翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
FSx for Windows File Server でのストレージの管理
ファイルシステムのストレージ設定には、プロビジョニングされたストレージ容量、ストレージタイプ、ストレージタイプがソリッドステートドライブ (SSD) の場合は SSD IOPS の量が含まれます。ファイルシステムの作成中および作成後に、これらのリソースをスループットキャパシティとともに設定して、ワークロードに望ましいパフォーマンスを達成できます。 AWS Management Console、、および PowerShell でのリモート管理用の Amazon FSx CLI を使用してファイルシステムのストレージとストレージ関連のパフォーマンスを管理する方法については AWS CLI、以下のトピックを参照してください。
トピック
ストレージコストの最適化
FSx for Windows で使用できるストレージ設定オプションを使用して、ストレージコストを最適化できます。
ストレージタイプオプション - FSx for Windows ファイルサーバーは、ハードディスクドライブ (HDD) およびソリッドステートドライブ (SSD) の 2 種類のストレージを用意しており、お客様のワークロードのニーズに合わせてコストおよびパフォーマンスを最適化することができます。HDD ストレージは、ホームディレクトリ、ユーザーと部門の共有、コンテンツ管理システムなど、幅広いワークロード向けに設計されています。SSD ストレージは、データベース、メディア処理ワークロード、データ分析アプリケーションなど、最もパフォーマンスが高く、レイテンシーの影響を受けやすいワークロード向けに設計されています。ストレージタイプとファイルシステムのパフォーマンスに関する詳細については、「FSx for Windows File Server のパフォーマンス」を参照してください。
データの重複排除 - 大規模なデータセットには冗長データが含まれていることが多く、データストレージのコストが増加します。例えば、ユーザーのファイル共有には、複数のユーザーによって保存された同じファイルのコピーが複数存在する場合があります。ソフトウェア開発共有には、ビルドごとに変更されないままの多くのバイナリを含めることができます。ファイルシステムの データ重複排除 を有効にすることで、データストレージのコストを削減することができます。重複排除機能を有効にすると、データセットの重複した部分を一度だけ保存することで、冗長データを自動的に削減または排除します。データ重複排除の詳細、および Amazon FSx ファイルシステムで簡単にそれを有効にする方法については、「データ重複排除によるストレージコストの削減」を参照してください。
ストレージ容量の管理
ストレージ要件の変化に応じて、FSx for Windows ファイルシステムのストレージ容量を増やすことができます。これを行うには、Amazon FSx コンソール、Amazon FSx API、または AWS Command Line Interface (AWS CLI) を使用します。ストレージ容量の増加を計画する際に考慮すべき要因には、ストレージ容量を増やす必要があるタイミングを把握すること、Amazon FSx がストレージ容量の増加を処理する方法を理解すること、ストレージの増加リクエストの進行状況を追跡することなどがあります。ファイルシステムのストレージ容量は増加のみが可能で、ストレージ容量を減らすことはできません。
注記
2019 年 6 月 23 日より前に作成されたファイルシステムや、2019 年 6 月 23 日より前に作成されたファイルシステムに属するバックアップから復元されたファイルシステムでは、ストレージ容量を増やすことはできません。
Amazon FSx ファイルシステムのストレージ容量を増やすと、Amazon FSx は裏でファイルシステムに新しい大きなディスクセットを追加します。その後、Amazon FSx は、ストレージ最適化プロセスをバックグラウンドで実行し、古いディスクから新しいディスクにデータを透過的に移行します。ストレージタイプとその他の要因によってストレージの最適化には数時間から数日かかることがありますが、ワークロードのパフォーマンスに及ぼす影響は最小限です。この最適化では、古いストレージボリュームと新しいストレージボリュームの両方がファイルシステムレベルのバックアップに含まれるため、バックアップの使用量が一時的に高くなります。両方のストレージボリュームのセットが含まれているので、ストレージの拡張作業中にも Amazon FSx がバックアップを正常に取得して復元することができます。以前のストレージボリュームがバックアップ履歴に含まれていない場合、バックアップの使用量は、以前のベースラインレベルに戻ります。新しいストレージ容量が利用可能になると、新しいストレージ容量に対してのみ請求されます。
次の図は、Amazon FSx がファイルシステムのストレージ容量を増やすときに使用するプロセスの、4 つの主要ステップを示しています。
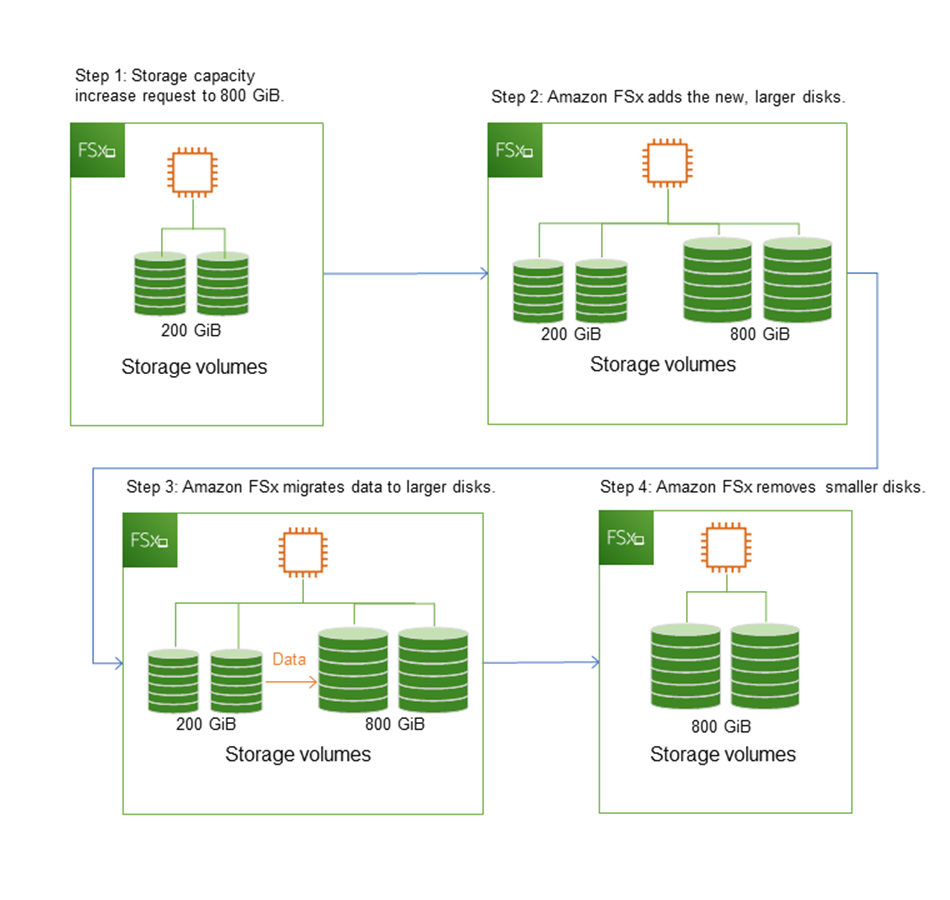
Amazon FSx コンソール、CLI、または API を使用して、ストレージ最適化、SSD ストレージ容量の増加、SSD IOPS の更新の進捗状況をいつでも追跡できます。詳細については、「ストレージ容量の拡張をモニタリングする」を参照してください。
ファイルシステムのストレージ容量を増やす方法について知っておくべきこと
ストレージ容量を増やすときに考慮すべき重要な事項をいくつか挙げます。
-
増加のみ - ファイルシステムのストレージ容量は増加することのみ可能で、ストレージ容量は減らせません。
-
増加最小値 - 各ストレージ容量の増加は、ファイルシステムの現在のストレージ容量の最低 10% で、最大許容値 65,536 GiB までである必要があります。
-
最小スループットキャパシティ – ストレージキャパシティを増やすには、ファイルシステムの最小スループットキャパシティが 16 MBps である必要があります。これは、ストレージの最適化ステップがスループットを大量に消費するプロセスであるためです。
-
拡張するまでの時間 - 最後の拡張がリクエストされてから 6 時間経過するか、ストレージの最適化プロセスが完了するか、どちらが長い方は終わるまでは、ファイルシステムのストレージ容量をさらに増やすことはできません。ストレージの最適化には数時間から数日かかります。ストレージの最適化が完了するまでの時間を最小限に抑えるには、ストレージ容量を増やす前にファイルシステムのスループットキャパシティを増やし (ストレージのスケーリング完了後にスループットキャパシティは元に戻せます)、ファイルシステムのトラフィックが最小である場合はストレージ容量を増やすことをお勧めします。
注記
特定のファイルシステムイベントは、次の例のように、ディスク I/O のパフォーマンスリソースを消費する可能性があります。
ストレージ容量のスケーリングの最適化フェーズでは、ディスクスループットが向上し、パフォーマンス警告が発生する可能性があります。詳細については、「パフォーマンスの警告と推奨事項」を参照してください。
ストレージ容量を増やすタイミングを知る
空きストレージ容量が不足している場合は、ファイルシステムのストレージ容量を増やします。FreeStorageCapacity CloudWatch メトリクスを使用して、ファイルシステム上で利用可能な空きストレージ容量をモニタリングします。このメトリクスで Amazon CloudWatch アラームを作成し、特定のしきい値を下回ったときに通知を受け取ることができます。詳細については、「Amazon CloudWatch によるモニターリング」を参照してください。
ファイルシステム上で常に 20% 以上の空きストレージ容量を維持することをお勧めします。ストレージ容量をすべて使用するとパフォーマンスに悪影響が生じ、データの不整合が生じる可能性があります。
空きストレージ容量が定義済みしきい値を下回った際にファイルシステムのストレージ容量を自動的に増やすことができます。が AWS開発したカスタム AWS CloudFormation テンプレートを使用して、自動化ソリューションの実装に必要なすべてのコンポーネントをデプロイします。詳細については、「ストレージ容量を動的に増やす」を参照してください。
ストレージ容量の拡張とファイルシステムのパフォーマンス
ほとんどのワークロードでは、パフォーマンスへの影響は最小限に抑えられますが、Amazon FSx は新しいストレージ容量が利用可能になった後、バックグラウンドでストレージ最適化プロセスを実行します。ただし、HDD ストレージタイプを持つファイルシステムや、多数のエンドユーザー、高レベルの I/O、または多数の小さなファイルを持つデータセットを含むワークロードでは、パフォーマンスが一時的に低下する可能性があります。このような場合は、ストレージ容量を増やす前に、まずファイルシステムのスループット容量を増やすことをお勧めします。これらのタイプのワークロードでは、ファイルシステムの負荷が最小限であるアイドル期間中にスループットキャパシティを変更することもお勧めします。これにより、アプリケーションのパフォーマンスニーズを満たすために、同じレベルのスループットを提供し続けることができます。詳細については、「スループット容量の管理」を参照してください。
ファイルシステムのストレージタイプの管理
AWS Management Console および を使用して、ファイルシステムのストレージタイプを HDD から SSD に変更できます AWS CLI。ストレージタイプを SSD に変更する場合、最後の更新がリクエストされてから 6 時間後、またはストレージ最適化プロセスが完了するまでのどちらか長い方までは、ファイルシステム構成を再び更新できないことに注意してください。ストレージの最適化には数時間から数日かかります。この時間を最小限に抑えるために、ファイルシステムのトラフィックが最小のときにストレージタイプを更新することをお勧めします。詳細については、「FSx for Windows ファイルシステムのストレージタイプの更新」を参照してください。
ファイルシステムのストレージタイプは SSD から HDD には変更できません。ファイルシステムのストレージタイプを SSD から HDD に変更する場合は、HDD ストレージを使用するように設定した新しいファイルシステムにファイルシステムのバックアップを復元する必要があります。詳細については、「新しいファイルシステムへのバックアップの復元」を参照してください。
ストレージタイプについて
FSx for Windows File Server ファイルシステムは、ソリッドステートドライブ (SSD) または磁気ハードディスクドライブ (HDD) ストレージタイプを使用するように設定できます。
SSD ストレージは、高いパフォーマンス要件とレイシンシーセンシティブを持つほとんどのプロダクション ワークロードに適します。これらのワークロードの例には、データベース、データ分析、メディア処理、ビジネスアプリケーションなどがあります。また、多数のエンドユーザー、高レベルの I/O、またはデータセットに多数の小さなファイルが含まれるユースケースには、SSD をお勧めします。最後に、シャドウコピーを有効にする場合は SSD ストレージの使用をお勧めします。SSD ストレージを使用するファイルシステムの SSD IOPS は構成およびスケールできますが、HDD ストレージでは構成およびスケールできません。
HDD ストレージは、ホームディレクトリ、ユーザーおよび部門のファイル共有、コンテンツ管理システムなど、幅広いワークロードに対応するように設計されています。HDD ストレージは SSD ストレージに比べて低コストですが、レイテンシーが高く、ストレージ単位あたりのディスクスループットとディスク IOPS のレベルが低くなります。I/O 要件の低い汎用のユーザー共有やホームディレクトリ、データの取得頻度が低い大規模なコンテンツ管理システム (CMS)、またはサイズの大きいファイルの数が少ないデータセットに適する場合があります。
詳細については、「ストレージ構成とパフォーマンス」を参照してください。
SSD IOPS の管理
