Amazon Aurora DB クラスターのボリュームのクローン作成
Aurora クローン作成を使用すると、元のクラスターと同じデータページを共有するものの、個別の独立したボリュームを持つ新しいクラスターを作成できます。このプロセスは、高速で、費用効果が高いように設計されています。関連付けられたデータボリュームを持つ新しいクラスターは、クローンと呼ばれます。クローンの作成は、スナップショットの復元など、他の手法を使用してデータを物理的にコピーするよりも、高速かつスペース効率に優れています。
トピック
Aurora クローン作成の概要
Aurora では、クローン作成に、コピーオンライトプロトコルが使用されます。このメカニズムでは、初期クローンを作成するために使用する追加領域は最小限です。クローンが初期に作成されると、Aurora は、ソース Aurora DB クラスターと新しい (クローンの) Aurora DB クラスターで使用されるデータのコピーを 1 つだけ保持します。追加のストレージは、ソース Aurora DB クラスターまたは Aurora DB クラスターのクローンが (Aurora ストレージボリューム上の) データに変更を加えた場合にのみ割り当てられます。コピーオンライトプロトコルの詳細については、「Aurora クローン作成の仕組み」を参照してください。
Aurora のクローン作成は、データを破損の危険にさらすことなく、本番データを使用してテスト環境を迅速にセットアップする場合に特に役立ちます。クローンは、次のようなさまざまなタイプのアプリケーションに使用できます。
-
潜在的な変更 (スキーマの変更やパラメータグループの変更など) を試して、すべての影響を評価する。
-
データのエクスポートや分析クエリの実行など、大量のワークロードを扱うオペレーションをクローン上で実行する。
-
開発、テスト、またはその他の目的のために、本番 DB クラスターのコピーを作成する。
同じ Aurora DB クラスターから複数のクローンを作成できます。また、別のクローンから複数のクローンを作成することもできます。
Aurora クローンを作成したら、その Aurora DB インスタンスを、ソース Aurora DB クラスターとは異なる設定にできます。例えば、開発用途のクローンは、ソース本番 Aurora DB クラスターと同じ高可用性要件を満たす必要がない場合があります。この場合、Aurora DB クラスターで使用される複数の DB インスタンスではなく、単一の Aurora DB インスタンスを使用するようにクローンを設定できます。
作成元とは異なるデプロイ設定を使用してクローンを作成すると、作成元の Aurora DB エンジンの最新のマイナーバージョンを使用してクローンが作成されます。
Aurora DB クラスターからクローンを作成すると、クローンは作成者の AWS アカウント (ソース Aurora DB クラスターを所有しているアカウントと同じアカウント) に作成されます。ただし、Aurora Serverless v2 とプロビジョニングされた Aurora DB クラスターおよびクローンを他の AWS アカウントと共有することもできます。詳細については、「AWS RAM および Amazon Aurora を使用したクロスアカウントのクローン作成」を参照してください。
テスト、開発などの用途へのクローンの使用が終了したら、クローンを削除できます。
Aurora クローン作成の制限
Aurora のクローン作成には、現在、次の制約事項があります。
-
AWS リージョン で許可される DB クラスターの最大数まで、必要な数のクローンを作成できます。
-
copy-on-write プロトコルで最大 15 個のクローンを作成できます。クローンが 15 個になった後、次のクローンはフルコピーになります。フルコピープロトコルは、ポイントインタイムリカバリのように機能します。
-
ソース Aurora DB クラスターとは異なる AWS リージョンにはクローンを作成できません。
-
パラレルクエリ機能なしの Aurora DB クラスターから、パラレルクエリを使用するクラスターにクローンを作成することはできません。並行クエリを使用するクラスターにデータを格納するには、元のクラスターのスナップショットを作成して、並行クエリ機能を使用するクラスターにそれを復元します。
-
DB インスタンスを持たない Aurora DB クラスターからクローンを作成することはできません。少なくとも 1 つの DB インスタンスを持つ Aurora DB クラスターのクローン作成のみが可能です。
-
クローンは、Aurora DB クラスターとは異なる仮想プライベートクラウド (VPC) で作成できます。その場合、VPCのサブネットは同じアベイラビリティーゾーンにマッピングする必要があります。
-
プロビジョニングされた Aurora DB クラスターから、Aurora プロビジョニングされたクローンを作成できます。
-
Aurora Serverless v2 インスタンスを持つクラスターは、プロビジョンドクラスターと同じルールに従います。
-
Aurora Serverless v1 の場合:
-
