d'afficher les résultats de votre code en temps réel et de le visualiser. Vous pouvez créer un notebook Studio optimisé par Apache Zeppelin et Apache Flink en un seul clic depuis Kinesis Data Streams et la console Amazon MSK, ou le lancer à partir de Kinesis Data Analytics Console.
Après avoir développé le code de manière itérative dans le cadre de Kinesis Data Analytics Studio, vous pouvez déployer un notebook en tant qu'application d'analyse de données Kinesis pour l'exécuter en mode streaming, lire les données de vos sources, écrire sur vos destinations, gérer l'état de l'application à long terme et dimensionner automatiquement en fonction du débit de vos flux sources. Auparavant, les clients utilisaient Kinesis Data Analytics pour applications SQL pour de telles analyses interactives de données de streaming en temps réel sur AWS.
Kinesis Data Analytics pour applications SQL est toujours disponible, mais pour les nouveaux projets, AWS recommande d'utiliser le nouveau Kinesis Data Analytics Studio
Pour rendre l'application Kinesis Data Analytics Flink tolérante aux pannes, vous pouvez utiliser des points de contrôle et des instantanés, comme décrit dans Implémentation de la tolérance aux pannes dans Kinesis Data Analytics pour Apache Flink.
Les applications Flink Kinesis Data Analytics sont utiles pour écrire des applications d'analyse de streaming complexes, telles que des applications avec une sémantique « exactement une fois »
Après avoir traité les données de streaming dans l'application Flink, vous pouvez conserver les données dans divers récepteurs ou destinations comme Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, Amazon DynamoDB, Amazon OpenSearch Service, Amazon Timestream, Amazon S3, etc. L'application Flink Kinesis Data Analytics fournit également des garanties de performances inférieures à la seconde.
Applications Apache Beam pour Kinesis Data Analytics
Apache Beam
Vous pouvez utiliser le cadre Apache Beam avec votre application d'analyse de données Kinesis pour traiter les données de streaming. Les applications d'analyse de données Kinesis qui utilisent Apache Beam font appel à l'exécuteur Apache Flink
Récapitulatif
En utilisant les services de streaming AWS Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics et Amazon Kinesis Data Firehose,
ABC4Logistics peut détecter des schémas anormaux dans les relevés de température et informer le conducteur et l'équipe de gestion de la flotte en temps réel, évitant ainsi des accidents majeurs tels qu'une panne complète du véhicule ou un incendie.
