翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon SageMaker Serverless Inference を使用してモデルをデプロイする
Amazon SageMaker Serverless Inference は、基盤となるインフラストラクチャを設定または管理せずに、ML モデルをデプロイおよびスケールする専用の推論オプションです。オンデマンドのサーバーレス推論は、トラフィックの増加の間にアイドル期間があり、コールドスタートを許容できるワークロードに最適です。サーバーレスエンドポイントは、コンピューティングリソースを自動的に起動し、トラフィックに応じてスケールインおよびスケールアウトできるため、インスタンスタイプを選択したり、スケーリングポリシーを管理したりする必要がなくなります。これにより、サーバーを選択し管理する画一的な負荷の大きい作業から解放されます。サーバーレス推論は AWS Lambda と統合され、高可用性、組み込みの耐障害性、オートスケーリングを提供します。従量課金モデルでは、頻度の低いまたは予測不可能なトラフィックパターンがある場合、サーバーレス推論は費用対効果の高いオプションです。リクエストがない間、サーバーレス推論はエンドポイントを 0 にスケールダウンし、コストを最小限に抑えます。オンデマンドサーバーレス推論の料金の詳細については、「Amazon SageMaker の料金
オプションで、サーバーレス推論でプロビジョニングされた同時実行を利用することもできます。プロビジョニングされた同時実行を使用したサーバーレス推論は、トラフィックの急増が予測できる場合に費用対効果の高いオプションです。プロビジョニングされた同時実行を使用すると、エンドポイントをウォーム状態に保つことで、予測可能なパフォーマンスと高いスケーラビリティを備えたサーバーレスエンドポイントにモデルをデプロイできます。SageMaker AI は、割り当てるプロビジョニングされた同時実行数に対して、コンピューティングリソースが初期化され、ミリ秒以内に応答する準備ができていることを保証します。プロビジョニングされた同時実行を使用したサーバーレス推論では、推論リクエストの処理に使用されたコンピューティング性能 (ミリ秒単位で課金)、および処理されたデータ量に対して料金を支払います。また、設定されているメモリ、プロビジョニングされた期間、および有効になっている同時実行数に基づいて、プロビジョニングされた同時実行の使用量に対しても料金が発生します。プロビジョニングされた同時実行を使用したサーバーレス推論の料金の詳細については、「Amazon SageMaker の料金
サーバーレス推論を MLOps パイプラインと統合して ML ワークフローを効率化できます。また、サーバーレスエンドポイントを使用してモデルレジストリに登録されたモデルをホストできます。
サーバーレス推論は、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (北カリフォルニア)、米国西部 (オレゴン)、アフリカ (ケープタウン)、アジアパシフィック (香港)、アジアパシフィック (ムンバイ)、アジアパシフィック (東京)、アジアパシフィック (ソウル)、アジアパシフィック (大阪)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、カナダ (中部)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (ロンドン)、欧州 (パリ)、欧州 (ストックホルム)、欧州 (ミラノ)、中東 (バーレーン)、南米 (サンパウロ) の 21 AWS リージョンで一般利用可能です。Amazon SageMaker AI のリージョンでの可用性の詳細については、AWS 「リージョンサービスリスト
仕組み
次の図表は、オンデマンドのサーバーレス推論のワークフローと、サーバーレスエンドポイントを使用する利点を示しています。
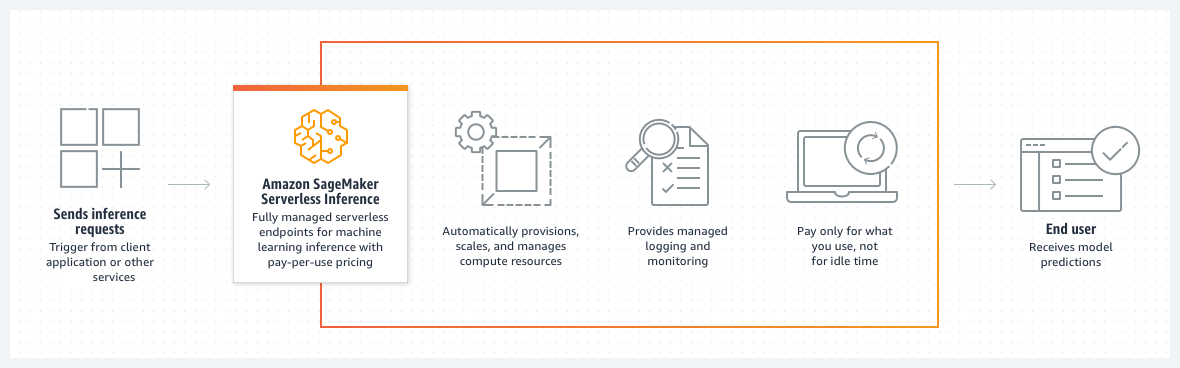
オンデマンドサーバーレスエンドポイントを作成すると、SageMaker AI はコンピューティングリソースをプロビジョニングおよび管理します。次に、エンドポイントに推論リクエストを行い、レスポンスでモデル予測を受け取ることができます。SageMaker AI は、リクエストトラフィックを処理するために必要に応じてコンピューティングリソースをスケールアップまたはスケールダウンし、使用した分に対してのみ料金が発生します。
