End of support notice: On October 7th, 2026, AWS will discontinue support for AWS IoT Greengrass Version 1. After October 7th, 2026, you will no longer be able to access the AWS IoT Greengrass V1 resources. For more information, please visit Migrate from AWS IoT Greengrass Version 1.
Export data streams to the AWS Cloud (CLI)
This tutorial shows you how to use the AWS CLI to configure and deploy an AWS IoT Greengrass group with stream manager enabled. The group contains a user-defined Lambda function that writes to a stream in stream manager, which is then exported automatically to the AWS Cloud.
Stream manager makes ingesting, processing, and exporting high-volume data streams more
efficient and reliable. In this tutorial, you create a TransferStream Lambda
function that consumes IoT data. The Lambda function uses the AWS IoT Greengrass Core SDK to create a stream in
stream manager and then read and write to it. Stream manager then exports the stream to Kinesis Data Streams.
The following diagram shows this workflow.
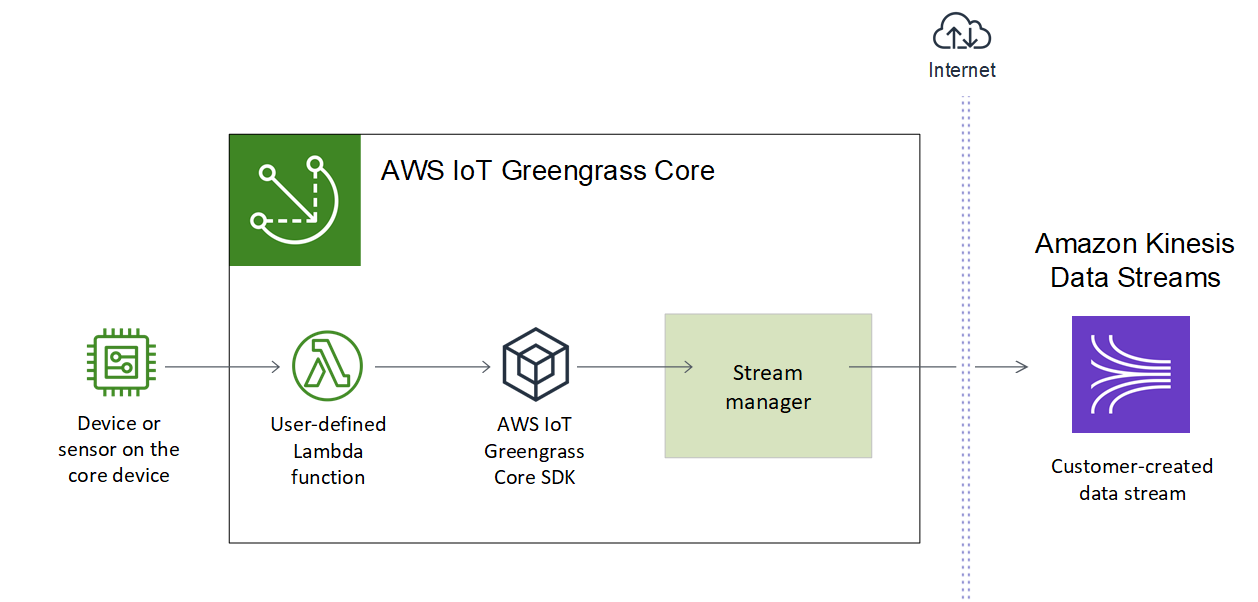
The focus of this tutorial is to show how user-defined Lambda functions use the
StreamManagerClient object in the AWS IoT Greengrass Core SDK to interact with stream manager. For
simplicity, the Python Lambda function that you create for this tutorial generates simulated device
data.
When you use the AWS IoT Greengrass API, which includes the Greengrass commands in the AWS CLI, to create a group, stream manager is disabled by default.
To enable stream manager on your core, you create a function definition version that includes the system
GGStreamManager Lambda function and a group version that references the new function definition version. Then you deploy the
group.
Prerequisites
To complete this tutorial, you need:
-
A Greengrass group and a Greengrass core (v1.10 or later). For information about how to create a Greengrass group and core, see Getting started with AWS IoT Greengrass. The Getting Started tutorial also includes steps for installing the AWS IoT Greengrass Core software.
Note
Stream manager is not supported on OpenWrt distributions.
-
The Java 8 runtime (JDK 8) installed on the core device.
-
For Debian-based distributions (including Raspbian) or Ubuntu-based distributions, run the following command:
sudo apt install openjdk-8-jdk -
For Red Hat-based distributions (including Amazon Linux), run the following command:
sudo yum install java-1.8.0-openjdkFor more information, see How to download and install prebuilt OpenJDK packages
in the OpenJDK documentation.
