翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデル並列処理の概要
モデル並列処理は、深層学習モデルを複数のデバイス、インスタンス内またはインスタンス間で分割する分散型トレーニング方法です。この紹介ページでは、モデル並列処理に関する大まかな概要、通常非常に大きなサイズの DL モデルをトレーニングする際に発生する問題の克服に役立つ方法の説明、モデルの並列ストラテジーとメモリ消費の管理に役立つ SageMaker モデル並列ライブラリの例を紹介します。
モデル並列処理とは
深層学習モデル (レイヤーとパラメータ) のサイズを大きくすると、コンピュータービジョンや自然言語処理などの複雑なタスクの精度が向上します。ただし、単一の GPU のメモリに収めることができる最大モデルサイズには制限があります。DL モデルをトレーニングする場合、GPU メモリの制限は次の点でボトルネックになる可能性があります。
-
モデルのメモリフットプリントはパラメータの数に比例して大きくなるため、トレーニングできるモデルのサイズが制限されます。
-
これにより、トレーニング中の GPU ごとのバッチサイズが制限され、GPU の使用率とトレーニング効率が低下します。
1 つの GPU でのモデルのトレーニングに関連する制限を克服するために、SageMaker はモデル並列ライブラリを提供し、DL モデルを複数のコンピューティングノードに分散して効率的にトレーニングすることを支援します。さらに、このライブラリでは、EFA 対応デバイスを使用して最適化された分散トレーニングを実現できます。これにより、低遅延、高スループット、OS バイパスによるノード間通信のパフォーマンスが向上します。