SSD ストレージで設定されたファイルシステムの場合、SSD IOPS の量は、キャッシュにあるデータではなく、ファイルシステムがディスクとの間でデータを読み取り、ディスクにデータを書き込む必要があるときに使用可能なディスク I/O の量を決定します。ストレージ容量とは別に SSD IOPS の量を選択してスケーリングできます。プロビジョニングできる最大 SSD IOPS は、ファイルシステムに選択したストレージ容量とスループットキャパシティによって異なります。SSD IOPS をスループットキャパシティでサポートされる制限を超えて増やそうとすると、その SSD IOPS のレベルに達するようにスループットキャパシティを増やす必要が生じる場合があります。詳細については、FSx for Windows File Server のパフォーマンスおよびスループット容量の管理を参照してください。
ファイルシステムのプロビジョニングされた SSD IOPS の更新について知っておくべき重要な項目を以下に示します。
IOPS モードの選択 – 次の 2 つの IOPS モードから選択できます。
[自動] - このモードと Amazon FSx を選択すると、SSD IOPS を自動的にスケーリングして、ストレージ容量の GiB ごとに 3 つの SSD IOPS、ファイルシステムごとに最大 400,000 SSD IOPS を維持します。
[ユーザープロビジョニング] — このモードを選択すると、SSD IOPS の数を 96 ~ 400,000 の範囲で指定できます。Amazon FSx AWS リージョン が利用可能なすべての について、ストレージ容量の GiB あたり 3~50 IOPS、または米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ)、欧州 (アイルランド)、アジアパシフィック (東京)、アジアパシフィック (シンガポール) でストレージ容量の GiB あたり 3~500 IOPS の数値を指定します。ユーザープロビジョンドモードを選択すると、指定した SSD IOPS の量が GiB あたり少なくとも 3 IOPS でない場合、リクエストは失敗します。プロビジョニングされた SSD IOPS のレベルが高い場合は、ファイルシステムごとに GiB あたり 3 IOPS を超える平均 IOPS に対して料金が発生します。
ストレージ容量の更新 – ファイルシステムのストレージ容量を増やし、デフォルトで現在のユーザープロビジョニング SSD IOPS レベルを超える SSD IOPS 量を必要とする場合、Amazon FSx はファイルシステムを自動的に自動モードに切り替え、ファイルシステムにはストレージ容量の GiB あたり少なくとも 3 つの SSD IOPS があります。
スループットキャパシティの更新 – スループットキャパシティを増やし、新しいスループット容量でサポートされる最大 SSD IOPS がユーザープロビジョニングの SSD IOPS レベルよりも高い場合、Amazon FSx は自動的にファイルシステムを自動モードに切り替えます。
SSD IOPS 増加の時間間隔 – 最後に増加がリクエストされてから 6 時間後まで、またはストレージの最適化プロセスが完了するまでのどちらか長い期間は、SSD IOPS の増加も、スループットキャパシティの増加も、ファイルシステム上のストレージタイプの更新も、さらに行うことはできません。ストレージの最適化には数時間から数日かかります。ストレージの最適化が完了するまでの時間を最小限に抑えるために、ファイルシステムのトラフィックが最小限のときに SSD IOPS をスケーリングすることをお勧めします。
注記
4,608 MBps 以上のスループットキャパシティレベルは、 AWS リージョン米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ)、欧州 (アイルランド)、アジアパシフィック (東京)、アジアパシフィック (シンガポール) でのみサポートされることに注意してください。
FSx for Windows File Server ファイルシステムのプロビジョニングされた SSD IOPS の量を更新する方法の詳細については、「ファイルシステムの SSD IOPS の更新」を参照してください。
データ重複排除によるストレージコストの削減
データ重複排除は、Dedup for Short とも呼ばれ、ストレージ管理者が重複データに関連するコストを削減するのに役立ちます。FSx for Windows File Server を使用すると、Microsoft Data Deduplication を使用して冗長データを特定して排除できます。大規模なデータセットは冗長なデータを持つことが多く、データストレージのコストが増加します。以下に例を示します。
ユーザーファイル共有には、同じファイルまたは同様のファイルのコピーが多数ある場合があります。
ソフトウェア開発共有には、ビルドごとに変更されないままの多くのバイナリを含めることができます。
ファイルシステムのデータ重複排除を有効にすることで、データストレージのコストを削減できます。データ重複除外 はデータセットの重複した部分を 1 回のみ保存することで、冗長データを削減または排除します。データ重複除外を有効にすると、重複除外後のデータ圧縮がデフォルトで有効になり、さらに節約ができます。重複排除は、データの忠実度や整合性を損なうことなく冗長性を最適化します。データ重複除外は、ファイルシステムを継続的に自動的にスキャンして最適化するバックグラウンドプロセスとして実行され、ユーザーや接続されたクライアントに対して透過的に実行されます。
データ重複除外によって達成できるストレージの節約は、ファイル間で重複する量など、データセットの性質によって異なります。一般的な汎用ファイル共有では、平均 50~60% 削減されます。共有内では、ユーザードキュメントの 30~50% からソフトウェア開発データセットの 70~80% が節約範囲です。重複除外による節約の可能性を測定するには、以下に説明する Measure-FSxDedupFileMetadata リモート PowerShell コマンドを使用します。
また、特定のストレージニーズに合わせてデータ重複除外をカスタマイズすることもできます。例えば、特定のファイルタイプでのみ実行するように重複除外を設定したり、カスタムジョブスケジュールを作成したりできます。重複除外ジョブはファイルサーバリソースを消費することがあるため、Get-FSxDedupStatus を使用して重複除外ジョブのステータスをモニタリングすることをお勧めします。
ファイルシステムでのデータ重複排除の設定については、「データ重複除外の管理」を参照してください。
データ重複排除に関連する問題の解決については、「」を参照してください。
データ重複除外の詳細については、Microsoft の「データ重複除外について
警告
特定の Robocopy コマンドをデータ重複除外で実行することは推奨されません。これらのコマンドはチャンクストアのデータ整合性に影響を与える可能性があるためです。詳細については、Microsoft のデータ重複除外の相互運用性
データ重複排除を使用する際のベストプラクティス
ここでは、Data Deduplication を使用するためのいくつかのベストプラクティスを以下に示します。
ファイルシステムがアイドル状態のときに実行するように Data Deduplication ジョブをスケジュールする: デフォルトのスケジュールには、毎週土曜日の 2:45 UTC に実行される
GarbageCollectionジョブが含まれています。ファイルシステムで大量のデータが流出している場合、完了するまでに数時間かかることがあります。この時間がワークロードにとって理想的でない場合は、ファイルシステムのトラフィックが少ないと予想される時間にこのジョブを実行するようにスケジュールします。Data Deduplication を完了するのに十分なスループットキャパシティを設定する: スループットキャパシティが大きいほど、メモリのレベルが高くなります。Microsoft では、Data Deduplication を実行するには、論理データの 1 TB あたり 1 GB のメモリを用意することを推奨します。Amazon FSx パフォーマンステーブルを使用して、ファイルシステムのスループットキャパシティに関連付けられているメモリを特定し、メモリリソースがデータのサイズに対して十分であることを確認します。
Data Deduplication の設定をカスタマイズして、特定のストレージのニーズを満たし、パフォーマンス要件を緩和する: 特定のファイルタイプまたはフォルダーで実行するように最適化を制限したり、最適化のための最小ファイルサイズと経過時間を設定したりできます。詳細については、「データ重複排除によるストレージコストの削減」を参照してください。