プロビジョニングされた同時実行については、サーバーレス推論はアプリケーションの自動スケーリングとも統合されるため、ターゲットメトリクスまたはスケジュールに基づいてプロビジョニングされた同時実行を管理できます。詳細については、「サーバーレスエンドポイントのプロビジョニングされた同時実行の自動スケール」を参照してください。
次のセクションでは、サーバーレス推論とその仕組みに関する追加の詳細について説明します。
コンテナのサポート
エンドポイントコンテナでは、SageMaker AI が提供するコンテナを選択するか、独自のコンテナを持ち込むことができます。SageMaker AI は、Apache MXNet、TensorFlow、PyTorch、Chainer など、最も一般的な機械学習フレームワークの組み込みアルゴリズムと構築済みの Docker イメージ用のコンテナを提供します。利用可能な SageMaker イメージのリストについては、「使用可能なDeep Learning Containers イメージ
使用できるコンテナイメージの最大サイズは 10 GB です。サーバーレスエンドポイントの場合、コンテナ内にワーカーを 1 つだけ作成し、モデルのコピーを 1 つだけロードすることをお勧めします。これはリアルタイムエンドポイントとは異なります。一部の SageMaker AI コンテナは、推論リクエストを処理して各ワーカーにモデルをロードするために、各 vCPU のワーカーを作成する場合があります。
リアルタイムエンドポイント用のコンテナが既にある場合は、サーバーレスエンドポイントに同じコンテナを使用できますが、一部の機能は除外されます。サーバーレス推論でサポートされていないコンテナ機能の詳細については、「機能の除外」を参照してください。同じコンテナを使用することを選択した場合、SageMaker AI は、イメージを使用するすべてのエンドポイントを削除するまで、コンテナイメージのコピーをエスクロー (保持) します。SageMaker AI は、コピーした保管中のイメージを SageMaker AI 所有の AWS KMS キーで暗号化します。
メモリサイズ
サーバーレスエンドポイントの最小 RAM サイズは 1024 MB (1 GB) で、選択できる最大 RAM サイズは 6144 MB (6 GB) です。選択できるメモリサイズは、1024 MB、2048 MB、3072 MB、4096 MB、5120 MB、6144 MBです。サーバーレス推論は、選択したメモリに比例してコンピューティングリソースを自動的に割り当てます。より大きなメモリサイズを選択すると、コンテナはより多くの vCPUs にアクセスできます。モデルサイズに応じて、エンドポイントのメモリサイズを選択します。一般に、メモリサイズは少なくともモデルサイズと同じ大きさである必要があります。レイテンシー SLA に基づいてモデルに適したメモリを選択するために、ベンチマークが必要になる場合があります。ベンチマークのステップバイステップガイドについては、「Introducing the Amazon SageMaker Serverless Inference Benchmarking Toolkit
選択したメモリサイズに関係なく、サーバーレスエンドポイントには 5 GB の利用可能なエフェメラルディスクストレージがあります。ストレージを操作するときのコンテナ許可の問題については、「トラブルシューティング」を参照してください。
同時呼び出し
オンデマンドサーバーレス推論は、エンドポイントの容量に関する事前定義されたスケーリングポリシーとクォータを管理します。サーバーレスエンドポイントには、同時に処理できる同時呼び出しの数に対するクォータがあります。最初のリクエストの処理が完了する前にエンドポイントが呼び出されると、2 番目のリクエストを同時に処理します。
アカウント内のすべてのサーバーレスエンドポイント間で共有できる同時実行数の合計は、次のようにリージョンによって異なります。
-
アカウントにおけるリージョンごとにすべてのサーバーレスエンドポイント間で共有できる同時実行数の合計が 1000 になるリージョン: 米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、欧州 (フランクフルト)、欧州 (アイルランド)