モデル並列処理を使用する前にメモリ要件を見積もる
SageMaker モデル並列ライブラリを使用する前に、以下の点を考慮して、大きな DL モデルの学習に必要なメモリ量を把握してください。
AMP (FP16) と Adam オプティマイザを使用するトレーニングジョブでは、パラメータ 1 つあたりに必要な GPU メモリは約 20 バイトで、以下のように分類できます。
-
FP16 パラメータ (最大 2 バイト)
-
FP16 勾配 (最大 2 バイト)
-
FP32 オプティマイザステート (Adam オプティマイザに基づく最大 8 バイト)
-
パラメータの FP32 コピー (最大 4 バイト) (
optimizer apply(OA) オペレーションに必要) -
勾配の FP32 コピー (最大 4 バイト) (OA オペレーションに必要)
100 億個のパラメータを持つ比較的小規模な DL モデルでも、少なくとも 200GB のメモリが必要になることがあります。これは、単一の GPU で利用できる一般的な GPU メモリ (例えば、40GB/80GB のメモリを搭載した NVIDIA A100 と 16/32GB のメモリを搭載した V100) よりもはるかに大きいメモリです。モデルとオプティマイザの状態に必要なメモリ量に加えて、フォワードパスで生成されるアクティベーションなど、他のメモリ消費量もあることに注意してください。必要なメモリは 200GB をはるかに超える場合があります。
