Autopilot モデルのパフォーマンスレポートを表示する
Amazon SageMaker AI モデル品質レポート (パフォーマンスレポートとも呼ばれる) は、AutoML ジョブによって生成された最適なモデル候補に関するインサイトと品質情報を提供します。これには、ジョブの詳細、モデルの問題タイプ、目的関数、および問題タイプに関連するその他の情報が含まれます。このガイドでは、Amazon SageMaker Autopilot のパフォーマンスメトリクスをグラフィカルに表示する方法、または JSON ファイル内の raw データとしてメトリクスを表示する方法を説明します。
例えば、分類問題の場合、モデル品質レポートには以下が含まれます。
-
混同行列
-
受信者操作特性曲線の下面積 (AUC)
-
偽陽性と偽陰性を理解するための情報
-
真陽性と偽陽性のトレードオフ
-
精度と再現率のトレードオフ
Autopilot は、候補となるすべてのモデルのパフォーマンスメトリクスも提供します。これらのメトリクスはすべてのトレーニングデータを使用して計算され、モデルのパフォーマンスの推定に使用されます。メイン作業領域には、デフォルトでこれらのメトリクスが含まれます。メトリクスの種類は、対処する問題の種類によって決まります。
Autopilot でサポートされている使用可能なメトリクスのリストについては、Amazon SageMaker API リファレンスのドキュメントを参照してください。
関連するメトリクスを使用してモデル候補を並べ替えると、ビジネスニーズに対処するモデルを選択してデプロイしやすくなります。これらのメトリクスの定義については、「Autopilot candidate metrics」トピックを参照してください。
Autopilot ジョブのパフォーマンスレポートを表示するには、以下の手順に従います。
-
左側のナビゲーションペインからホームアイコン (
 ) を選択し、[Amazon SageMaker Studio Classic] の最上位のナビゲーションメニューを表示します。
) を選択し、[Amazon SageMaker Studio Classic] の最上位のナビゲーションメニューを表示します。 -
メインワークエリアから [AutoML] カードを選択します。新しい [Autopilot] タブが開きます。
-
[名前] セクションで、調べたい詳細を含む Autopilot ジョブを選択します。新しい [Autopilot ジョブ] タブが開きます。
