翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Personalize を使用して、パーソナライズされ再ランク付けされたレコメンデーションを生成します
Mason Cahill、Matthew Chasse、Tayo Olajide、Amazon Web Services
概要
このパターンは、Amazon Personalize を使用して、ユーザーからのリアルタイムのユーザーインタラクションデータの取り込みに基づいて、ユーザー向けにパーソナライズされたレコメンデーション (再ランク付けされたレコメンデーションを含む) を生成する方法を示しています。このパターンで使用されるシナリオの例は、ペット養子縁組ウェブサイトに基づいています。このウェブサイトでは、ユーザーとのやり取り (たとえば、ユーザーが訪問したペットなど) に基づいてユーザー向けのレコメンデーションが生成されます。シナリオ例に従うことで、Amazon Kinesis Data Streams を使用してインタラクションデータを取り込み、AWS Lambda を使用してレコメンデーションを生成してレコメンデーションを再ランク付けし、Amazon Data Firehose を使用して Amazon Simple Storage Service (Amazon S3) バケットにデータを保存する方法を学びます。また、AWS Step Functions を使用して、レコメンデーションを生成するソリューションバージョン (つまり、トレーニング済みモデル) を管理するステートマシンを構築する方法も学びます。
前提条件と制限
前提条件
「ブートストラップ」された AWS Cloud Development Kit (AWS CDK) を使用したアクティブな「AWS アカウント
」 認証情報が設定された「AWS コマンドラインインターフェイス(AWS CLI)」
製品バージョン
Python 3.9
AWS CDK 2.23.0 以降
AWS CLI 2.7.27 以降
アーキテクチャ
テクノロジースタック
Amazon Data Firehose
Amazon Kinesis Data Streams
Amazon Personalize
Amazon Simple Storage Service (Amazon S3)
AWS Cloud Development Kit (AWS CDK)
AWS コマンドラインインターフェイス (AWS CLI)
AWS Lambda
AWS Step Functions
ターゲットアーキテクチャ
次の図は、Amazon Personalize にリアルタイムデータを取り込むためのパイプラインを示しています。次に、パイプラインはそのデータを使用して、ユーザー向けにパーソナライズされ、ランクが変更されたレコメンデーションを生成します。
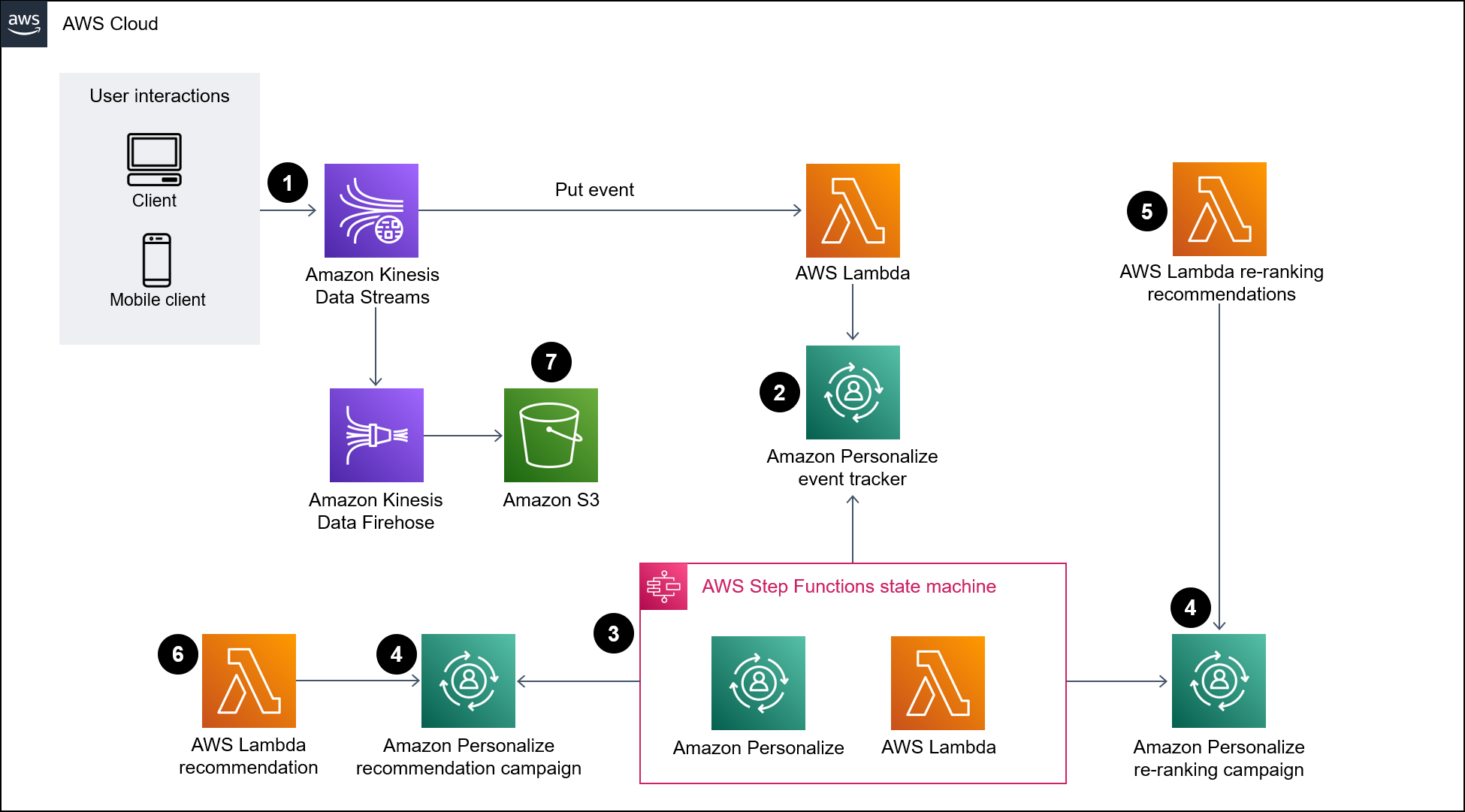
この図表は、次のワークフローを示しています:
Kinesis Data Streams は、Lambda と Firehose による処理のために、リアルタイムのユーザーデータ (訪問したペットなどのイベント) を取り込みます。
Lambda 関数は Kinesis データストリームからのレコードを処理し、レコード内のユーザーインタラクションを Amazon Personalize のイベントトラッカーに追加するための API コールを行います。
時間ベースのルールは Step Functions ステートマシンを呼び出し、Amazon Personalize のイベントトラッカーからのイベントを使用して、レコメンデーションモデルと再ランク付けモデルの新しいソリューションバージョンを生成します。
Amazon Personalize「キャンペーン」は、ステートマシンによって新しいソ「リューションバージョン」を使用するように更新されます。
Lambda は Amazon Personalize 再ランキングキャンペーンを呼び出して、おすすめ商品のリストを再ランク付けします。
Lambda は Amazon Personalize レコメンデーションキャンペーンを呼び出して、おすすめ商品のリストを取得します。
Firehose は、イベントを履歴データとしてアクセスできる S3 バケットに保存します。
ツール
AWS ツール
AWS Cloud Development Kit (AWS CDK) は、AWS クラウドインフラストラクチャをコードで定義してプロビジョニングするのに役立つソフトウェア開発フレームワークです。
「AWS コマンドラインインターフェイス (AWS CLI)」は、オープンソースのツールであり、コマンドラインシェルのコマンドを使用して AWS サービスとやり取りすることができます。
Amazon Data Firehose は、サポートされているサードパーティーサービスプロバイダーが所有する他の AWS のサービス、カスタム HTTP エンドポイント、HTTP エンドポイントにリアルタイムのストリーミングデータを
配信するのに役立ちます。 「Amazon Kinesis Data Streams」は、データレコードの大量のストリームをリアルタイムで収集し、処理するのに役立ちます。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
「Amazon Personalize」はフルマネージド型の機械学習 (ML) サービスで、データに基づいてユーザー向けの商品レコメンデーションを作成できます。
「AWS Step Functions」は、Lambda 関数と他の AWS サービスを組み合わせてビジネスクリティカルなアプリケーションを構築できるサーバーレスオーケストレーションサービスです。
その他のツール
Code
このパターンのコードは、GitHub 内の「Animal Recommender
注記
Amazon Personalize ソリューションバージョン、イベントトラッカー、キャンペーンは、ネイティブ CloudFormation リソースを拡張するカスタムリソース (インフラストラクチャ内) によってバックアップされます。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
隔離された Python 環境を作成します。 | Mac/Linux セットアップ
Windows セットアップ 仮想環境を手動で作成するには、ターミナルから | DevOps エンジニア |
CloudFormation のテンプレートを合成します。 |
注記ステップ 2 では、 は | DevOps エンジニア |
リソースをデプロイし、インフラストラクチャーを構築します。 | ソリューションリソースをデプロイするには、ターミナルから このコマンドは、必要な Python 依存関係をインストールします。Python スクリプトは、S3 バケットと AWS Key Management Service (AWS KMS) キーを作成し、最初にモデルを作成するためのシードデータを追加します。最後に、スクリプトは 注記初期モデルトレーニングは、スタックの作成中に行われます。スタックの作成が完了するまでに、最大 2 時間かかることがあります。 | DevOps エンジニア |
関連リソース
「アニマルレコメンダー
」(GitHub) 「Amazon Personalize で選択したビジネス指標に最適化されたパーソナライズされたレコメンデーションを最適化
」(AWS 機械学習 ブログ)。
追加情報
ペイロードとレスポンスの例
Lambda 関数の推奨事項
レコメンデーションを取得するには、以下の形式のペイロードを含むレコメンデーション Lambda 関数にリクエストを送信します。
{ "userId": "3578196281679609099", "limit": 6 }
次のレスポンス例には、アニマルグループのリストが含まれています。
[{"id": "1-domestic short hair-1-1"}, {"id": "1-domestic short hair-3-3"}, {"id": "1-domestic short hair-3-2"}, {"id": "1-domestic short hair-1-2"}, {"id": "1-domestic short hair-3-1"}, {"id": "2-beagle-3-3"},
userId フィールドを省略すると、関数は一般的な推奨事項を返します。
Lambda 関数の再ランク付け
再ランク付けを使用するには、再ランク付けの Lambda 関数にリクエストを送信します。ペイロードには、再ランク付けの対象となるすべてのアイテム ID の userId とそのメタデータが含まれます。以下のデータ例では、animal_species_id (1=猫、2=犬) には Oxford Pets クラスを使用し、animal_age_id および animal_size_id には 1 ~ 5 の整数を使用しています。
{ "userId":"12345", "itemMetadataList":[ { "itemId":"1", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } }, { "itemId":"2", "animalMetadata":{ "animal_species_id":"1", "animal_primary_breed_id":"Egyptian_Mau", "animal_size_id":"1", "animal_age_id":"1" } }, { "itemId":"3", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } } ] }
Lambda 関数はこれらの項目を再ランク付けし、項目 ID と Amazon Personalize からのダイレクトレスポンスを含む順序付きリストを返します。これは、商品が属するアニマルグループとそのスコアをランク付けしたリストです。Amazon Personalize は、「ユーザーパーソナライズ」と「パーソナライズランキング」のレシピを使用して、各項目のスコアをレコメンデーションに含めます。これらのスコアは、ユーザーが次にどのアイテムを選ぶかについて、Amazon Personalize の相対的な確実性を表します。スコアが高いほど、確実性が高くなります。
{ "ranking":[ "1", "3", "2" ], "personalizeResponse":{ "ResponseMetadata":{ "RequestId":"a2ec0417-9dcd-4986-8341-a3b3d26cd694", "HTTPStatusCode":200, "HTTPHeaders":{ "date":"Thu, 16 Jun 2022 22:23:33 GMT", "content-type":"application/json", "content-length":"243", "connection":"keep-alive", "x-amzn-requestid":"a2ec0417-9dcd-4986-8341-a3b3d26cd694" }, "RetryAttempts":0 }, "personalizedRanking":[ { "itemId":"2-Saint_Bernard-3-2", "score":0.8947961 }, { "itemId":"1-Siamese-1-1", "score":0.105204 } ], "recommendationId":"RID-d97c7a87-bd4e-47b5-a89b-ac1d19386aec" } }
Amazon Kinesis スペイロード
Amazon Kinesis に送信するペイロードの形式は次のとおりです。
{ "Partitionkey": "randomstring", "Data": { "userId": "12345", "sessionId": "sessionId4545454", "eventType": "DetailView", "animalMetadata": { "animal_species_id": "1", "animal_primary_breed_id": "Russian_Blue", "animal_size_id": "1", "animal_age_id": "2" }, "animal_id": "98765" } }
注記
認証されていないユーザーの userIdフィールドは削除されます。