分散型トレーニングでは、それぞれ NVIDIA V100 と A100 Tensor コア GPU を搭載した Amazon EC2 P3 インスタンスと P4 インスタンスを使用することをお勧めします。CPU コア、RAM、アタッチされたストレージボリューム、ネットワーク帯域幅などの仕様の詳細については、Amazon EC2 インスタンスタイプ
高速コンピューティングインスタンスを使用しても、Megatron-LM や T5 のように約 100 億個のパラメータを持つモデルや、GPT-3 のように数千億個のパラメータを持つさらに大規模なモデルでは、各 GPU デバイスのモデルレプリカに適合しないことは明らかです。
ライブラリがモデルの並列処理とメモリ節約の手法を採用している方法
このライブラリは、さまざまなタイプのモデル並列処理機能と、オプティマイザ状態のシャーディング、アクティベーションチェックポイント、アクティベーションオフロードなどのメモリ節約機能で構成されています。これらの手法をすべて組み合わせることで、数千億のパラメータで構成される大規模なモデルを効率的にトレーニングできます。
トピック
シャーディングデータ並列処理 (PyTorch で利用可能)
シャーディングデータ並列処理は、メモリを節約する分散トレーニング手法で、モデルの状態 (モデルパラメータ、勾配、およびオプティマイザの状態) をデータ並列グループ内の GPU 間で分割します。
