Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: Caricamento dei dati da Amazon S3
Questo tutorial guida attraverso l'intero processo di caricamento di dati nelle tabelle di database Amazon Redshift a partire dai file di dati in un bucket Amazon S3.
In questo tutorial, esegui quanto indicato di seguito:
-
Scarichi file di dati che utilizzano formati CSV, delimitati da caratteri e a larghezza fissa.
-
Creare un bucket Amazon S3 e quindi caricare i file di dati nel bucket.
-
Avviare un cluster Amazon Redshift e creare le tabelle di database.
-
Utilizzare i comandi COPY per caricare le tabelle dai file di dati su Amazon S3.
-
Risolvere gli errori di caricamento e modificare i comandi COPY per correggere gli errori.
Prerequisiti
Sono necessari i seguenti prerequisiti:
-
Un AWS account per avviare un cluster Amazon Redshift e creare un bucket in Amazon S3.
-
AWS Le tue credenziali (ruolo IAM) per caricare i dati di test da Amazon S3. Se hai bisogno di un nuovo ruolo IAM, vai a Creazione di ruoli IAM.
-
Un client SQL, ad esempio l'editor di query della console Amazon Redshift.
Questo tutorial è stato concepito in modo da essere svolto indipendentemente dagli altri. Oltre a questo tutorial, consigliamo di seguire i tutorial seguenti per avere una migliore comprensione del modo in cui progettare e utilizzare database Amazon Redshift.
-
Il manuale Guida alle operazioni di base di Amazon Redshift guiderà attraverso il processo di creazione di un cluster Amazon Redshift e nel caricamento di dati di esempio.
Panoramica di
È possibile aggiungere dati alle tabelle Amazon Redshift utilizzando un comando INSERT o COPY. Alla scala e alla velocità di un data warehouse Amazon Redshift, il comando COPY risulta molto più veloce ed efficace dei comandi INSERT.
Il comando COPY utilizza l'architettura MPP (Massively Parallel Processing) di Amazon Redshift per leggere e caricare dati in parallelo da più origini dati. È possibile caricare i file di dati su Amazon S3, Amazon EMR o qualsiasi host remoto accessibile mediante una connessione Secure Shell (SSH). In alternativa, è possibile caricare direttamente da una tabella Amazon DynamoDB.
In questo tutorial, sarà utilizzato il comando COPY per caricare dati da Amazon S3. Molti dei principi presentati qui sono validi anche per il caricamento da altre origini dati.
Per ulteriori informazioni sull'utilizzo del comando COPY, consultare le seguenti risorse:
Fase 1: creazione di un cluster
Se disponi già di un cluster che intendi utilizzare, puoi ignorare questa fase.
Per gli esercizi in questo tutorial, si utilizza un cluster a quattro nodi.
Come creare un cluster
-
Accedi Console di gestione AWS e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
Dal menu di navigazione, scegli Pannello di controllo dei cluster con provisioning.
Importante
Verifica di disporre delle autorizzazioni necessarie per eseguire le operazioni relative al cluster. Per informazioni sulla concessione delle autorizzazioni necessarie, consulta Autorizzazione di Amazon Redshift all'accesso ai servizi. AWS
-
In alto a destra, scegli la AWS regione in cui desideri creare il cluster. Ai fini del presente tutorial, selezionare Stati Uniti occidentali (Oregon).
-
Dal menu di navigazione, scegliere Clusters (Cluster), quindi Create cluster (Crea cluster). Appare la pagina Create cluster (Crea cluster).
-
Alla pagina Creazione di un cluster inserire i parametri per il cluster. Scegliere i tuoi valori per i parametri, eccetto modificare i seguenti valori:
Scegliere
dc2.largeper il tipo di nodo.Scegliere
4per Numero di nodi.Nella sezione Cluster permissions (Autorizzazioni cluster), scegli un ruolo IAM da Available IAM roles (Ruoli IAM disponibili). Questo ruolo dovrebbe essere quello che creato in precedenza e che ha accesso ad Amazon S3. Quindi scegliere Add IAM role (Aggiungi ruolo IAM) per aggiungerlo all'elenco degli Attached IAM roles (Ruoli IAM collegati) del cluster.
-
Scegli Crea cluster.
Seguire la procedura riportata in Guida alle operazioni di base di Amazon Redshift per connettersi al cluster da un client SQL e testare una connessione. Non è necessario mettere in pratica le altre fasi indicate nella Guida Rapida relativa alla creazione di tabelle, al caricamento di dati e all'esecuzione di query di esempio.
