Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Replikasi database mainframe ke AWS dengan menggunakan Exactly Connect
Lucio Pereira, Sayantan Giri, dan Balaji Mohan, Amazon Web Services
Ringkasan
Pola ini menguraikan langkah-langkah untuk mereplikasi data dari basis data mainframe ke penyimpanan data Amazon dalam waktu dekat dengan menggunakan Exacently Connect. Ini mengimplementasikan arsitektur berbasis acara dengan Amazon Managed Streaming for Apache Kafka (Amazon MSK) dan konektor basis data khusus di cloud untuk meningkatkan skalabilitas, ketahanan, dan kinerja.
Tepat Connect adalah alat replikasi yang menangkap data dari sistem mainframe lama dan mengintegrasikannya ke dalam lingkungan cloud. Data direplikasi dari mainframe ke AWS melalui change data capture (CDC) dengan menggunakan aliran pesan mendekati real-time dengan jalur data heterogen latensi rendah dan throughput tinggi.
Pola ini juga mencakup strategi pemulihan bencana untuk jaringan data tangguh dengan replikasi data Multi-region dan routing failover.
Prasyarat dan batasan
Prasyarat
Database mainframe yang ada—misalnya, IBM, IBM Information Management System (IMS) DB2, atau Virtual Storage Access Method (VSAM) —yang ingin Anda tiru ke AWS Cloud
Akun AWS
yang aktif AWS Direct Connect
atau AWS Virtual Private Network (AWS VPN ) dari lingkungan perusahaan Anda ke AWS Cloud pribadi virtual
dengan subnet yang dapat dijangkau oleh platform lama Anda
Arsitektur
Tumpukan teknologi sumber
Lingkungan mainframe yang mencakup setidaknya satu dari database berikut:
Basis data IBM IMS
Basis data IBM DB2
File VSAM
Tumpukan teknologi target
Amazon MSK
Amazon Elastic Kubernetes Service (Amazon EKS) dan Amazon EKS Anywhere
Docker
Database relasional AWS atau NoSQL seperti berikut ini:
Amazon DynamoDB
Amazon Relational Database Service (Amazon RDS) untuk Oracle, Amazon RDS for PostgreSQL, atau Amazon Aurora
Amazon ElastiCache untuk Redis
Amazon Keyspaces (untuk Apache Cassandra)
Arsitektur target
Mereplikasi data mainframe ke database AWS
Diagram berikut menggambarkan replikasi data mainframe ke database AWS seperti DynamoDB, Amazon RDS, Amazon, atau Amazon Keyspaces. ElastiCache Replikasi terjadi dalam waktu dekat dengan menggunakan Tangkap dan Penerbit Secara Tepat di lingkungan mainframe lokal Anda, Pengirim dengan Tepat di Amazon EKS Anywhere di lingkungan terdistribusi lokal Anda, serta Terapkan konektor Mesin dan database dengan Tepat di AWS Cloud.

Diagram menunjukkan alur kerja berikut:
Tepat Capture mendapatkan data mainframe dari log CDC dan memelihara data dalam penyimpanan transien internal.
Tepatnya Publisher mendengarkan perubahan dalam penyimpanan data internal dan mengirimkan catatan CDC ke Excently Dispatcher melalui koneksi. TCP/IP
Tepatnya Dispatcher menerima catatan CDC dari Publisher dan mengirimkannya ke Amazon MSK. Dispatcher membuat kunci Kafka berdasarkan konfigurasi pengguna dan beberapa tugas pekerja untuk mendorong data secara paralel. Dispatcher mengirimkan pengakuan kembali ke Publisher ketika catatan telah disimpan di Amazon MSK.
Amazon MSK memegang catatan CDC di lingkungan cloud. Ukuran partisi topik tergantung pada persyaratan sistem pemrosesan transaksi (TPS) Anda untuk throughput. Kunci Kafka wajib untuk transformasi lebih lanjut dan pemesanan transaksi.
