DynamoDB でリレーショナルデータをモデル化する例
この例では、Amazon DynamoDB でリレーショナルデータをモデル化する方法について説明します。DynamoDB テーブルの設計は、「リレーショナルモデル化」に示されているリレーショナルオーダーのエントリスキーマに対応しています。これは、DynamoDB のリレーショナルデータ構造を表す一般的な方法である「隣接関係のリスト設計パターン」に基づいています。
この設計パターンでは、通常、リレーショナルスキーマのさまざまなテーブルに相関するエンティティタイプのセットを定義する必要があります。その後、エンティティ項目は、複合 (パーティションおよびソート) のプライマリキーを使用してテーブルに追加されます。これらのエンティティ項目のパーティションキーは、項目を一意に識別する属性です。また、このパーティションキーは一般的に、すべての項目で PK と呼ばれます。ソートキー属性には、反転されたインデックスまたはグローバルセカンダリインデックスに使用できる属性値が含まれています。これは、一般的に SK と呼ばれます。
以下のエンティティを定義します。このエンティティは、リレーショナルオーダーのエントリスキーマをサポートしています。
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK: CountryId, SK: Country Name
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
HR-Department - PK: DepartmentID, SK: DepartmentName
-
OE-Customer - PK: CustomerID, SK: AccountRepID
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
これらのエンティティ項目をテーブルに追加したら、エンティティ項目のパーティションにエッジ項目を追加することで、それらのエンティティ項目間の関係を定義できます。このステップを以下のテーブルに示します。

この例では、Employee、Order、Product
Entity のパーティションには、テーブル上の他のエンティティ項目へのポインタを含む追加のエッジ項目があります。次に、以前に定義されたすべてのアクセスパターンをサポートするために、グローバルセカンダリインデックス (GSI) をいくつか定義します。すべてのエンティティ項目で、プライマリキーまたはソートキー属性に同じタイプの値を使用するわけではありません。必要なことは、プライマリキー属性とソートキー属性をテーブルに挿入することだけです。
これらのエンティティの一部に適切な名前が使用されており、他のエンティティではソートキーバリューとして他のエンティティ ID が使用されているため、同じグローバルセカンダリインデックスで複数のタイプのクエリをサポートすることができます。この技術は、GSI 多重定義と呼ばれます。これにより、複数の項目タイプを含むテーブルのデフォルトの 20 のグローバルセカンダリインデックスの制限は効果的に排除されます。これは、GSI 1 として次の図に示されています。