Aurora Serverless v1 DB クラスターからプロビジョニングされたクローンを作成できます。
-
Aurora Serverless v1 または プロビジョニングされた DB クラスターから Aurora Serverless v1 クローンを作成できます。
-
暗号化されていないプロビジョニングされた Aurora DB クラスターからは Aurora Serverless v1 クローンを作成できません。
-
現在、Aurora Serverless v1 DB クラスターのクローン作成では、他のアカウントへのクローン作成はサポートされていません。詳細については、「クロスアカウントのクローン作成の制約事項」を参照してください。
-
クローンの Aurora Serverless v1 DB クラスターの動作と制限は、Aurora Serverless v1 DB クラスターと同じです。詳細については、「Amazon Aurora Serverless v1 の使用」を参照してください。
-
Aurora Serverless v1 DB クラスターは常に暗号化されます。クローンを作成するとき Aurora Serverless v1 DB クラスターをプロビジョニングされた Aurora DB クラスターに変換すると、プロビジョニングされた Aurora DB クラスターは暗号化されます。暗号化キーは選択できますが、暗号化を無効にすることはできません。プロビジョニングされた Aurora DB クラスターから Aurora Serverless v1 にクローンを作成するには、まず暗号化プロビジョニングされた Aurora DB クラスターから開始する必要があります。
-
Aurora クローン作成の仕組み
Aurora クローン作成は Aurora DB クラスターのストレージレイヤーで動作します。コピーオンライトプロトコルが使用されます。これは、Aurora ストレージボリュームをサポートする基盤となる耐久性の高いメディアという点で、高速かつスペース効率に優れています。Aurora クラスターボリュームの詳細については、「Amazon Aurora ストレージの概要」を参照してください。
コピーオンライトプロトコルの理解
Aurora DB クラスターでは、基になる Aurora ストレージボリュームのページにデータが格納されます。
例えば、次の図には、4 つのデータページ 1、2、3、4 を持つ Aurora DB クラスター (A) があります。クローン B が Aurora DB クラスターから作成されたとします。クローンが作成されても、データはコピーされません。クローンは、ソース Aurora DB クラスターと同じページのセットを参照しています。
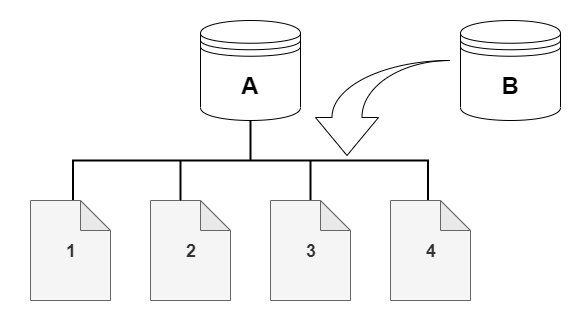
クローンが作成されたとき、通常は追加のストレージは必要ありません。コピーオンライトプロトコルでは、ソースセグメントと同じ物理ストレージメディア上のセグメントを使用します。追加のストレージが必要になるのは、ソースセグメントの容量がクローンセグメント全体に対して十分でない場合のみです。この場合、ソースセグメントは別の物理デバイスにコピーされます。
次の図に、前述と同様にクラスター A とそのクローン B を使用して動作中のコピーオンライトプロトコルの例を示します。Aurora DB クラスター (A) に変更を加えて、ページ 1 に保持されているデータが変更されたとします。元のページ 1 に書き込む代わりに、Aurora は新しいページ 1[A] を作成します。クラスター (A) の Aurora DB クラスターボリュームは、1[A]、2、3、4 ページを参照していますが、クローン (B) は引き続き元のページを参照しています。
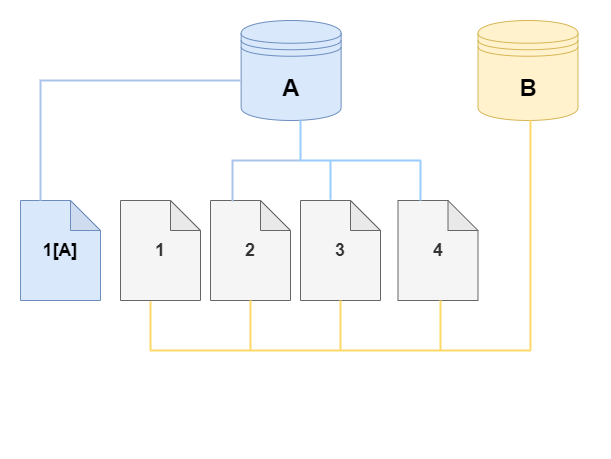
クローンでは、ストレージボリュームのページ 4 に変更が加えられています。元のページ 4 に書き込む代わりに、Aurora は新しいページ 4[B] を作成します。クローンはページ 1、2、3、およびページ 4[B] を参照し、クラスター (A) は引き続き 1[A]、2、3、4 を参照しています。
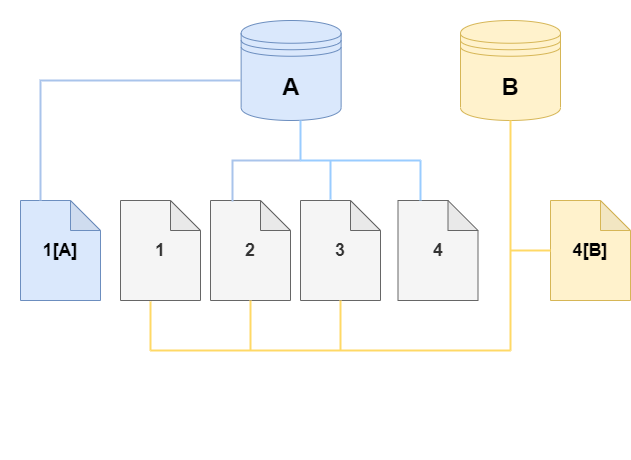
時間が経過してソース Aurora DB クラスターボリュームとクローンの両方で追加の変更があると、その変更をキャプチャして保存するためにさらにストレージが必要になります。
ソースクラスターボリュームの削除
当初、クローンボリュームは、クローンの作成元のボリュームと同じデータページを共有します。元のボリュームが存在する限り、クローンボリュームはクローンが作成または変更したページの所有者と見なされるのみです。したがって、クローンボリュームの VolumeBytesUsed メトリクスは最初は小さく、元のクラスターとクローンの間でデータが分岐するに従って増えていきます。ソースボリュームとクローン間でページが同じである場合、ストレージ料金は元のクラスターにのみ適用されます。VolumeBytesUsed メトリクスの詳細については、「Amazon Aurora のクラスターレベルのメトリクス」を参照してください。
1 つ以上のクローンが関連付けられているソースクラスターボリュームを削除しても、クローンのクラスターボリューム内のデータは変更されません。Aurora は、ソースクラスターボリュームが以前に所有していたページを保持します。Aurora は、削除したクラスターが所有していたページのストレージ料金を再分配します。例えば、元のクラスターに 2 つのクローンがあり、後で元のクラスターを削除したとします。元のクラスターが所有していたデータページの半分は、1 つのクローンが所有することになります。残りの半分のページは、もう 1 つのクローンが所有します。
元のクラスターを削除してクローンを作成または削除すると、Aurora は同じページを共有するすべてのクローン間で、データページの所有権を引き続き再配分します。したがって、クローンのクラスターボリュームに応じてメトリクスの値が変わることがわかります。より多くのクローンを作成して、ページの所有権がより多くのクラスターに分散されると、メトリクスの値は減少する可能性があります。また、クローンを削除して、ページの所有権を割り当てるクラスターの数が少なくなると、メトリクスの値は増える可能性があります。書き込みオペレーションがクローンボリュームのデータページにどのように影響するかについては、「コピーオンライトプロトコルの理解」を参照してください。
元のクラスターとクローンを同じ AWS アカウントが所有している場合、これらのクラスターのすべてのストレージ料金は同じ AWS アカウントに適用されます。一部のクラスターがクロスアカウントクローンである場合、元のクラスターを削除すると、クロスアカウントクローンを所有する AWS アカウントに追加のストレージ料金がかかる可能性があります。
例えば、クローンを作成する前に、クラスターボリュームに 1,000 件の使用済みデータページがあるとします。このクラスターのクローンを作成すると、当初のクローンボリュームの使用済みページはゼロです。クローンが 100 件のデータページに変更を加えると、その 100 ページだけがクローンボリュームに保存され、使用済みとしてマークされます。親ボリュームから変更されていない残りの 900 ページは、両方のクラスターで共有されます。この例で、親クラスターの場合は 1,000 ページ、クローンボリュームの場合は 100 ページに対してストレージ料金が発生します。
ソースボリュームを削除した場合、クローンのストレージ料金は、変更した 100 ページと元のボリュームの 900 の共有ページを含めて、合計 1,000 ページ分となります。
Amazon Aurora クローンの作成
ソース Aurora DB クラスターと同じ AWS アカウントにクローンを作成できます。そうするには、AWS Management Console または AWS CLI を使用して、その後の手順を行ってください。
別の AWS アカウントにクローン作成を許可したり、別の AWS アカウントとクローンを共有したりするには、AWS RAM および Amazon Aurora を使用したクロスアカウントのクローン作成 の手順を使用します。
AWS Management Console を使用して Aurora DB クラスターのクローンを作成する手順を以下に示します。
AWS Management Console を使用してクローンを作成すると、1 つの Aurora DB インスタンスを持つ Aurora DB クラスターができます。
これらの手順は、クローンを作成しているのと同じ AWS アカウントが所有する DB クラスターに適用されます。別の AWS アカウントが所有する DB クラスターの場合は、AWS RAM および Amazon Aurora を使用したクロスアカウントのクローン作成 を参照してください。
AWS を使用して、お客様の AWS Management Console アカウントが所有している DB クラスターのクローンを作成するには
AWS Management Console にサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 ナビゲーションペインで、[データベース] を選択します。
リストから Aurora DB クラスターを選択し、[アクション] で、[クローンの作成] を選択します。

[クローンの作成] ページが開きます。そこで、[設定]、[接続] などの Aurora DB クラスタークローンのオプションが設定できます。
-
[DB インスタンス識別子] に、作成する Aurora DB クラスターのクローンに付ける名前を入力します。
Aurora Serverless v1 DB クラスターの場合は、[キャパシティータイプ] に[プロビジョニング済み] または [サーバーレス] を選択します。
ソース Aurora DB クラスターが Aurora Serverless v1 DB クラスターまたは暗号化されているプロビジョニングされた Aurora DB クラスターであるときのみ、[サーバーレス] を選択することができます。
-
Aurora Serverless v2 またはプロビジョニングされた DB クラスターの場合は、[クラスターストレージ設定] に Aurora Standard または Aurora I/O-Optimized を選択します。
詳細については、「Amazon Aurora DB クラスターのストレージ設定」を参照してください。
-
DB インスタンスのサイズまたは DB クラスターの容量を選択してください。
-
プロビジョニングされたクローンの場合は、DB インスタンスクラスを選択します。
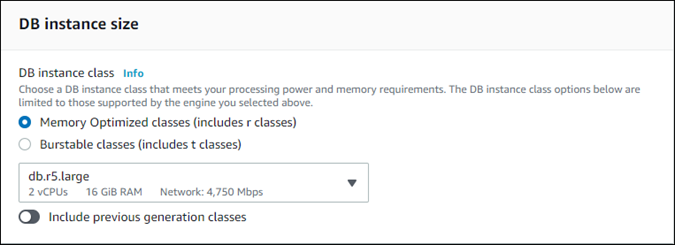
用意されている設定のままにすることも、クローンに別の DB インスタンスクラスを使用することもできます。
-
Aurora Serverless v1 または Aurora Serverless v2 クローンの場合は、[容量設定] を選択します。
用意されている設定のままにすることも、クローンに合わせて変更することもできます。
-
-
クローンに必要な他の設定を選択します。Aurora DB クラスターとインスタンスの設定の詳細については、「Amazon Aurora DB クラスターの作成」を参照してください。
-
[クローンの作成] を選択します。
クローンが作成されると、コンソールの [データベース] セクションに他の Aurora DB クラスターとともに一覧表示され、現在の状態が表示されます。状態が [使用可能] の場合は、クローンはすぐに使用できます。
Aurora DB クラスターのクローン作成に AWS CLI を使用するには、クローンクラスターを作成し、1 つ以上の DB インスタンスを追加するステップが必要です。
restore-db-cluster-to-point-in-time AWS CLI コマンドを使用した結果として、元のクラスターと同じストレージデータを持つ Aurora DB クラスターができますが、Aurora DB インスタンスは生成されません。DB インスタンスは、クローンが使用可能になった後に個別に作成します。DB インスタンスとそのインスタンスクラスの数を選択して、クローンに元のクラスターより多いか少ない計算容量を与えることができます。プロセスのステップは次のとおりです。
-
restore-db-cluster-to-point-in-time CLI コマンドを使用して、クローンを作成します。
-
create-db-instance CLI コマンドを使用して、クローンのライター DB インスタンスを作成します。
-
(オプション) 追加の create-db-instance CLI コマンドを実行して、クローンクラスターに 1 つ以上のリーダーインスタンスを追加します。リーダーインスタンスを使用すると、クローンの高可用性と読み取りスケーラビリティの側面が向上します。クローンを開発とテストにのみ使用する場合は、このステップをスキップできます。
クローンの作成
restore-db-cluster-to-point-in-time CLI コマンドを使用して、最初のクローンクラスターを作成します。
ソース Aurora DB クラスターからクローンを作成するには
-
restore-db-cluster-to-point-in-timeCLI コマンドを使用します。次のパラメータの値を指定します。この一般的なケースでは、クローンは元のクラスターと同じエンジンモード (プロビジョニングされた または Aurora Serverless v1) を使用します。-
--db-cluster-identifier- クローン用の意味のある名前を選択します。restore-db-cluster-to-point-in-time CLI コマンド使用時に、クローンに名前を付けます。次に、create-db-instance CLI コマンドで、クローンの名前を渡します。 -
--restore-type- ソース DB クラスターのクローンの作成にcopy-on-writeを使用します。このパラメータを指定しない場合、restore-db-cluster-to-point-in-timeは、クローンを作成するのではなく、Aurora DB クラスターを復元します。 -
--source-db-cluster-identifier- クローンを作成するソース Aurora DB クラスターの名前を使用します。 -
--use-latest-restorable-time- この値は、ソース DB クラスターの最新の復元可能なボリュームデータを指します。これを使用してクローンを作成します。
-
次の例では、my-source-cluster という名前のクラスターから my-clone という名前のクローンを作成します。
Linux、macOS、Unix の場合:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Windows の場合:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
このコマンドは、クローンの詳細を含む JSON オブジェクトを返します。クローンの DB インスタンスを作成する前に、作成した DB クラスターのクローンが使用可能であることを確認します。詳細については、「ステータスの確認とクローンの詳細の取得」を参照してください。
例えば、これからクローンを作成しようとしている tpch100g という名前のクラスターがあるとします。次の Linux の例では、tpch100g-clone という名前のクローンクラスター、tpch100g-clone-instance という名前の Aurora Serverless v2 ライターインスタンス、および新しいクラスター用の tpch100g-clone-instance-2 という名前のプロビジョニングされたリーダーインスタンスを作成します。
--master-username や --master-user-password など、いくつかのパラメータは指定する必要がありません。Aurora では、元のクラスターからそれらが自動的に決定されます。使用する DB エンジンについては、指定が必要です。この例では、新しいクラスターをテストして、--engine パラメータに使用する適切な値を判断します。
この例には、クローンクラスターの作成時に --serverless-v2-scaling-configuration オプションも含まれています。これにより、元のクラスターが Aurora Serverless v2 を使用していなくても、クローンに Aurora Serverless v2 インスタンスを追加できます。
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
ソース Aurora DB クラスターとは異なるエンジンモードでクローンを作成するには
-
この手順は、Aurora Serverless v1 をサポートする古いエンジンバージョンにのみ適用されます。Aurora Serverless v1 クラスターがあり、プロビジョニングされたクラスターであるクローンを作成するとします。その場合、
restore-db-cluster-to-point-in-timeCLI コマンドを使用して、前の例と同様のパラメータ値と、以下の追加パラメータを指定します。-
--engine-mode- このパラメータは、ソース Aurora DB クラスターとは異なるエンジンモードのクローンを作成する場合にのみ使用します。この手順は、Aurora Serverless v1 をサポートする古いエンジンバージョンにのみ適用されます。次のように--engine-modeとして渡す値を選択します。-
Aurora Serverless DB クラスターからプロビジョニングされた Aurora DB クラスターのクローンを作成するには、
--engine-mode provisionedを使用します。注記
Aurora Serverless v1 からクローンされたクラスターで Aurora Serverless v2 を使用する場合でも、クローンのエンジンモードを
provisionedとして指定します。その後、追加のアップグレードと移行のステップを実行します。 -
--engine-mode serverlessを使用して、プロビジョニングされた Aurora DB クラスターから Aurora Serverless v1 クローンを作成します。serverlessエンジンモードを指定すると、--scaling-configurationを選択することもできます。
-
-
--scaling-configuration- (オプション)--engine-mode serverlessの場合に使用して、Aurora Serverless v1 クローンの最小と最大の容量を設定します。このパラメータを使用しなかった場合、Aurora は DB エンジンとしてデフォルトの Aurora Serverless v1 容量値を使用して Aurora Serverless v1 クローンを作成します。
-
次の例では、my-source-cluster という名前の Aurora Serverless v1 DB クラスターから my-clone という名前のプロビジョニングされたクローンを作成します。
Linux、macOS、Unix の場合:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --engine-mode provisioned \ --restore-type copy-on-write \ --use-latest-restorable-time
Windows の場合:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --engine-mode provisioned ^ --restore-type copy-on-write ^ --use-latest-restorable-time
これらのコマンドは、DB インスタンスの作成に必要なクローンの詳細を含む JSON オブジェクトを返します。クローン (空の Aurora DB クラスター) のステータスが [使用可能] になるまでこれを実行できません。
注記
restore-db-cluster-to-point-in-time AWS CLI コマンドは、その DB クラスターの DB インスタンスではなく、DB クラスターのみを復元します。create-db-instance コマンドを実行して、復元された DB クラスターの DB インスタンスを作成します。このコマンドでは、復元された DB クラスターの識別子を --db-cluster-identifier パラメータとして指定します。restore-db-cluster-to-point-in-time コマンドが完了し、DB クラスターが使用可能になった後でのみ、DB インスタンスを作成できます。
Aurora Serverless v1 クラスターから開始し、Aurora Serverless v2 クラスターに移行するとします。移行の最初のステップとして、Aurora Serverless v1 クラスターのプロビジョニングされたクローンを作成します。必要なバージョンアップグレードを含む詳細な手順については、「Aurora Serverless v1 クラスターから Aurora Serverless v2 クラスターへのアップグレード」を参照してください。
ステータスの確認とクローンの詳細の取得
次のコマンドを使用して、新しく作成したクローンクラスターのステータスを確認できます。
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
または、次の AWS CLI クエリを使用して、ステータスなどの必要な値を取得して、クローン用の DB インスタンスを作成できます。
Linux、macOS、Unix の場合:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Windows の場合:
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
このクエリにより、以下のような出力が返されます。
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
クローン用の Aurora DB インスタンスの作成
Aurora Serverless v2 またはプロビジョニングされたクローン用の DB インスタンスを作成するには、create-db-instance CLI コマンドを使用します。Aurora Serverless v1 クローン用の DB インスタンスは作成しません。
DB インスタンスは、--master-username および --master-user-password プロパティを、ソース DB クラスターから引き継ぎます。
次の例では、プロビジョニングされたクローンの DB インスタンスを作成します。
Linux、macOS、Unix の場合:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Windows の場合:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
次の例では、Aurora Serverless v2 をサポートするエンジンバージョンを使用するクローンの Aurora Serverless v2 DB インスタンスを作成します。
Linux、macOS、Unix の場合:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Windows の場合:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
クローン作成に使用するパラメータ
次の表は restore-db-cluster-to-point-in-time を使用して Aurora DB クラスターのクローンを作成する際に使用されるさまざまなパラメータをまとめたものです。
| Parameter | 説明 |
|---|---|
|
|
クローンを作成するソース Aurora DB クラスターの名前を使用します。 |
|
|
|
|
|
|
|
|
この値は、ソース DB クラスターの最新の復元可能なボリュームデータを指します。これを使用してクローンを作成します。 |
|
|
(Aurora Serverless v2 をサポートする新しいバージョン) このパラメータを使用して、Aurora Serverless v2 クローンの最小容量と最大容量を設定します。このパラメータを指定しなかった場合、この属性を追加するようにクラスターを変更するまで、クローンクラスターに Aurora Serverless v2 インスタンスを作成することはできません。 |
|
|
(Aurora Serverless v1 をサポートする古いバージョンのみ) このパラメータを使用して、以下のいずれかの値でソース Aurora DB クラスターとは異なるタイプのクローンを作成します。
|
|
|
(Aurora Serverless v1 をサポートする古いバージョンのみ) このパラメータを使用して、Aurora Serverless v1 クローンの最小容量と最大容量を設定します。このパラメータを指定しない場合、Aurora は DB エンジンのデフォルトの容量値を使用してクローンを作成します。 |
クロス VPC およびクロスアカウントのクローン作成については、以下のセクションを参照してください。
