翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
メトリクスと検証
このガイドでは、機械学習モデルのパフォーマンスを測定するために使用できるメトリクスと検証手法について説明します。Amazon SageMaker Autopilot は、機械学習モデル候補の予測品質を測定するメトリクスを生成します。候補に対して計算されるメトリクスは、MetricDatum タイプの配列を使用して指定します。
Autopilot メトリクス
次のリストは、Autopilot 内でモデルのパフォーマンスを測定するために現在使用可能なメトリクスの名前を示しています。
注記
Autopilot はサンプルの重みをサポートしています。サンプルの重みと使用可能な目標メトリクスの詳細については、「Autopilot 加重メトリクス」を参照してください。
以下は使用可能なメトリクスです。
Accuracy-
正しく分類された項目の数の、(正しくおよび誤って) 分類された項目の総数に対する比率。二項分類と多クラス分類の両方で使用されます。精度は、予測されたクラス値が実際の値にどれだけ近いかを測定します。精度メトリクスの値は 0~1 の間で変化します。値 1 は完全な精度を示し、0 は完全な不正確さを示します。
AUC-
曲線下面積 (AUC) メトリクスは、ロジスティック回帰など、確率を返すアルゴリズムによる二項分類の比較と評価に使用します。確率を分類にマッピングするには、しきい値と比較します。
関連する曲線は、受信者操作特性曲線です。曲線は、予測の偽陽性率 (FPR) に対する真陽性率 (TPR)/再現率を、しきい値 (これを超えれば予測を陽性とみなす) の関数としてプロットします。しきい値を高くすると偽陽性は小さくなりますが、偽陰性が増加します。
AUC は、この受信者操作特性曲線の下面積です。したがって、AUC は、考えられるすべての分類しきい値にわたってモデルパフォーマンスの集約評価基準を提供します。AUC スコアは 0~1 の間の値をとります。1 のスコアは完全な精度を示し、半分のスコア (0.5) は予測がランダム分類器を上回らないことを示します。
BalancedAccuracy-
BalancedAccuracyは、すべての予測に対する正確な予測の比率を測定するメトリクスです。この比率は、真陽性 (TP) と真陰性 (TN) を陽性 (P) と陰性 (N) の合計数で正規化した後に計算します。これは、二項分類と多クラス分類の両方で使用し、0.5*((TP/P)+(TN/N)) として定義します。値は 0~1 の範囲です。BalancedAccuracyは、不均衡なデータセットで陽性と陰性の数が相互に大きく異なる場合に、より優れた精度の尺度となります。 F1-
F1スコアは適合率と再現率の調和平均で、F1 = 2 * (適合率 * 再現率) / (適合率 + 再現率) のように定義されます。これは、従来、正と負と呼ばれているクラスへの二項分類に使用されます。予測は、実際の (正しい) クラスと一致する場合は true、そうでない場合は false とみなされます。精度は、すべての陽性予測数に対する真陽性予測数の比率であり、データセット内の偽陽性予測数を含みます。精度は、陽性クラスを予測するときの予測品質を測定します。
再現率 (または感度) は、すべての実際の陽性インスタンス数に対する真陽性予測数の比率です。再現率は、モデルがデータセット内の実際のクラスメンバーをどれだけ完全に予測したかを測定します。
F1 のスコアは 0~1 の間の値です。スコアが 1 の場合は可能な限り最高のパフォーマンスを示し、0 は最悪を示します。