-
-
AWS IoT Greengrass Core SDK for Python v1.5.0 or later. To use
StreamManagerClientin the AWS IoT Greengrass Core SDK for Python, you must:-
Install Python 3.7 or later on the core device.
-
Include the SDK and its dependencies in your Lambda function deployment package. Instructions are provided in this tutorial.
Tip
You can use
StreamManagerClientwith Java or NodeJS. For example code, see the AWS IoT Greengrass Core SDK for Javaand AWS IoT Greengrass Core SDK for Node.js on GitHub. -
-
A destination stream named
MyKinesisStreamcreated in Amazon Kinesis Data Streams in the same AWS Region as your Greengrass group. For more information, see Create a stream in the Amazon Kinesis Developer Guide.Note
In this tutorial, stream manager exports data to Kinesis Data Streams, which results in charges to your AWS account. For information about pricing, see Kinesis Data Streams pricing
. To avoid incurring charges, you can run this tutorial without creating a Kinesis data stream. In this case, you check the logs to see that stream manager attempted to export the stream to Kinesis Data Streams.
-
An IAM policy added to the Greengrass group role that allows the
kinesis:PutRecordsaction on the target data stream, as shown in the following example:
-
The AWS CLI installed and configured on your computer. For more information, see Installing the AWS Command Line Interface and Configuring the AWS CLI in the AWS Command Line Interface User Guide.
The example commands in this tutorial are written for Linux and other Unix-based systems. If you're using Windows, see Specifying parameter values for the AWS command line interface for more information about differences in syntax.
If the command contains a JSON string, the tutorial provides an example that has the JSON on a single line. On some systems, it might be more efficient to edit and run commands using this format.
The tutorial contains the following high-level steps:
The tutorial should take about 30 minutes to complete.
Step 1: Create a Lambda function deployment package
In this step, you create a Lambda function deployment package that contains Python function code and dependencies. You upload this package later when you create the Lambda function in AWS Lambda. The Lambda function uses the AWS IoT Greengrass Core SDK to create and interact with local streams.
Note
Your user-defined Lambda functions must use the AWS IoT Greengrass Core SDK to interact with stream manager. For more information about requirements for the Greengrass stream manager, see Greengrass stream manager requirements.
-
Download the AWS IoT Greengrass Core SDK for Python v1.5.0 or later.
-
Unzip the downloaded package to get the SDK. The SDK is the
greengrasssdkfolder. -
Install package dependencies to include with the SDK in your Lambda function deployment package.
-
Navigate to the SDK directory that contains the
requirements.txtfile. This file lists the dependencies. -
Install the SDK dependencies. For example, run the following
pipcommand to install them in the current directory:pip install --target . -r requirements.txt
-
-
Save the following Python code function in a local file named
transfer_stream.py.Tip
For example code that uses Java and NodeJS, see the AWS IoT Greengrass Core SDK for Java
and AWS IoT Greengrass Core SDK for Node.js on GitHub. import asyncio import logging import random import time from greengrasssdk.stream_manager import ( ExportDefinition, KinesisConfig, MessageStreamDefinition, ReadMessagesOptions, ResourceNotFoundException, StrategyOnFull, StreamManagerClient, ) # This example creates a local stream named "SomeStream". # It starts writing data into that stream and then stream manager automatically exports # the data to a customer-created Kinesis data stream named "MyKinesisStream". # This example runs forever until the program is stopped. # The size of the local stream on disk will not exceed the default (which is 256 MB). # Any data appended after the stream reaches the size limit continues to be appended, and # stream manager deletes the oldest data until the total stream size is back under 256 MB. # The Kinesis data stream in the cloud has no such bound, so all the data from this script is # uploaded to Kinesis and you will be charged for that usage. def main(logger): try: stream_name = "SomeStream" kinesis_stream_name = "MyKinesisStream" # Create a client for the StreamManager client = StreamManagerClient() # Try deleting the stream (if it exists) so that we have a fresh start try: client.delete_message_stream(stream_name=stream_name) except ResourceNotFoundException: pass exports = ExportDefinition( kinesis=[KinesisConfig(identifier="KinesisExport" + stream_name, kinesis_stream_name=kinesis_stream_name)] ) client.create_message_stream( MessageStreamDefinition( name=stream_name, strategy_on_full=StrategyOnFull.OverwriteOldestData, export_definition=exports ) ) # Append two messages and print their sequence numbers logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "ABCDEFGHIJKLMNO".encode("utf-8")), ) logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "PQRSTUVWXYZ".encode("utf-8")), ) # Try reading the two messages we just appended and print them out logger.info( "Successfully read 2 messages: %s", client.read_messages(stream_name, ReadMessagesOptions(min_message_count=2, read_timeout_millis=1000)), ) logger.info("Now going to start writing random integers between 0 and 1000 to the stream") # Now start putting in random data between 0 and 1000 to emulate device sensor input while True: logger.debug("Appending new random integer to stream") client.append_message(stream_name, random.randint(0, 1000).to_bytes(length=4, signed=True, byteorder="big")) time.sleep(1) except asyncio.TimeoutError: logger.exception("Timed out while executing") except Exception: logger.exception("Exception while running") def function_handler(event, context): return logging.basicConfig(level=logging.INFO) # Start up this sample code main(logger=logging.getLogger()) -
Zip the following items into a file named
transfer_stream_python.zip. This is your Lambda function deployment package.-
transfer_stream.py. App logic.
