サポート終了通知: 2025 年 10 月 31 日、 AWS は Amazon Lookout for Vision のサポートを終了します。2025 年 10 月 31 日以降、Lookout for Vision コンソールまたは Lookout for Vision リソースにアクセスできなくなります。詳細については、このブログ記事
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Lookout for Vision コンソールの開始
開始の手引きを始める前に、「Amazon Lookout for Vision について」を読むことをお勧めします。
開始の手引きでは、サンプルの画像セグメンテーションモデルの使用と作成の方法を説明します。サンプルの画像分類モデルを作成する場合は、画像分類データセット を参照してください。
サンプルモデルをすぐに試してみたい場合は、サンプルのトレーニング画像とマスク画像を提供します。また、画像セグメンテーションマニフェストファイルを作成する Python スクリプトも提供します。マニフェストファイルを使用してプロジェクトのデータセットを作成すれば、データセット内の画像にラベルを付ける必要はありません。独自の画像を使用してモデルを作成する場合は、データセット内の画像にラベルを付ける必要があります。詳細については、「データセットの作成」を参照してください。
私たちが提供する画像は、通常のクッキーと異常クッキーのものです。異常クッキーは、クッキーの形状全体にひびが入っています。画像を使ってトレーニングしたモデルは、次の例に示すように、分類 (正常または異常) を予測し、異常な Cookie の欠陥の領域 (マスク) を検出します。

トピック
ステップ1: マニフェストファイルとアップロード画像を作成する
この手続きでは、Amazon Lookout for Vision ドキュメンテーションリポジトリをコンピュータに複製します。次に、Python (バージョン 3.7 以降) スクリプトを使用してマニフェストファイルを作成し、指定した Amazon S3 の場所にトレーニング画像とマスク画像をアップロードします。マニフェストファイルを使用してモデルを作成します。後で、ローカルリポジトリのテスト画像を使用してモデルを試します。
マニフェストファイルを作成して画像をアップロードするには
「Amazon Lookout for Vision をセットアップする」の手順に従って Amazon Lookout for Vision をセットアップします。必ず Python 用AWS SDK
をインストールしてください。 Lookout for Vision を使用する AWS リージョンで、S3 バケットを作成します。
Amazon S3 バケットで、
getting-startedという名前のフォルダを作成します。Amazon S3 URI and Amazon リソースネーム (ARN) をメモします。これらを使用して権限をセットアップし、スクリプトを実行します。
スクリプトを呼び出すユーザーに、
s3:PutObjectオペレーションを呼び出す権限があることを確かめてください。以下のポリシーを使用できます。権限を割り当てるには 権限の割り当て を参照してください。{ "Version": "2012-10-17", "Statement": [{ "Sid": "Statement1", "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3::: ARN for S3 folder in step 4/*" ] }] }-
lookoutvision-accessという名前のローカルプロファイルがあり、そのプロファイルユーザーが前のステップの権限を持っていることを確かめてください。詳細については、「ローカルコンピュータでのプロファイルの使用」を参照してください。 -
zip ファイル getting-started.zip をダウンロードします。zip ファイルには、開始用データセットとセットアップスクリプトが含まれています。
ファイル
getting-started.zipを解凍します。コマンドプロンプトで、以下を行います:
getting-startedフォルダに移動します。-
次のコマンドを実行してマニフェストファイルを作成し、ステップ 4 でメモした Amazon S3 パスにトレーニング画像と画像マスクをアップロードします。
python getting_started.pyS3-URI-from-step-4 スクリプトが完了したら、スクリプトで
Create dataset using manifest file:の後に表示されるtrain.manifestファイルへのパスをメモします。パスはs3://に似たものとなるはずです。path to getting started folder/manifests/train.manifest
ステップ 2: ロールを作成する
この手続きでは、前に Amazon S3 バケットにアップロードした画像とマニフェストファイルを使ってプロジェクトとデータセットを作成します。次に、モデルを作成し、モデルトレーニングの評価結果を表示します。
データセットは開始用マニフェストファイルから作成するため、データセットの画像にラベルを付ける必要はありません。独自の画像を使用してデータセットを作成する場合、画像にラベルを付ける必要があります。詳細については、「画像のラベリング」を参照してください。
重要
課金はモデルのトレーニングが完了するごとに行われます。
モデルを作成するには
-
https://console.aws.amazon.com/lookoutvision/
で Amazon Lookout for Vision コンソールを開きます。 で Amazon S3 バケットを作成したリージョンと同じ AWS リージョンにいることを確認しますステップ1: マニフェストファイルとアップロード画像を作成する。リージョンを変更するには、ナビゲーションバーで、現在表示されているリージョン名を選択します。切り替え先となるリージョンを選択します。
-
[開始する] を選択します。

[プロジェクト] セクションで、[プロジェクトを作成] を選択します。

-
「プロジェクトを作成」ページで、以下を行います:
-
[プロジェクト名] に
getting-startedを入力します。 -
[プロジェクトを作成] を選択します。

-
-
[動作方法] セクションで、[データセットを作成] を選択します。

「データセットを作成する」ページで、次の操作を行います。
-
[シングルデータセットを作成] を選択します。
-
[画像ソース構成] セクションで、[SageMaker Ground Truth によってラベル付けされた画像をインポート] を選択します。
-
[.manifest ファイルの場所] には、ステップ1: マニフェストファイルとアップロード画像を作成する のステップ 6.c. でメモしたマニフェストファイルの Amazon S3 の場所を入力します。Amazon S3 の場所は
s3://のようになっているはずですpath to getting started folder/manifests/train.manifest -
[データセットを作成] を選択します。

-
-
プロジェクト詳細ページの [画像] セクションに、データセットの画像が表示されます。各データセット画像の分類と画像セグメンテーション情報 (マスクラベルと異常ラベル) を表示できます。また、画像を検索したり、ラベリングステータス (ラベル付き/ラベルなし) で画像をフィルターしたり、割り当てられた異常ラベルで画像をフィルターしたりすることもできます。

-
プロジェクト詳細ページで、[モデルをトレーニング] を選択します。

-
「モデルをトレーニングする」詳細ページで、[モデルをトレーニング] を選択します。
-
「モデルをトレーニングしますか?」ダイアログボックスで、[モデルをトレーニング] を選択します。
-
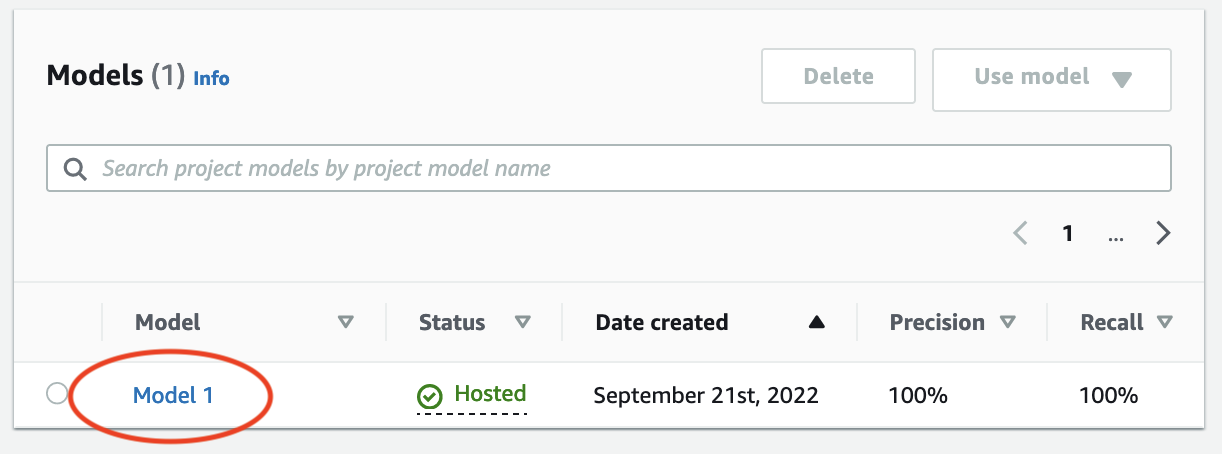
プロジェクトの「モデル」ページでは、トレーニングが開始されたことを確認できます。モデルの現在のステータスは、「ステータス」列に表示されます。モデルのトレーニングには 30 分ほどかかります。ステータスが「トレーニング完了」に変わると、トレーニングは正常に終了します。
-
トレーニングが終了したら、「モデル」ページで [モデル 1] を選択します。

-
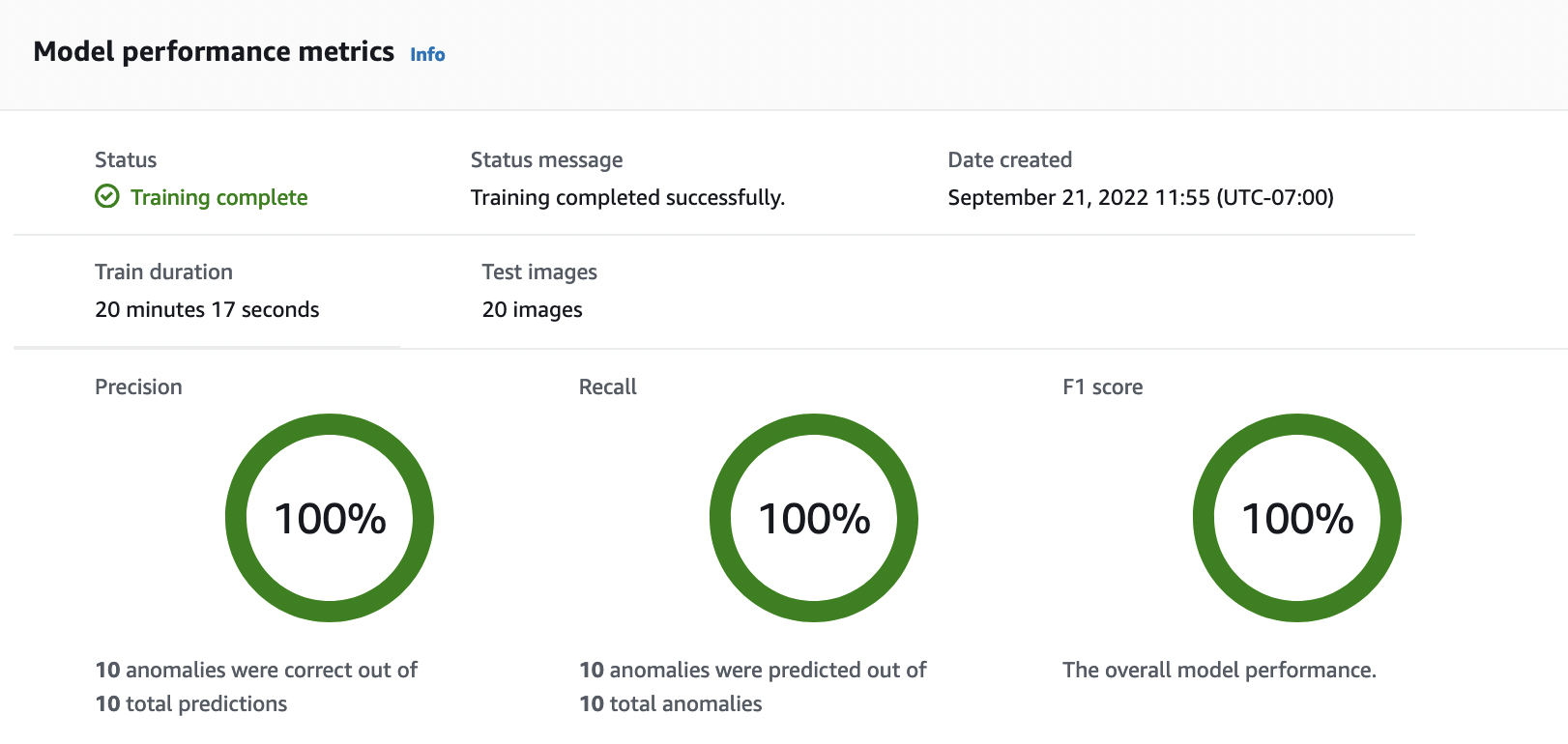
モデルの詳細ページの「パフォーマンスメトリクス」タブに評価結果が表示されます。次のメトリクスを参照できます:
モデルトレーニングは非決定的であるため、評価結果がこのページに表示されている結果と異なる場合があります。詳細については、「Amazon Lookout for Vision モデルの改善」を参照してください。


ステップ 3: モデルを開始する
このステップでは、モデルのホスティングを開始して、画像を分析できる状態にします。詳細については、「トレーニング済みの Amazon Lookout for Vision モデルの実行」を参照してください。
注記
モデルの稼働時間に応じて課金されます。ステップ 5: モデルを停止する でモデルを停止します。
モデルを開始します。
モデルの詳細ページで [モデルを使用] を選択し、[API をクラウドに統合] を選択します。

AWS CLI コマンドセクションで、
start-modelAWS CLI コマンドをコピーします。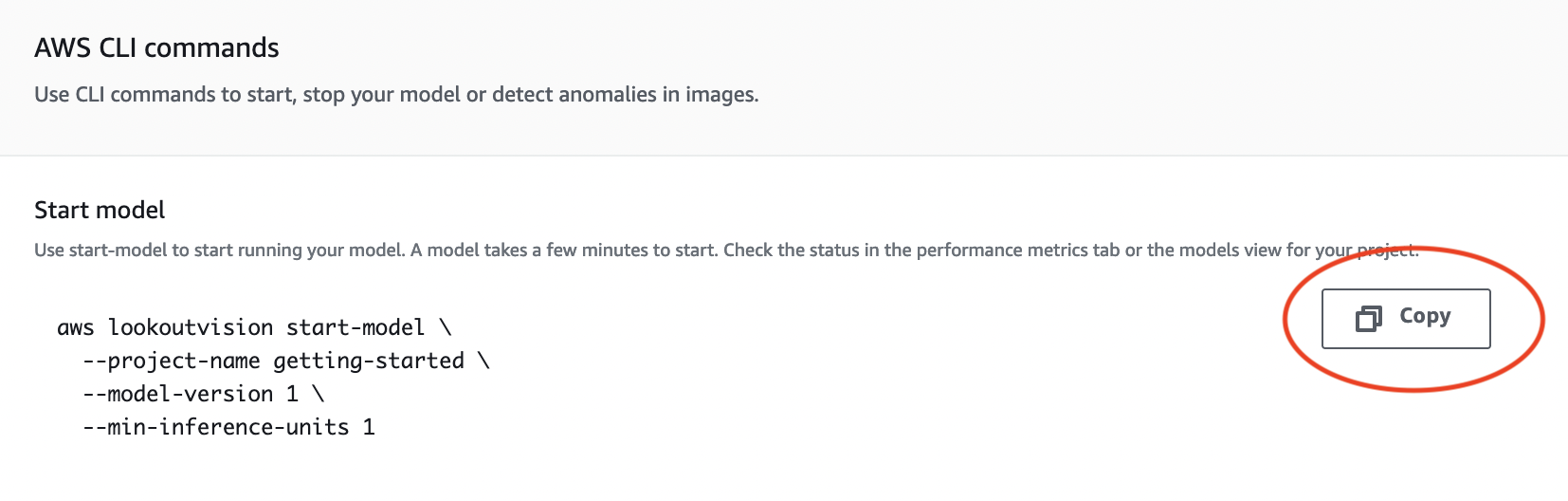
-
AWS CLI が Amazon Lookout for Vision コンソールを使用しているのと同じ AWS リージョンで実行されるように設定されていることを確認します。が AWS CLI 使用する AWS リージョンを変更するには、「」を参照してくださいAWS SDKS のインストール。
-
コマンドプロンプトで、
start-modelコマンドの入力によりモデルを開始します。lookoutvisionプロファイルを使用して認証情報を取得する場合は、--profile lookoutvision-accessパラメータを追加します。以下に例を示します。aws lookoutvision start-model \ --project-name getting-started \ --model-version 1 \ --min-inference-units 1 \ --profile lookoutvision-accessクラスターが作成されると、次の出力が表示されます:
{ "Status": "STARTING_HOSTING" } コンソールに戻り、ナビゲーションペインの [モデル] を選択します。
[ステータス] 列でモデル (Model 1) のステータスが「ホスト済み」と表示されるまで待ってください。以前にプロジェクトでモデルをトレーニングしたことがある場合は、最新のモデルバージョンが完了するまでお待ちください。

ステップ 4: 画像を分析する
このステップでは、4 つのモデルで画像を分析します。お使いの PC 上の Lookout for Vision ドキュメンテーションリポジトリ内の開始用 test-images フォルダーで使えるサンプル画像を提供しています。詳細については、「画像内の異常を検出する」を参照してください。
クエリを分析するには
-
「モデル」ページで、[モデル 1] を選択します。
-
モデルの詳細ページで [モデルを使用] を選択してから [API をクラウドに統合] を選択します。
-
AWS CLI コマンドセクションで、
detect-anomaliesAWS CLI コマンドをコピーします。
-
コマンドプロンプトで、前のステップの
detect-anomaliesコマンドを入力して異常画像を分析します。--bodyパラメータには、PC の開始用test-imagesフォルダーにある異常画像を指定します。lookoutvisionプロファイルを使用して認証情報を取得する場合は、--profile lookoutvision-accessパラメータを追加します。以下に例を示します。aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-anomaly-1.jpg\ --profile lookoutvision-access出力は次の例に類似したものになります:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": true, "Confidence": 0.983975887298584, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 0.9818974137306213, "Color": "#FFFFFF" } }, { "Name": "cracked", "PixelAnomaly": { "TotalPercentageArea": 0.018102575093507767, "Color": "#23A436" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAAMACA......" } } -
出力について、以下の点に注意してください:
-
IsAnomalousは予測分類のブール値です。画像が異常な場合trueで、そうでない場合falseとなります。 -
Confidenceは、予測での Amazon Lookout for Vision の信頼度を表す浮動小数点値であり、0 が最低、1 が最高となります。 -
Anomaliesは、画像内で見つかった異常のリストです。Nameは異常ラベルです。PixelAnomalyは異常の領域の合計パーセンテージ (TotalPercentageArea) と異常ラベルの色 (Color) を含んでいます。リストには、画像で見つかった異常以外の領域に及ぶ「バックグラウンド」異常も含まれています。 -
AnomalyMaskは、分析された画像上の異常の位置を示すマスク画像です。
次の例のように、レスポンス内の情報を使って、分析された画像と異常マスクを融合させたものを表示できます。サンプルコードについては、「分類とセグメンテーションの情報の表示」を参照してください。

-
-
コマンドプロンプトで、開始用
test-imagesフォルダーにある正常の画像を分析します。lookoutvisionプロファイルを使用して認証情報を取得する場合は、--profile lookoutvision-accessパラメータを追加します。以下に例を示します。aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-normal-1.jpg\ --profile lookoutvision-access出力は次の例に類似したものになります:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": false, "Confidence": 0.9916400909423828, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 1.0, "Color": "#FFFFFF" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAA....." } } -
出力では、
IsAnomalousに対するfalse値によって画像を異常なしと分類することに注意してください。Confidenceを分類の信頼度を判断するのに役立ててください。また、Anomalies配列にはbackground異常ラベルしか付いていません。
ステップ 5: モデルを停止する
このステップでは、モデルのホスティングを作成します。モデルの実行時間に応じて課金されます。モデルを使用していない場合は、停止できます。モデルは次に必要な時に再開できます。詳細については、「Amazon Lookout for Vision モデルの開始」を参照してください。
モデルを停止するには
-
ナビゲーションペインで、[モデル] を選択します。
「モデル」ページで、[モデル 1] を選択します。
モデルの詳細ページで [モデルを使用] を選択してから [API をクラウドに統合] を選択します。
AWS CLI コマンドセクションで、
stop-modelAWS CLI コマンドをコピーします。
-
コマンドプロンプトで、前のステップの
stop-modelAWS CLI コマンドを入力してモデルを停止します。lookoutvisionプロファイルを使用して認証情報を取得する場合は、--profile lookoutvision-accessパラメーターを追加します。以下に例を示します。aws lookoutvision stop-model \ --project-name getting-started \ --model-version 1 \ --profile lookoutvision-access呼び出しが完了すると、次の出力が表示されます:
{ "Status": "STOPPING_HOSTING" } コンソールで戻り、左ナビゲーションページで [モデル] を選択します。
「ステータス」列のモデルのステータスが「トレーニング完了」の場合、このモデルは停止しています。
次のステップ
独自の画像によりモデルを作成する準備ができたら、プロジェクトを作成します の手引きに従って開始します。手順には、Amazon Lookout for Vision コンソールと AWS SDK を使用してモデルを作成する手順が含まれています。
他のサンプルデータセットを試してみたい場合は、サンプルのコードおよびデータセット を参照してください。