-
[Autopilot ジョブ] パネルには、[モデル名] の下に各モデルの [目標] メトリクスを含むメトリクス値が表示されます。[最適なモデル] はリストの一番上にある [モデル名] の下に表示され、[モデル] タブで強調表示されます。
-
モデルの詳細を確認するには、確認したいモデルを選択し、[モデル詳細の表示] を選択します。新しい [モデルの詳細] タブが開きます。
-
-
[説明可能性] タブと [アーティファクト] タブの間の [パフォーマンス] タブを選択します。
-
タブの右上にある [パフォーマンスレポートのダウンロード] ボタンの下向き矢印を選択します。
-
下向き矢印には、Autopilot のパフォーマンスメトリクスを表示するためのオプションが 2 つあります。
-
パフォーマンスレポートの PDF をダウンロードして、メトリクスをグラフィカルに表示できます。
-
メトリクスを raw データとして表示し、JSON ファイルとしてダウンロードできます。
-
-
SageMaker Studio Classic で AutoML ジョブを作成して実行する方法については、「AutoML API を使用して表形式データのリグレッションジョブまたは分類ジョブを作成する」を参照してください。
パフォーマンスレポートには 2 つのセクションがあります。1 つ目のセクションには、モデルを作成した Autopilot ジョブに関する詳細が含まれています。2 つ目のセクションには、モデル品質レポートが含まれています。
Autopilot ジョブの詳細
レポートの最初のセクションには、モデルを作成した Autopilot ジョブに関する一般的な情報が記載されています。ジョブの詳細には、以下の情報が含まれます。
-
Autopilot 候補名
-
Autopilot ジョブ名
-
問題タイプ
-
目標メトリクス
-
最適化の方向
モデル品質レポート
モデル品質情報は、Autopilot モデルインサイトによって生成されます。生成されるレポートの内容は、対処する問題のタイプ (回帰、二項分類、または多クラス分類) によって異なります。このレポートは、評価データセットに含まれていた行の数と、評価が行われた時刻を示します。
メトリクステーブル
モデル品質レポートの最初の部分にはメトリクステーブルが含まれています。これらは、モデルが対処した問題のタイプに適したものです。
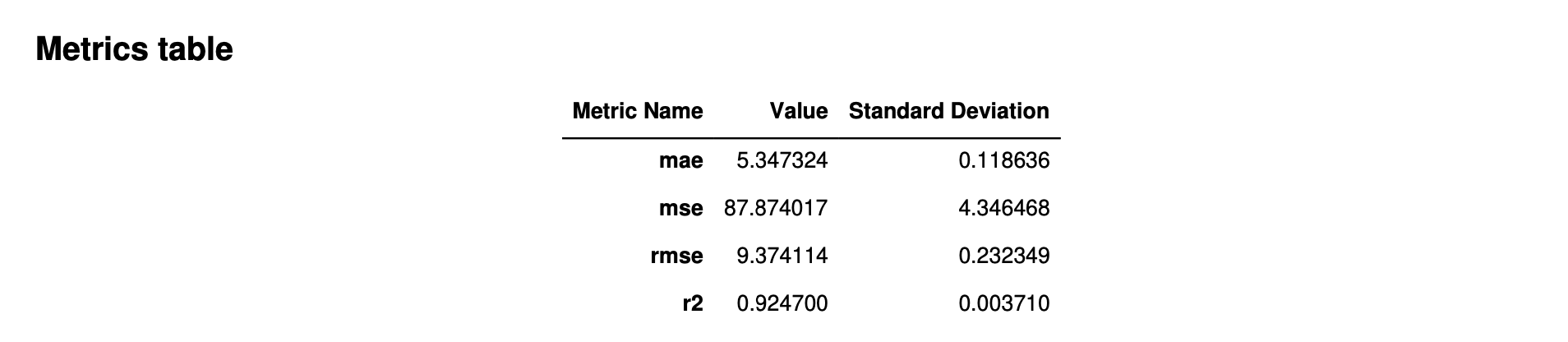