-
greengrasssdk. Required library for Python Greengrass Lambda functions that publish MQTT messages.
Stream manager operations are available in version 1.5.0 or later of the AWS IoT Greengrass Core SDK for Python.
-
The dependencies you installed for the AWS IoT Greengrass Core SDK for Python (for example, the
cbor2directories).
When you create the
zipfile, include only these items, not the containing folder. -
Step 2: Create a Lambda function
-
Create an IAM role so you can pass in the role ARN when you create the function.
Note
AWS IoT Greengrass doesn't use this role because permissions for your Greengrass Lambda functions are specified in the Greengrass group role. For this tutorial, you create an empty role.
-
Copy the
Arnfrom the output. -
Use the AWS Lambda API to create the
TransferStreamfunction. The following command assumes that the zip file is in the current directory.-
Replace
role-arnwith theArnthat you copied.
aws lambda create-function \ --function-name TransferStream \ --zip-file fileb://transfer_stream_python.zip \ --rolerole-arn\ --handler transfer_stream.function_handler \ --runtime python3.7 -
-
Publish a version of the function.
aws lambda publish-version --function-name TransferStream --description 'First version' -
Create an alias for the published version.
Greengrass groups can reference a Lambda function by alias (recommended) or by version. Using an alias makes it easier to manage code updates because you don't have to change your subscription table or group definition when the function code is updated. Instead, you just point the alias to the new function version.
aws lambda create-alias --function-name TransferStream --name GG_TransferStream --function-version 1Note
AWS IoT Greengrass doesn't support Lambda aliases for $LATEST versions.
-
Copy the
AliasArnfrom the output. You use this value when you configure the function for AWS IoT Greengrass.
Now you're ready to configure the function for AWS IoT Greengrass.
Step 3: Create a function definition and version
This step creates a function definition version that references the system GGStreamManager Lambda function and
your user-defined TransferStream Lambda function. To enable stream manager when you use the AWS IoT Greengrass API, your function definition
version must include the GGStreamManager function.
-
Create a function definition with an initial version that contains the system and user-defined Lambda functions.
The following definition version enables stream manager with default parameter settings. To configure custom settings, you must define environment variables for corresponding stream manager parameters. For an example, see To enable, disable, or configure stream manager (CLI). AWS IoT Greengrass uses default settings for parameters that are omitted.
MemorySizeshould be at least128000.Pinnedmust be set totrue.Note
A long-lived (or pinned) Lambda function starts automatically after AWS IoT Greengrass starts and keeps running in its own container. This is in contrast to an on-demand Lambda function, which starts when invoked and stops when there are no tasks left to run. For more information, see Lifecycle configuration for Greengrass Lambda functions.
-
Replace
arbitrary-function-idwith a name for the function, such asstream-manager. -
Replace
alias-arnwith theAliasArnthat you copied when you created the alias for theTransferStreamLambda function.
Note
Timeoutis required by the function definition version, butGGStreamManagerdoesn't use it. For more information aboutTimeoutand other group-level settings, see Controlling execution of Greengrass Lambda functions by using group-specific configuration. -
-
Copy the
LatestVersionArnfrom the output. You use this value to add the function definition version to the group version that you deploy to the core.
Step 4: Create a logger definition and version
Configure the group's logging settings. For this tutorial, you configure AWS IoT Greengrass system components, user-defined Lambda functions, and connectors to write logs to the file system of the core device. You can use logs to troubleshoot any issues you might encounter. For more information, see Monitoring with AWS IoT Greengrass logs.
-
Create a logger definition that includes an initial version.
-
Copy the
LatestVersionArnof the logger definition from the output. You use this value to add the logger definition version to the group version that you deploy to the core.
Step 5: Get the ARN of your core definition version
Get the ARN of the core definition version to add to your new group version. To deploy a group version, it must reference a core definition version that contains exactly one core.