SageMaker AI は、MiCS MiCS は、c ommunication s cale を模倣し、ブログ記事「巨大なモデルトレーニングのほぼ線形スケーリング AWS
シャーディングデータ並列処理は、スタンドアロン戦略としてモデルに適用できます。さらに、NVIDIA A100 Tensor Core GPU、ml.p4d.24xlarge を搭載した最もパフォーマンスの高い GPU インスタンスを使用している場合は、SMDDP Collectives が提供する AllGather オペレーションによるトレーニング速度の向上という利点を活用できます。
シャーディングデータ並列処理について深く掘り下げ、その設定方法や、シャーディングデータ並列処理とテンソル並列処理や FP16 トレーニングなどの他の手法を組み合わせて使用する方法については、シャーディングデータ並列処理 を参照してください。
パイプライン並列処理 (PyTorch と TensorFlow で利用可能)
パイプライン並列処理は、レイヤーのセットまたはオペレーションをデバイスのセット全体に分割し、各オペレーションはそのまま残します。モデルパーティションの数 (pipeline_parallel_degree) の値を指定する場合、GPU の総数 (processes_per_host) はモデルパーティションの数で割り切れる必要があります。これを正しく設定するには、pipeline_parallel_degree および processes_per_host のパラメータに正しい値を指定する必要があります。簡単な計算は以下のようになります。