Mesin Terapkan Secara Tepat mendengarkan catatan CDC dari Amazon MSK dan mengubah data (misalnya, dengan memfilter atau memetakan) berdasarkan persyaratan basis data target. Anda dapat menambahkan logika yang disesuaikan ke skrip SQD Tepatnya. (SQD adalah bahasa hak milik Tepat.) Mesin Terapkan Secara Tepat mengubah setiap rekaman CDC ke format Apache Avro atau JSON dan mendistribusikannya ke berbagai topik berdasarkan kebutuhan Anda.
Topik Kafka target menyimpan catatan CDC dalam berbagai topik berdasarkan basis data target, dan Kafka memfasilitasi pemesanan transaksi berdasarkan kunci Kafka yang ditentukan. Tombol partisi sejajar dengan partisi yang sesuai untuk mendukung proses berurutan.
Konektor database (aplikasi Java yang disesuaikan) mendengarkan catatan CDC dari Amazon MSK dan menyimpannya di database target.
Anda dapat memilih database target berdasarkan kebutuhan Anda. Pola ini mendukung NoSQL dan database relasional.
Pemulihan bencana
Kesinambungan bisnis adalah kunci keberhasilan organisasi Anda. AWS Cloud menyediakan kemampuan untuk ketersediaan tinggi (HA) dan pemulihan bencana (DR), serta mendukung paket failover dan fallback organisasi Anda. Pola ini mengikuti strategi active/passive DR dan memberikan panduan tingkat tinggi untuk menerapkan strategi DR yang memenuhi persyaratan RTO dan RPO Anda.
Diagram berikut menggambarkan alur kerja DR.

Diagram menunjukkan yang berikut:
Failover semi-otomatis diperlukan jika terjadi kegagalan di AWS Region 1. Dalam kasus kegagalan di Wilayah 1, sistem harus memulai perubahan perutean untuk menghubungkan Tepatnya Dispatcher ke Wilayah 2.
Amazon MSK mereplikasi data melalui mirroring antar Wilayah, Untuk alasan ini, selama failover, cluster MSK Amazon di Wilayah 2 harus dipromosikan sebagai pemimpin utama.
Tepat Apply Engine dan konektor database adalah aplikasi stateless yang dapat bekerja di Wilayah mana pun.
Sinkronisasi database tergantung pada database target. Misalnya, DynamoDB dapat menggunakan tabel global, ElastiCache dan dapat menggunakan datastores global.
Pemrosesan latensi rendah dan throughput tinggi melalui konektor database
Konektor database adalah komponen penting dalam pola ini. Konektor mengikuti pendekatan berbasis pendengar untuk mengumpulkan data dari Amazon MSK dan mengirim transaksi ke database melalui pemrosesan throughput tinggi dan latensi rendah untuk aplikasi kritis misi (tingkatan 0 dan 1). Diagram berikut menggambarkan proses.