F1macro-
F1macroスコアは、多クラス分類問題に F1 スコアリングを適用します。これを行うために、精度と再現率を計算し、その調和平均をとって各クラスの F1 スコアを計算します。最後に、F1macroは個々のスコアを平均化し、F1macroスコアを取得します。F1macroスコアは 0~1 の間の値をとります。スコアが 1 の場合は可能な限り最高のパフォーマンスを示し、0 は最悪を示します。 InferenceLatency-
推論待ち時間は、モデル予測のリクエストを送信してから、モデルがデプロイされているリアルタイムエンドポイントからそのリクエストを受け取るまでのおおよその時間です。このメトリクスは秒単位で測定され、アンサンブルモードでのみ使用できます。
LogLoss-
対数損失は、クロスエントロピー損失とも呼ばれ、確率出力そのものではなく、出力の品質を評価するために使用するメトリクスです。二項分類と多クラス分類の両方、およびニューラルネットで使用されます。ロジスティック回帰のコスト関数でもあります。対数損失は、モデルが高い確率で誤った予測を行っていることを示す重要なメトリクスです。値の範囲は 0 から無限大です。値 0 は、データを完全に予測するモデルを表します。
MAE-
平均絶対誤差 (MAE) は、すべての値を平均化した際に予測値と実際の値がどの程度異なるかを示す尺度です。MAE は、モデルの予測誤差を理解するために回帰分析で一般的に使用します。線形回帰がある場合、MAE は予測線から実際の値までの平均距離を表します。MAE は、絶対誤差の合計を観測値の数で割った値として定義されます。値の範囲は 0 から無限大で、数字が小さいほど、モデルがよりデータに適合していることを示します。
MSE-
平均二乗誤差 (MSE) は、予測値と実際の値の差の二乗の平均です。これは回帰に使用します。MSE の値は常に正です。モデルによる実際の値の予測精度が高くなるほど、MSE 値は小さくなります。
Precision-
精度は、アルゴリズムが識別したすべての陽性のうち、真陽性 (TP) をどの程度適切に予測したかを測定します。精度は Precision = TP/(TP+FP) として定義し、値は 0~1 の範囲です。二項分類で使用します。偽陽性のコストが高い場合、精度は重要なメトリクスです。例えば、航空機の安全システムが誤って安全に飛行可能と判断した場合、偽陽性のコストは非常に高くなります。偽陽性 (FP) は、陽性予測であるが、データ内で実際には陰性であることを示します。
PrecisionMacro-
精度マクロは、多クラス分類問題の精度を計算します。そのために、各クラスの精度を計算し、スコアを平均化して複数のクラスの精度を取得します。
PrecisionMacroのスコアは 0~1 の範囲です。スコアが高いほど、モデルが特定したすべての陽性のうち、真陽性 (TP) を予測した能力が高いこと (複数のクラスを平均化した結果) を示します。 R2-
R2 は、決定係数とも呼ばれ、モデルが従属変数の分散をどれだけ説明できるかを定量化するために回帰で使用します。値は 1 から -1 の範囲です。数値が大きいほど、変動性を説明した割合が高いことを示します。ゼロ (0) に近い
R2値は、従属変数のほとんどをモデルが説明できなかったことを示します。負の値は、適合度が悪く、モデルは定数関数と比べてパフォーマンスが下回ることを示します。線形回帰の場合、これは水平線です。 Recall-
再現率は、アルゴリズムがデータセット内のすべての真陽性 (TP) をどれだけ正しく予測するかを測定します。真陽性は、陽性予測のうち、データ内で実際にも陽性である値を示します。再現率は、Recall = TP/(TP+FN) として定義し、値は 0~1 の範囲です。スコアが高いほど、データの真陽性 (TP) を予測するモデルの能力が高いことを示します。二項分類で使用します。
再現率は、すべての真陽性を見つけるために使用されるため、がんの検査で重要です。偽陽性 (FP) は、陽性予測であるが、データ内で実際には陰性であることを示します。再現率を測定するだけでは不十分な場合があります。すべての出力を真陽性として予測すると、完全な再現率スコアになってしまうためです。
RecallMacro-
RecallMacroは、多クラス分類問題の再現率を計算します。そのために、各クラスの再現率を計算し、スコアを平均化して複数のクラスの再現率を取得します。RecallMacroのスコアは 0~1 の範囲の値です。スコアが高いほど、データセット内の真陽性 (TP) を予測するモデルの能力が高いことを示します。真陽性は、陽性予測のうち、データ内で実際にも陽性である値です。再現率を測定するだけでは不十分な場合があります。すべての出力を真陽性として予測すると、完全な再現率スコアになってしまうためです。 RMSE-
二乗平均平方根誤差 (RMSE) は、予測値と実際値の二乗差の平均値を求め、その値の平方根を計算したものです。これは、モデルの予測誤差を理解するために回帰分析で使用します。これは、大きなモデル誤差や外れ値の存在を示す重要なメトリクスです。値はゼロ (0) から無限大の範囲で、数値が小さいほど、モデルがデータにより適合していることを示します。RMSE は規模に依存するため、サイズが異なるデータセットの比較には使用しないでください。
モデル候補に対して自動的に計算されるメトリクスは、対象としている問題のタイプによって決まります。
Autopilot でサポートされている使用可能なメトリクスのリストについては、Amazon SageMaker API リファレンスのドキュメントを参照してください。
Autopilot 加重メトリクス
注記
Autopilot は、Balanced Accuracy と InferenceLatency を除くすべての利用可能なメトリクスについて、アンサンブルモードでのみサンプルの重みをサポートしています。BalanceAccuracy には、不均衡なデータセットに対する独自の重み付けスキームが用意されており、サンプルの重みは必要ありません。InferenceLatency ではサンプルの重みはサポートされません。目的 Balanced Accuracy と InferenceLatency メトリクスはどちらも、モデルのトレーニングと評価時に既存のサンプルの重みを無視します。
ユーザーはデータにサンプルの重み列を追加して、機械学習モデルのトレーニングに使用される各観測に、モデルにとって認識されている重要度に応じた重みが割り当てられるようにすることができます。これは、データセット内の観測の重要度が異なる場合や、あるクラスのサンプル数が他のクラスと比較して不釣り合いな数のデータセットに含まれている場合に特に役立ちます。各観測にその重要度または少数クラスに対する重要度に基づいて重みを割り当てると、モデルの全体的なパフォーマンスが向上したり、モデルが多数派のクラスに偏らないようにしたりできます。
Studio Classic UI で実験を作成する際にサンプルの重みを渡す方法については、「Studio Classic UI を使用して Autopilot 実験を作成するには」のステップ 7 を参照してください。