以下の図は、Autopilot が回帰問題に対して生成するメトリクステーブルの例です。メトリクスの名前、値、標準偏差が表示されます。
以下の図は、多クラス分類問題に関して、Autopilot によって生成されるメトリクステーブルの例です。メトリクスの名前、値、標準偏差が表示されます。
グラフィカルなモデルパフォーマンス情報
モデル品質レポートの 2 つ目の部分には、モデルのパフォーマンスを評価するのに役立つグラフィカルな情報が含まれています。このセクションの内容は、モデリングで使用した問題タイプに応じて異なります。
受信者操作特性曲線の下面積
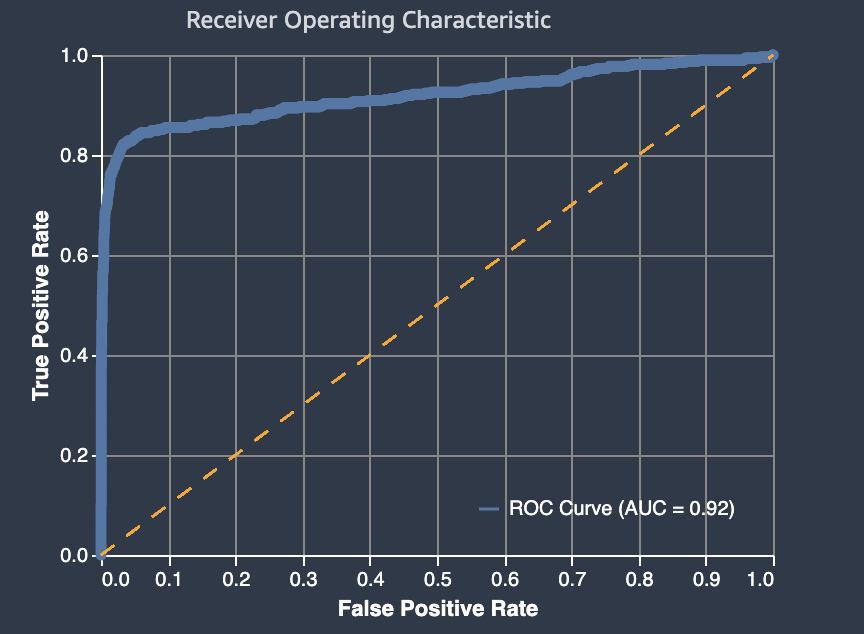
受信者操作特性曲線の下面積は、真陽性率と偽陽性率のトレードオフを表します。これは、二項分類モデルで使用される業界標準の精度メトリクスです。AUC (受信者操作特性曲線) は、モデルが陰性の例と比較して陽性の例により高いスコアを予測する能力を測定します。AUC メトリクスは、考えられるすべての分類しきい値にわたってモデルパフォーマンスの集約評価基準を提供します。
AUC のメトリクスは 0 から 1 の 10 進値を返します。1 に近い AUC 値は、極めて正確な機械学習モデルであることを示します。0.5 付近の値は、モデルのパフォーマンスがランダムな推測を上回っていないことを示します。0 に近い AUC 値は、機械学習モデルが正しいパターンを学習したが、これらのパターンを使用して可能な限り不正確な予測を行っていることを示します。値がゼロに近い場合、データに問題がある可能性があります。AUC メトリクスの詳細については、Wikipedia の記事「Receiver operating characteristic
以下は、バイナリ分類モデルによる予測を評価するための、受信者操作特性曲線グラフの下面積の例です。細い点線は、ランダムな推測を上回ることがないモデルの受信者操作特性曲線の下面積を表し、AUC スコアは 0.5 です。より正確な分類モデルの曲線は、このランダムベースラインより上にあり、真陽性の割合が偽陽性の率を超えています。二項分類モデルの性能を表す受信機動作特性曲線の下面積は、太い実線です。
グラフを構成する偽陽性率 (FPR) と真陽性率 (TPR) の構成要素の概要は、次のように定義されます。
-
正しい予測
-
真陽性 (TP): 予測値は 1 で、真の値は 1 です。
-
真陰性 (TN): 予測値は 0 で、真の値は 0 です。
-
-
誤った予測
-
偽陽性 (FP): 予測値は 1 ですが、真の値は 0 です。
-
偽陰性 (FN): 予測値は 0 ですが、真の値は 1 です。
-
偽陽性率 (FPR) は、FP と TN の合計に対して、陽性として誤って予測された (FP) 真陰性 (TN) の割合を測定します。範囲は 0~1 です。値が小さいほど予測精度が高いことを示します。
-
FPR = FP/(FP+TN)
真陽性率 (TPR) は、TP と偽陰性 (FN) の合計に対して、陽性として正しく予測された真陽性 (TP) の割合を測定します。範囲は 0~1 です。値が大きいほど予測精度が良いことを示します。
-
TPR = TP/(TP+FN)
混同行列
混同行列は、さまざまな問題に対して、二項分類および多クラス分類のモデルで行われた予測の精度を可視化する方法を提供します。モデル品質レポートの混同行列には以下が含まれます。
-
実際のラベルの予測の正解と誤りの数と割合
-
左上から右下までの対角線上に示される、正確な予測の数と割合
-
右上から左下までの対角線上に示される、不正確な予測の数と割合
混同行列上の誤った予測は、混同値です。
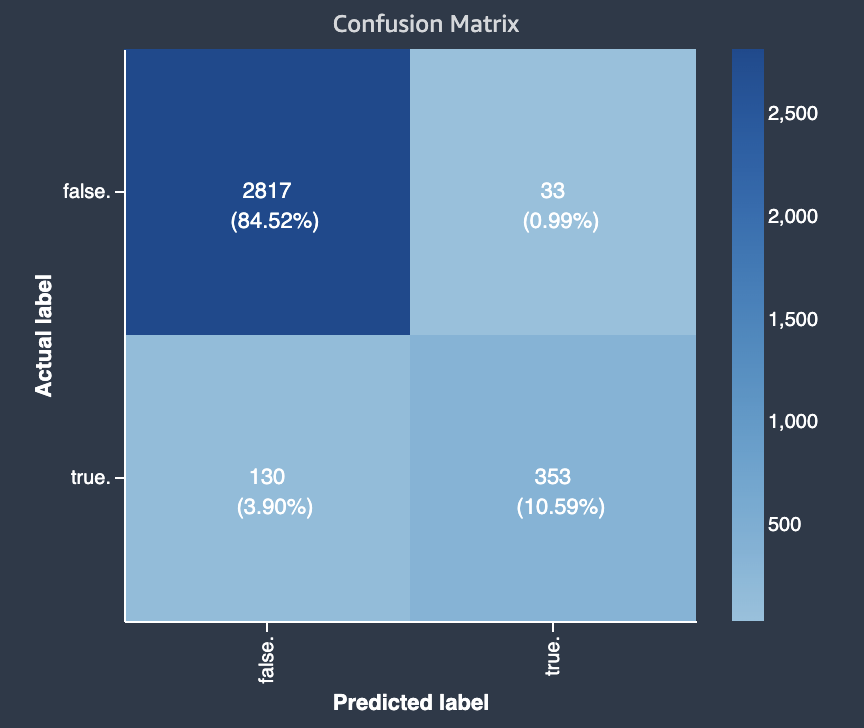
次の図は、二項分類問題に関する混同行列の例です。これには、以下の情報が含まれています。
-
縦軸は、真と偽の実際のラベルを含む 2 つの行に分かれています。
-
横軸は、モデルによって予測された真と偽のラベルを含む 2 つの列に分かれています。
-
カラーバーは、各カテゴリに分類された値の数を視覚的に示すために、サンプル数が多いほど暗い色調を割り当てます。
この例では、モデルは 2,817 個の実際の false 値を正しく予測し、353 個の実際の true 値を正しく予測しました。このモデルでは、130 個の実際の true 値が false で、33 個の実際の false 値が true であると誤って予測されていました。階調の違いは、データセットのバランスが取れていないことを示しています。この不均衡は、実際の false ラベルの方が実際の true ラベルよりもはるかに多いためです。
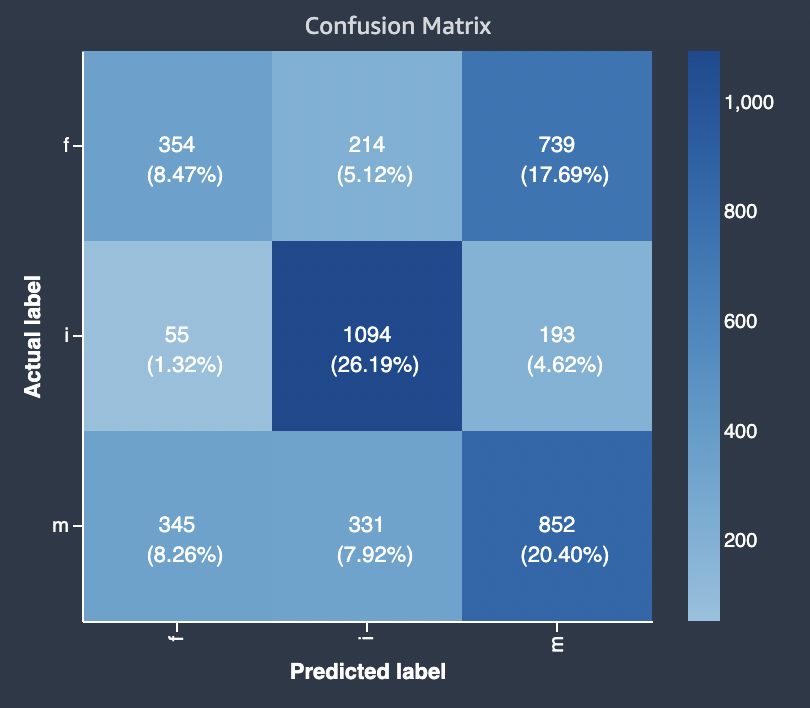
次の図は、多クラス分類問題に関する混同行列の例です。モデル品質レポートの混同行列には以下が含まれます。
-
縦軸は、3 つの異なる実際のラベルを含む 3 つの行に分かれています。
-
横軸は、モデルによって予測されたラベルを含む 3 つの列に分かれています。
-
色付きのバーは、各カテゴリに分類された値の数を視覚的に示すため、サンプル数が多いほど濃い色調を割り当てています。
以下の例では、モデルはラベル f の実際の値を 354 個、ラベル i の値を 1,094 個、ラベル m の値を 852 個正しく予測しています。色調の違いは、値 i のラベルが f や m よりも多いため、データセットのバランスが取れていないことを示しています。
提供されたモデル品質レポートの混同行列は、多クラス分類問題タイプに対して、最大 15 個のラベルを収容することができます。ラベルに対応する行に Nan 値が表示されている場合、モデル予測のチェックに使用された検証データセットにはそのラベルのデータが含まれていないことを意味します。
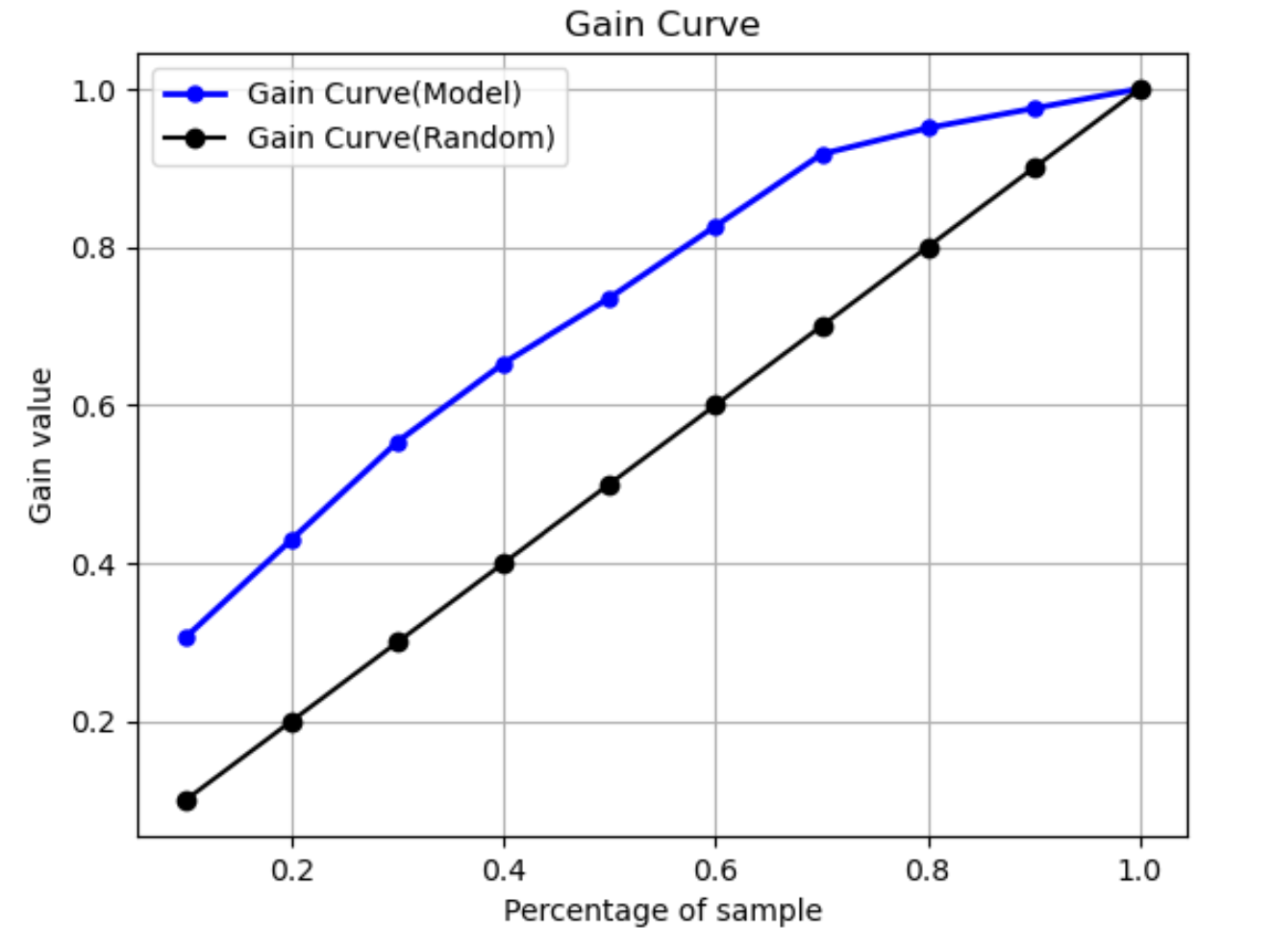
ゲイン曲線
二項分類では、ゲイン曲線は、データセットの割合を使用して陽性ラベルを見つけることによる累積的なメリットを予測します。ゲイン値は、トレーニング中に、陽性観測値の累積数をデータ内の陽性観測値の総数で除算し、各十分位数で算出されます。トレーニング中に作成した分類モデルが目に見えないデータを表すものであれば、ゲイン曲線を使用して、陽性ラベルの割合を取得するためにターゲットにしなければならないデータの割合を予測できます。使用するデータセットの割合が高いほど、検出された陽性ラベルの割合も高くなります。
次のグラフ例では、ゲイン曲線は傾きが変化する線です。直線は、データセットからランダムにデータの割合を選択して見つかった陽性ラベルの割合です。データセットの 20% をターゲットにすると、陽性ラベルの 40% を超えるものが見つかると予想されます。一例として、ゲイン曲線を使用してマーケティングキャンペーンにおける取り組みを決定することを検討するとします。ゲイン曲線の例で言うと、ある地域の 83% の人がクッキーを購入するためには、その地域の約 60% に広告を送信することになります。
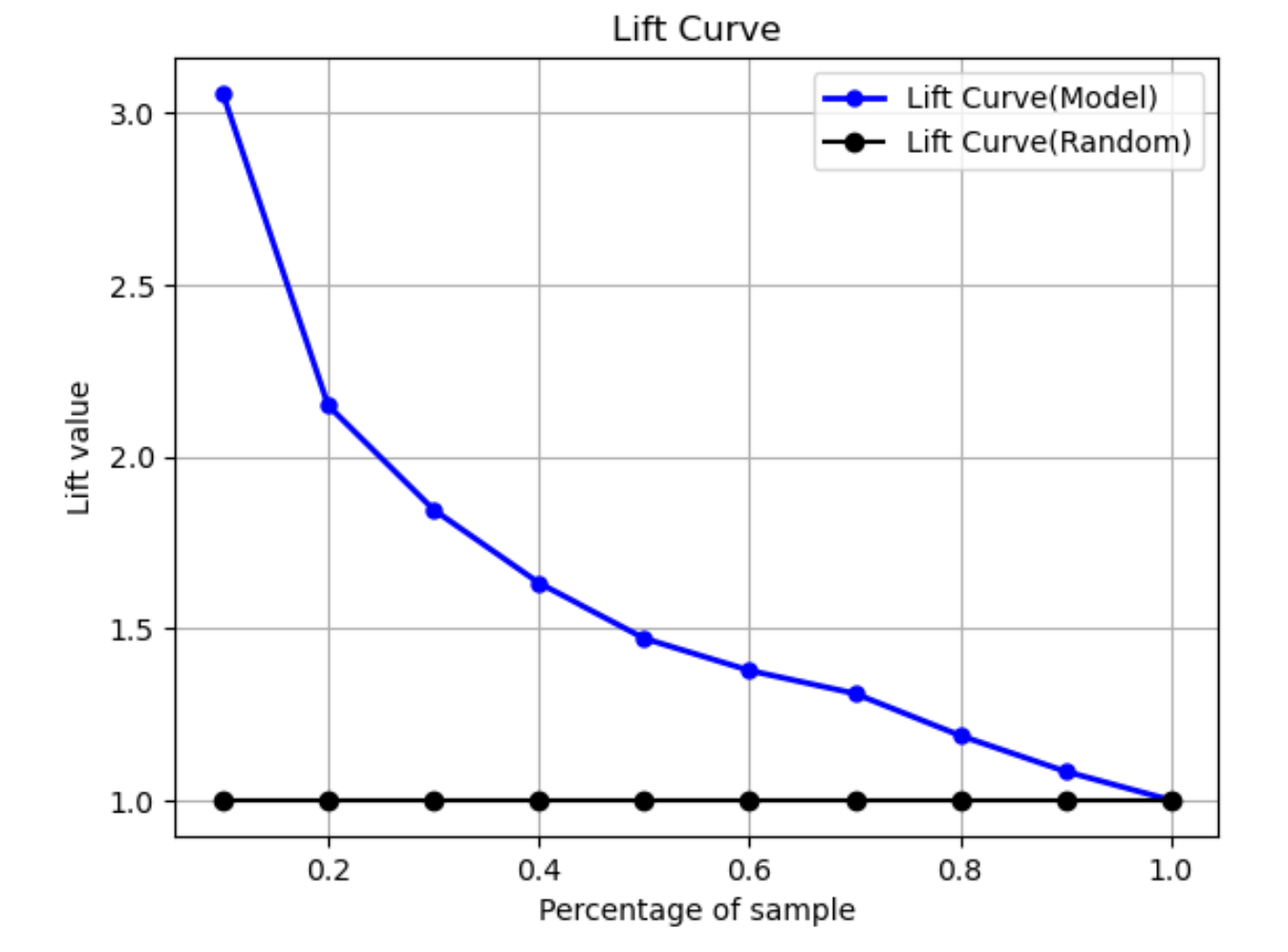
リフト曲線
二項分類におけるリフト曲線は、トレーニング済みのモデルを使用して陽性ラベルが見つかる可能性を無作為に推定した場合と比較して向上することを示しています。リフト値は、各十分位数における陽性ラベルの比率に対する増加率の比率を使用してトレーニング中に計算されます。トレーニング中に作成したモデルが目に見えないデータを表すものである場合は、リフト曲線を使用して、ランダムに推測するよりもそのモデルを使用するメリットを予測します。
次のグラフ例では、リフト曲線は傾きが変化する線です。直線は、データセットから対応する割合をランダムに選択したときのリフト曲線です。データセットの 40% をモデルの分類ラベルでターゲットにすると、目に見えないデータの 40% を無作為に選択した場合に見つかる陽性ラベルの数の約 1.7 倍が見つかると予想されます。
精度-再現率曲線
精度-再現率曲線は、二項分類問題における精度と再現率のトレードオフを表します。
精度は、陽性と予測されたすべての結果 (TP と偽陽性) のうち、実際の陽性が陽性と予測された (TP) 割合を測定します。範囲は 0~1 です。値が大きいほど、予測された値の精度が高いことを示します。
-
精度 = TP/(TP+FP)
再現率は、すべての実際の陽性予測数 (TP と偽陰性) のうち、実際の陽性が陽性と予測された (TP) 割合を測定します。これは、感度または真陽性率とも呼ばれます。範囲は 0~1 です。値が大きいほど、サンプルからの陽性値の検出率が高いことを示します。
-
再現率 = TP/(TP+FN)
分類問題の目的は、できるだけ多くの要素に正しくラベルを付けることです。再現率は高いが精度が低いシステムでは、偽陽性の割合が高くなります。
次の図は、すべての E メールをスパムとしてマークするスパムフィルターを示しています。再現率は偽陽性を測定しないため、再現率は高くなりますが、精度は低くなります。
偽陽性の値に対するペナルティは低いが、真陽性の結果を見逃した場合は高いペナルティがある問題の場合は、精度よりも再現率に重きを置きます。例えば、自動運転車両で差し迫った衝突を検出する場合などです。
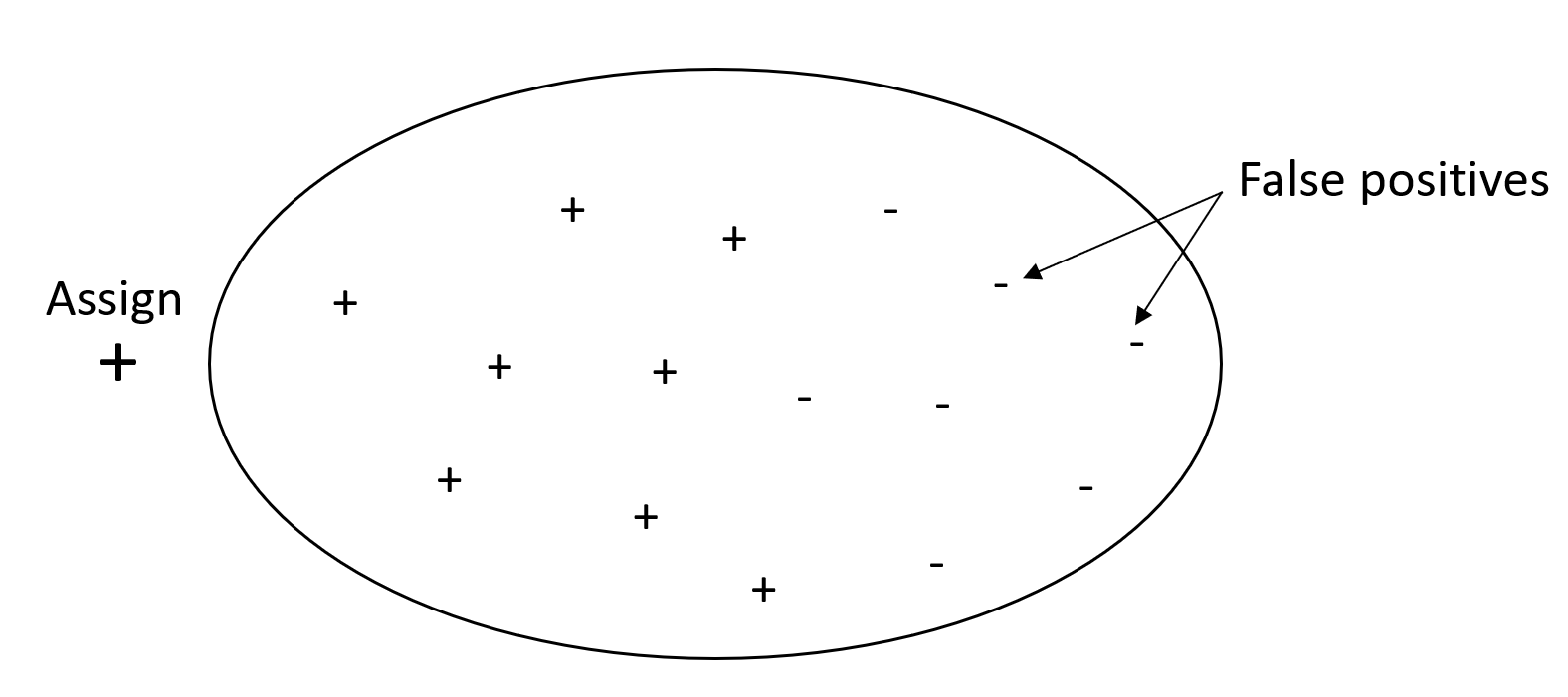
これとは対照的に、精度は高いが再現率が低いシステムでは、偽陰性の割合が高くなります。すべての E メールを望ましい (スパムではない) ものとしてマークするスパムフィルターは精度は高くなりますが、精度が偽陰性を測定しないため、再現率は低くなります。
問題で、偽陰性の値に対するペナルティは低いが、真陰性の結果を見逃した場合のペナルティが高い場合は、再現率よりも精度を重視してください。例えば、税務監査のために疑わしいフィルターにフラグを立てる場合などです。
次の図は、精度が高いが再現率が低いスパムフィルターを示しています。精度では偽陰性を測定できないためです。
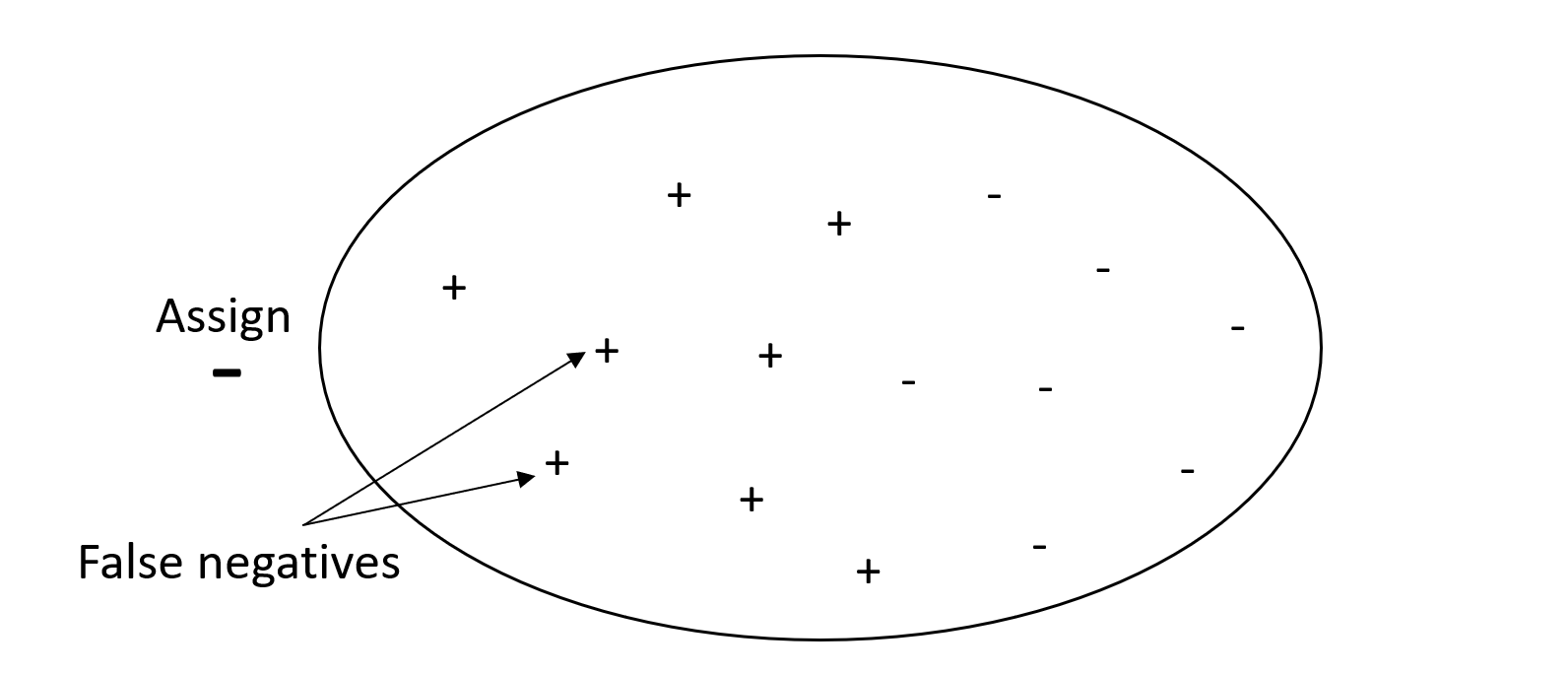
高い精度と高い再現率の両方を備えたモデルが予測を行う場合、正しくラベル付けされた結果が数多く生成されます。詳細については、Wikipedia の「Precision and recall
精度-再現率曲線の下面積 (AUPRC)
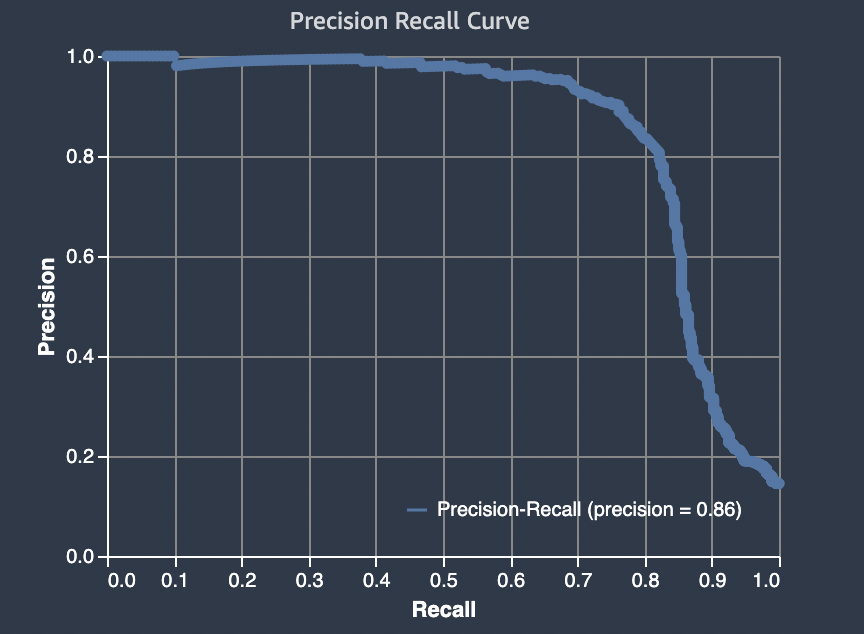
二項分類の問題の場合、Amazon SageMaker Autopilot には精度-再現率曲線の下面積 (AUPRC) のグラフが含まれます。AUPRC メトリクスは、考えられるすべての分類しきい値にわたってモデルパフォーマンスの集約評価基準を提供し、精度と再現率の両方を使用します。AUPRC は真陰性の数を取得しません。そのため、データに真陰性が多数含まれている場合は、モデルのパフォーマンスを評価すると便利な場合があります。例えば、まれな突然変異を含む遺伝子をモデル化する場合などです。
以下の図は AUPRC グラフの例です。精度の最高値は 1 で、再現率は 0 です。グラフの右下隅では、再現率は最高値 (1) で、精度は 0 です。これら 2 つの点の間にある AUPRC 曲線は、異なるしきい値での精度と再現率のトレードオフを示しています。
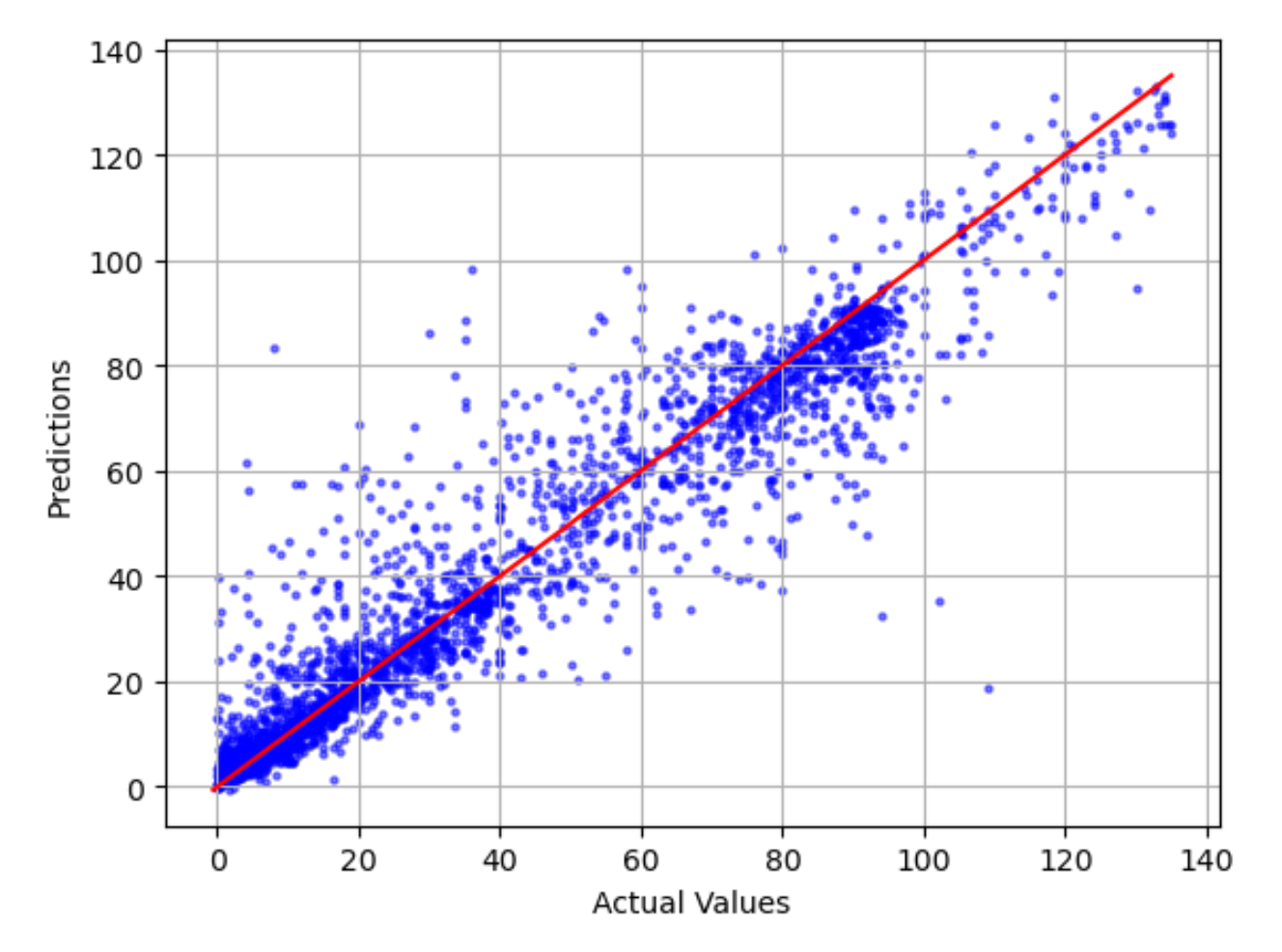
予測値に対する実際値のプロット
予測値に対する実際値のプロットには、実際のモデル値と予測されたモデル値の差が表示されます。次のグラフ例では、実線は最適な直線です。モデルが 100% 正確であれば、予測される各点は対応する実際の点と等しく、最も適合するこの線上にあることになります。最適な線からの距離は、モデルエラーを視覚的に示します。最適な線からの距離が大きいほど、モデル誤差は大きくなります。
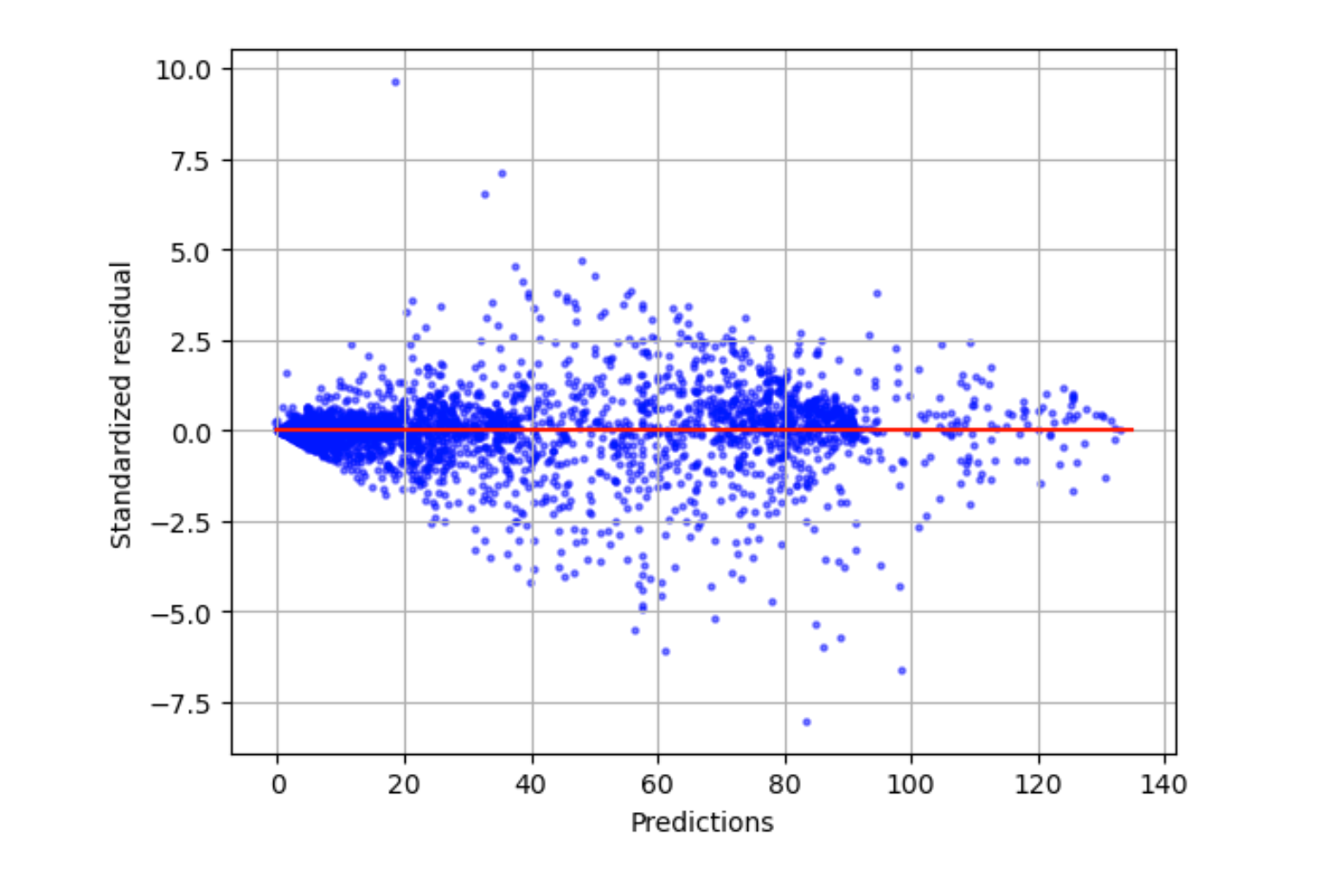
標準化残差プロット
標準化残差プロットには以下の統計用語が含まれます。
residual-
(未加工の) 残差は、実際の値とモデルによって予測された値との差を示します。差が大きいほど、残差値は大きくなります。
standard deviation-
標準偏差は、値が平均値とどの程度異なるかを示す尺度です。標準偏差が高いということは、多くの値が平均値と大きく異なることを示しています。標準偏差が低いということは、多くの値が平均値に近いことを示しています。
standardized residual-
標準化残差は、未加工の残差を標準偏差で割ります。標準化残差には標準偏差の単位があり、未加工残差のスケールの違いに関係なくデータ内の外れ値を特定するのに役立ちます。標準化残差が他の標準化残差よりもはるかに小さいか大きい場合は、モデルがこれらの観測値にうまく適合していないことを示しています。
標準化残差プロットは、観測値と期待値の差の強度を測定します。実際の予測値は X 軸に表示されます。絶対値 3 よりも大きい値のポイントは、通常、外れ値と見なされます。
次のグラフ例は、多数の標準化残差が横軸の 0 を中心に集まっていることを示しています。ゼロに近い値は、モデルがこれらの点にうまく適合していることを示しています。プロットの上部と下部にある点は、モデルによって適切に予測されません。
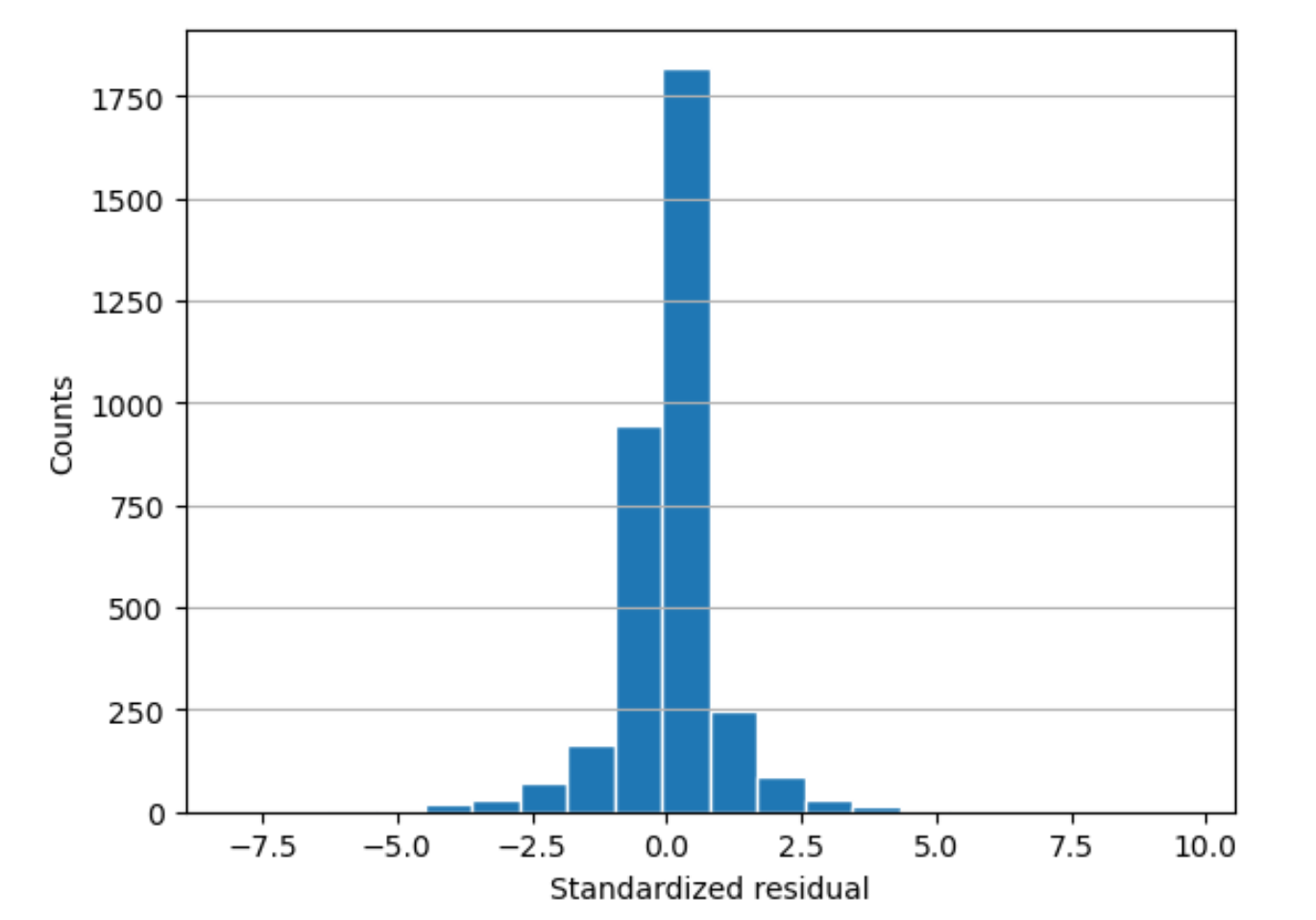
残差ヒストグラム
残差ヒストグラムには以下の統計用語が含まれます。
residual-
(未加工の) 残差は、実際の値とモデルによって予測された値との差を示します。差が大きいほど、残差値は大きくなります。
standard deviation-
標準偏差は、値が平均値とどの程度異なるかを示す尺度です。標準偏差が高いということは、多くの値が平均値と大きく異なることを示しています。標準偏差が低いということは、多くの値が平均値に近いことを示しています。
standardized residual-
標準化残差は、未加工の残差を標準偏差で割ります。標準化残差には標準偏差の単位があります。これらは、未加工の残差のスケールの違いに関係なく、データ内の外れ値を特定するのに役立ちます。標準化残差が他の標準化残差よりもはるかに小さいか大きい場合は、そのモデルがこれらの観測値にうまく適合していないことを示しています。
histogram-
ヒストグラムは、ある値が出現する頻度を示すグラフです。
残差ヒストグラムは、標準化された残差値の分布を示します。ヒストグラムが、ゼロを中心とするベル形状で分布している場合、モデルがターゲット値の特定の範囲で体系的に過大予測または過小予測していないことを示します。
以下の図では、標準化された残差値は、モデルがデータにうまく適合していることを示しています。グラフに中央値から遠く離れた値が表示されている場合は、それらの値がモデルにうまく適合していないことを示しています。