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
指定した 2 つの入力パラメータを指定すると、ライブラリがモデルレプリカ (別名 data_parallel_degree) の数を計算します。
例えば、ml.p3.16xlarge のような 8 つの GPU ワーカーを持つ ML インスタンスを "pipeline_parallel_degree": 2 および "processes_per_host": 8 に設定して使用すると、ライブラリは GPU 全体に分散モデルと 4 方向データ並列処理を自動的にセットアップします。次の図は、モデルを 8 つの GPU に分散して 4 方向データ並列処理と双方向パイプライン並列処理を実現する方法を示しています。パイプライン並列グループとして定義し、PP_GROUP というラベルを付けた各モデルレプリカは、2 つの GPU に分割されます。モデルの各パーティションは 4 つの GPU に割り当てられ、4 つのパーティションレプリカはデータ並列グループに属し、DP_GROUP というラベルが付けられます。テンソル並列処理がなければ、パイプライン並列グループは基本的にモデル並列グループになります。
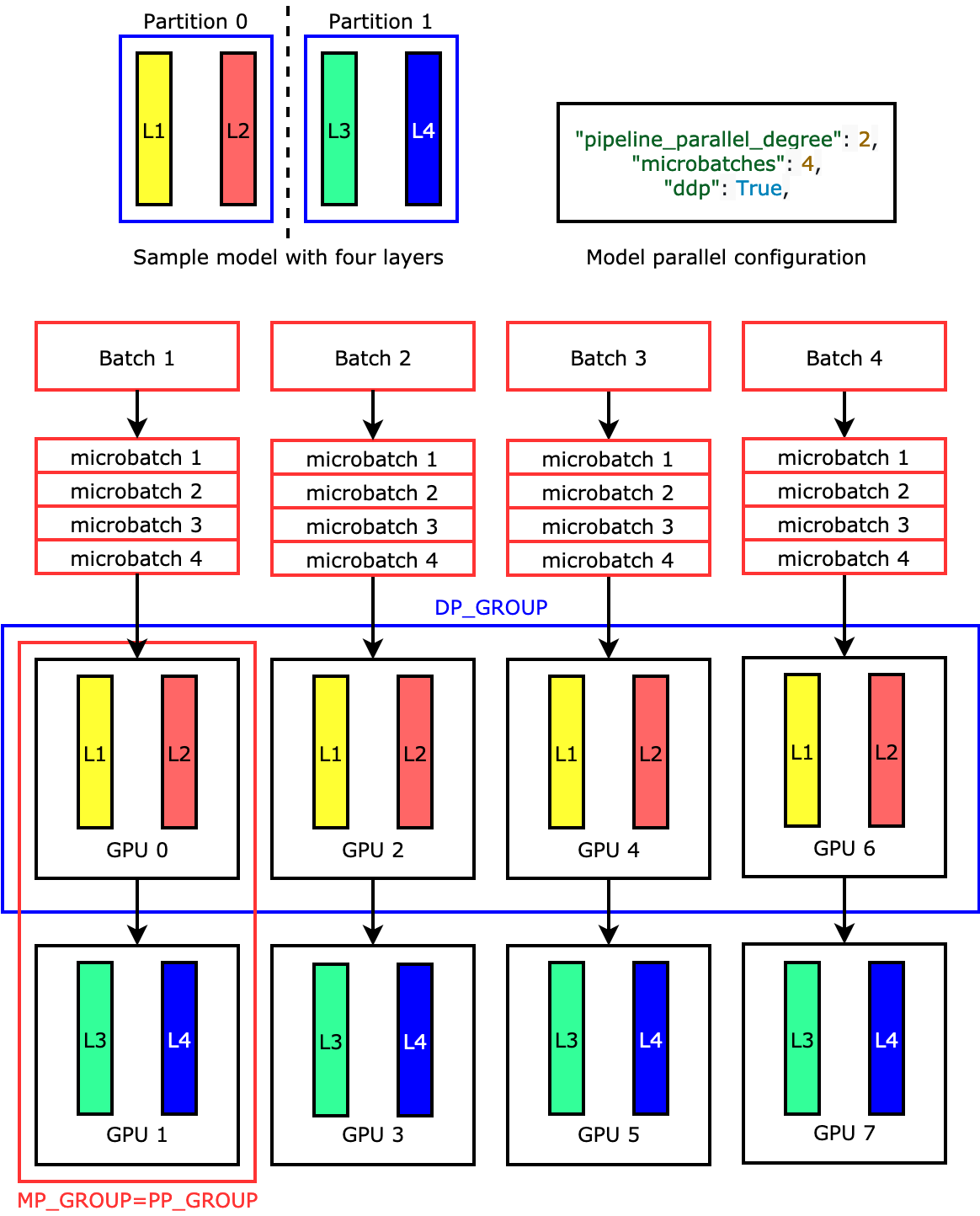
パイプラインの並列処理について詳しくは、「SageMaker モデル並列処理ライブラリの主要機能」を参照してください。