Fase 2: download dei file di dati
In questa fase, scarichi un set di file di dati di esempio sul tuo computer. Nella fase successiva, i file verranno caricati in un bucket Amazon S3.
Per scaricare i file di dati
-
Scarica il file zippato: LoadingDataSampleFiles.zip.
-
Estrarre i file in una cartella sul computer.
-
Verificare che la cartella contenga i file seguenti.
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Fase 3: Caricamento dei file in un bucket Amazon S3
In questa fase, viene creato un bucket Amazon S3 e quindi i file di dati vengono caricati nel bucket.
Come caricare i file in un bucket Amazon S3
-
Creare un bucket in Amazon S3.
Per ulteriori informazioni sulla creazione di un bucket, consulta Creazione di un bucket nella Guida per l'utente di Amazon Simple Storage Service.
-
Accedi a Console di gestione AWS e apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/
-
Seleziona Crea bucket.
-
Scegli un Regione AWS.
Creare il bucket nella stessa regione del cluster. Se il cluster è nella regione Stati Uniti occidentali (Oregon), scegliere Regione Stati Uniti occidentali (Oregon) (us-west-2).
-
Immetti un nome per il bucket nella casella Nome bucket della finestra di dialogo Crea bucket.
Il nome di bucket scelto deve essere univoco tra tutti i nomi di bucket esistenti in Amazon S3. Una delle possibilità per garantire l'univocità consiste nell'aggiungere il nome dell'organizzazione come prefisso ai nomi dei bucket. I nomi di bucket devono soddisfare determinati requisiti. Per ulteriori informazioni, consultare Restrizioni e limitazioni dei bucket nella Guida per l'utente di Amazon Simple Storage Service.
-
Scegli le impostazioni predefinite suggerite per le restanti opzioni.
-
Seleziona Crea bucket.
Una volta che Amazon S3 ha completato la creazione del bucket, la console visualizza il bucket vuoto nel pannello Bucket.
-
-
Creare una cartella.
-
Scelta del nome del bucket.
-
Scegli il pulsante Crea cartella.
-
Assegnare il nome
loadalla nuova cartella.Nota
Il bucket creato non è in una sandbox. In questo esercizio aggiungi oggetti a un vero bucket. Per il tempo in cui conservi gli oggetti nel bucket, ti viene addebitato un importo nominale. Per maggiori informazioni sui prezzi di Amazon S3, consultare Prezzi di Amazon S3
.
-
-
Caricare i file di dati nel nuovo bucket Amazon S3.
-
Scegliere il nome della cartella di dati.
-
Nella procedura guidata Carica scegli Aggiungi file.
Segui le istruzioni della console Amazon S3 per caricare tutti i file scaricati ed estratti,
-
Scegli Carica.
-
Credenziali utente
Il comando COPY di Amazon Redshift deve avere accesso in lettura agli oggetti file nel bucket Amazon S3. Se si utilizzano le stesse credenziali utente per creare il bucket Amazon S3 ed eseguire il comando COPY di Amazon Redshift, questo comando disporrà di tutte le autorizzazioni necessarie. Se si desidera utilizzare credenziali utente differenti, è possibile concedere l'accesso utilizzando i controlli accessi di Amazon S3. Il comando Amazon Redshift COPY richiede almeno due ListBucket GetObject autorizzazioni per accedere agli oggetti file nel bucket Amazon S3. Per ulteriori informazioni sul controllo degli accessi ad Amazon S3, consultare Gestione delle autorizzazioni di accesso alle risorse Amazon S3.
Fase 4: creazione delle tabelle di esempio
Per questo tutorial utilizza un set di tabelle basate sullo schema Star Schema Benchmark (SSB). Il diagramma seguente mostra il modello di dati SSB.

Le tabelle SSB potrebbero già essere presenti nel database corrente. In tal caso eliminale dal database prima di crearle con i comandi CREATE TABLE nella fase successiva. Le tabelle utilizzate in questo tutorial potrebbero avere attributi differenti rispetto alla tabelle esistenti.
Per creare le tabelle di esempio
-
Per eliminare le tabelle SSB, eseguire i seguenti comandi nel client SQL.
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
Eseguire i seguenti comandi CREATE TABLE nel client SQL.
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
Fase 5: esecuzione dei comandi COPY
In questa fase, esegui i comandi COPY per caricare ognuna della tabelle nello schema SSB. Gli esempi relativi al comando COPY illustrano il caricamento da differenti formati di file mediante varie opzioni del comando COPY nonché la risoluzione degli errori di caricamento.
