翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
統合モデルのリファレンス
パイプラインのリリースプロセスに、既存の顧客ツールを構築するのに役立つサードパーティーサービスのための事前構築済みの統合がいくつかあります。パートナーまたはサードパーティーのサービスプロバイダーは、統合モデルを使用して CodePipeline で使用するアクションタイプを実装します。
このリファレンスは、CodePipeline でサポートされている統合モデルで管理されるアクションタイプを計画または操作するときに使用します。
CodePipeline とのパートナー統合としてサードパーティーのアクションタイプを認証するには、 AWS パートナーネットワーク (APN) を参照してください。この情報は、AWS CLI リファレンス を補足するものです。
インテグレータとサードパーティーのアクションタイプがどのように機能するか
カスタマーパイプラインにサードパーティーのアクションタイプを追加して、顧客リソースのタスクを完了できます。インテグレータはジョブリクエストを管理し、CodePipeline でアクションを実行します。次の図表は、顧客がパイプラインで使用するために作成されたサードパーティーのアクションタイプを示しています。顧客がアクションを設定すると、アクションが実行され、インテグレータのアクションエンジンによって処理されるジョブリクエストが作成されます。
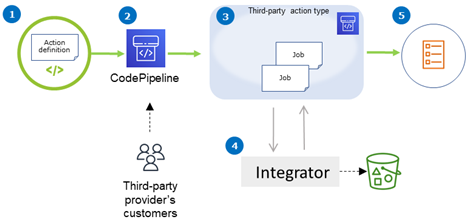
図表に示す内容は以下のステップです。
-
アクション定義が登録され、CodePipeline で使用できるようになります。サードパーティーのアクションは、サードパーティープロバイダのカスタマーに対して実行できます。
-
プロバイダーの顧客は CodePipeline でアクションを選択し、設定します。
-
アクションが実行され、ジョブが CodePipeline にキューに入れられます。CodePipeline でジョブの準備が整ったら、ジョブリクエストを送信します。
-
インテグレーター (サードパーティーポーリング API または Lambda 関数のジョブワーカー) は、ジョブリクエストを取得し、確認を返し、アクションのアーティファクトを処理します。
-
インテグレーターは、ジョブ結果と継続トークンを使用して、成功/失敗の出力 (ジョブワーカーは成功/失敗 API を使用するか、Lambda 関数が成功/失敗の出力を送信します) を返します。
アクションタイプのリクエスト、表示、および更新に使用できる手順については、 アクションタイプの使用 を参照してください。
概念
このセクションでは、サードパーティーのアクションタイプについて以下の用語を使用します。
- アクションタイプ
-
同じ継続的デリバリーのワークロードを実行するパイプラインで再利用できる反復可能なプロセス。アクションタイプは、
Owner、Category、Provider、およびVersion。例:{ "Category": "Deploy", "Owner": "AWS", "Provider": "CodeDeploy", "Version": "1" },同じタイプのアクションはすべて、同じ実装を共有します。
- アクション
-
アクションタイプの単一のインスタンス。パイプラインのステージ内で発生する個別のプロセスの1つです。これには、通常、このアクションが実行されるパイプラインに固有のユーザー値が含まれます。
- アクションの定義
-
アクションおよび入出力アーティファクトの構成に必要なプロパティを定義するアクションタイプのスキーマ。
- アクションの実行
-
顧客のパイプラインでのアクションが成功したかどうかを判断するために実行されたジョブの集まり。
- アクション実行エンジン
-
アクションタイプで使用される統合タイプを定義するアクション実行設定のプロパティ。有効な値は、
JobWorkerおよびLambdaです。 - Integration
-
アクションタイプを実装するためにインテグレータによって実行されるソフトウェアについて説明します。CodePipeline は、サポートされている 2 つのアクションエンジン
JobWorkerそしてLambdaに対応する 2 つの統合タイプをサポートしています。 - インテグレータ
-
アクションタイプの実装を所有している人。
- ジョブ
-
パイプラインと顧客コンテキストを使用して統合を実行するための作業です。アクションの実行は、1 つ以上のジョブで構成されます。
- ジョブワーカー
-
顧客入力を処理してジョブを実行するサービス。
サポートされている統合モデル
CodePipeline には 2 つの統合モデルがあります
-
Lambda 統合モデル:CodePipeline でアクションタイプを操作するには、この統合モデルが推奨されます。Lambda 統合モデルは、アクションの実行時に Lambda 関数を使用してジョブリクエストを処理します。
-
ジョブワーカー統合モデル: ジョブワーカー統合モデルは、サードパーティー統合で以前に使用されたモデルです。ジョブワーカー統合モデルは、 CodePipeline API にアクセスするように設定されたジョブワーカーを使用して、アクションの実行時にジョブリクエストを処理します。
比較のために、次の表に 2 つのモデルの特徴を示します。
| Lambda 統合モデル | ジョブワーカー統合モデル | |
|---|---|---|
| 説明 | インテグレータは、インテグレーションを Lambda 関数として書き込み、アクションで使用可能なジョブがあるたびに CodePipeline によって呼び出されます。Lambda 関数は、使用可能なジョブをポーリングするのではなく、次のジョブ リクエストが受信されるまで待機します。 | インテグレータは、インテグレーションをジョブワーカーとして書き込み、顧客のパイプラインで利用可能なジョブを常にポーリングします。その後ジョブワーカーはジョブを実行し、CodePipeline API を使用してジョブ結果を CodePipeline に送り返します。 |
| インフラストラクチャ | AWS Lambda | Amazon EC2 インスタンスなどのインテグレータのインフラストラクチャにジョブワーカーコードをデプロイします。 |
| 開発作業 | 統合にはビジネスロジックのみが含まれます。 | 統合は、ビジネスロジックを含めるだけでなく、CodePipeline API と対話する必要があります。 |
| Opsの努力 | インフラストラクチャは AWS リソースにすぎないため、運用の労力が少なくなります。 | ジョブワーカーはスタンドアロンのハードウェアを必要とするため、オペレーションの労力が高くなります。 |
| 最大ジョブのランタイム | 統合を 15 分以上アクティブに実行する必要がある場合は、このモデルを使用できません。このアクションは、プロセスを開始する (顧客のコードアーティファクトの構築を開始するなど)、終了時に結果を返す必要があるインテグレータを対象としています。インテグレータがビルドの終了を待ち続けることはお勧めしません。代わりに、継続 を返す。CodePipeline は、インテグレータのコードから継続を受け取り、終了するまでジョブをチェックすると、さらに 30 秒以内に新しいジョブを作成します。 | このモデルを使用すると、非常に長時間実行されるジョブ (時間/日) を維持できます。 |
Lambda 統合モデル
サポートされる Lambda 統合モデルには、Lambda 関数の作成と、サードパーティーアクションタイプの出力の定義が含まれます。
Lambda 関数を更新して CodePipeline からの入力を処理します。
新しい Lambda 関数の作成 アクションタイプのパイプラインで利用可能なジョブがあるときに実行される Lambda 関数にビジネスロジックを追加できます。たとえば、顧客とパイプラインのコンテキストを考えると、顧客のためのサービスでビルドを開始したい場合があります。
以下のパラメータを使用して Lambda 関数を更新し、 CodePipeline からの入力を処理します。
形式:
-
jobId:-
システムによって生成されたジョブの固有の ID 。
-
タイプ: 文字列
-
パターン:[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}
-
-
accountId:-
ジョブの実行時に使用する顧客の AWS アカウントの ID。
-
タイプ: 文字列
-
Pattern: [0-9]\{12\}
-
-
data:-
統合がジョブの完了に使用するジョブに関するその他の情報。
-
次のいずれかのマップが含まれます。
-
actionConfiguration:-
アクションの設定データ。アクション設定フィールドは、顧客が値を入力するためのキー値のペアのマッピングです。キーは、アクションを設定するときに、アクションタイプ定義ファイル内のキーパラメータによって決定されます。この例では、
UsernameそしてPasswordフィールドに情報を指定するアクションのユーザーよって値が決定される。 -
タイプ : 文字列から文字列へのマッピング、オプションで提供
例:
"configuration": { "Username": "MyUser", "Password": "MyPassword" },
-
-
encryptionKey:-
キーなど、アーティファクトストア内のデータの暗号化に使用される AWS KMS キーに関する情報を表します。
-
内容 : データ型タイプ
encryptionKey、オプションで提供
-
-
inputArtifacts:-
作業対象のアーティファクト (テスト、構築アーティファクトなど) に関する情報のリスト。
-
目次 : データ型のリスト
Artifact、オプションで提供
-
-
outputArtifacts:-
アクションの出力に関する情報のリスト。
-
目次:データ型のリスト
Artifact、オプションで提供
-
-
actionCredentials:-
AWS セッション認証情報オブジェクトを表します。これらの認証情報は、 AWS STSによって発行される一時的な認証情報です。CodePipeline にパイプラインのアーティファクトを格納するために使用される S3 バケットの入出力アーティファクトにアクセスするために使用できます。
これらの認証情報には、アクションタイプ定義ファイル内の指定されたポリシーステートメントテンプレートと同じ権限もあります。
-
内容 : データ型タイプ
AWSSessionCredentials、オプションで提供
-
-
actionExecutionId:-
アクションの実行の外部 ID。
-
タイプ: 文字列
-
-
continuationToken:-
ジョブを非同期的に続行するためにジョブに必要な、デプロイメント ID などのシステム生成トークン。
-
タイプ : 文字列、オプションで提供
-
-
-
データ型:
-
encryptionKey:-
id:-
キーを識別する際に使用された ID。 AWS KMS キーには、キー ID、キー ARN、またはエイリアス ARN を使用できます。
-
タイプ: 文字列
-
-
type:-
キーなどの暗号化 AWS KMS キーのタイプ。
-
型: 文字列
-
有効な値:
KMS
-
-
-
Artifact:-
name:-
アーティファクトの名前。
-
タイプ : 文字列、オプションで提供
-
-
revision:-
アーティファクトのリビジョン ID 。オブジェクトのタイプに応じて、コミット ID (GitHub) またはリビジョン ID (Amazon S3)になります。
-
タイプ : 文字列、オプションで提供
-
-
location:-
アーティファクトの位置。
-
内容 : データ型タイプ
ArtifactLocation、オプションで提供
-
-
-
ArtifactLocation:-
type:-
ロケーション内のアーティファクトのタイプ。
-
タイプ : 文字列、オプションで提供
-
有効な値:
S3
-
-
s3Location:-
リビジョンを含む S3 バケットの場所。
-
内容 : データ型タイプ
S3Location、オプションで提供
-
-
-
S3Location:-
bucketName:-
S3 バケットの名前。
-
タイプ: 文字列
-
-
objectKey:-
S3 バケット内のオブジェクトのキー。バケット内のオブジェクトを一意に識別します。
-
タイプ: 文字列
-
-
-
AWSSessionCredentials:-
accessKeyId:-
セッションのアクセスキー。
-
タイプ: 文字列
-
-
secretAccessKey:-
セッションのシークレットアクセスキー。
-
タイプ: 文字列
-
-
sessionToken:-
セッションのトークン。
-
タイプ: 文字列
-
-
例:
{ "jobId": "01234567-abcd-abcd-abcd-012345678910", "accountId": "012345678910", "data": { "actionConfiguration": { "key1": "value1", "key2": "value2" }, "encryptionKey": { "id": "123-abc", "type": "KMS" }, "inputArtifacts": [ { "name": "input-art-name", "location": { "type": "S3", "s3Location": { "bucketName": "inputBucket", "objectKey": "inputKey" } } } ], "outputArtifacts": [ { "name": "output-art-name", "location": { "type": "S3", "s3Location": { "bucketName": "outputBucket", "objectKey": "outputKey" } } } ], "actionExecutionId": "actionExecutionId", "actionCredentials": { "accessKeyId": "access-id", "secretAccessKey": "secret-id", "sessionToken": "session-id" }, "continuationToken": "continueId-xxyyzz" } }
Lambda 関数の結果を CodePipeline に返す
インテグレータのジョブワーカー リソースは、成功、失敗、または継続の場合に有効なペイロードを返す必要があります。
形式:
-
result: ジョブの結果。-
必須
-
有効な値 (大文字と小文字は区別されません)
-
Success: ジョブが正常に終了したことを示します。 -
Continue:ジョブが正常に実行され、ジョブワーカーが同じアクションの実行に対して再呼び出された場合など、続行する必要があることを示します。 -
Fail: ジョブが失敗し、ターミナルであることを示します。
-
-
-
failureType: 失敗したジョブに関連付ける障害タイプ。パートナーアクションの
failureTypeカテゴリは、ジョブの実行中に発生した障害のタイプを示します。インテグレータは、ジョブの障害結果を CodePipeline に戻すときに、障害メッセージとともにタイプを設定します。-
オプション。結果が
Failの場合に必須。 -
resultがSuccessまたはContinueの場合は、null にする必要があります。 -
有効な値:
-
構成エラー
-
ジョブ失敗
-
パーミッションエラー
-
リビジョンOutOfSync
-
リビジョン利用不可
-
システム利用不可
-
-
-
continuation: 現在のアクション実行内で次のジョブに渡される継続状態。-
オプション。結果が
Continueの場合に必須。 -
resultがSuccessまたはFailの場合は、 null にする必要があります。 -
プロパティ:
-
State: 渡すステートのハッシュ。
-
-
-
status: アクション実行のステータス。-
オプション。
-
プロパティ:
-
ExternalExecutionId: ジョブに関連付けるオプションの外部実行 ID またはコミット ID。 -
Summary: 発生した事象の要約。障害シナリオでは、これがユーザーに表示される障害メッセージになります。
-
-
-
outputVariables: 次のアクションの実行に渡されるキーと値のペアのセット。-
オプション。
-
resultがContinueまたはFailの場合は、 null にする必要があります。
-
例:
{ "result":"success", "failureType": null, "continuation": null, "status": { "externalExecutionId":"my-commit-id-123", "summary":"everything is dandy"}, "outputVariables": { "FirstOne":"Nice", "SecondOne":"Nicest", ... } }
継続トークンを使用して、非同期プロセスの結果を待つ
continuation トークンは Lambda 関数のペイロードと結果の一部です。これは、ジョブの状態を CodePipeline に渡し、ジョブを継続する必要があることを示す方法です。たとえば、インテグレータがリソースでカスタマーの構築を開始した後、構築が完了するのを待たずに、 result をcontinue として返すことで、 CodePipeline にターミナル結果がないことを示し、構築の一意の ID を CodePipeline に continuation トークンとして返します。
注記
Lambda 関数は最大 15 分まで実行できます。ジョブを長く実行する必要がある場合は、継続トークンを使用できます。
CodePipeline チームは 30 秒後にインテグレータを呼び出します。ペイロードに continuation トークンを入れて、完了をチェックできるようにします。構築が完了すると、インテグレータはターミナルの成功/失敗結果を返し、そうでない場合は続行します。
ランタイム時にインテグレーターの Lambda 関数を呼び出す権限を CodePipeline に提供します。
インテグレータの Lambda 関数に、CodePipeline サービスプリンシパルを使用して呼び出す権限を追加して、 CodePipeline サービスに提供します。: codepipeline.amazonaws.com アクセス許可を追加するには、 AWS CloudFormation または コマンドラインを使用します。例については、アクションタイプの使用を参照してください。
ジョブワーカー統合モデル
高レベル ワークフローを綿密に設計した後、ジョブワーカーを作成できます。最終的にはサードパーティーアクションの仕様がジョブワーカーに必要なものを決定しますが、サードパーティーアクションのジョブワーカーの多くは以下の機能を含みます:
-
PollForThirdPartyJobsを使用して CodePipeline からジョブをポーリングする。 -
ジョブを確認し、 CodePipeline に
AcknowledgeThirdPartyJob、PutThirdPartyJobSuccessResultおよびPutThirdPartyJobFailureResultを使用して結果を返す。 -
パイプラインの Amazon S3 バケットからアーティファクトを取得する、またはアーティファクトを配置する。Amazon S3 バケットからアーティファクトをダウンロードするには、署名バージョン 4 の署名 (Sig V4) を使用する Amazon S3 クライアントを作成する必要があります。Sig V4 は に必要です AWS KMS。
Amazon S3 バケットにアーティファクトをアップロードするには、 AWS Key Management Service (AWS KMS). AWS KMS uses で暗号化を使用するように Amazon S3
PutObjectリクエストを設定する必要があります AWS KMS keys。 AWS マネージドキー またはカスタマーマネージドキーを使用してアーティファクトをアップロードするかどうかを知るには、ジョブワーカーがジョブデータを調べ、暗号化キープロパティを確認する必要があります。プロパティが設定されている場合は、設定時にそのカスタマーマネージドキー ID を使用する必要があります AWS KMS。key プロパティが null の場合は、 AWS マネージドキーを使用します。CodePipeline は、特に設定 AWS マネージドキー されていない限り、 を使用します。Java または .NET で AWS KMS パラメータを作成する方法を示す例については、「 SDK を使用した Amazon S3 AWS Key Management Service での の指定 AWS SDKs」を参照してください。CodePipeline 用の Amazon S3 バケットの詳細については、「CodePipeline の概念 」を参照してください。
ジョブワーカー用にアクセス許可管理戦略を選択して設定する
CodePipeline でサードパーティーアクションのジョブワーカーを開発するには、ユーザーやアクセス権限管理を統合するための戦略が必要になります。
最も簡単な戦略は、 AWS Identity and Access Management (IAM) インスタンスロールを使用して Amazon EC2 インスタンスを作成して、ジョブワーカーに必要なインフラストラクチャを追加することです。これにより、統合に必要なリソースを簡単にスケールアップできます。との組み込み統合を使用して AWS 、ジョブワーカーと CodePipeline 間のやり取りを簡素化できます。
Amazon EC2 の詳細を参照し、統合に適しているかどうかを判断します。詳細については、「Amazon EC2 - 仮想サーバーのホスティング
他に考慮すべき戦略は、IAMと ID フェデレーションを使用した既存の ID プロバイダーシステムおよびリソースとの統合です。この戦略は、お客様がすでに企業 ID プロバイダーを持っているか、ウェブ ID プロバイダーを使用するユーザーをサポートできるよう設定されている場合に、特に便利です。ID フェデレーションを使用すると、IAM ユーザーを作成または管理することなく、CodePipeline などの AWS リソースへの安全なアクセスを許可できます。パスワードのセキュリティ要件や認証情報の更新に機能やポリシーを活用できます。サンプルアプリケーションをお客様自身の設計のテンプレートとして使用できます。詳細については、「フェデレーションの管理
アクセス権限を付与するにはユーザー、グループ、またはロールにアクセス許可を追加します。
-
以下のユーザーとグループ AWS IAM Identity Center:
アクセス許可セットを作成します。「AWS IAM Identity Center ユーザーガイド」の「権限設定を作成する」の手順に従ってください。
-
IAM 内で、ID プロバイダーによって管理されているユーザー:
ID フェデレーションのロールを作成します。詳細については「IAM ユーザーガイド」の「サードパーティー ID プロバイダー (フェデレーション) 用のロールを作成する」を参照してください。
-
IAM ユーザー:
-
ユーザーが担当できるロールを作成します。手順については「IAM ユーザーガイド」の「IAM ユーザーのロールの作成」を参照してください。
-
(お奨めできない方法) ポリシーをユーザーに直接アタッチするか、ユーザーをユーザーグループに追加します。詳細については「IAM ユーザーガイド」の「ユーザー (コンソール) へのアクセス権限の追加」を参照してください。
-
次は、サードパーティー ジョブワーカーで使用するために作成する可能性があるポリシーの例です。このポリシーは例に過ぎず、そのまま提供されています。