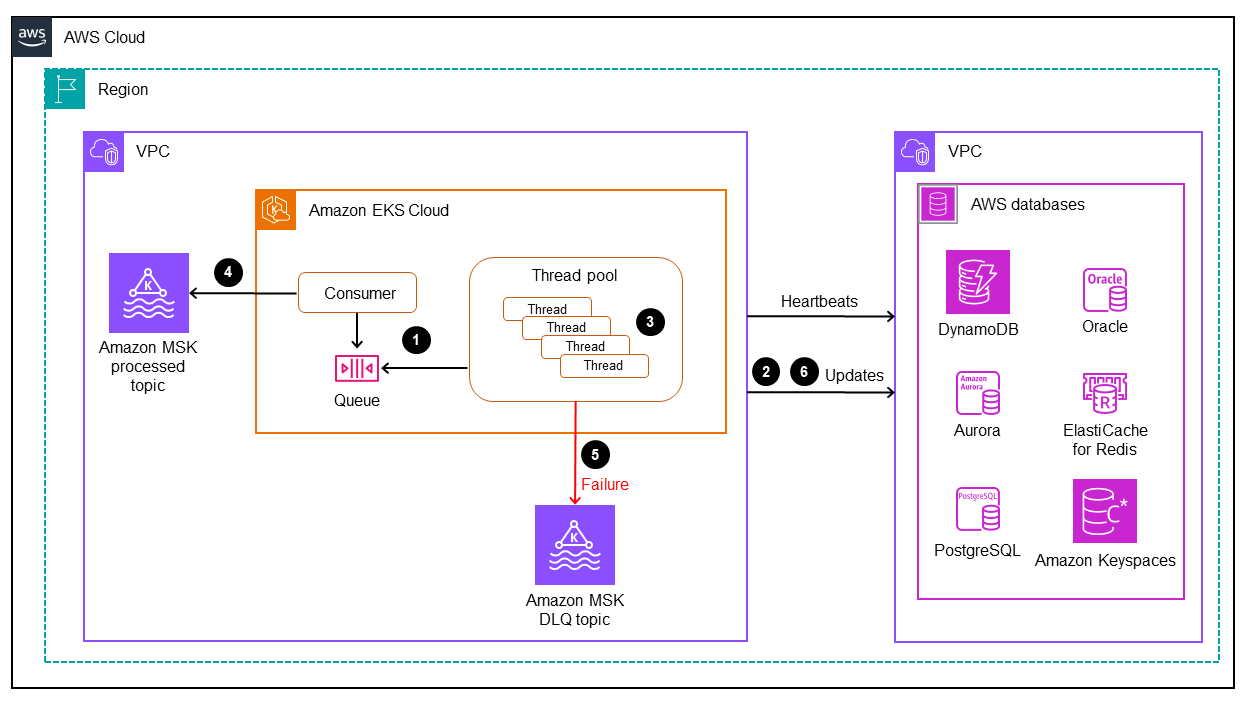
Pola ini mendukung pengembangan aplikasi yang disesuaikan dengan konsumsi ulir tunggal melalui mesin pemrosesan multithreaded.
Utas utama konektor mengkonsumsi catatan CDC dari Amazon MSK dan mengirimkannya ke kumpulan utas untuk diproses.
Thread dari kumpulan thread memproses catatan CDC dan mengirimkannya ke database target.
Jika semua utas sibuk, catatan CDC ditahan oleh antrian utas.
Utas utama menunggu untuk menghapus semua catatan dari antrian utas dan melakukan offset ke Amazon MSK.
Utas anak menangani kegagalan. Jika kegagalan terjadi selama pemrosesan, pesan yang gagal dikirim ke topik DLQ (antrian surat mati).
Thread anak memulai pembaruan bersyarat (lihat Ekspresi kondisi dalam dokumentasi DynamoDB), berdasarkan stempel waktu mainframe, untuk menghindari duplikasi atau pembaruan apa pun dalam database. out-of-order
Untuk informasi tentang cara menerapkan aplikasi konsumen Kafka dengan kemampuan multi-threading, lihat posting blog Konsumsi Pesan Multi-Threaded dengan Konsumen Apache Kafka di
Alat
Layanan AWS
Amazon Managed Streaming for Apache Kafka (Amazon MSK) adalah layanan yang dikelola sepenuhnya yang membantu Anda membangun dan menjalankan aplikasi yang menggunakan Apache Kafka untuk memproses data streaming.
Amazon Elastic Kubernetes Service (Amazon EKS) membantu Anda menjalankan Kubernetes di AWS tanpa harus menginstal atau memelihara control plane atau node Kubernetes Anda sendiri.
Amazon EKS Anywhere
membantu Anda menerapkan, menggunakan, dan mengelola klaster Kubernetes yang berjalan di pusat data Anda sendiri. Amazon DynamoDB adalah layanan database NoSQL yang dikelola sepenuhnya yang menyediakan kinerja yang cepat, dapat diprediksi, dan dapat diskalakan.
Amazon Relational Database Service (Amazon RDS) membantu Anda menyiapkan, mengoperasikan, dan menskalakan database relasional di AWS Cloud.