-
アカウントにおけるリージョンごとの合計同時実行数が 500 になるリージョン: 米国西部 (北カリフォルニア)、アフリカ (ケープタウン)、アジアパシフィック (香港)、アジアパシフィック (ムンバイ)、アジアパシフィック (大阪)、アジアパシフィック (ソウル)、カナダ (中部)、欧州 (ロンドン)、欧州 (ミラノ)、欧州 (パリ)、欧州 (ストックホルム)、中東 (バーレーン)、南米 (サンパウロ)
1 つのエンドポイントの最大同時実行数は最大 200 に設定でき、リージョンでホストできるサーバーレスエンドポイントの合計数は 50 です。個々のエンドポイントの最大同時実行数は、そのエンドポイントがアカウントで許可されているすべての呼び出しを取得することを防ぎ、最大値を超えるエンドポイント呼び出しをスロットリングします。
注記
サーバーレスエンドポイントに割り当てるプロビジョニングされた同時実行数は、常にそのエンドポイントに割り当てた最大同時実行数以下でなければなりません。
エンドポイントの最大同時実行数を設定する方法については、「エンドポイント設定を作成する」を参照してください。クォータと制限の詳細については、のAmazon SageMaker AI エンドポイントとクォータ」を参照してくださいAWS 全般のリファレンス。サービスの制限の引き上げをリクエストするには、「AWS サポート
コールドスタートの最小化
オンデマンドサーバーレス推論エンドポイントがしばらくトラフィックを受信せず、エンドポイントが突然新しいリクエストを受信した場合、エンドポイントがコンピューティングリソースをスピンアップしてリクエストを処理するまでに時間がかかることがあります。これは、コールドスタートと呼ばれます。サーバーレスエンドポイントはオンデマンドでコンピューティングリソースをプロビジョニングするため、エンドポイントでコールドスタートが発生する可能性があります。コールドスタートは、同時リクエストが現在の同時リクエストの使用量を超えた場合にも発生する可能性があります。コールドスタート時間は、モデルのサイズ、モデルのダウンロードにかかる時間、コンテナの起動時間によって異なります。
コールドスタート時間の長さをモニタリングするには、Amazon CloudWatch メトリクス OverheadLatency を使用して、サーバーレスエンドポイントをモニタリングします。このメトリクスは、エンドポイントの新しいコンピューティングリソースの起動にかかる時間を追跡します。サーバーレスエンドポイントでの CloudWatch メトリクスの使用方法の詳細については、「サーバーレスエンドポイントからメトリクスを追跡するためのアラームとログ」を参照してください。
プロビジョニングされた同時実行を使用することにより、コールドスタートを最小限に抑えることができます。SageMaker AI は、割り当てたプロビジョニングされた同時実行数に対して、エンドポイントをウォームに保ち、ミリ秒単位で応答できるようにします。
機能の除外
SageMaker AI リアルタイム推論で現在利用可能な機能の一部は、GPUs、 AWS 市場モデルパッケージ、プライベート Docker レジストリ、マルチモデルエンドポイント、VPC 設定、ネットワーク分離、データキャプチャ、複数の本番稼働用バリアント、Model Monitor、推論パイプラインなど、サーバーレス推論ではサポートされていません。
インスタンスベースのリアルタイムエンドポイントをサーバーレスエンドポイントに変換することはできません。リアルタイムエンドポイントをサーバーレスに更新しようとすると、ValidationErrorメッセージが表示されます。サーバーレスエンドポイントをリアルタイムに変換することはできますが、更新を行うと、サーバーレスにロールバックできません。
入門
SageMaker AI コンソール、 AWS SDKs、Amazon SageMaker Python SDK
注記
プロビジョニングされた同時実行を使用したサーバーレス推論のアプリーエションの自動スケーリングは、現在 AWS CloudFormationではサポートされていません。
ノートブックとブログの例
エンドツーエンドのサーバーレスエンドポイントワークフローを示す Jupyter Notebook の例については、「Serverless Inference example notebooks
