Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connettore Amazon Athena HBase
Il HBase connettore Amazon Athena consente ad Amazon Athena di comunicare con le tue istanze HBase Apache in modo da poter interrogare i dati con SQL. HBase
A differenza degli archivi di dati relazionali tradizionali, HBase le raccolte non hanno uno schema prestabilito. HBasenon dispone di un archivio di metadati. Ogni voce di una HBase raccolta può avere campi e tipi di dati diversi.
Il HBase connettore supporta due meccanismi per la generazione di informazioni sullo schema delle tabelle: inferenza di base dello schema e AWS Glue Data Catalog metadati.
L'inferenza dello schema è l'impostazione predefinita. Questa opzione esegue la scansione di un numero limitato di documenti della raccolta, forma un'unione di tutti i campi e forza i campi che hanno tipi di dati non sovrapposti. Questa opzione funziona bene per le raccolte che hanno voci per lo più uniformi.
Per le raccolte con una maggiore varietà di tipi di dati, il connettore supporta il recupero dei metadati da AWS Glue Data Catalog. Se il connettore rileva un AWS Glue database e una tabella che corrispondono al HBase namespace e ai nomi delle raccolte, ottiene le informazioni sullo schema dalla tabella corrispondente. AWS Glue Quando crei la AWS Glue tabella, ti consigliamo di renderla un superset di tutti i campi a cui potresti voler accedere dalla tua raccolta. HBase
Se hai abilitato Lake Formation nel tuo account, il ruolo IAM per il tuo connettore Lambda federato Athena che hai distribuito nell'accesso in lettura deve avere accesso in lettura in AWS Serverless Application Repository Lake Formation a. AWS Glue Data Catalog
Questo connettore può essere registrato con Glue Data Catalog come catalogo federato. Supporta i controlli di accesso ai dati definiti in Lake Formation a livello di catalogo, database, tabella, colonna, riga e tag. Questo connettore utilizza Glue Connections per centralizzare le proprietà di configurazione in Glue.
Prerequisiti
Implementa il connettore sul tuo Account AWS utilizzando la console Athena o AWS Serverless Application Repository. Per ulteriori informazioni, consulta Crea una connessione a una fonte di dati o Usa il AWS Serverless Application Repository per distribuire un connettore di origine dati.
Parametri
Usa i parametri di questa sezione per configurare il HBase connettore.
Nota
I connettori di origine dati Athena creati il 3 dicembre 2024 e versioni successive utilizzano connessioni. AWS Glue
I nomi e le definizioni dei parametri elencati di seguito si riferiscono ai connettori di origine dati Athena creati prima del 3 dicembre 2024. Questi possono differire dalle proprietà di AWS Glue connessione corrispondenti. A partire dal 3 dicembre 2024, utilizza i parametri seguenti solo quando distribuisci manualmente una versione precedente di un connettore di origine dati Athena.
Si consiglia di configurare un HBase connettore utilizzando un oggetto Glue connections. Per fare ciò, imposta la variabile di glue_connection ambiente del HBase connettore Lambda sul nome della connessione Glue da utilizzare.
Proprietà delle connessioni Glue
Utilizzate il comando seguente per ottenere lo schema per un oggetto di connessione Glue. Questo schema contiene tutti i parametri che puoi usare per controllare la tua connessione.
aws glue describe-connection-type --connection-type HBASE
Proprietà dell'ambiente Lambda
-
glue_connection — Specificate il nome della connessione Glue associata al connettore federato.
Nota
-
Tutti i connettori che utilizzano le connessioni Glue devono essere utilizzati AWS Secrets Manager per memorizzare le credenziali.
-
Il HBase connettore creato utilizzando le connessioni Glue non supporta l'uso di un gestore di multiplexing.
-
Il HBase connettore creato utilizzando le connessioni Glue supporta solo
ConnectionSchemaVersion2.
-
spill_bucket: specifica il bucket Amazon S3 per i dati che superano i limiti della funzione Lambda.
