翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon SageMaker AI による機械学習の概要
このセクションでは、一般的な機械学習 (ML) ワークフローと、Amazon SageMaker AI でこれらのタスクを実行する方法について説明します。
機械学習では、コンピュータに予測や推論を行うように教えます。まず、アルゴリズムとサンプルデータを使用してモデルをトレーニングします。次に、モデルをアプリケーションに統合して、リアルタイムで、そして大規模に推論を生成します。
次の図は、ML モデル作成の一般的なワークフローを示しています。循環フローには 3 つのステージが含まれており、図の続きで詳しく説明します。
-
サンプルデータを生成する
-
モデルをトレーニングする
-
モデルをデプロイする
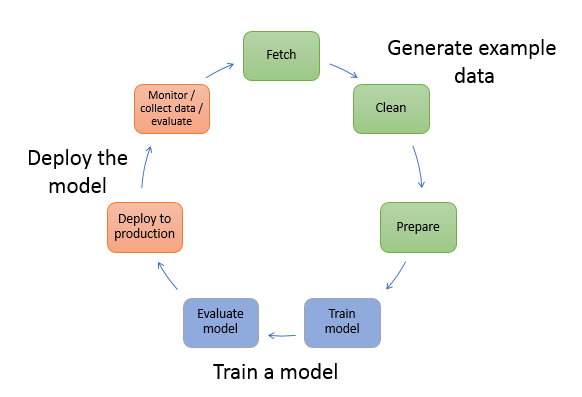
この図は、最も一般的なシナリオで次のタスクを実行する方法を示しています。
-
サンプルデータを生成する – モデルをトレーニングするには、サンプルデータが必要です。必要なデータのタイプは、モデルで解決するビジネス上の問題によって異なります。これは、モデルが生成する推論に関連しています。例えば、手書き数字の入力画像からその数字を予測するモデルを作成するとします。このモデルをトレーニングするには、手書き数字の画像サンプルが必要です。
モデルトレーニングに使用する前に、データ科学者は多くの場合、サンプルデータの探索や前処理に多くの時間を費やしています。データを前処理するには、通常、次の操作を実行します。
-
データを取得する – 社内にサンプルデータリポジトリがある場合や、公開されているデータセットを使用する場合があります。通常、データセット (複数可) を 1 つのリポジトリにプルします。
-
データをクリーンアップする - モデルトレーニングを改善するには、データを検査し、必要に応じてクリーンアップします。例えば、データの
country name属性に、United StatesとUSの値がある場合、データの整合性をとるために編集できます。 -
データを準備または変換する - 追加のデータ変換を実行してパフォーマンスを向上させることができます。例えば、航空機の除氷を必要とする条件を予測するモデル用に、属性を組み合わせることを選択できます。温度と湿度の属性を別々に使用するのではなく、それらの属性を組み合わせて新しい 1 つの属性にすることで、より良いモデルを得ることができます。
SageMaker AI では、統合開発環境 (IDE) の SageMaker Python SDK で SageMaker APIs を使用してサンプルデータを前処理できます。 SageMaker
SDK for Python (Boto3) を使用すると、モデルトレーニング用にデータを取得、探索、準備できます。データの準備、処理、変換の詳細については、「SageMaker AI で適切なデータ準備ツールを選択するための推奨事項」、「SageMaker Processing によるデータ変換ワークロード」、「特徴量ストアを使用して特徴量を作成、保存、共有する」を参照してください。 -
-
モデルをトレーニングする - モデルトレーニングには、次のように、モデルのトレーニングと評価の両方が含まれます。
-
モデルのトレーニング - モデルをトレーニングするには、アルゴリズムまたは事前トレーニング済みのベースモデルが必要です。選択するアルゴリズムは、さまざまな要因によって異なります。組み込みソリューションでは、SageMaker が提供するアルゴリズムのいずれかを使用できます。SageMaker によって提供されるアルゴリズムのリストおよび関連する考慮事項については、「Amazon SageMaker の組み込みアルゴリズムと事前トレーニング済みモデル」を参照してください。アルゴリズムとモデルを提供する UI ベースのトレーニングソリューションについては、「SageMaker JumpStart の事前トレーニング済みモデル」を参照してください。
トレーニングのためにコンピューティングリソースも必要です。リソースの使用は、トレーニングデータセットのサイズと、結果を必要とする速度によって異なります。1 つの汎用インスタンスから GPU インスタンスの分散クラスターまでのリソースを使用できます。詳細については、「Amazon SageMaker でモデルをトレーニングする」を参照してください。
-
モデルの評価 - モデルをトレーニングした後、モデルを評価して、推論の正確性が許容可能かどうかを判断します。モデルをトレーニングして評価するには、SageMaker Python SDK
を使用して、使用可能な IDE のいずれかを介してモデルにリクエストを送信し、推論を実行します。モデルの評価の詳細については、「Amazon SageMaker Model Monitor を使用したデータとモデルの品質モニタリング」を参照してください。
-
-
モデルをデプロイする – モデルをアプリケーションと統合してデプロイする前に、モデルを従来の方法で設計し直す必要があります。SageMaker AI ホスティングサービスを使用すると、モデルを個別にデプロイし、アプリケーションコードから切り離すことができます。詳細については、「推論のためのモデルをデプロイする」を参照してください。
機械学習は、継続的なサイクルです。モデルをデプロイしたら、推論のモニタリング、より高品質なデータの収集、およびモデルの評価を行い、ドリフトを特定します。次に、トレーニングデータを更新して新しく収集した高品質データを含めることで、推論の精度を高めます。より多くのサンプルデータが利用可能になれば、モデルの再トレーニングを続けて、精度を上げることができます。