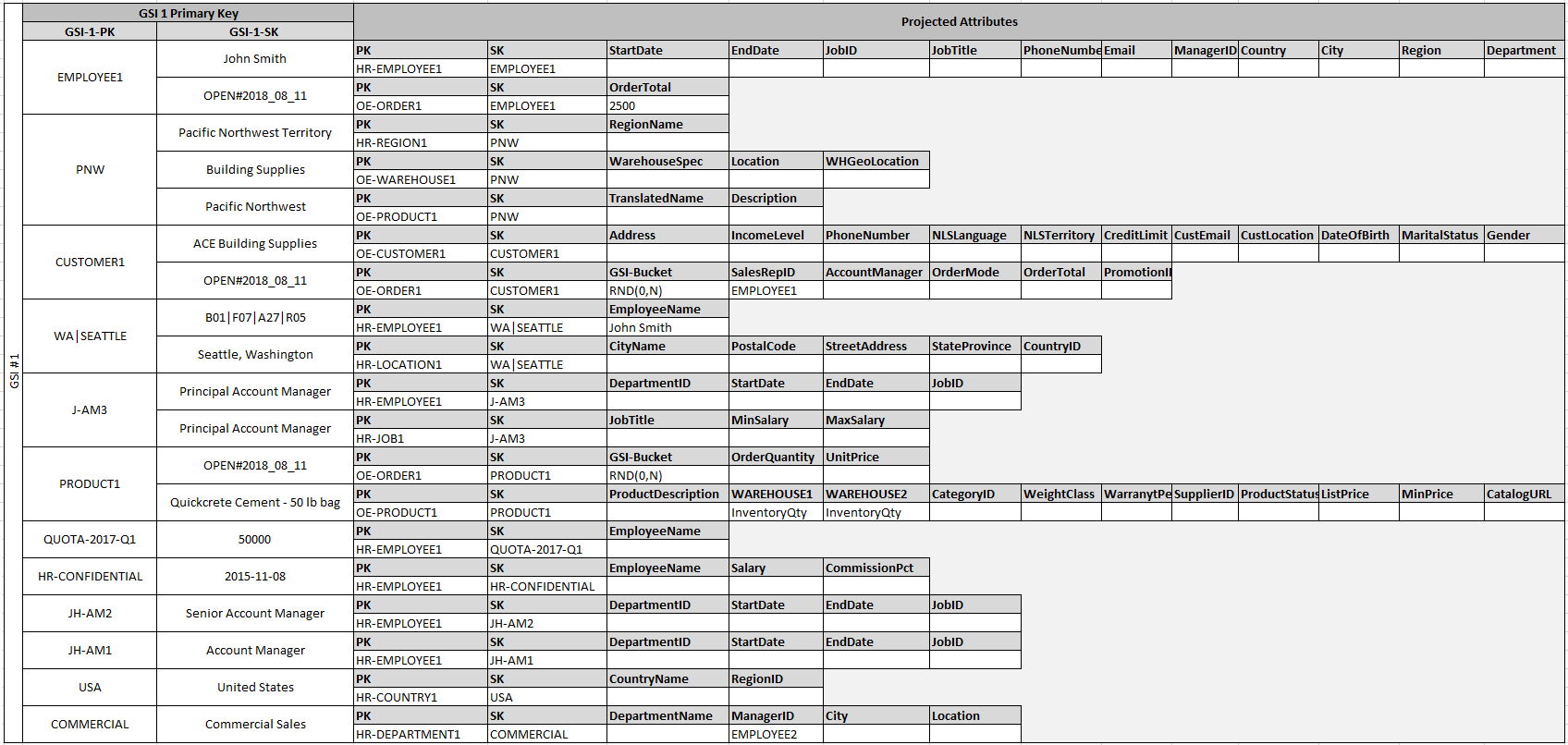
GSI 2 は、一般的なアプリケーションアクセスパターンをサポートするように設計されています。これは、特定の状態のテーブル上のすべての項目を取得することを目的としています。使用可能な状態間で項目の分散が不均一な大きなテーブルの場合は、この項目が、並列でクエリ可能な複数の論理パーティションに分散されていない限り、このアクセスパターンはホットキーになります。この設計パターンは、write sharding と呼ばれます。
GSI 2 で実現するには、アプリケーションで、すべての Order 項目に GSI 2 プライマリキー属性を追加します。これは、0〜N の範囲内の乱数にそれを移入します。N は、特別な理由がない限り、一般的に次の式を使用して計算できます。
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
例えば、次のことを前提とします。
-
最大 200 万件の注文がシステム内にあり、5 年間で 300 万件に増加します。
-
これらの注文のうち、最大 20% は任意の時点で OPEN 状態になります。
-
平均注文レコードは約 100 バイトで、注文パーティション内の 3 つの
OrderItemレコードはそれぞれ約 50 バイト、注文エンティティの平均サイズは 250 バイトです。
そのテーブルでは、N 係数の計算方法は次のようになります。
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
この場合、Order 状態のすべての OPEN 項目を読み込んでも、物理ストレージレイヤーにホットパーティションが発生しないように、GSI 2 の少なくとも 13 の論理パーティションにわたってすべての注文を分散させる必要があります。この番号は、データセットの異常を考慮した上で、埋め込むことをお勧めします。そのため、N = 15 を使用したモデルは問題ありません。前述したように、これを行うには、テーブルに挿入された Order レコードと OrderItem のレコードの GSI 2 PK 属性にランダムな 0~N 値を追加します。
この概要では、すべての OPEN の請求書を収集する必要があるアクセスパターンは比較的発生頻度が低いことを前提としているため、バースト容量を使用してリクエストを満たすことができます。State と Date Range のソートキー条件を使用して、次のグローバルセカンダリインデックスを照会し、必要に応じて特定の状態のサブセットまたはすべての Orders を生成することができます。

この例では、項目は 15 の論理パーティションにわたってランダムに分散されています。この構造は、アクセスパターンで多数の項目を取得する必要があるために機能します。したがって、15 スレッドのいずれかが空の結果セットを返して、無駄な容量を表すことはほとんどありません。何も返されなかった場合やデータが書き込まれていない場合でも、クエリは常に 1 つの読み込み容量ユニット (RCU) または 1 つの書き込み容量ユニット (WCU) を使用します。