Amazon ElastiCache membantu Anda mengatur, mengelola, dan menskalakan lingkungan cache dalam memori terdistribusi di AWS Cloud.
Amazon Keyspaces (untuk Apache Cassandra) adalah layanan database terkelola yang membantu Anda memigrasi, menjalankan, dan menskalakan beban kerja Cassandra Anda di AWS Cloud.
Alat-alat lainnya
Connect
mengintegrasikan data dari sistem mainframe lama seperti dataset VSAM atau database mainframe IBM ke dalam platform cloud dan data generasi berikutnya.
Praktik terbaik
Temukan kombinasi terbaik dari partisi Kafka dan konektor multi-ulir untuk menyeimbangkan kinerja dan biaya yang optimal. Beberapa Instans Pengambilan dan Dispatcher Secara Tepat dapat meningkatkan biaya karena konsumsi MIPS (juta instruksi per detik) yang lebih tinggi.
Hindari menambahkan manipulasi data dan logika transformasi ke konektor database. Untuk tujuan ini, gunakan Mesin Terapkan Tepatnya, yang menyediakan waktu pemrosesan dalam mikrodetik.
Buat permintaan berkala atau panggilan pemeriksaan kesehatan ke database (detak jantung) di konektor database untuk sering menghangatkan koneksi dan mengurangi latensi.
Terapkan logika validasi kumpulan utas untuk memahami tugas yang tertunda dalam antrian utas dan tunggu semua utas selesai sebelum polling Kafka berikutnya. Ini membantu menghindari kehilangan data jika node, wadah, atau proses mogok.
Paparkan metrik latensi melalui titik akhir kesehatan untuk meningkatkan kemampuan observabilitas melalui dasbor dan mekanisme penelusuran.
Epik
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Siapkan proses mainframe (batch atau utilitas online) untuk memulai proses CDC dari database mainframe. |
| Insinyur mainframe |
Aktifkan aliran log basis data mainframe. |
| Spesialis DB Mainframe |
Gunakan komponen Capture untuk menangkap catatan CDC. |
| Insinyur mainframe, Tepatnya Connect SME |
Konfigurasikan komponen Publisher untuk mendengarkan komponen Capture. |
| Insinyur mainframe, Tepatnya Connect SME |
Menyediakan Amazon EKS Anywhere di lingkungan terdistribusi lokal. |
| DevOps insinyur |
Terapkan dan konfigurasikan komponen Dispatcher di lingkungan terdistribusi untuk mempublikasikan topik di AWS Cloud. |
| DevOps insinyur, Tepatnya Connect SME |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Menyediakan kluster Amazon EKS di Wilayah AWS yang ditentukan. |
| DevOps insinyur, Administrator jaringan |
Menyediakan kluster MSK dan mengkonfigurasi topik Kafka yang berlaku. |
| DevOps insinyur, Administrator jaringan |
Konfigurasikan komponen Apply Engine untuk mendengarkan topik Kafka yang direplikasi. |
| Tepatnya Connect SME |
Menyediakan instans DB di AWS Cloud. |
| Insinyur data, DevOps insinyur |
Konfigurasikan dan gunakan konektor database untuk mendengarkan topik yang diterbitkan oleh Apply Engine. |
| Pengembang aplikasi, arsitek Cloud, Insinyur data |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Tentukan tujuan pemulihan bencana untuk aplikasi bisnis Anda. |
| Arsitek cloud, Insinyur data, Pemilik aplikasi |
Merancang strategi pemulihan bencana berdasarkan RTO/RPO yang ditentukan. |
| Arsitek cloud, Insinyur data |
Penyediaan cluster dan konfigurasi pemulihan bencana. |
| DevOps insinyur, Administrator jaringan, Arsitek cloud |
Uji pipa CDC untuk pemulihan bencana. |
| Pemilik aplikasi, Insinyur data, arsitek Cloud |
Sumber daya terkait
Sumber daya AWS
Tepat Connect sumber daya
Sumber daya pertemuan
