OPS10-BP02 Menjalankan proses untuk setiap peringatan
Menetapkan proses yang jelas dan terdefinisi untuk setiap peringatan di dalam sistem Anda sangat penting untuk manajemen insiden yang efektif dan efisien. Praktik ini memastikan bahwa setiap peringatan menghasilkan respons spesifik yang dapat ditindaklanjuti, sehingga meningkatkan keandalan dan responsivitas operasi Anda.
Hasil yang diinginkan: Setiap peringatan memulai rencana respons spesifik dan terdefinisi dengan baik. Jika memungkinkan, respons dilakukan secara otomatis, dengan kepemilikan yang jelas dan jalur eskalasi yang sudah ditentukan. Peringatan ditautkan ke basis pengetahuan yang mutakhir sehingga setiap operator dapat memberikan respons secara konsisten dan efektif. Respons diberikan secara cepat dan seragam, sehingga meningkatkan efisiensi dan keandalan operasional.
Anti-pola umum:
-
Peringatan tidak memiliki proses respons yang telah ditentukan sebelumnya, sehingga menyebabkan resolusi yang seadanya dan tertunda.
-
Jumlah peringatan yang terlalu banyak dapat menyebabkan terabaikannya peringatan-peringatan penting.
-
Peringatan-peringatan ditangani secara tidak konsisten karena tidak adanya kepemilikan dan tanggung jawab yang jelas.
Manfaat menjalankan praktik terbaik ini:
-
Mengurangi kewalahan akibat peringatan dengan hanya memunculkan peringatan yang dapat ditindaklanjuti.
-
Penurunan rata-rata waktu resolusi (MTTR) untuk masalah operasional.
-
Penurunan rata-rata waktu untuk menyelidiki (MTTI), sehingga membantu mengurangi MTTR.
-
Peningkatan kemampuan untuk menskalakan respons-respons operasional.
-
Peningkatan konsistensi dan keandalan dalam menangani peristiwa-peristiwa operasional.
Misalnya, Anda memiliki proses yang ditentukan untuk peristiwa AWS Health untuk akun-akun penting, termasuk alarm aplikasi, masalah operasional, dan peristiwa siklus hidup terencana (seperti memperbarui versi Amazon EKS sebelum klaster diperbarui secara otomatis), dan Anda memberikan kemampuan bagi tim Anda untuk secara aktif memantau, berkomunikasi, dan merespons peristiwa-peristiwa ini. Tindakan ini membantu Anda mencegah gangguan layanan yang disebabkan oleh perubahan di sisi AWS atau memitigasinya lebih cepat ketika terjadi masalah yang tak terduga.
Tingkat risiko yang terjadi jika praktik terbaik ini tidak diterapkan: Tinggi
Panduan implementasi
Untuk membuat sebuah proses untuk setiap peringatan, diperlukan pembuatan rencana respons yang jelas untuk setiap peringatan, otomatisasi respons apabila memungkinkan, dan penyempurnaan proses-proses ini secara berkelanjutan berdasarkan umpan balik operasional dan perubahan persyaratan.