-
Get the IDs of the target Greengrass group and group version. This procedure assumes that this is the latest group and group version. The following query returns the most recently created group.
aws greengrass list-groups --query "reverse(sort_by(Groups, &CreationTimestamp))[0]"Or, you can query by name. Group names are not required to be unique, so multiple groups might be returned.
aws greengrass list-groups --query "Groups[?Name=='MyGroup']"Note
You can also find these values in the AWS IoT console. The group ID is displayed on the group's Settings page. Group version IDs are displayed on the group's Deployments tab.
-
Copy the
Idof the target group from the output. You use this to get the core definition version and when you deploy the group. -
Copy the
LatestVersionfrom the output, which is the ID of the last version added to the group. You use this to get the core definition version. -
Get the ARN of the core definition version:
-
Get the group version.
-
Replace
group-idwith theIdthat you copied for the group. -
Replace
group-version-idwith theLatestVersionthat you copied for the group.
aws greengrass get-group-version \ --group-idgroup-id\ --group-version-idgroup-version-id -
-
Copy the
CoreDefinitionVersionArnfrom the output. You use this value to add the core definition version to the group version that you deploy to the core.
-
Step 6: Create a group version
Now, you're ready to create a group version that contains the entities that you want to deploy. You do this by creating a group version that references the target version of each component type. For this tutorial, you include a core definition version, a function definition version, and a logger definition version.
-
Create a group version.
-
Replace
group-idwith theIdthat you copied for the group. -
Replace
core-definition-version-arnwith theCoreDefinitionVersionArnthat you copied for the core definition version. -
Replace
function-definition-version-arnwith theLatestVersionArnthat you copied for your new function definition version. -
Replace
logger-definition-version-arnwith theLatestVersionArnthat you copied for your new logger definition version.
aws greengrass create-group-version \ --group-idgroup-id\ --core-definition-version-arncore-definition-version-arn\ --function-definition-version-arnfunction-definition-version-arn\ --logger-definition-version-arnlogger-definition-version-arn -
-
Copy the
Versionfrom the output. This is the ID of the new group version.
Step 7: Create a deployment
Deploy the group to the core device.
-
Create a deployment.
Replace
group-idwith theIdthat you copied for the group.Replace
group-version-idwith theVersionthat you copied for the new group version.
aws greengrass create-deployment \ --deployment-type NewDeployment \ --group-idgroup-id\ --group-version-idgroup-version-id -
Copy the
DeploymentIdfrom the output. -
Get the deployment status.
Replace
group-idwith theIdthat you copied for the group.Replace
deployment-idwith theDeploymentIdthat you copied for the deployment.
aws greengrass get-deployment-status \ --group-idgroup-id\ --deployment-iddeployment-idIf the status is
Success, the deployment was successful. For troubleshooting help, see Troubleshooting AWS IoT Greengrass.
Step 8: Test the application
The TransferStream Lambda function generates simulated device data. It writes data to a stream that stream manager exports to the target Kinesis data stream.
-
In the Amazon Kinesis console, under Kinesis data streams, choose MyKinesisStream.
Note
If you ran the tutorial without a target Kinesis data stream, check the log file for the stream manager (
GGStreamManager). If it containsexport stream MyKinesisStream doesn't existin an error message, then the test is successful. This error means that the service tried to export to the stream but the stream doesn't exist. -
On the MyKinesisStream page, choose Monitoring. If the test is successful, you should see data in the Put Records charts. Depending on your connection, it might take a minute before the data is displayed.
Important
When you're finished testing, delete the Kinesis data stream to avoid incurring more charges.
Or, run the following commands to stop the Greengrass daemon. This prevents the core from sending messages until you're ready to continue testing.
cd /greengrass/ggc/core/ sudo ./greengrassd stop -
Remove the TransferStream Lambda function from the core.
Follow Step 6: Create a group version to create a new group version. but remove the
--function-definition-version-arnoption in thecreate-group-versioncommand. Or, create a function definition version that doesn't include the TransferStream Lambda function.Note
By omitting the system
GGStreamManagerLambda function from the deployed group version, you disable stream management on the core.-
Follow Step 7: Create a deployment to deploy the new group version.
To view logging information or troubleshoot issues with streams, check the logs for the TransferStream and GGStreamManager functions.
You must have root permissions to read AWS IoT Greengrass logs on the file system.
TransferStreamwrites log entries togreengrass-root/ggc/var/log/user/region/account-id/TransferStream.logGGStreamManagerwrites log entries togreengrass-root/ggc/var/log/system/GGStreamManager.log
If you need more troubleshooting information, you can set the Lambda logging level to DEBUG and then create and deploy a new group version.
See also
-
AWS Identity and Access Management (IAM) commands in the AWS CLI Command Reference
-
AWS Lambda commands in the AWS CLI Command Reference
-
AWS IoT Greengrass commands in the AWS CLI Command Reference
