Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Parametri e convalida
Questa guida mostra i parametri e le tecniche di convalida che è possibile utilizzare per misurare le prestazioni dei modelli di machine learning. Amazon SageMaker Autopilot produce metriche che misurano la qualità predittiva dei modelli di apprendimento automatico candidati. Le metriche calcolate per i candidati vengono specificate utilizzando una serie di tipi. MetricDatum
Parametri Autopilot
L'elenco seguente contiene i nomi dei parametri attualmente disponibili per misurare le prestazioni dei modelli in Autopilot.
Nota
Autopilot supporta i pesi dei campioni. Per ulteriori informazioni sui pesi dei campioni e sui parametri obiettivo disponibili, consulta Parametri ponderati per Autopilot.
I parametri disponibili sono i seguenti.
Accuracy-
Il rapporto tra il numero di elementi classificati correttamente e il numero totale di elementi classificati (correttamente e erroneamente). Viene utilizzato sia per la classificazione binaria che multiclasse. La precisione misura quanto i valori delle classi previsti si avvicinano ai valori effettivi. I valori per i parametri di precisione variano tra zero (0) e uno (1). Un valore pari a 1 indica una perfetta precisione e 0 indica una perfetta imprecisione.
AUC-
Il parametro dell'area sotto la curva (AUC) viene utilizzato per confrontare e valutare la classificazione binaria mediante algoritmi che restituiscono probabilità, come la regressione logistica. Per mappare le probabilità in classificazioni, queste vengono confrontate con un valore soglia.
La curva rilevante è la curva ROC (Receiver Operating Characteristic). La curva traccia la percentuale di veri positivi (True Positive Rate, TPR) delle previsioni (o recupero) rispetto alla percentuale di falsi positivi (False Positive Rate, FPR) in funzione del valore soglia, al di sopra del quale una previsione è considerata positiva. L’aumento della soglia comporta un minor numero di falsi positivi, ma più falsi negativi.
L’AUC è l’area sotto questa curva ROC. Pertanto, l’AUC fornisce una misura aggregata delle prestazioni del modello attraverso tutte le possibili soglie di classificazione. I punteggi AUC variano tra 0 e 1. Un punteggio di 1 indica una precisione perfetta, mentre un punteggio pari alla metà (0,5) indica che la previsione non è migliore di un classificatore casuale.
BalancedAccuracy-
BalancedAccuracyè un parametro che misura il rapporto tra previsioni accurate e tutte le previsioni. Questo rapporto viene calcolato dopo aver normalizzato i veri positivi (TP) e i veri negativi (TN) in base al numero totale di valori positivi (P) e negativi (N). Viene utilizzata sia nella classificazione binaria che in quella multiclasse ed è definita come segue: 0,5* ((TP/P)+(TN/N)), con valori compresi tra 0 e 1.BalancedAccuracyoffre una migliore misura di precisione quando il numero di aspetti positivi o negativi differisce notevolmente l'uno dall'altro in un set di dati squilibrato, ad esempio quando solo l'1% dei messaggi di posta elettronica è spam. F1-
Il punteggio
F1è la media armonica della precisione e del recupero, definita come segue: F1 = 2 * (precisione* recupero)/(precisione + recupero). Viene utilizzato per la classificazione binaria in classi tradizionalmente denominate positive e negative. Si dice che le previsioni siano vere quando corrispondono alla loro classe effettiva (corretta) e false quando non lo sono.La precisione è il rapporto tra le previsioni vere positive e tutte le previsioni positive e include i falsi positivi in un set di dati. La precisione misura la qualità della previsione quando prevede la classe positiva.
Il recupero (o sensibilità) è il rapporto tra le previsioni vere positive e tutte le istanze positive effettive. Il recupero misura la completezza con cui un modello prevede gli effettivi membri della classe in un set di dati.
I punteggi di F1 variano tra 0 e 1. Un punteggio pari a 1 indica la migliore prestazione possibile, mentre 0 indica la peggiore.
F1macro-
Il punteggio
F1macroapplica il punteggio F1 ai problemi di classificazione multiclasse. A tale scopo, calcola la precisione e il recupero, quindi utilizza la media armonica per calcolare il punteggio F1 per ogni classe. Infine, calcola la mediaF1macrodei punteggi individuali per ottenere il punteggio.F1macro. I punteggiF1macrovariano tra 0 e 1. Un punteggio pari a 1 indica la migliore prestazione possibile, mentre 0 indica la peggiore. InferenceLatency-
La latenza di inferenza è il periodo di tempo approssimativo che intercorre tra l'invio di una richiesta di previsione del modello e la sua ricezione da un endpoint in tempo reale su cui viene distribuito il modello. Questo parametro viene misurato in secondi ed è disponibile solo in modalità ensembling.
LogLoss-
La perdita di log, nota anche come perdita di entropia incrociata, è un parametro utilizzato per valutare la qualità degli output di probabilità, anziché gli output stessi. Viene utilizzato sia nella classificazione binaria che multiclasse e nelle reti neurali. È anche la funzione di costo per la regressione logistica. La perdita di log è un parametro importante per indicare quando un modello effettua previsioni errate con probabilità elevate. I valori tipici sono compresi tra 0 e infinito. Il valore 0 rappresenta un modello che prevede perfettamente i dati.
MAE-
La media degli errori assoluti (Mean Absolute Error, MAE) è una misura della differenza tra i valori previsti e quelli effettivi, quando viene calcolata la media di tutti i valori. La MAE è comunemente usata nell’analisi di regressione per comprendere l’errore di previsione del modello. In caso di regressione lineare, la MAE rappresenta la distanza media tra una linea prevista e il valore effettivo. La MAE è definita come la somma degli errori assoluti divisa per il numero di osservazioni. I valori sono compresi tra 0 e infinito, con numeri più piccoli che indicano una migliore adattabilità del modello ai dati.
MSE-
L'errore quadratico medio (Mean Squared Error, MSE) è la media delle differenze quadratiche tra i valori previsti e quelli effettivi. Viene utilizzato per la regressione. I valori MSE sono sempre positivi. Quanto più un modello è in grado di prevedere i valori effettivi, tanto più piccolo è il valore MSE.
Precision-
La precisione misura la capacità di un algoritmo di prevedere i veri positivi (TP) tra tutti i positivi che identifica. È definita come segue: Precisione = TP/ (TP+FP), con valori compresi tra zero (0) e uno (1), e viene utilizzata nella classificazione binaria. La precisione è un parametro importante quando il costo di un falso positivo è elevato. Ad esempio, il costo di un falso positivo è molto elevato se un sistema di sicurezza aereo viene erroneamente considerato sicuro da pilotare. Un falso positivo (FP) riflette una previsione positiva che in realtà è negativa nei dati.
PrecisionMacro-
La macro di precisione calcola la precisione per i problemi di classificazione multiclasse. A tale scopo, calcola la precisione per ogni classe e calcola la media dei punteggi per ottenere la precisione per diverse classi. I punteggi
PrecisionMacrosono compresi tra zero (0) e uno (1). I punteggi più alti riflettono la capacità del modello di prevedere i veri positivi (TP) tra tutti i positivi che identifica, calcolando la media tra più classi. R2-
R 2, noto anche come coefficiente di determinazione, viene utilizzato nella regressione per quantificare in che misura un modello può spiegare la varianza di una variabile dipendente. I valori sono compresi tra uno (1) e meno uno (-1). I numeri più alti indicano una frazione più alta della variabilità spiegata. I valori
R2vicini allo zero (0) indicano che il modello può spiegare una minima parte della variabile dipendente. I valori negativi indicano un adattamento inadeguato e che il modello è superato da una funzione costante. Per la regressione lineare, questa è una linea orizzontale. Recall-
Il recupero misura la capacità di un algoritmo di prevedere correttamente tutti i veri positivi (TP) in un set di dati. Un vero positivo è una previsione positiva che è anche un valore positivo effettivo dei dati. Il recupero è definito come segue: Recupero = TP/ (TP+FN), con valori compresi tra 0 e 1. I punteggi più alti riflettono una migliore capacità del modello di prevedere i veri positivi (TP) nei dati. Viene utilizzato nella classificazione binaria.
Il recupero è importante quando si esegue il test per il cancro perché viene utilizzato per individuare tutti i veri aspetti positivi. Un falso positivo (FP) riflette una previsione positiva che in realtà è negativa nei dati. Spesso non è sufficiente misurare solo il recupero, perché prevedendo ogni output come un vero positivo si ottiene un punteggio di recupero perfetto.