Langkah-langkah implementasi
Diagram berikut ini menggambarkan alur kerja manajemen insiden di dalam Manajer Insiden AWS Systems Manager
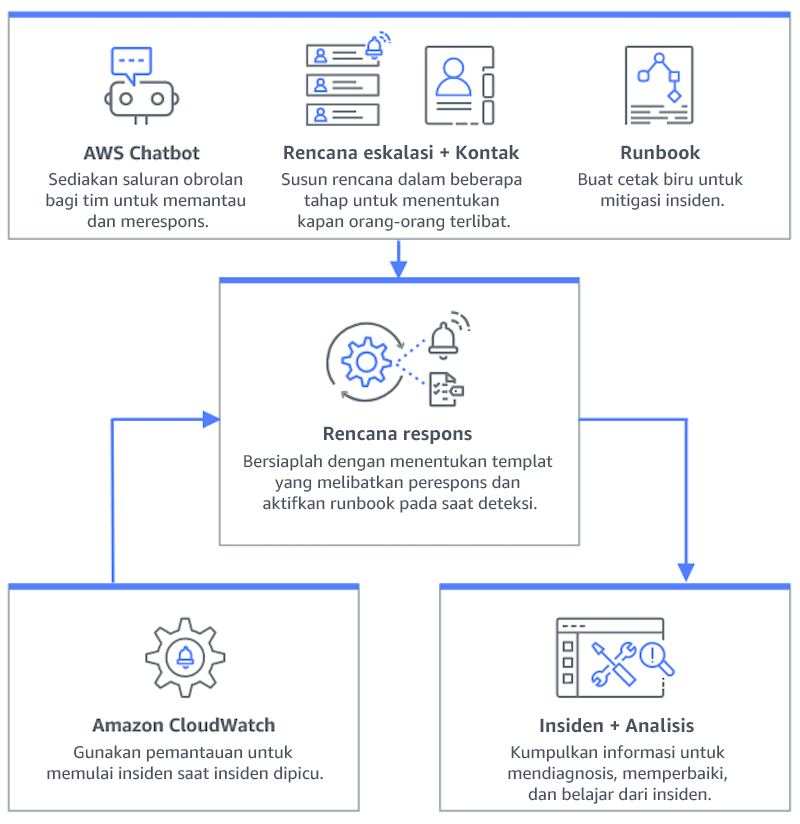
-
Gunakan alarm komposit: Buat alarm komposit di CloudWatch untuk mengelompokkan alarm terkait, mengurangi noise, dan memungkinkan respons yang lebih bermakna.
-
Terus dapatkan informasi dengan AWS Health. AWS Health adalah sumber informasi otoritatif tentang kondisi sumber daya AWS Cloud Anda. Gunakan AWS Health untuk memvisualisasikan dan mendapatkan notifikasi tentang peristiwa layanan saat ini dan perubahan yang akan datang, seperti peristiwa siklus hidup yang direncanakan, sehingga Anda dapat mengambil langkah-langkah untuk mengurangi dampaknya.
-
Buat notifikasi peristiwa AWS Health sesuai keperluan yang dikirim ke saluran email dan obrolan melalui Notifikasi Pengguna AWS serta integrasikan secara programatis dengan alat pemantauan dan peringatan Anda melalui Amazon EventBridge atau API AWS Health.
-
Rencanakan dan lacak progres pada peristiwa kesehatan yang memerlukan tindakan dengan mengintegrasikan dengan manajemen perubahan atau alat ITSM (seperti Jira atau ServiceNow) yang mungkin sudah Anda gunakan melalui Amazon EventBridge atau API AWS Health.
-
Jika Anda menggunakan AWS Organizations, aktifkan tampilan organisasi untuk AWS Health guna menggabungkan peristiwa AWS Health di seluruh akun.
-
-
Integrasikan alarm Amazon CloudWatch dengan Manajer Insiden: Konfigurasikan alarm CloudWatch untuk membuat insiden secara otomatis di Manajer Insiden AWS Systems Manager.
-
Integrasikan Amazon EventBridge dengan Manajer Insiden: Buat aturan EventBridge untuk bereaksi terhadap peristiwa dan membuat insiden menggunakan rencana respons yang ditentukan.
-
Mempersiapkan insiden di Manajer Insiden:
-
Buat rencana respons terperinci di Manajer Insiden untuk setiap jenis peringatan.
-
Buat saluran obrolan melalui Amazon Q Developer dalam aplikasi obrolan yang terhubung ke rencana respons di Manajer Insiden, sehingga akan memfasilitasi komunikasi waktu nyata selama insiden di seluruh platform seperti Slack, Microsoft Teams, dan Amazon Chime.
-
Menggabungkan runbook Otomatisasi Systems Manager dalam Manajer Insiden untuk mendorong respons otomatis terhadap insiden.
-
Sumber daya
Praktik-praktik terbaik terkait:
Dokumen terkait:
Video terkait:
Contoh terkait:
