Amazon Aurora Global Database の使用
Amazon Aurora Global Database 機能では、複数の AWS リージョンにまたがる複数の Aurora DB クラスターを設定します。Aurora は、プライマリ DB クラスターで行われたすべての変更を 1 つ以上のセカンダリクラスターに自動的に同期します。Aurora Global Database では、1 つのリージョンにプライマリ DB クラスターがあり、異なるリージョンに最大 10 のセカンダリ DB クラスターがあります。このマルチリージョン設定により、AWS リージョン全体に影響を与えるような、まれな停止から迅速に復旧できます。また、すべてのデータの完全なコピーを複数の地理的場所に保持することで、世界中の広く離れた場所から接続するアプリケーションの低レイテンシーの読み取りオペレーションも可能になります。
トピック
Amazon Aurora Global Database の概要
Amazon Aurora Global Database 機能を使用すると、複数の AWS リージョンにまたがる単一の Aurora データベースを使用して、グローバルに分散したアプリケーションを実行できます。
Aurora Global Database は、データが書き込まれる 1 つのプライマリ AWS リージョンと、最大 10 の読み取り専用セカンダリ AWS リージョンで構成されます。書き込みオペレーションは、プライマリ AWS リージョン内のプライマリ DB クラスターに対して発行します。これを行う最も便利な方法は、Aurora Global Database ライターエンドポイントに接続することです。このエンドポイントは、別の AWS リージョン へのスイッチオーバーやフェイルオーバーの後でも、常にプライマリ DB クラスターを指します。書き込みオペレーションの後で、Aurora は、専用インフラストラクチャを使用して、通常 1 秒未満のレイテンシーで、データをセカンダリ AWS リージョンにレプリケートします。
次の図に、2 つの AWS リージョン にまたがる Aurora Global Database の例を示します。
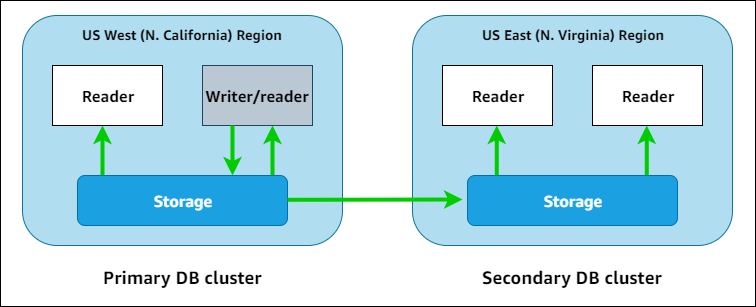
各セカンダリクラスターは、読み取り専用のワークロードを処理する Aurora リーダーインスタンスを 1 つ以上追加することで、個別にスケールアップできます。リーダーインスタンスで Aurora Serverless v2 を使用すると、より詳細で柔軟なスケーリングが可能になります。
書き込みオペレーションはプライマリクラスターのみが実行します。書き込みオペレーションを実行するクライアントは、Aurora Global Database ライターエンドポイントに接続します。このエンドポイントは、常にプライマリクラスターのライター DB インスタンスを指します。図に示すように、Aurora は、高速でオーバーヘッドの少ないレプリケーションを実現するために、データベースエンジンではなく、クラスターストレージボリュームを使用します。詳細についてはAmazon Aurora ストレージの概要を参照してください。
Aurora Global Database は、世界的規模で展開するアプリケーション向けに設計されています。複数の AWS リージョンにおける読み取り専用セカンダリ DB クラスターは、アプリケーションユーザーの近くで読み取りオペレーションを最適化するのに役立ちます。書き込み転送機能を使用すると、セカンダリクラスターからプライマリクラスターに書き込みリクエストを送信するようにグローバルデータベースを設定することもできます。詳細については、「Amazon Aurora Global Database の書き込み転送を使用する」を参照してください。
Aurora Global Database は、プライマリ DB クラスターのリージョンをシナリオに応じて変更する 2 つの異なるオペレーションとして、Aurora Global Database スイッチオーバーと Aurora Global Database フェイルオーバーをサポートしています。
-
リージョナルローテーションなどの計画された運用手順には、スイッチオーバーメカニズム (以前は「計画されたマネージドフェイルオーバー」と呼ばれていました) を使用します。この機能を使用すると、正常な Aurora Global Database のプライマリクラスターを、データを失うことなく、セカンダリリージョンの 1 つに再配置できます。詳細についてはAmazon Aurora Global Database に対するスイッチオーバーの実行を参照してください。
-
プライマリリージョンで機能が停止した後に Aurora Global Database を復旧するには、フェイルオーバーメカニズムを使用します。この機能では、プライマリ DB クラスターから別のリージョンへのフェイルオーバー (クロスリージョンフェイルオーバー) を行います。詳細についてはAurora Global Database のマネージドフェイルオーバーを実行するを参照してください。
Amazon Aurora Global Database の利点
Aurora Global Database を使用すると、以下の利点が得られます。
ローカルレイテンシーでのグローバルな読み取り – 世界中にオフィスを持つ企業は、Aurora Global Database を使用することで、プライマリ AWS リージョンで主要な情報ソースを最新状態に保つことができます。他のリージョンにあるオフィスは、自社のリージョンにある情報にローカルのレイテンシーでアクセスすることができます。
スケーラブルなセカンダリ Aurora DB クラスター – 読み取り専用インスタンスをセカンダリ AWS リージョンに追加することで、セカンダリクラスターをスケールできます。セカンダリクラスターは読み取り専用であるため、1 つの Aurora クラスターにつき、読み取り専用の DB インスタンスを通常の 15 件ではなく最大 16 件サポートできます。
プライマリ Aurora DB クラスターからセカンダリ Aurora DB クラスターへの高速レプリケーション - Aurora Global Database によるレプリケーションは、プライマリ DB クラスターのパフォーマンスにほとんど影響しません。DB インスタンスのリソースは、全面的にアプリケーションの読み取りおよび書き込みワークロードに当てられます。
リージョン全体にわたる停止からの回復 – セカンダリクラスターを使用すると、従来のレプリケーションソリューションよりも迅速 (低い RTO) に、かつ少ないデータ損失 (低い RPO) で、Aurora Global Database を新しいプライマリ AWS リージョンで使用できるようになります。
利用可能なリージョンとバージョン
機能の可用性とサポートは、各 Aurora データベースエンジンの特定のバージョン、および AWS リージョン によって異なります。Aurora Global Database のバージョンとリージョン可用性については、「Aurora グローバルデータベースでサポートされているリージョンと DB エンジン」を参照してください。
Amazon Aurora Global Database の制限
現在、Aurora Global Database には以下の制限があります。
Aurora Global Database は特定の AWS リージョン、および Aurora MySQL と Aurora PostgreSQL の特定のバージョンで使用できます。詳細については、「Aurora グローバルデータベースでサポートされているリージョンと DB エンジン」を参照してください。
Aurora Global Database には、サポート対象の Aurora DB インスタンスクラス、AWS リージョンの最大数などに関する特定の設定要件があります。詳細については、「Amazon Aurora Global Database の構成要件」を参照してください。
MySQL 5.7 と互換性のある Aurora MySQL の場合、Aurora Global Database スイッチオーバーにはバージョン 2.09.1 以上のマイナーバージョンが必要です。
-
Aurora Global Database でマネージドのクロスリージョンスイッチオーバーまたはフェイルオーバーを実行できるのは、プライマリ DB クラスターとセカンダリ DB クラスターのメジャーおよびマイナーのエンジンバージョンが同じである場合のみです。パッチレベルは、エンジンとエンジンバージョンに応じて、同じである必要がある場合と、異なっても構わない場合があります。プライマリクラスターとセカンダリクラスターの間でパッチレベルが異なる場合に、これらのオペレーションを許可するエンジンとエンジンバージョンのリストについては、「マネージドクロスリージョンスイッチオーバーまたはフェイルオーバーに対するパッチレベルの互換性」を参照してください。エンジンバージョン間で同じパッチレベルが必要な場合は、「Aurora Global Database のマニュアルフェイルオーバーを実行する」の手順に従ってフェイルオーバーを手動で実行できます。
Aurora Global Database は、現在、以下の Aurora 機能をサポートしていません。
-
Aurora Serverless v1
-
Aurora でのバックトラック
-
Aurora Global Database で RDS プロキシ機能を使用する際の制限については、「グローバル データベースを使用した RDS Proxy の制約事項」を参照してください。
マイナーバージョンの自動アップグレードは、グローバルデータベースの一部である Aurora MySQL クラスターと Aurora PostgreSQL クラスターには適用されません。なお、グローバルデータベースクラスターの一部である DB インスタンスに対してこの設定を指定できますが、その設定に効果はありません。
Aurora Global Database は、現在、セカンダリ DB クラスターで Aurora Auto Scaling をサポートしていません。
Aurora MySQL 5.7 を実行している Aurora Global Database でデータベースアクティビティストリーム (DAS) を使用するには、エンジンバージョンがバージョン 2.08 以上である必要があります。DAS の詳細については、「データベースアクティビティストリームを使用した Amazon Aurora のモニタリング」を参照してください。
-
現在、Aurora Global Database のアップグレードには以下の制限があります。
Aurora グローバルデータベースのメジャーバージョンアップグレードを実行している間、グローバルデータベースクラスターにカスタムパラメータグループを適用できません。グローバルクラスターの各リージョンにカスタムパラメータグループを作成し、アップグレード後に手動でリージョンクラスターに適用します。
-
Aurora MySQL に基づく Aurora グローバルデータベースでは、
lower_case_table_namesパラメータがオンの場合、Aurora MySQL バージョン 2 からバージョン 3 へのインプレースアップグレードを実行できません。使用できる方法の詳細については、「メジャーバージョンのアップグレード」を参照してください。 Aurora Global Database では、目標復旧時点 (RPO) 機能がオンになっている場合、Aurora PostgreSQL DB エンジンのメジャーバージョンアップグレードを実行できません。RPO 機能については、「Aurora PostgreSQL- ベースのグローバルデータベースの RPO (目標復旧時点) 管理」を参照してください。
Aurora Global Database では、標準プロセスを使用した Aurora MySQL バージョン 3.01 または 3.02 から 3.03 以上へのマイナーバージョンアップグレードは実行できません。使用するプロセスの詳細については、「エンジンのバージョンを変更して Aurora MySQL アップグレードする」を参照してください。
Aurora Global Database のアップグレードについては、「Amazon Aurora Global Database のアップグレード」を参照してください。
グローバルデータベースの Aurora DB クラスターを個別に停止または起動することはできません。詳細についてはAmazon Aurora DB クラスターの停止と開始を参照してください。
セカンダリ Aurora DB クラスターにアタッチされた Aurora リーダー DB インスタンスは、特定の状況下で再起動できます。プライマリ AWS リージョンのライター DB インスタンスが再起動またはフェイルオーバーすると、セカンダリリージョンのリーダー DB インスタンスも再起動します。セカンダリクラスターは、その後、すべてのリーダー DB インスタンスがプライマリ DB クラスターのライターインスタンスと再び同期するまで使用できません。再起動時またはフェイルオーバー時のプライマリクラスターの動作は、単一の非グローバル DB クラスターの動作と同じです。詳細については、「Amazon Aurora でのレプリケーション」を参照してください。
プライマリ DB クラスターに変更を加えるときは、必ず事前に、 グローバルデータベースへの影響を把握してください。詳細については予期しない停止からの Amazon Aurora Global Database の復旧を参照してください。
Aurora Global Database は現在、Amazon Aurora から DB クラスターの AWS KMS キーにアクセスできなくなった場合の
inaccessible-encryption-credentials-recoverableステータスをサポートしていません。このような場合、暗号化された DB クラスターはターミナルのinaccessible-encryption-credentials状態になります。上記の状態についての詳細は、「DB クラスターステータスの表示」を参照してください。-
Secrets Manager は Aurora Global Database をサポートしていません。グローバルデータベースにリージョンを追加するときは、まず DB インスタンスの Secrets Manager 統合をオフにする必要があります。
-
Aurora Global Database を使用する Aurora PostgreSQL ベースの DB クラスターには、以下の制限があります。
クラスターキャッシュ管理は、Aurora Global Database の一部である Aurora PostgreSQL セカンダリ DB クラスターではサポートされません。
-
グローバルデータベースのプライマリ DB クラスターが Amazon RDS PostgreSQL インスタンスのレプリカをベースとしている場合、セカンダリクラスターを作成することはできません。そのクラスターから、AWS Management Console、AWS CLI、または
CreateDBClusterAPI オペレーションを使用してセカンダリを作成しようとしないでください。作成しようとするとタイムアウトし、セカンダリクラスターは作成されません。
プライマリと同じバージョンの Aurora DB エンジンを使用して、グローバルデータベースのセカンダリ DB クラスターを作成することをお勧めします。詳細については、「Amazon Aurora Global Database の作成」を参照してください。