-
spill_prefix: (facoltativo) per impostazione predefinita, viene utilizzata una sottocartella nello
spill_bucketspecificato chiamataathena-federation-spill. Ti consigliamo di configurare un ciclo di vita dell'archiviazione di Amazon S3 in questa posizione per eliminare gli spill più vecchi di un numero predeterminato di giorni o ore. -
spill_put_request_headers: (facoltativo) una mappa codificata in JSON delle intestazioni e dei valori della richiesta per la richiesta
putObjectdi Amazon S3 utilizzata per lo spill (ad esempio,{"x-amz-server-side-encryption" : "AES256"}). Per altre possibili intestazioni, consulta il riferimento PutObjectall'API di Amazon Simple Storage Service. -
kms_key_id: (facoltativo) per impostazione predefinita, tutti i dati riversati in Amazon S3 vengono crittografati utilizzando la modalità di crittografia autenticata AES-GCM e una chiave generata casualmente. Per fare in modo che la tua funzione Lambda utilizzi chiavi di crittografia più potenti generate da KMS come
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, puoi specificare l'ID della chiave KMS. -
disable_spill_encryption: (facoltativo) se impostato su
True, disabilita la crittografia dello spill. L'impostazione predefinita èFalse: in questo modo, i dati riversati su S3 vengono crittografati utilizzando AES-GCM tramite una chiave generata casualmente o una chiave generata mediante KMS. La disabilitazione della crittografia dello spill può migliorare le prestazioni, soprattutto se la posizione dello spill utilizza la crittografia lato server. -
disable_glue — (Facoltativo) Se presente e impostato su true, il connettore non tenta di recuperare metadati supplementari da. AWS Glue
-
glue_catalog: (facoltativo) utilizza questa opzione per specificare un catalogo AWS Glue multi-account. Per impostazione predefinita, il connettore tenta di ottenere metadati dal proprio account. AWS Glue
-
default_hbase — Se presente, specifica una stringa di HBase connessione da utilizzare quando non esiste alcuna variabile di ambiente specifica del catalogo.
-
enable_case_insensitive_match — (Facoltativo) When, esegue ricerche senza distinzione tra maiuscole e minuscole nei nomi delle tabelle in.
trueHBase Il valore predefinito èfalse. Utilizza se la tua query contiene nomi di tabella in maiuscolo.
Specifica delle stringhe di connessione
È possibile fornire una o più proprietà che definiscono i dettagli di HBase connessione per le HBase istanze utilizzate con il connettore. A tale scopo, imposta una variabile di ambiente Lambda che corrisponda al nome del catalogo che desideri utilizzare in Athena. Ad esempio, supponete di voler utilizzare le seguenti query per interrogare due diverse HBase istanze di Athena:
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
Prima di poter utilizzare queste due istruzioni SQL, devi aggiungere due variabili di ambiente alla funzione Lambda: hbase_instance_1 e hbase_instance_2. Il valore per ciascuna deve essere una stringa di HBase connessione nel formato seguente:
master_hostname:hbase_port:zookeeper_port
Utilizzo dei segreti
Facoltativamente, è possibile utilizzare AWS Secrets Manager per intero o in parte il valore per i dettagli della stringa di connessione. Per utilizzare la funzione Athena Federated Query con Secrets Manager, il VPC collegato alla funzione Lambda dovrebbe disporre dell'accesso a Internet
Se si utilizza la sintassi ${my_secret} per inserire il nome di un segreto di Secrets Manager nella stringa di connessione, il connettore sostituisce il nome del segreto con i valori del nome utente e della password di Secrets Manager.
Ad esempio, supponiamo di impostare la variabile di ambiente Lambda per hbase_instance_1 sul seguente valore:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
L'SDK Athena Query Federation tenta automaticamente di recuperare un segreto denominato hbase_instance_1_creds da Secrets Manager e inietta quel valore al posto di ${hbase_instance_1_creds}. Qualsiasi parte della stringa di connessione racchiusa entro la combinazione di caratteri ${
} viene interpretata come un segreto da Secrets Manager. Se specifichi un nome del segreto che il connettore non riesce a trovare in Secrets Manager, il connettore non sostituisce il testo.
Configurazione di database e tabelle in AWS Glue
L'inferenza dello schema integrata nel connettore supporta solo i valori serializzati HBase come stringhe (ad esempio,). String.valueOf(int) Poiché la capacità integrata di inferenza dello schema del connettore è limitata, in alternativa potresti voler usare AWS Glue
per i metadati. Per abilitare una AWS Glue tabella da utilizzare con HBase, è necessario disporre di un AWS Glue database e di una tabella con nomi che corrispondano allo spazio dei HBase nomi e alla tabella per i quali si desidera fornire metadati supplementari. L'uso delle convenzioni di denominazione delle famiglie di HBase colonne è facoltativo ma non obbligatorio.
Per utilizzare una AWS Glue tabella per metadati supplementari
-
Quando modifichi la tabella e il database nella AWS Glue console, aggiungi le seguenti proprietà della tabella:
hbase-metadata-flag— Questa proprietà indica al HBase connettore che il connettore può utilizzare la tabella per metadati supplementari. Puoi fornire qualsiasi valore per
hbase-metadata-flag, purché la proprietàhbase-metadata-flagsia presente nell'elenco delle proprietà della tabella.-
hbase-native-storage-flag— Utilizzate questo flag per attivare o disattivare le due modalità di serializzazione dei valori supportate dal connettore. Per impostazione predefinita, quando questo campo non è presente, il connettore presuppone che tutti i valori siano memorizzati come stringhe. HBase Pertanto, tenterà di analizzare tipi di dati come
INTBIGINT, eDOUBLEda HBase come stringhe. Se questo campo è impostato con qualsiasi valore della tabella in AWS Glue, il connettore passa alla modalità di archiviazione «nativa» e tenta di leggereINTBIGINTBIT, eDOUBLEcome byte utilizzando le seguenti funzioni:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Assicurati di utilizzare i tipi di dati appropriati elencati AWS Glue in questo documento.
Modellazione delle famiglie di colonne
Il HBase connettore Athena supporta due modi per modellare famiglie di HBase colonne: denominazione completamente qualificata (appiattita) o utilizzo di oggetti. family:column STRUCT
Nel modello STRUCT, il nome del campo STRUCT dovrebbe corrispondere alla famiglia della colonna, mentre i figli di STRUCT dovrebbero corrispondere ai nomi delle colonne della famiglia. Tuttavia, poiché le letture colonnari e il pushdown dei predicati non sono ancora completamente supportati per tipi complessi come STRUCT, l'utilizzo di STRUCT al momento non è consigliato.
L'immagine seguente mostra una tabella configurata in AWS Glue che utilizza una combinazione dei due approcci.
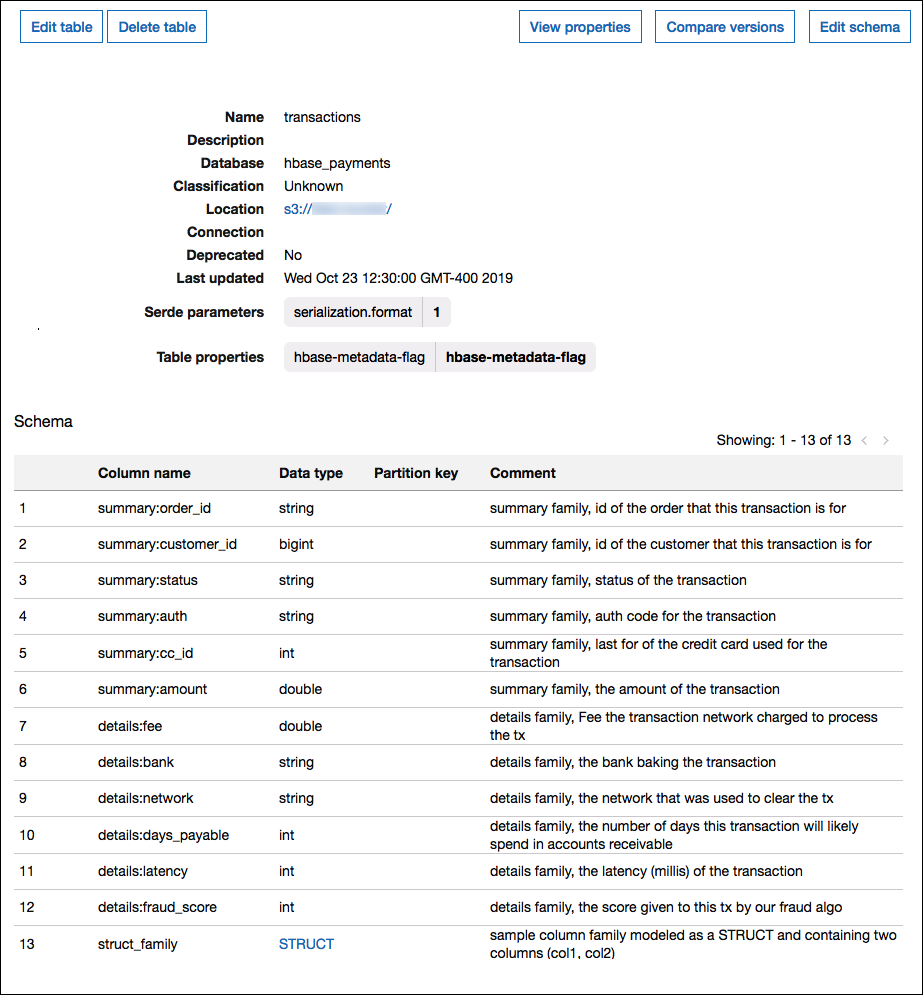
Supporto dei tipi di dati
Il connettore recupera tutti i HBase valori come tipo di byte di base. Quindi, in base a come hai definito le tabelle in AWS Glue Data Catalog, mappa i valori in uno dei tipi di dati Apache Arrow nella tabella seguente.
| AWS Glue tipo di dati | Tipo di dati Apache Arrow |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| float | FLOAT4 |
| booleano | BIT |
| binary | VARBINARY |
| string | VARCHAR |
Nota
Se non si utilizza AWS Glue per integrare i metadati, l'inferenza dello schema del connettore utilizza solo i tipi di BIGINT dati e. FLOAT8 VARCHAR
Autorizzazioni richieste
Consulta la sezione Policies del file athena-hbase.yaml
-
Accesso in scrittura ad Amazon S3: per trasferire i risultati di query di grandi dimensioni, il connettore richiede l'accesso in scrittura a una posizione in Amazon S3.
-
Athena GetQueryExecution: il connettore utilizza questa autorizzazione per fallire rapidamente quando la query Athena upstream è terminata.
-
AWS Glue Data Catalog— Il HBase connettore richiede l'accesso in sola lettura a per ottenere informazioni sullo schema. AWS Glue Data Catalog
-
CloudWatch Registri: il connettore richiede l'accesso ai CloudWatch registri per l'archiviazione dei registri.
-
AWS Secrets Manager accesso in lettura: se si sceglie di archiviare i dettagli HBase degli endpoint in Secrets Manager, è necessario concedere al connettore l'accesso a tali segreti.
-
Accesso VPC: il connettore richiede la possibilità di collegare e scollegare interfacce al VPC in modo che possa connettersi ad esso e comunicare con le istanze. HBase
Prestazioni
Il HBase connettore Athena tenta di parallelizzare le query sull' HBase istanza leggendo ogni server regionale in parallelo. Il HBase connettore Athena esegue il pushdown dei predicati per ridurre i dati scansionati dalla query.
La funzione Lambda esegue inoltre il pushdown delle proiezioni per ridurre la quantità di dati scansionati dalla query. Tuttavia, la selezione di un sottoinsieme di colonne a volte comporta un periodo di esecuzione delle query più lungo. LIMITle clausole riducono la quantità di dati analizzati, ma se non si fornisce un predicato, è necessario aspettarsi che SELECT le query con una LIMIT clausola analizzino almeno 16 MB di dati.
HBase è soggetta a errori di query e tempi di esecuzione delle query variabili. Potrebbe essere necessario ritentare più volte affinché le query abbiano esito positivo. Il HBase connettore è resistente alle limitazioni dovute alla concorrenza.
Interrogazioni pass-through
Il HBase connettore supporta le query passthrough ed è basato su NoSQL. Per informazioni su come interrogare Apache HBase utilizzando i filtri, consulta Filter language nella documentazione di Apache.
Per utilizzare le query passthrough con HBase, utilizzate la seguente sintassi:
SELECT * FROM TABLE( system.query( database => 'database_name', collection => 'collection_name', filter => '{query_syntax}' ))
Il seguente esempio di filtri di interrogazione HBase passthrough per i dipendenti di 24 o 30 anni all'interno della employee raccolta del database. default
SELECT * FROM TABLE( system.query( DATABASE => 'default', COLLECTION => 'employee', FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' || ' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')' ))
Informazioni sulla licenza
Il progetto Amazon Athena HBase Connector è concesso in licenza con licenza Apache-2.0.
Risorse aggiuntive
Per ulteriori informazioni su questo connettore, visita il sito corrispondente su .com.