Sintassi del comando COPY
La sintassi di base del comando COPY è descritta di seguito.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
Per eseguire un comando COPY, fornisci i valori seguenti.
Nome tabella
La tabella di destinazione per il comando COPY. La tabella deve esistere già nel database. La tabella può essere temporanea o persistente. Il comando COPY aggiunge i nuovi dati di input a tutte le righe esistenti nella tabella.
Elenco di colonne
Per impostazione predefinita, COPY carica i campi dai dati di origine nelle colonne della tabella nell'ordine. Puoi eventualmente specificare un elenco di colonne, ovvero un elenco di nomi di colonna separati da virgole, per associare i campi dei dati a colonne specifiche. In questo tutorial, non utilizzi elenchi di colonne. Per ulteriori informazioni, consultare Column List nel riferimento del comando COPY.
Origine dati
È possibile utilizzare il comando COPY per caricare dati da un bucket Amazon S3, un cluster Amazon EMR, un host remoto mediante una connessione SSH oppure da una tabella Amazon DynamoDB. Per questo tutorial, i file di dati saranno caricati in un bucket Amazon S3. Durante il caricamento da Amazon S3 è necessario fornire il nome del bucket e la posizione dei file di dati. Per farlo, indicare un percorso dell'oggetto per i file di dati o la posizione di un file manifest che elenchi esplicitamente ogni file di dati e la sua posizione.
-
Prefisso della chiave
Un oggetto archiviato in Amazon S3 è identificato in modo univoco da una chiave oggetto che include il nome del bucket, gli eventuali nomi delle cartelle e il nome dell'oggetto. Un prefisso della chiave fa riferimento a un insieme di oggetti con lo stesso prefisso. Il percorso oggetto è un prefisso di chiave che il comando COPY utilizza per caricare tutti gli oggetti che condividono quel prefisso. Ad esempio, il prefisso di chiave
custdata.txtpuò fare riferimento a un singolo file o a un insieme di file, ad esempiocustdata.txt.001,custdata.txt.002e così di seguito. -
File manifest
In alcuni casi, potrebbe essere necessario caricare file con prefissi diversi, ad esempio da più bucket o cartelle. In altri, potrebbe essere necessario escludere i file che condividono un prefisso. In questi casi, è possibile utilizzare un file manifest. Un file manifest elenca esplicitamente ogni file di caricamento e la relativa chiave oggetto univoca. Utilizzi un file manifest per caricare la tabella PART più avanti in questo tutorial.
Credenziali
Per accedere alle AWS risorse che contengono i dati da caricare, devi fornire le credenziali di AWS accesso a un utente con privilegi sufficienti. Queste credenziali includono un ruolo IAM (ARN) Amazon Resource Name (ARN). Per caricare dati da Amazon S3, le credenziali devono includere ListBucket e autorizzazioni. GetObject Ulteriori credenziali sono necessarie se i dati sono crittografati. Per ulteriori informazioni, consultare Parametri di autorizzazione nel riferimento del comando COPY. Per ulteriori informazioni sulla gestione degli accessi, consultare Gestione delle autorizzazioni di accesso alle risorse Amazon S3.
Opzioni
Puoi specificare vari parametri con il comando COPY per definire formati di file, gestire formati di dati, gestire errori e controllare altre funzionalità. In questo tutorial, utilizzi le seguenti opzioni e funzionalità del comando COPY:
-
Prefisso della chiave
Per informazioni su come caricare da più file specificando un prefisso chiave, consultare Caricamento della tabella PART mediante NULL AS.
-
Formato CSV
Per informazioni su come caricare i dati in formato CSV, consultare Caricamento della tabella PART mediante NULL AS.
-
NULL AS
Per informazioni su come caricare PART utilizzando l'opzione NULL AS, consultare Caricamento della tabella PART mediante NULL AS.
-
Character-delimited formato
Per informazioni su come utilizzare l'opzione DELIMITER, consultare Opzioni DELIMITER e REGION.
-
REGION
Per informazioni su come utilizzare l'opzione REGION, consultare Opzioni DELIMITER e REGION.
-
Fixed-format larghezza
Per informazioni su come caricare la tabella CUSTOMER dai dati a larghezza fissa, consultare Caricamento della tabella CUSTOMER mediante MANIFEST.
-
MAXERROR
Per informazioni su come utilizzare l'opzione MAXERROR, consultare Caricamento della tabella CUSTOMER mediante MANIFEST.