API を使用して Autopilot を作成するときにサンプルの重みをプログラムで渡す方法については、「Create an Autopilot experiment programmatically」の「How to add sample weights to an AutoML job」を参照してください。
Autopilot での交差検証
交差検証は、モデル選択における過剰適合やバイアスを減らすために使用されます。このメソッドは、検証データセットが同じ集団から抽出された場合、モデルが未確認の検証データセットの値をどれだけセ核に予測できるかを評価するためにも使用されます。この方法は、トレーニングインスタンスの数が限られているデータセットをトレーニングする場合に特に重要です。
Autopilot は交差検証を使用して、ハイパーパラメータ最適化 (HPO) モードとアンサンブルトレーニングモードでモデルを構築します。Autopilot の交差検証プロセスの最初のステップは、データを K 分割することです。
K 分割
K 分割は、入力トレーニングデータセットを複数のトレーニングデータセットと検証データセットに分割する方法です。データセットは、k 個の同じサイズのサブサンプルまたは Fold に分割されます。その後、モデルは k-1 fold でトレーニングされ、残りの K 番目の fold (検証データセット) に対してテストされます。このプロセスは、検証用に別のデータセットを使って k 回繰り返されます。
次の画像は、K = 4 fold の K 分割を示しています。各 fold は行として表されます。濃い色のボックスは、トレーニングに使用されたデータの一部を表しています。残りの明るい色のボックスは検証データセットを表しています。

Autopilot は、ハイパーパラメータ最適化 (HPO) モードとアンサンブルモードの両方に K 分割交差検証を使用します。
他の Autopilot または SageMaker AI モデルと同様に、交差検証を使用して構築された Autopilot モデルをデプロイできます。
HPO モード
K 分割交差検証は、交差検証に K 分割メソッドを使用します。HPO モードでは、50,000 以下のトレーニングインスタンスを持つ小さなデータセットに対して、Autopilot が自動的に k-fold 分割交差検証を実行します。交差検証の実行は、過剰適合や選択バイアスを防ぐため、小規模なデータセットでトレーニングを行う場合に特に重要です。
HPO モードは、データセットのモデル化に使用される各候補アルゴリズムに対して 5 の k 値を使用します。複数のモデルが異なる分割でトレーニングされ、モデルは別々に保存されます。トレーニングが完了すると、各モデルの検証メトリクスが平均化され、1 つの推定メトリクスが生成されます。最後に、Autopilot は、試験で得られたモデルと最適な検証メトリクスを組み合わせてアンサンブルモデルにします。Autopilot はこのアンサンブルモデルを使用して予測を行います。
Autopilot によってトレーニングされたモデルの検証メトリクスは、モデルリーダーボードに目標メトリクスとして表示されます。特に指定しない限り、Autopilot は扱う各問題タイプに対してデフォルトの検証メトリクスを使用します。Autopilot が使用するすべてのメトリクスのリストについては、「Autopilot メトリクス」を参照してください。
例えば、ボストンの住宅のデータセット
交差検証を行うと、トレーニング時間が平均 20% 長くなる可能性があります。また、データセットが複雑な場合、トレーニング時間が大幅に長くなる可能性があります。
注記