RecallMacro-
La
RecallMacrocalcola il recupero per problemi di classificazione multiclasse calcolando il recupero per ogni classe e calcolando la media dei punteggi per ottenere il recupero per diverse classi. I punteggiRecallMacrosono compresi tra 0 e 1. I punteggi più alti riflettono la capacità del modello di prevedere i veri positivi (TP) in un set di dati, mentre un vero positivo riflette una previsione positiva che è anche un valore positivo effettivo nei dati. Spesso non è sufficiente misurare solo il recupero, perché prevedendo ogni output come un vero positivo si otterrà un punteggio di recupero perfetto. RMSE-
L’errore quadratico medio (RMSE) misura la radice quadrata della differenza quadratica tra i valori previsti e quelli effettivi, e viene calcolata la media di tutti i valori. Viene utilizzato nell’analisi di regressione per comprendere l’errore di previsione del modello. È un parametro importante per indicare la presenza di errori e valori anomali di un modello di grandi dimensioni. I valori sono compresi tra zero (0) e infinito, con numeri più piccoli che indicano una migliore adattabilità del modello ai dati. L’RMSE dipende dalla scala e non deve essere utilizzato per confrontare set di dati di dimensioni diverse.
I parametri calcolati automaticamente per un modello candidato sono determinati dal tipo di problema da risolvere.
Consulta la documentazione di riferimento dell' SageMaker API Amazon per l'elenco delle metriche disponibili supportate da Autopilot.
Parametri ponderati per Autopilot
Nota
Autopilot supporta i pesi dei campioni solo in modalità ensembling per tutti i parametri disponibili ad eccezione di Balanced Accuracy e InferenceLatency. BalanceAccuracy è dotato di un proprio schema di ponderazione per set di dati sbilanciati che non richiede pesi di campioni. InferenceLatency non supporta i pesi dei campioni. Entrambi i parametri Balanced Accuracy e InferenceLatency obiettivi ignorano i pesi dei campioni esistenti durante l’addestramento e la valutazione di un modello.
Gli utenti possono aggiungere una colonna di pesi di campioni ai propri dati per garantire che a ogni osservazione utilizzata per addestrare un modello di machine learning venga assegnato un peso corrispondente all'importanza percepita per il modello. Ciò è particolarmente utile negli scenari in cui le osservazioni nel set di dati hanno diversi gradi di importanza o in cui un set di dati contiene un numero sproporzionato di campioni di una classe rispetto ad altre. Assegnare un peso a ciascuna osservazione in base alla sua importanza o maggiore importanza per una classe minoritaria può aiutare le prestazioni complessive di un modello o garantire che un modello non sia orientato verso la classe di maggioranza.
Per informazioni su come passare i pesi dei campioni durante la creazione di un esperimento nell'interfaccia utente di Studio Classic, consulta il passaggio 7 della sezione Creazione di un esperimento Autopilot utilizzando Studio Classic.
Per informazioni su come passare i pesi dei campioni a livello di codice durante la creazione di un esperimento Autopilot utilizzando l'API, fai riferimento a Come aggiungere pesi di campioni a un processo AutoML in Crea un esperimento Autopilot a livello di programmazione.
Convalida incrociata in Autopilot
La convalida incrociata viene utilizzata per ridurre l'overfitting e il bias nella selezione del modello. Viene anche utilizzata per valutare la capacità di un modello di prevedere i valori di un set di dati di convalida invisibile, se il set di dati di convalida proviene dalla stessa popolazione. Questo metodo è particolarmente importante durante l'addestramento su set di dati che hanno un numero limitato di istanze di addestramento.
Autopilot utilizza la convalida incrociata per creare modelli in modalità di ottimizzazione degli iperparametri (HPO) e addestramento di ensembling. La prima fase del processo di convalida incrociata di Autopilot consiste nel suddividere i dati in k-fold.
Suddivisione in k-fold
La suddivisione in k-fold è un metodo che separa un set di dati di addestramento in input in più set di dati di addestramento e convalida. Il set di dati è suddiviso in k sottocampioni di uguali dimensioni chiamati fold. I modelli vengono quindi addestrati su k-1 fold e testati rispetto al fold k° rimanente, che è il set di dati di convalida. Il processo viene ripetuto k volte utilizzando un set di dati diverso per la convalida.
L'immagine seguente mostra la suddivisione k-fold con k = 4 fold. Ogni fold è rappresentato come una riga. Le caselle di colore scuro rappresentano le parti dei dati utilizzate nell'addestramento. Le restanti caselle di colore chiaro indicano i set di dati di convalida.

Autopilot utilizza la convalida incrociata k-fold sia per la modalità di ottimizzazione degli iperparametri (hyperparameter optimization, HPO) che per la modalità ensembling.
Puoi implementare modelli Autopilot creati utilizzando la convalida incrociata come faresti con qualsiasi altro modello Autopilot o di intelligenza artificiale. SageMaker
Modalità HPO
La convalida incrociata k-fold utilizza il metodo di suddivisione k-fold per la convalida incrociata. In modalità HPO, Autopilot implementa automaticamente la convalida incrociata k-fold per piccoli set di dati con al massimo 50.000 istanze di addestramento. L’esecuzione della convalida incrociata è particolarmente importante quando si esegue l'addestramento su set di dati di piccole dimensioni perché protegge dall'overfit e dal bias nella selezione.
La modalità HPO utilizza un valore k pari a 5 su ciascuno degli algoritmi candidati utilizzati per modellare il set di dati. Vengono addestrati più modelli su diverse suddivisioni e i modelli vengono archiviati separatamente. Una volta completato l’addestramento, viene calcolata la media dei parametri di convalida per ciascuno dei modelli per produrre un unico parametro di stima. Infine, Autopilot combina i modelli della versione di prova con il migliore parametro di convalida in un modello di ensembling. Autopilot utilizza questo modello di ensembling per fare previsioni.
Il parametro di convalida per i modelli addestrati da Autopilot viene presentato come parametro obiettivo nella classifica dei modelli. Autopilot utilizza il parametro di convalida predefinito per ogni tipo di problema che gestisce, a meno che non venga specificato diversamente. Per un elenco di tutti i parametri utilizzati da Autopilot, consulta Parametri Autopilot.
Ad esempio, il set di dati Patrimonio immobiliare di Boston
La convalida incrociata può aumentare i tempi di addestramento del 20% in media. I tempi di addestramento possono inoltre aumentare in modo significativo per set di dati complessi.
Nota
In modalità HPO, puoi visualizzare le metriche di formazione e convalida di ogni riquadro nei tuoi log. /aws/sagemaker/TrainingJobs CloudWatch Per ulteriori informazioni sui CloudWatch registri, consulta. CloudWatch Registri per Amazon SageMaker AI
Modalità ensembling
Nota
Autopilot supporta i pesi dei campioni in modalità ensembling. Per l'elenco dei parametri disponibili che supportano i pesi dei campioni, consulta Parametri Autopilot.
In modalità ensembling, la convalida incrociata viene eseguita indipendentemente dalla dimensione del set di dati. I clienti possono fornire il proprio set di dati di convalida e il rapporto di suddivisione dei dati personalizzato oppure lasciare che Autopilot suddivida automaticamente il set di dati in un rapporto di suddivisione dell'80-20%. I dati di addestramento vengono quindi suddivisi in k -fold per la convalida incrociata, dove il valore di k è determinato dal motore. AutoGluon Un ensemble è costituito da più modelli di machine learning, in cui ogni modello è noto come modello base. Un singolo modello di base viene addestrato sulle pieghe (k-1) e fa out-of-fold previsioni sulla piega rimanente. Questo processo viene ripetuto per tutte le k pieghe e le previsioni out-of-fold (OOF) vengono concatenate per formare un unico set di previsioni. Tutti i modelli base dell'ensemble seguono lo stesso processo di generazione delle previsioni OOF.
L'immagine seguente mostra la convalida k-fold con k = 4 fold. Ogni fold è rappresentato come una riga. Le caselle di colore scuro rappresentano le parti dei dati utilizzate nell'addestramento. Le restanti caselle di colore chiaro indicano i set di dati di convalida.
Nella parte superiore dell'immagine, in ogni fold, il primo modello di base effettua previsioni sul set di dati di convalida dopo l'addestramento sui set di dati di addestramento. A ogni fold successivo, i set di dati cambiano ruolo. Un set di dati precedentemente utilizzato per l’addestramento viene ora utilizzato per la convalida, e ciò vale anche al contrario. Alla fine delle k pieghe, tutte le previsioni vengono concatenate per formare un unico insieme di previsioni chiamato previsione (OOF). out-of-fold Questo processo viene ripetuto per ogni n modelli base.
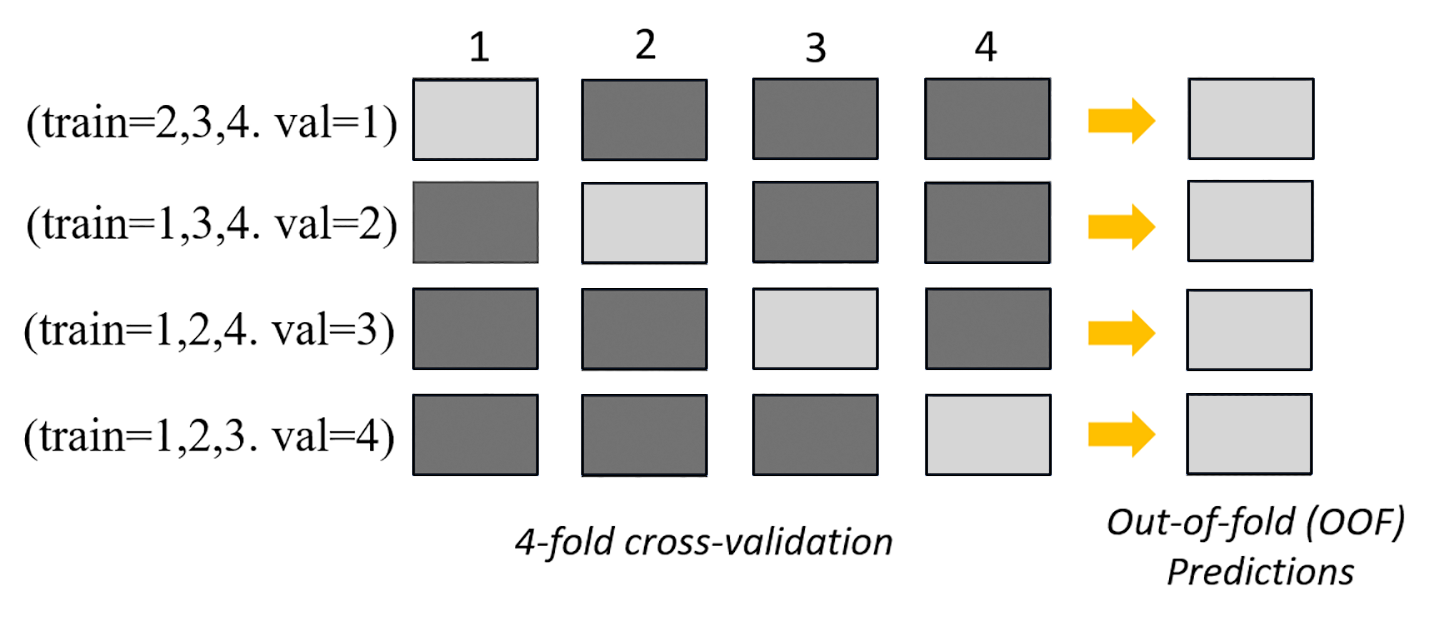
Le previsioni OOF per ogni modello base vengono quindi utilizzate come funzionalità per addestrare un modello di impilamento. Il modello di impilamento apprende i pesi di importanza per ogni modello base. Questi pesi vengono utilizzati per combinare le previsioni OOF per formare la previsione finale. Le prestazioni del set di dati di convalida determinano quale modello base o di impilamento è il migliore e questo modello viene restituito come modello finale.
In modalità ensemble, puoi fornire il tuo set di dati di convalida o lasciare che Autopilot suddivida automaticamente il set di dati di input in set di dati di addestramento all'80% e di convalida al 20%. I dati di addestramento vengono quindi suddivisi in k-fold per la convalida incrociata e producono una previsione OOF e un modello base per ogni fold.
Queste previsioni OOF vengono utilizzate come funzionalità per addestrare un modello di impilamento, che apprende simultaneamente i pesi per ogni modello base. Questi pesi vengono utilizzati per combinare le previsioni OOF per formare la previsione finale. I set di dati di convalida per ogni fold vengono utilizzati per l’ottimizzazione degli iperparametri di tutti i modelli base e del modello di impilamento. Le prestazioni del set di dati di convalida determinano quale modello base o di impilamento è il migliore e questo modello viene restituito come modello finale.