-
ACCEPTINVCHARS
Per informazioni su come utilizzare l'opzione ACCEPTINVCHARS, consultare Caricamento della tabella CUSTOMER mediante MANIFEST.
-
MANIFEST
Per informazioni su come utilizzare l'opzione MANIFEST, consultare Caricamento della tabella CUSTOMER mediante MANIFEST.
-
DATEFORMAT
Per informazioni su come utilizzare l'opzione DATEFORMAT, consultare Caricamento della tabella DWDATE mediante DATEFORMAT.
-
GZIP, LZOP e BZIP2
Per informazioni su come comprimere i file, consultare Caricare più file di dati.
-
COMPUPDATE
Per informazioni su come utilizzare l'opzione COMPUPDATE, consultare Caricare più file di dati.
-
Molteplici file
Per informazioni su come caricare più file, consultare Caricare più file di dati.
Caricamento delle tabelle SSB
Per caricare ognuna delle tabelle nello schema SSB, utilizzi i comandi COPY seguenti. Ogni comando comporta opzioni COPY e tecniche di risoluzione dei problemi differenti.
Per caricare le tabelle SSB:
Sostituisci il nome del bucket e AWS credenziali
I comandi COPY in questo tutorial hanno il formato illustrato di seguito.
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
Per ogni comando COPY:
-
Sostituiscilo
<your-bucket-name>con il nome di un bucket nella stessa regione del cluster.Questa fase presuppone che il bucket e il cluster siano nella stessa regione. In alternativa, è possibile specificare regione utilizzando l'opzione REGION con il comando COPY.
-
Sostituisci
<aws-account-id>e<role-name>con il tuo ruolo Account AWS e quello di IAM. Il segmento della stringa delle credenziali racchiuso tra virgolette singole non deve contenere spazi o interruzioni di riga. Tieni presente che l'ARN potrebbe differire leggermente nel formato rispetto all'esempio. È consigliabile copiare l'ARN per il ruolo dalla console IAM, per assicurarsi che sia accurato, quando esegui i comandi COPY.
Caricamento della tabella PART mediante NULL AS
In questa fase, utilizzi le opzioni CSV e NULL AS per caricare la tabella PART.
Il comando COPY consente il caricamento di dati da più file in parallelo, che è un'operazione molto più rapida rispetto al caricamento da un singolo file. Per illustrare questo principio, i dati di ogni tabella in questo tutorial sono suddivisi in otto file, anche se i file sono molto piccoli. In una fase successiva, confronterai la differenza di tempo tra il caricamento da un singolo file e da più file. Per ulteriori informazioni, consulta Caricamento di file di dati.
Prefisso della chiave
Puoi eseguire i caricamenti da più file specificando un prefisso di chiave per il set di file oppure elencando esplicitamente i file in un file manifest. In questa fase, utilizzerai un prefisso della chiave. In una fase successiva, utilizzerai un file manifest. Il prefisso di chiave 's3://amzn-s3-demo-bucket/load/part-csv.tbl' carica il seguente set di file nella cartella load.
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Formato CSV
CSV, acronimo di Comma Separated Values (valori separati da virgole), è un formato comune per l'importazione e l'esportazione di dati di fogli di calcolo. CSV è più flessibile del formato delimitato da virgole in quanto ti consente di includere stringhe tra virgolette nei campi. Le virgolette di delimitazione predefinite per COPY dal formato CSV sono le virgolette doppie ("), ma è possibile specificare un altro tipo di virgolette utilizzando l'opzione QUOTE AS. Quando si utilizzano le virgolette di delimitazione nel campo, creare una sequenza di escape aggiungendo virgolette di delimitazione aggiuntive.
Il seguente estratto da un file di CSV-formatted dati per la tabella PART mostra le stringhe racchiuse tra virgolette doppie (). "LARGE ANODIZED
BRASS" Mostra anche una stringa racchiusa tra doppie virgolette all'interno di una stringa di citazion ("MEDIUM ""BURNISHED"" TIN").
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
I dati della tabella PART contengono caratteri che generano un errore nell'esecuzione del comando COPY. In questo esercizio, individuiamo e correggiamo tali errori.
Per caricare i dati in formato CSV, aggiungi csv al comando COPY. Esegui il comando seguente per caricare la tabella PART.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
Potrebbe essere visualizzato un messaggio di errore simile al seguente.
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
Per ottenere maggiori informazioni sull'errore, esegui una query sulla tabella STL_LOAD_ERRORS. La query seguente utilizza la funzione SUBSTRING per ridurre le colonne e facilitare la lettura e utilizza LIMIT 10 per ridurre il numero di righe restituite. Puoi regolare i valori in substring(filename,22,25) allo scopo di includere la lunghezza del nome di bucket.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL AS
I fila di dati part-csv.tbl utilizzano il carattere di terminazione NUL (\x000 o \x0) per indicare valori NULL.
Nota
Nonostante un'ortografia molto simile, NUL e NULL non sono identici. NUL è un UTF-8 carattere con codepoint x000 che viene spesso utilizzato per indicare la fine del record (EOR). NULL è un valore SQL che rappresenta l'assenza di dati.
Per impostazione predefinita, COPY tratta un carattere di terminazione NUL come carattere di fine record e termina il record, generando spesso risultati imprevisti o un errore. Non esiste un singolo metodo standard per indicare NULL in un dato testuale. Perciò l'opzione NULL AS del comando COPY ti consente di specificare quale carattere sostituire con NULL durante il caricamento della tabella. In questo esempio, vuoi che COPY consideri il carattere di terminazione NUL come valore NULL.
Nota
La colonna della tabella che riceve il valore NULL deve essere configurata come nullable Ciò significa che non deve includere il vincolo NOT NULL nella specifica CREATE TABLE.
Per caricare la tabella PART utilizzando l'opzione NULL AS, esegui il comando COPY seguente.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
Per verificare che COPY ha caricato i valori NULL, esegui il comando seguente per selezionare solo le righe che contengono NULL.
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
Opzioni DELIMITER e REGION
Le opzioni DELIMITER e REGION sono importanti per capire come caricare i dati.
Character-delimited formato
I campi di un file delimitato da caratteri sono separati da un carattere specifico, ad esempio un carattere pipe (|), una virgola (,) o una tabulazione (\ t). Character-delimited i file possono utilizzare qualsiasi carattere ASCII singolo, incluso uno dei caratteri ASCII non stampabili, come delimitatore. Per specificare il carattere delimitatore, utilizzi l'opzione DELIMITER. Il delimitatore predefinito è una barra verticale ( | ).
L'estratto seguente dei dati della tabella SUPPLIER utilizza il formato delimitato da una barra verticale.
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
REGION
Quando possibile, dovresti collocare i dati di carico nella stessa AWS regione del cluster Amazon Redshift. Se tali dati e il cluster si trovano nella stessa regione, si riduce la latenza e si evitano i costi di trasferimento dei dati tra regioni. Per ulteriori informazioni, consulta Best practice di Amazon Redshift per il caricamento di dati.
Se devi caricare dati da una AWS regione diversa, utilizza l'opzione REGION per specificare la AWS regione in cui si trovano i dati di caricamento. Se specifichi una regione, tutti i dati di caricamento, inclusi i file manifest, devono trovarsi in tale regione. Per ulteriori informazioni, consulta REGION.
Ad esempio, se il cluster si trova nella Regione Stati Uniti orientali (Virginia settentrionale) e il bucket Amazon S3 si trova nella Regione Stati Uniti occidentali (Oregon), il comando COPY seguente mostra come caricare la tabella SUPPLIER a partire dai dati delimitati da barra verticale.
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
Caricamento della tabella CUSTOMER mediante MANIFEST
In questa fase, utilizzi le opzioni FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS e MANIFEST per caricare la tabella CUSTOMER.
I dati di esempio per questo esercizio contengono caratteri che genereranno errori quando il comando COPY tenta di caricarli. Utilizzi l'opzione MAXERRORS e la tabella di sistema STL_LOAD_ERRORS per risolvere gli errori di caricamento e quindi le opzioni ACCEPTINVCHARS e MANIFEST per eliminare gli errori.
Fixed-Width Formato
Fixed-width format definisce ogni campo come un numero fisso di caratteri, anziché separare i campi con un delimitatore. L'estratto seguente dei dati della tabella CUSTOMER utilizza il formato a larghezza fissa.
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
L'ordine delle label/width coppie deve corrispondere esattamente all'ordine delle colonne della tabella. Per ulteriori informazioni, consulta FIXEDWIDTH.
La stringa di specifica a larghezza fissa per i dati della tabella CUSTOMER è la seguente.
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
Per caricare la tabella CUSTOMER a partire dai dati a larghezza, esegui il comando seguente.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
Dovrebbe essere visualizzato un messaggio di errore simile al seguente.