HPO モードでは、各 fold のトレーニングメトリクスと検証メトリクスは、/aws/sagemaker/TrainingJobs CloudWatch Logs で確認できます。CloudWatch Logs の詳細については、「Amazon SageMaker AI の CloudWatch Logs」を参照してください。
アンサンブルモード
注記
Autopilot はアンサンブルモードでのサンプルの重みをサポートします。サンプルの重みをサポートする使用可能なメトリクスのリストについては、「Autopilot メトリクス」を参照してください。
アンサンブルモードでは、データセットのサイズに関係なく交差検証が実行されます。お客様は、独自の検証データセットとカスタムデータ分割比率を指定することも、Autopilot にデータセットを自動的に 80~20% の分割比率に分割させることもできます。トレーニングデータは交差検証のために k 分割に分割され、k の値は AutoGluon エンジンによって決定されます。アンサンブルは複数の機械学習モデルで構成され、各モデルはベースモデルと呼ばれます。1 つの基本モデルが (k-1) fold でトレーニングされ、残りの部分で out-of-fold 予測が行われます。このプロセスはすべての k fold で繰り返され、Out of fold (OOF) 予測が連結されて 1 つの予測セットになります。アンサンブル内のすべての基本モデルは、これと同じ OOF 予測の生成プロセスに従います。
以下の画像は、k = 4 fold での k 分割検証を示しています。各 fold は行として表されます。濃い色のボックスは、トレーニングに使用されたデータの一部を表しています。残りの明るい色のボックスは検証データセットを表しています。
画像の上部では、各 fold において、最初の基本モデルがトレーニングデータセットでトレーニングした後に検証データセットの予測を行います。それ以降の fold では、データセットの役割が変わります。以前はトレーニングに使用されていたデータセットが検証に使用されるようになり、これは逆にも当てはまります。k fold の最後には、すべての予測が連結されて、Out of fold (OOF) 予測と呼ばれる 1 つの予測セットが形成されます。このプロセスは n ベースモデルごとに繰り返されます。
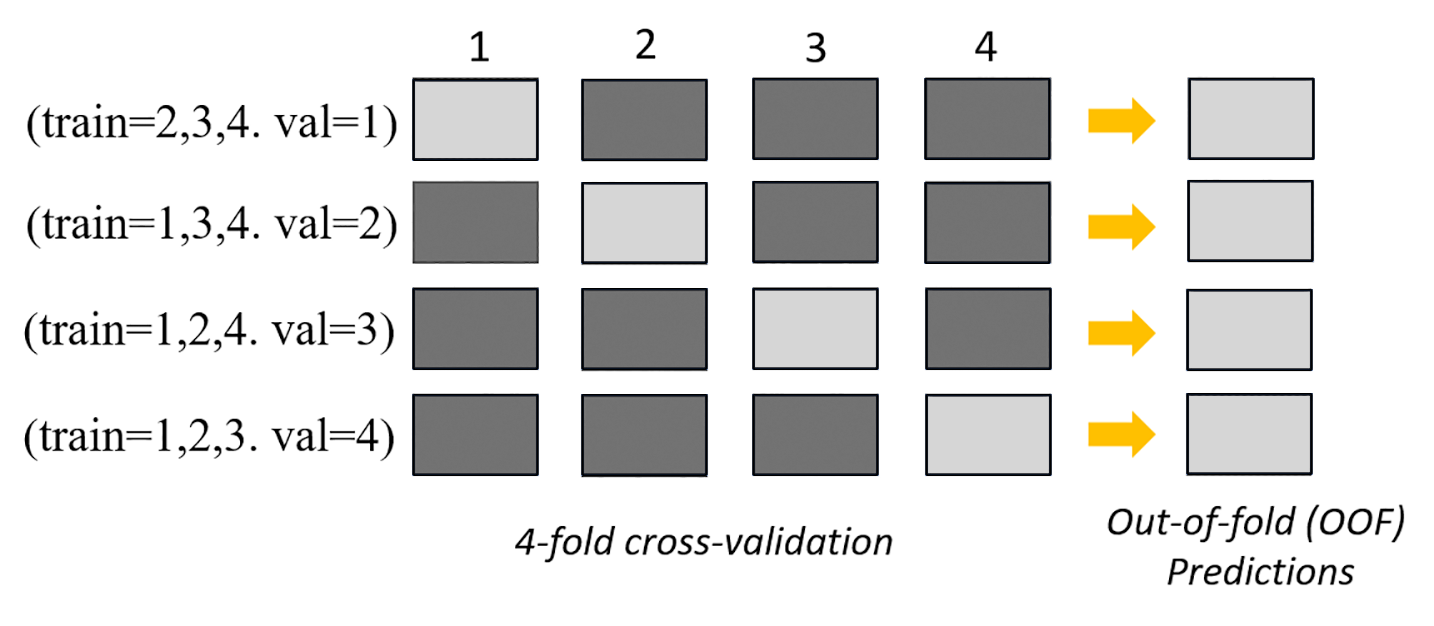
次に、各基本モデルの OOF 予測がスタッキングモデルをトレーニングするための特徴として使用されます。スタッキングモデルは各ベースモデルの重要度の重みを学習します。これらの重みを使用して OOF 予測を組み合わせて最終予測を作成します。検証データセットのパフォーマンスによって、どのベースモデルまたはスタッキングモデルが最適かが決まり、このモデルが最終モデルとして返されます。
アンサンブルモードでは、独自の検証データセットを提供することも、Autopilot に入力データセットを 80% のトレーニングと 20% の検証データセットに自動的に分割させることもできます。次に、トレーニングデータを k 分割に分割して交差検証を行い、fold ごとに OOF 予測と基本モデルを生成します。
これらの OOF 予測はスタッキングモデルをトレーニングするための特徴として使用され、スタッキングモデルは各ベースモデルの重みを同時に学習します。これらの重みを使用して OOF 予測を組み合わせ、最終予測を作成します。各 fold の検証データセットは、すべてのベースモデルとスタッキングモデルのハイパーパラメータ調整に使用されます。検証データセットのパフォーマンスによって、どのベースモデルまたはスタッキングモデルが最適かが決まり、このモデルが最終モデルとして返されます。
