Avviso di fine del supporto: il 31 maggio 2026, AWS terminerà il supporto per AWS Panorama. Dopo il 31 maggio 2026, non potrai più accedere alla AWS Panorama console o AWS Panorama alle risorse. Per ulteriori informazioni, consulta AWS Panorama Fine del supporto.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Modelli di visione artificiale
Un modello di visione artificiale è un programma software addestrato a rilevare oggetti nelle immagini. Un modello impara a riconoscere un insieme di oggetti analizzando prima le immagini di tali oggetti attraverso l'addestramento. Un modello di visione artificiale utilizza un'immagine come input e restituisce informazioni sugli oggetti rilevati, ad esempio il tipo di oggetto e la sua posizione. AWS Panorama supporta modelli di visione artificiale creati con PyTorch, Apache MXNet e TensorFlow.
Nota
Per un elenco di modelli predefiniti che sono stati testati con AWS Panorama, consulta Compatibilità dei modelli
Sections
Utilizzo di modelli nel codice
Un modello restituisce uno o più risultati, che possono includere probabilità per le classi rilevate, informazioni sulla posizione e altri dati. L'esempio seguente mostra come eseguire l'inferenza su un'immagine da un flusso video e inviare l'output del modello a una funzione di elaborazione.
Esempio application.py — Inferenza
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
L'esempio seguente mostra una funzione che elabora i risultati del modello di classificazione di base. Il modello di esempio restituisce una matrice di probabilità, che è il primo e unico valore nell'array dei risultati.
Esempio application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
Il codice dell'applicazione trova i valori con le probabilità più elevate e li associa alle etichette in un file di risorse che viene caricato durante l'inizializzazione.
Creazione di un modello personalizzato
Puoi usare modelli che crei in PyTorch MXNet Apache e TensorFlow nelle applicazioni AWS Panorama. In alternativa alla creazione e alla formazione di modelli nell' SageMaker intelligenza artificiale, puoi utilizzare un modello addestrato o creare e addestrare il tuo modello con un framework supportato ed esportarlo in un ambiente locale o in Amazon EC2.
Nota
Per informazioni dettagliate sulle versioni del framework e sui formati di file supportati da SageMaker AI Neo, consulta Supported Frameworks nella Amazon SageMaker AI Developer Guide.
L'archivio di questa guida fornisce un'applicazione di esempio che illustra questo flusso di lavoro per un modello Keras in formato. TensorFlow SavedModel Utilizza TensorFlow 2 e può essere eseguito localmente in un ambiente virtuale o in un contenitore Docker. L'app di esempio include anche modelli e script per creare il modello su un' EC2istanza Amazon.
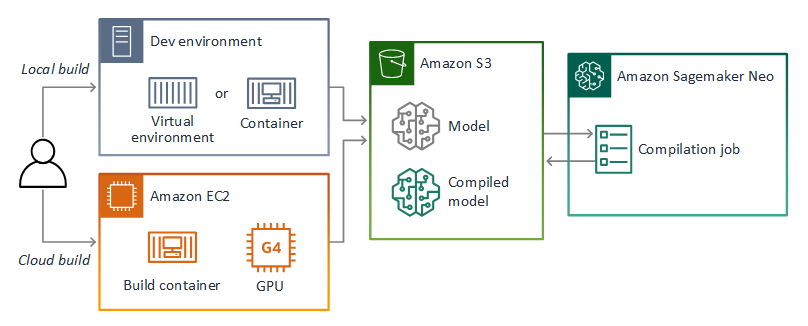
AWS Panorama utilizza SageMaker AI Neo per compilare modelli da utilizzare su AWS Panorama Appliance. Per ogni framework, usa il formato supportato da SageMaker AI Neo e raccogli il modello in un .tar.gz archivio.
Per ulteriori informazioni, consulta Compilare e distribuire modelli con Neo nella Amazon SageMaker AI Developer Guide.
Imballaggio di un modello
Un pacchetto modello comprende un descrittore, una configurazione del pacchetto e un archivio del modello. Come in un pacchetto di immagini applicative, la configurazione del pacchetto indica al servizio AWS Panorama dove il modello e il descrittore sono archiviati in Amazon S3.
Esempio Pacchetti/123456789012-Squeezenet_pytorch-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
Nota
Specificate solo la versione principale e secondaria della versione del framework. Per un elenco delle versioni supportate PyTorch, di Apache MXNet e delle TensorFlow versioni, consulta Framework supportati.
Per importare un modello, usa il comando CLI import-raw-model dell'applicazione AWS Panorama. Se apporti modifiche al modello o al suo descrittore, devi eseguire nuovamente questo comando per aggiornare gli asset dell'applicazione. Per ulteriori informazioni, consulta Modifica del modello di visione artificiale.
Per lo schema JSON del file descrittore, vedete AssetDescriptor.schema.json.
Addestramento dei modelli
Quando addestrate un modello, utilizzate immagini provenienti dall'ambiente di destinazione o da un ambiente di test molto simile a quello di destinazione. Considerate i seguenti fattori che possono influire sulle prestazioni del modello:
-
Illuminazione: la quantità di luce riflessa da un soggetto determina la quantità di dettagli che il modello deve analizzare. Un modello addestrato con immagini di soggetti ben illuminati potrebbe non funzionare bene in un ambiente con scarsa illuminazione o retroilluminazione.
-
Risoluzione: la dimensione di input di un modello è in genere fissata a una risoluzione compresa tra 224 e 512 pixel di larghezza in un rapporto di aspetto quadrato. Prima di passare un fotogramma di video al modello, potete ridimensionarlo o ritagliarlo per adattarlo alle dimensioni richieste.
-
Distorsione dell'immagine: la lunghezza focale e la forma dell'obiettivo di una fotocamera possono causare una distorsione delle immagini lontano dal centro dell'inquadratura. La posizione di una fotocamera determina anche quali caratteristiche di un soggetto sono visibili. Ad esempio, una fotocamera a soffitto con obiettivo grandangolare mostrerà la parte superiore di un soggetto quando è al centro dell'inquadratura e una visione distorta del lato del soggetto man mano che si allontana dal centro.
Per risolvere questi problemi, è possibile preelaborare le immagini prima di inviarle al modello e addestrare il modello su una più ampia varietà di immagini che riflettono le variazioni negli ambienti del mondo reale. Se un modello deve funzionare in situazioni di illuminazione e con una varietà di telecamere, sono necessari più dati per l'addestramento. Oltre a raccogliere più immagini, è possibile ottenere più dati di addestramento creando varianti delle immagini esistenti che sono distorte o hanno un'illuminazione diversa.