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
Per impostazione predefinita, al primo errore, il comando COPY non riesce e restituisce un messaggio di errore. Per risparmiare tempo durante il testing, puoi utilizzare l'opzione MAXERROR per indicare a COPY di ignorare un determinato numero di errori prima di avere esito negativo. Poiché ci aspettiamo degli errori la prima volta che testiamo il caricamento dei dati della tabella CUSTOMER, aggiungi maxerror 10 al comando COPY.
Per eseguire il test utilizzando le opzioni FIXEDWIDTH e MAXERROR, esegui il comando seguente.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
Questa volta, anziché un messaggio di errore, viene restituito un messaggio simile al seguente.
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
L'avviso segnala che sono stati rilevati sette errori durante l'esecuzione di COPY. Per verificare gli errori, esegui una query sulla tabella STL_LOAD_ERRORS, come mostrato nell'esempio seguente.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
I risultati della query STL_LOAD_ERRORS devono essere simili a quanto segue.
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
Esaminando i risultati, è possibile notare che vi sono due messaggi nella colonna error_reasons:
-
Invalid digit, Value '#', Pos 0, Type: IntegQuesti errori sono dovuti al file
customer-fw.tbl.log. Il problema è che si tratta di un file di log e non di un file di dati, quindi non dovrebbe essere caricato. Puoi utilizzare un file manifest per evitare di caricare file non appropriati. -
String contains invalid or unsupported UTF8Il tipo di dati VARCHAR supporta UTF-8 caratteri multibyte fino a tre byte. Se i dati di caricamento contengono caratteri non supportati o non validi, puoi utilizzare l'opzione ACCEPTINVCHARS per sostituire ogni carattere non valido con un carattere alternativo specificato.
Un altro problema con il carico è più difficile da rilevare: il carico ha prodotto risultati imprevisti. Per analizzare questo problema, esegui una query sulla tabella CUSTOMER con il comando seguente.
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
Le righe devono essere univoche, ma in questo caso si hanno dei duplicati.
Un altro modo di rilevare risultati imprevisti è di verificare il numero di righe caricate. Nel nostro caso, avremmo dovuto avere 100000 righe caricate, ma il messaggio ha segnalato 112497 record. Le righe in eccesso sono state caricate in quanto il comando COPY ha caricato un file estraneo, customer-fw.tbl0000.bak.
In questo esercizio, utilizzi un file manifest per evitare di caricare i file non appropriati.
ACCEPTINVCHARS
Per impostazione predefinita, quando COPY incontra un carattere non supportato dal tipo di dati della colonna, ignora la riga e restituisce un errore. Per informazioni sui caratteri non validi, vedere. UTF-8 Errori di caricamento di caratteri multibyte
Potresti utilizzare l'opzione MAXERRORS per ignorare gli errori e continuare il caricamento, quindi eseguire una query su STL_LOAD_ERRORS per individuare i caratteri non validi e infine correggere i file di dati. Tuttavia, MAXERRORS è più appropriato per risolvere i problemi di caricamento e in genere non dovrebbe essere utilizzato in un ambiente di produzione.
L'opzione ACCEPTINVCHARS è generalmente una scelta più adatta per la gestione di caratteri non validi. ACCEPTINVCHARS indica a COPY di sostituire ogni carattere non valido con un carattere valido specificato e di proseguire l'operazione di caricamento. Come carattere sostitutivo puoi specificare qualsiasi carattere ASCII valido tranne NULL. Il carattere sostitutivo predefinito è un punto interrogativo (?). COPY sostituisce i caratteri multibyte con una stringa sostitutiva della stessa lunghezza. Ad esempio, un carattere di 4 byte viene sostituito da '????'.
COPY restituisce il numero di righe che contenevano caratteri non validi UTF-8 . Aggiunge inoltre una voce alla tabella di sistema STL_REPLACEMENTS per ogni riga interessata, fino a un massimo di 100 righe per sezione di nodo. Vengono inoltre sostituiti altri UTF-8 caratteri non validi, ma tali eventi sostitutivi non vengono registrati.
ACCEPTINVCHARS è valido solo per le colonne VARCHAR.
Per questa fase, aggiungi ACCEPTINVCHARS con il carattere sostitutivo '^'.
MANIFEST
Quando si esegue una copia da Amazon S3 con COPY utilizzando un prefisso della chiave, esiste il rischio di caricare tabelle non desiderate. Ad esempio, la cartella 's3://amzn-s3-demo-bucket/load/ contiene otto file di dati che condividono il prefisso di chiave customer-fw.tbl: customer-fw.tbl0000, customer-fw.tbl0001 e così di seguito. Tuttavia, la stessa cartella contiene anche file estranei, ovvero customer-fw.tbl.log e customer-fw.tbl-0001.bak.
Per essere certo di caricare tutti i file corretti e solo quelli, utilizza un file manifest. Il manifest è un file di testo in formato JSON che elenca esplicitamente la chiave oggetto univoca di ogni file di origine da caricare. Gli oggetti file possono essere in cartelle o in bucket differenti, ma nella stessa regione. Per ulteriori informazioni, consulta MANIFEST.
Quanto segue mostra il testo customer-fw-manifest.
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
Per caricare i dati per la tabella CUSTOMER mediante un file manifest
-
Aprire il file
customer-fw-manifestin un editor di testo. -
Sostituisci
<your-bucket-name>con il nome del tuo bucket. -
Salvare il file.
-
Caricare il file nella cartella di caricamento del bucket.
-
Esegui il seguente comando COPY.
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
Caricamento della tabella DWDATE mediante DATEFORMAT
In questa fase, utilizzi le opzioni DELIMITER and DATEFORMAT per caricare la tabella DWDATE.
Quando si caricano le colonne DATE e TIMESTAMP, COPY prevede il formato predefinito, che è YYYY-MM-DD per le date e i timestamp. YYYY-MM-DD HH:MI:SS Se i dati di caricamento non utilizzano il formato predefinito, puoi utilizzare DATEFORMAT e TIMEFORMAT per specificare il formato.
L'estratto seguente mostra i formati di data nella tabella DWDATE. Nota la discordanza tra i formati di data nella seconda colonna.
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
DATEFORMAT
Puoi specificare un solo formato di data. Se i dati di caricamento contengono formati discordanti in varie colonne o se il formato non è noto al momento del caricamento, utilizza DATEFORMAT con l'argomento 'auto'. Quando 'auto' è specificato, COPY riconoscerà qualsiasi formato di data o ora valido e lo convertirà nel formato predefinito. L'opzione 'auto' riconosce diversi formati che non sono supportati quando si utilizza una stringa DATEFORMAT e TIMEFORMAT. Per ulteriori informazioni, consulta Utilizzo del riconoscimento automatico con DATEFORMAT e TIMEFORMAT.
Per caricare la tabella DWDATE, esegui il comando COPY seguente.
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
Caricare più file di dati
Puoi utilizzare le opzioni GZIP e COMPUPDATE per caricare una tabella.
Puoi caricare una tabella da un singolo file di dati o da più file. In questo modo puoi confrontare i tempi di caricamento dei due metodi.
GZIP, LZOP e BZIP2
Puoi comprimere i tuoi file utilizzando i formati di compressione gzip, lzop o bzip2. Nel caso di caricamento da file compressi, COPY decomprime i file durante il processo di caricamento. La compressione di file consente di risparmiare spazio di storage e riduce i tempi di caricamento.
COMPUPDATE
Quando COPY carica una tabella vuota senza codifiche di compressione, analizza i dati di caricamento per determinare le codifiche ottimali. Modifica quindi la tabella per utilizzare tali codifiche prima dell'inizio del caricamento. Questo processo di analisi richiede tempo, ma è necessario al massimo una sola volta per tabella. Per risparmiare tempo, puoi ignorare questa fese disattivando COMPUPDATE. Per consentire una valutazione accurata dei tempi di copia con il comando COPY, disattivi COMPUPDATE per questa fase.
Molteplici file
Il comando COPY consente caricamenti di dati estremamente efficaci quando vengono eseguiti da molteplici file in parallelo anziché da un singolo file. Dividi i dati in file in modo che il numero di file sia un multiplo del numero di sezioni nel cluster. Facendolo, Amazon Redshift divide il carico di lavoro e distribuisce i dati in modo omogeneo tra le sezioni del cluster. Il numero di sezioni per nodo dipende dalla dimensione dei nodi del cluster. Per ulteriori informazioni sul numero di sezioni per ogni dimensione di nodo, consulta Informazioni su cluster e nodi nella Guida alla gestione di Amazon Redshift.
Ad esempio, i nodi di calcolo del cluster in questo tutorial hanno due sezioni ciascuno. In altre parole un cluster a quattro nodi ha otto sezioni. Nelle fasi precedenti, i dati di caricamento erano contenuti in otto file, anche se i file erano molto piccoli. Puoi confrontare la differenza di tempo tra il caricamento da un singolo file voluminoso e quello da più file.