アクセスパターンが、スパースの結果セットを返すこのグローバルセカンダリインデックスで、高速なクエリを必要とする場合は、項目を分散させるため、ランダムパターンではなく、ハッシュアルゴリズムを使用することをお勧めします。この場合、実行時にクエリが実行されたときに認識される属性を選択し、項目が挿入されたときにその属性を 0~14 のキースペースにハッシュします。その後、それらをグローバルなセカンダリインデックスから効率的に読み込むことができます。
最後に、前に定義したアクセスパターンを再度使用することができます。次に、新しい DynamoDB バージョンのアプリケーションで使用するアクセスパターンとクエリ条件の一覧を示します。
| S 番号 | アクセスパターン | クエリの状態 |
|---|---|---|
|
1 |
従業員 ID で従業員の詳細を検索する |
テーブルのプライマリキー、ID="HR-EMPLOYEE" |
|
2 |
従業員名で従業員の詳細をクエリする |
GSI-1、PK="Employee Name" を使用する |
|
3 |
従業員の現在のジョブの詳細のみを取得する |
テーブルのプライマリキー、PK=HR-EMPLOYEE-1、SK は「JH」で始まる |
|
4 |
日付範囲の顧客の注文を取得する |
GSI-1、PK=CUSTOMER1、SK="STATUS-DATE" を StatusCode ごとに使用する |
|
5 |
すべての顧客にわたって日付範囲内でステータスが OPEN のすべての注文を表示する |
GSI-2、範囲 [0..N] での並列の PK=query、SK を OPEN-Date1 と OPEN-Date2 の間で使用する |
|
6 |
最近雇用したすべての従業員 |
GSI-1、PK= "HR-CONFIDENTIAL'、SK > date1 を使用する |
|
7 |
特定の倉庫のすべての従業員を検索する |
GSI-1、PK=WAREHOUSE1 を使用する |
|
8 |
倉庫の場所の在庫も含めて、商品のすべての注文項目を取得する |
GSI-1、PK=PRODUCT1 を使用する |
|
9 |
アカウント担当者別に顧客を取得する |
GSI-1、PK=ACCOUNT-REP を使用する |
|
10 |
アカウント担当者および日付別に注文を取得する |
GSI-1、PK=ACCOUNT-REP、SK="STATUS-DATE" を StatusCode ごとに使用する |
|
11 |
特定の役職を持つすべての従業員を取得する |
GSI-1、PK=JOBTITLE を使用する |
|
12 |
商品および倉庫別に在庫を取得する |
テーブルのプライマリキー、PK=OE-PRODUCT1、SK=PRODUCT1 |
|
13 |
商品在庫総数を取得する |
テーブルのプライマリキー、PK=OE-PRODUCT1、SK=PRODUCT1 |
|
14 |
注文合計および販売期間別にアカウント担当者をランク付けする |
GSI-1、PK=YYYY-Q1、scanIndexForward=False を使用する |