パイプライン並列処理によるモデルの実行を開始するには、「Run a SageMaker Distributed Training Job with the SageMaker Model Parallel Library」を参照してください。
Tensor 並列処理 (PyTorch で利用可能)
Tensor 並列処理は、個々のレイヤー (nn.Modules) をデバイス間で分割し、並列に実行します。次の図は、ライブラリがモデルを 4 つのレイヤーに分割して双方向のテンソル並列処理 ("tensor_parallel_degree": 2) を実現する方法の最も単純な例を示しています。各モデルレプリカのレイヤーは 2 分割され、2 つの GPU に分散されます。この例では、モデルの並列構成には "pipeline_parallel_degree": 1 と "ddp": True (バックグラウンドでは PyTorch DistributedDataParallel パッケージを使用) も含まれているため、データの並列度は 8 になります。このライブラリは、テンソル分散モデルのレプリカ間の通信を管理します。
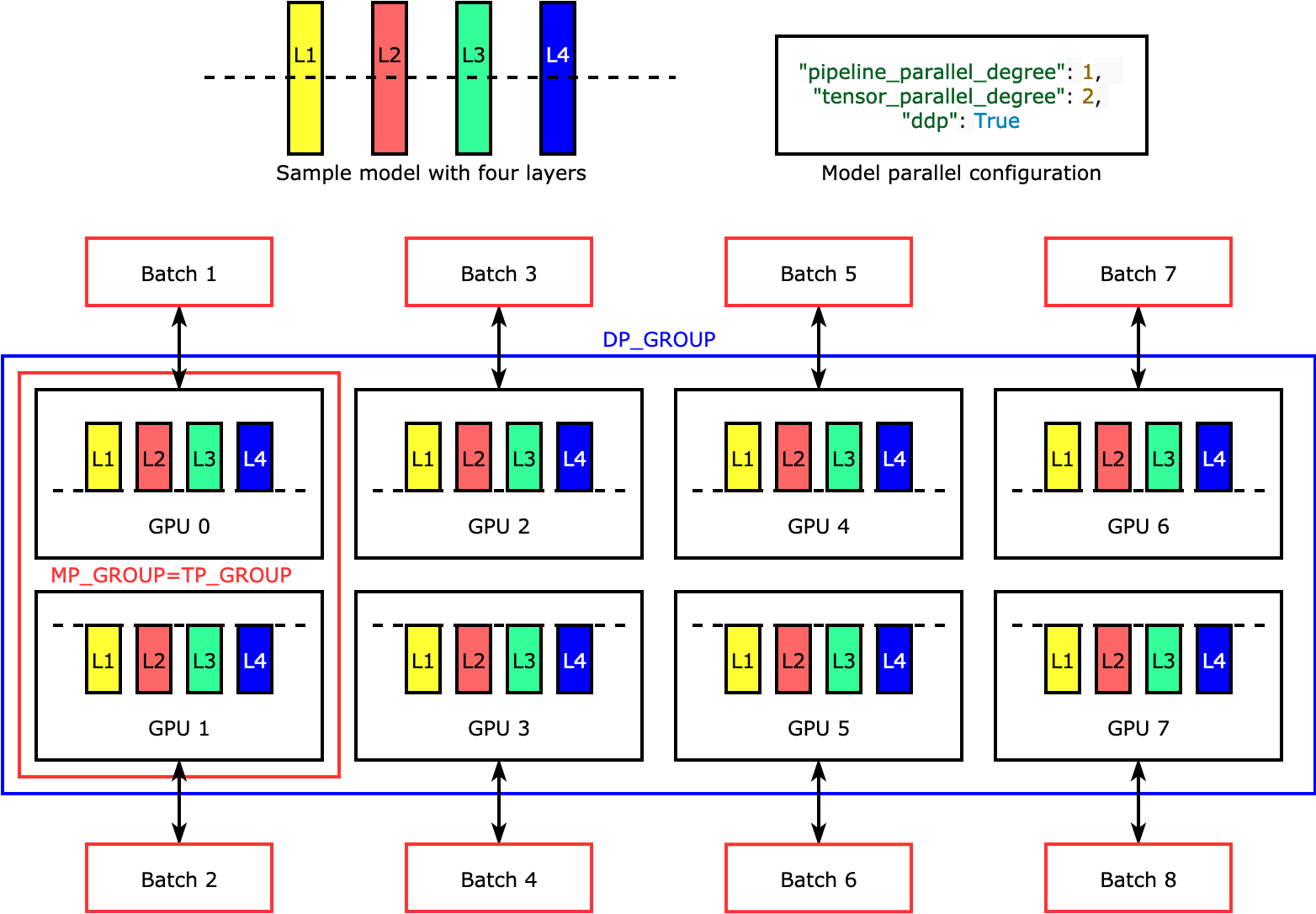
この機能の便利さは、特定のレイヤーまたはレイヤーのサブセットを選択してテンソル並列処理を適用できる点にあります。PyTorch のテンソル並列処理やその他のメモリ節約機能の詳細と、パイプラインとテンソルの並列処理の組み合わせを設定する方法については、「テンソル並列処理」を参照してください。