Anche i file che contengono 15 milioni di record e occupano circa 1,2 GB sono molto piccoli nel contesto di Amazon Redshift. Ma sono sufficienti per dimostrare i vantaggi prestazionali inerenti al caricamento da più file.
L’immagine seguente mostra i file di dati per LINEORDER.
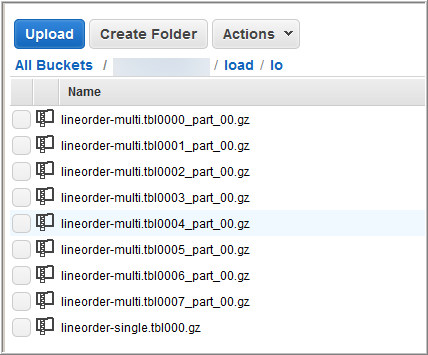
Per valutare le prestazioni di COPY con molteplici file
-
In un test di laboratorio, il comando seguente è stato eseguito per COPIARE da un singolo file. Questo comando mostra un bucket fittizio.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
I risultati sono stati i seguenti. Notare il tempo di esecuzione.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
Quindi è stato eseguito il comando seguente per effettuare COPIARE da più file.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
I risultati sono stati i seguenti. Notare il tempo di esecuzione.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
Confrontare i tempi di esecuzione.
Nel nostro esperimento, il tempo per caricare 15 milioni di record è passato da 51,56 secondi a 17,7 secondi, una riduzione del 65,7%.
Questi risultati sono basati sull'utilizzo di un cluster a quattro nodi. Se il cluster utilizzato ha più nodi, il risparmio di tempo sarà ancora maggiore. Per i cluster Amazon Redshift tipici, con decine di migliaia di nodi, la differenza sarà ancora più spettacolare. Se invece si dispone di un cluster a nodo singolo, la differenza tra i tempi di esecuzione sarà minima.
Fase 6: vacuum e analisi del database
Quando aggiungi, elimini o modifichi un numero significativo di righe, devi eseguire un comando VACUUM e quindi il comando ANALYZE. Un comando VACUUM recupera lo spazio dalle righe eliminate e ripristina l'ordinamento. Il comando ANALYZE aggiorna i metadati delle statistiche, consentendo all'ottimizzatore di query di generare piani di query più accurati. Per ulteriori informazioni, consulta Vacuum delle tabelle.
Se carichi i dati in base all'ordine delle chiavi di ordinamento, un vacuum è alquanto veloce. In questo tutorial, hai aggiunto un numero importante di righe, ma le hai aggiunte a delle tabelle vuote. Inoltre, non hai eliminato delle righe, di conseguenza non è necessario eseguire un riordinamento. Il comando COPY aggiorna automaticamente le statistiche dopo il caricamento di una tabella vuota, quindi le tue statistiche sono aggiornate. Tuttavia, per una corretta manutenzione, completi questo tutorial eseguendo un'operazione di vacuum e analizzando il database.
Per eseguire un vacuum e analizzare il database, esegui i comandi seguenti.
vacuum; analyze;
Fase 7: elimina le risorse
Il tuo cluster genera dei costi fino a che è in esecuzione. Una volta completato questo tutorial, sarà quindi necessario ripristinare lo stato precedente dell'ambiente seguendo le istruzioni contenute nella Fase 5: Revoca dell'accesso ed eliminazione del cluster di esempio in Guida alle operazioni di base di Amazon Redshift.
Se vuoi conservare il cluster, ma recuperare lo storage utilizzato dalle tabelle SSB, esegui i comandi seguenti.
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
Next
Riepilogo
In questo tutorial, sono stati caricati file di dati in Amazon S3 e quindi sono stati utilizzati i comandi COPY per caricare dati di file nelle tabelle Amazon Redshift.
Hai caricato i dati utilizzando i seguenti formati:
-
Character-delimited
-
CSV
-
Fixed-width
Hai utilizzato la tabella di sistema STL_LOAD_ERRORS e quindi le opzioni REGION, MANIFEST, MAXERROR, ACCEPTINVCHARS, DATEFORMAT e NULL AS per correggere gli errori di caricamento.
Hai applicato le seguenti best practice per il caricamento dei dati:
Per ulteriori informazioni sulle best practice di Amazon Redshift, fare riferimento ai seguenti collegamenti:
