Spark コネクタによる認証
次の図は、Amazon S3、Amazon Redshift、Spark ドライバー、および Spark エグゼキューター間の認証を示しています。
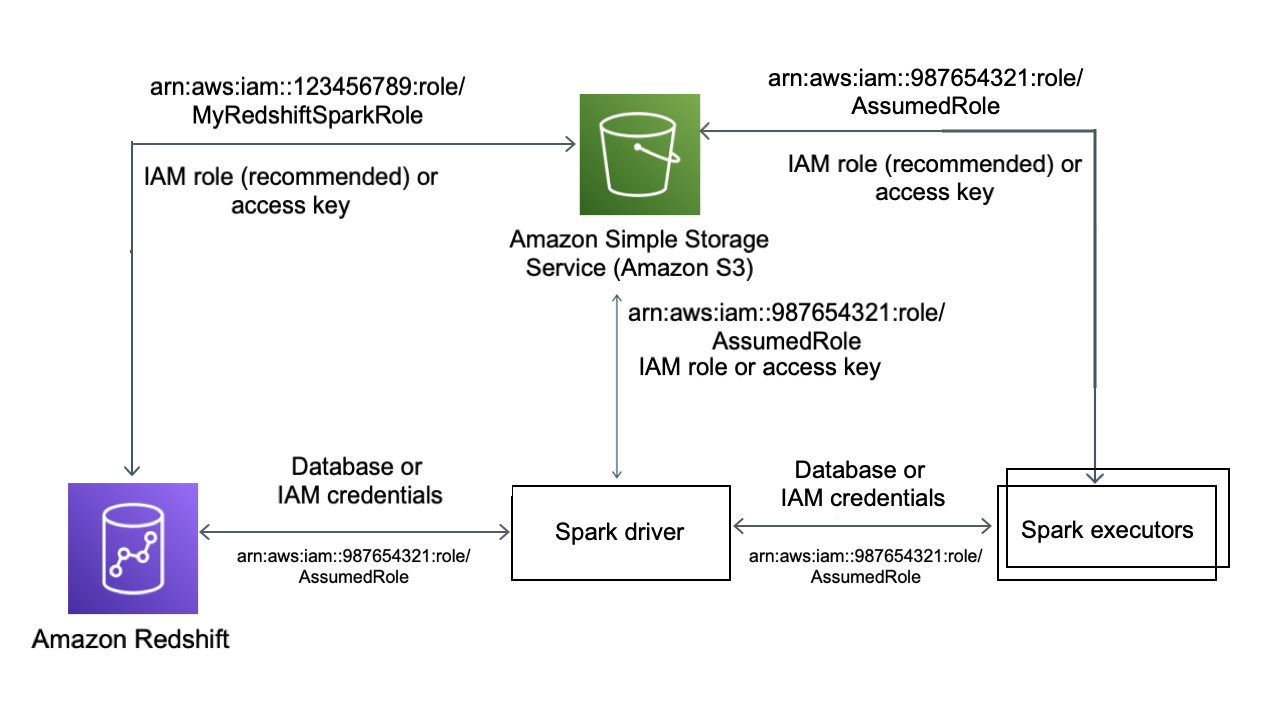
Redshift と Spark 間の認証
Amazon Redshift が提供する JDBC ドライバーバージョン 2 を使用し、サインイン認証情報を指定して Spark コネクタで Amazon Redshift に接続できます。IAM を使用するには、IAM 認証を使用するように JDBC URL を設定します。Amazon EMR または AWS Glue から Redshift クラスターに接続するには、IAM ロールに一時的な IAM 認証情報を取得するために必要なアクセス権限があることを確認します。次のリストは、IAM ロールが認証情報を取得して Amazon S3 オペレーションを実行するために必要なすべての権限を示しています。
-
Redshift:GetClusterCredentials (プロビジョニングされた Redshift クラスターの場合)
-
Redshift:DescribeClusters (プロビジョニングされた Redshift クラスターの場合)
-
Redshift:GetWorkgroup (Amazon Redshift Serverless ワークグループの場合)
-
Redshift:GetCredentials (Amazon Redshift Serverless の場合、ワークグループ)
GetClusterCredentials の詳細については、「GetClusterCredentials のリソースポリシー」を参照してください。
また、COPY および UNLOAD オペレーション中に Amazon Redshift が IAM ロールを引き継げるようにする必要があります。
最新の JDBC ドライバーを使用している場合、ドライバーは Amazon Redshift の自己署名証明書から ACM 証明書への移行を自動的に管理します。ただし、JDBC URL に SSL オプションを指定する必要があります。
以下は、JDBC ドライバーの URL と aws_iam_role を指定して Amazon Redshiftに接続する方法の例です。
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Amazon S3 と Spark 間の認証
IAM ロールを使用して Spark と Amazon S3 間での認証を行う場合は、以下のいずれかの方法を使用します。
-
AWS SDK for Java は、DefaultAWSCredentialsProviderChain クラスによって実装されたデフォルトの認証情報プロバイダーチェーンを使用して、AWS 認証情報を自動的に見つけようとします。詳細については、「デフォルトの認証情報プロバイダチェーンの使用」を参照してください。
-
Hadoop 設定プロパティ
で AWS キーを指定することができます。例えば、 tempdir設定がs3n://ファイルシステムを指している場合、Hadoop XML 設定ファイルでfs.s3n.awsAccessKeyIdおよびfs.s3n.awsSecretAccessKeyプロパティを設定するか、sc.hadoopConfiguration.set()を呼び出して Spark のグローバル Hadoop 設定を変更します。
例えば、s3n ファイルシステムを使用している場合は、以下を追加します。
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
s3a ファイルシステムの場合は、以下を追加します。
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
Python を使用している場合は、以下のオペレーションを使用します。
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
tempdirURL で認証キーをエンコードします。例えば、URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/dirでは キーペア (ACCESSKEY、SECRETKEY) をエンコードします。
Redshift と Amazon S3 間の認証
クエリで COPY コマンドと UNLOAD コマンドを使用している場合は、ユーザーに代わってクエリを実行するために Amazon S3 に Amazon Redshift へのアクセス権を付与する必要もあります。そのためには、まず Amazon Redshift が他の AWS のサービスにアクセスすることを許可し、次に IAM ロールを使用して COPY オペレーションと UNLOAD オペレーションを許可します。
ベストプラクティスとして、アクセス許可ポリシーを IAM ロールにアタッチし、それを必要に応じてユーザーやグループに割り当てることをお勧めします。詳細については、「Amazon Redshift での Identity and Access Management」を参照してください。
AWS Secrets Manager との統合
Redshift のユーザー名とパスワードの認証情報は、AWS Secrets Manager に保存されているシークレットから取得できます。Redshift 認証情報を自動的に提供するには、secret.id パラメータを使用します。Redshift 認証情報シークレットを作成する方法の詳細については、「AWS Secrets Manager データベースシークレットを作成する」を参照してください。
| GroupID | ArtifactID | サポート対象リビジョン | 説明 |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | Java 用 AWS Secrets Manager SQL Connection Library を使用すると、Java デベロッパーは AWS Secrets Manager に保存されているシークレットを使用して、簡単に SQL データベースに接続できます。 |
注記
謝辞: このドキュメントには、Apache 2.0