オプティマイザステートのシャーディング (PyTorch で利用可能)
ライブラリがオプティマイザステートシャーディングをどのように実行するのかを理解するために、4 つのレイヤーからなる単純なモデル例を考えてみましょう。ステートシャーディングを最適化するうえで重要なのは、オプティマイザの状態をすべての GPU に複製する必要がないということです。代わりに、オプティマイザの状態の単一のレプリカが、デバイス間の冗長性なくデータ並列ランクにわたってシャーディングされます。例えば、GPU 0 はレイヤー 1 のオプティマイザ状態を保持し、次の GPU 1 は L2 のオプティマイザ状態を保持する、という具合です。次のアニメーション図は、オプティマイザ状態のシャーディング手法による後方伝播を示しています。後方伝播の最後には、optimizer apply (OA) オペレーションでオプティマイザの状態を更新し、all-gather (AG) オペレーションで次の反復に備えてモデルパラメータを更新するための計算時間とネットワーク時間が残ります。最も重要なのは、この reduce 処理が GPU 0 での計算と重複する可能性があるため、メモリ効率が高まり、後方伝播が速くなることです。現在の実装では、AG と OA のオペレーションは compute と重複しません。その結果、AG オペレーション中の計算時間が長くなる可能性があるため、トレードオフが発生する可能性があります。
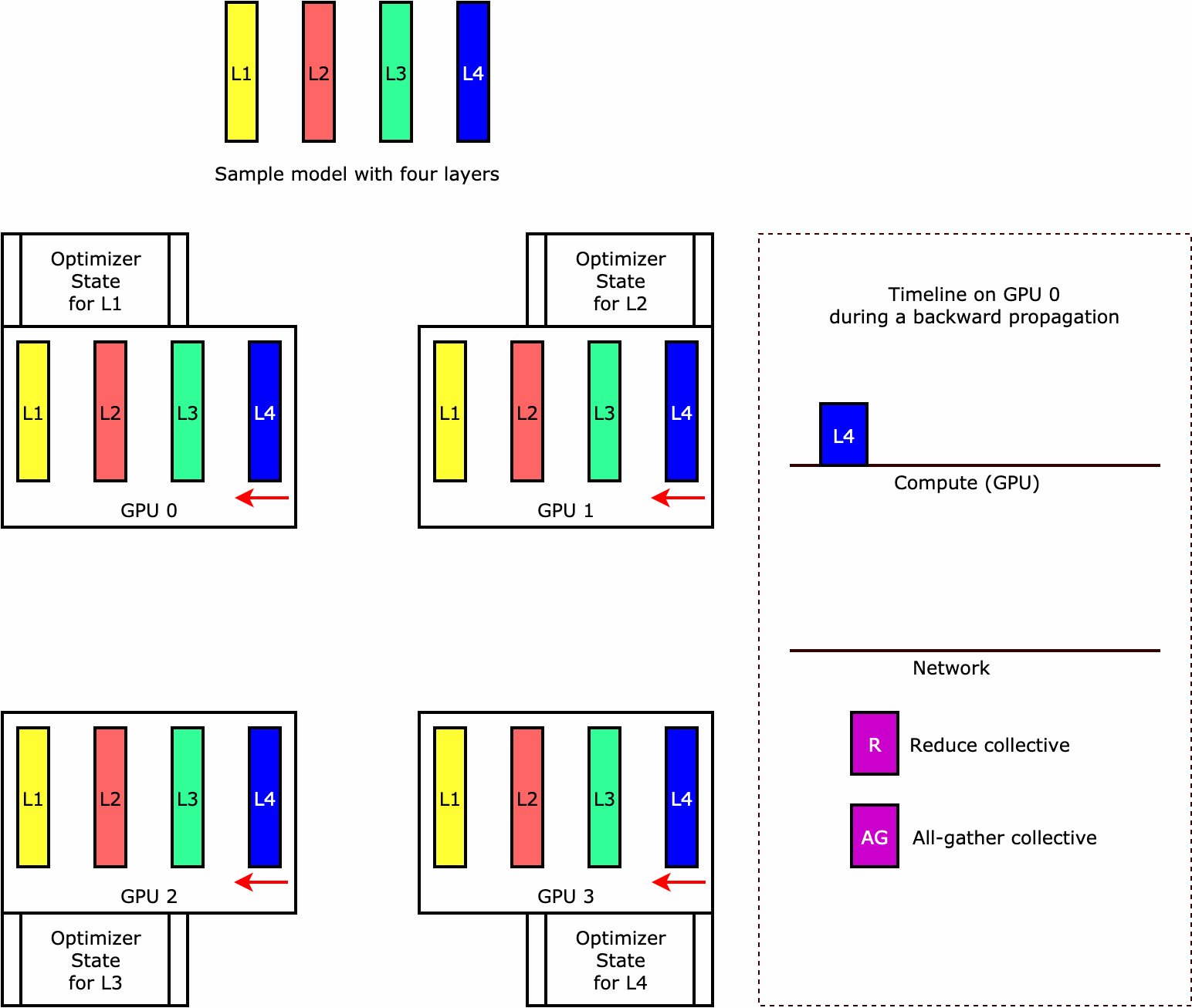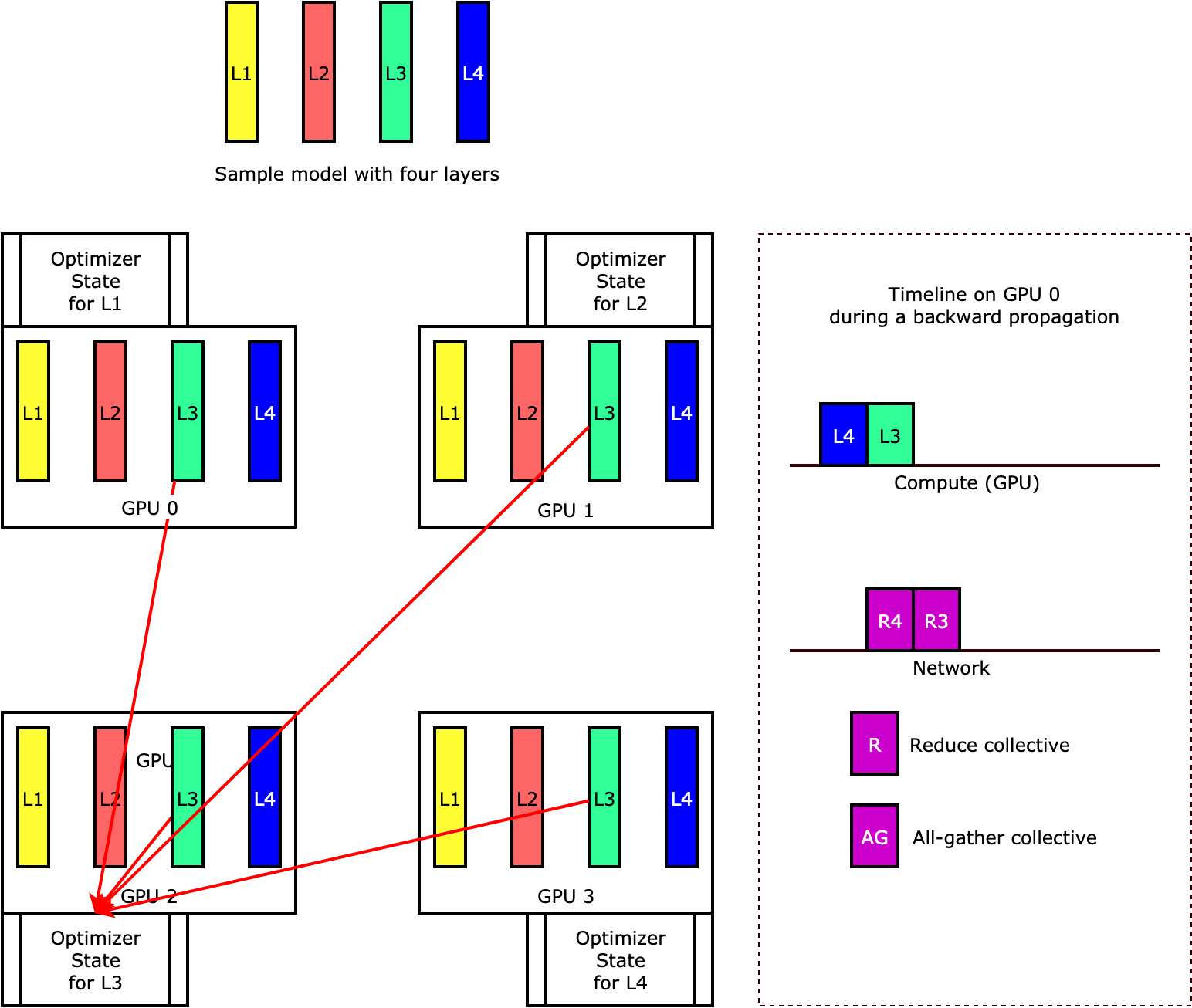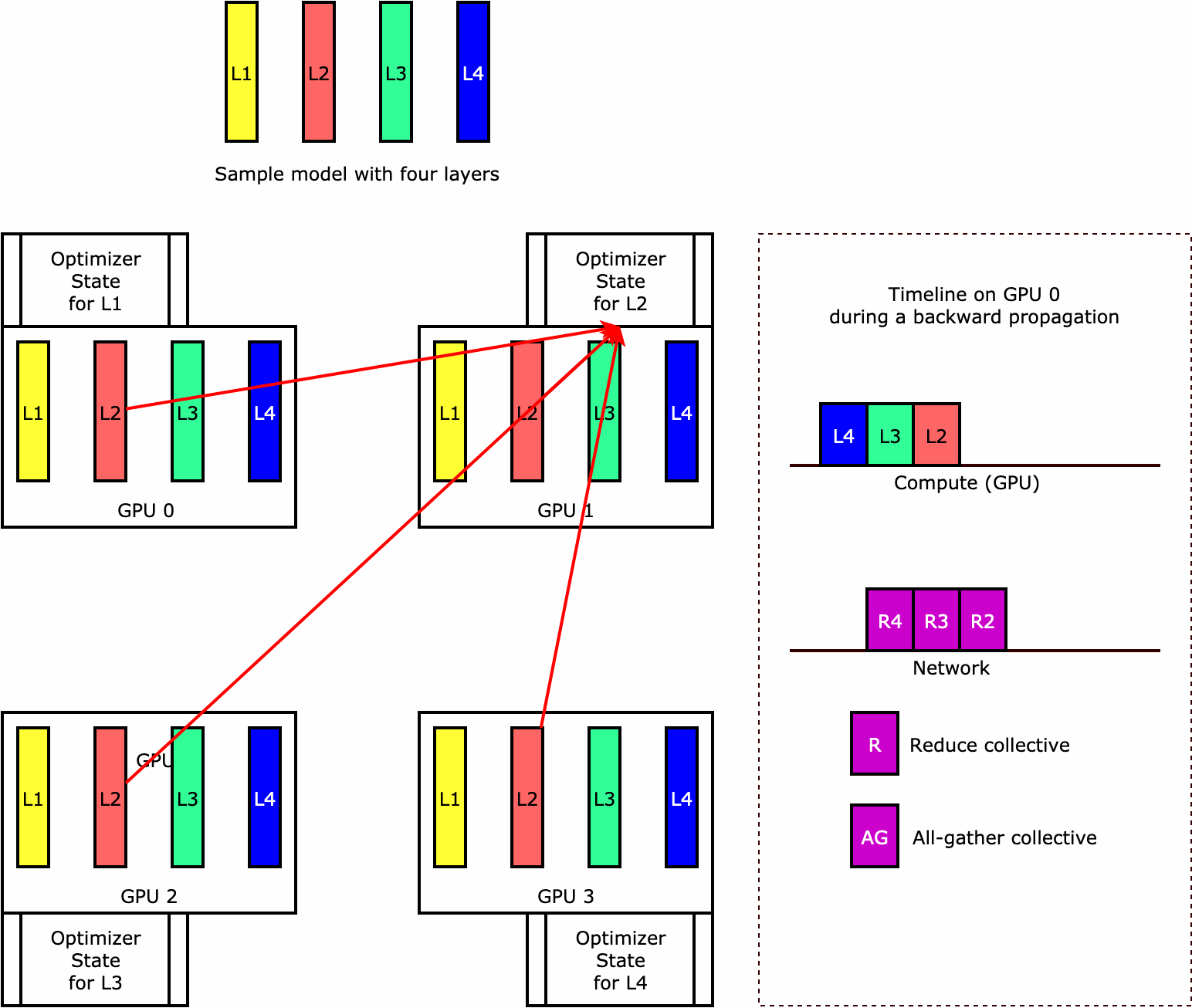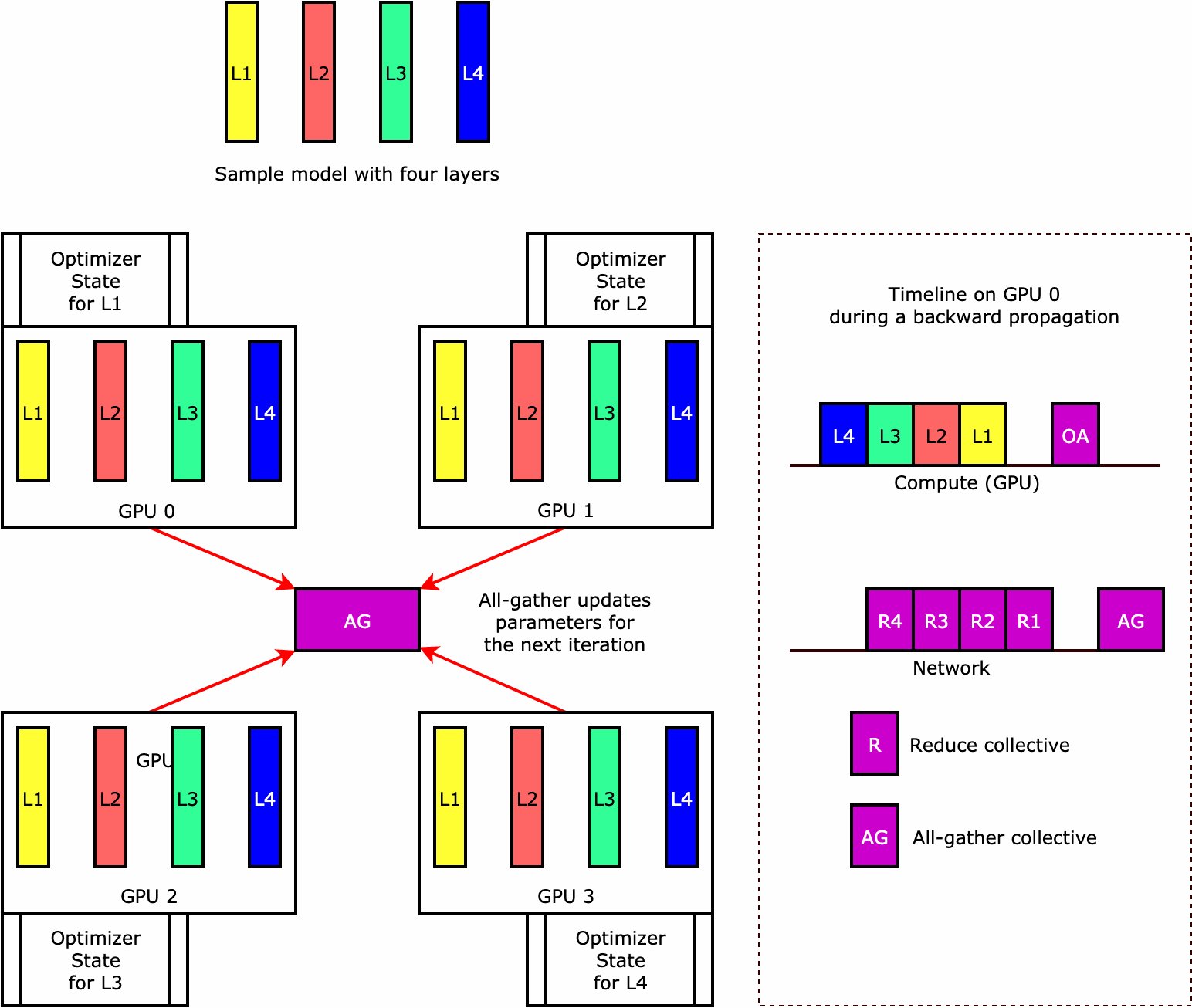
この機能の使用方法の詳細については、「Optimizer State Sharding」を参照してください。
アクティベーションオフロードとチェックポイント (PyTorch で利用可能)
GPU メモリを節約するため、ライブラリはアクティベーションチェックポイントをサポートしています。これにより、フォワードパス中にユーザー指定モジュールの内部アクティベーションが GPU メモリに保存されるのを防ぐことができます。ライブラリはバックワードパス中にこれらのアクティベーションを再計算します。さらに、アクティベーションオフロード機能は、保存されているアクティベーションを CPU メモリにオフロードし、バックワードパス中に GPU にフェッチバックすることで、アクティベーションメモリのフットプリントをさらに削減します。これらの機能の使用方法について詳しくは、「Activation Checkpointing」と「Activation Offloading」を参照してください。
モデルに適した手法の選択
適切な手法と構成の選択について詳しくは、「SageMaker Distributed Model Parallel Best Practices」と「Configuration Tips and Pitfalls」を参照してください。
