翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Step Functions とは
ステートの管理とデータの変換
変数を使用したステート間のデータ受け渡しと JSONata を使用したデータ変換について説明します。
を使用するとAWS Step Functions、 とも呼ばれるワークフローを作成してステートマシン、分散アプリケーションの構築、プロセスの自動化、マイクロサービスのオーケストレーション、データと機械学習パイプラインの作成を行うことができます。
Step Functions はステートマシンとタスクに基づいています。Step Functions では、ステートマシンはワークフローと呼ばれます。これは、一連のイベント駆動型ステップです。ワークフローの各ステップはステートと呼ばれます。たとえば、タスク状態は、別の AWS のサービスや API の呼び出しなど、別のAWSサービスが実行する作業単位を表します。タスクを行うワークフローを実行するインスタンスは、Step Functions では実行と呼ばれます。
ステートマシンタスクでの作業は、Step Functions の外部に存在するワーカーである アクティビティ を使用して実行することもできます。
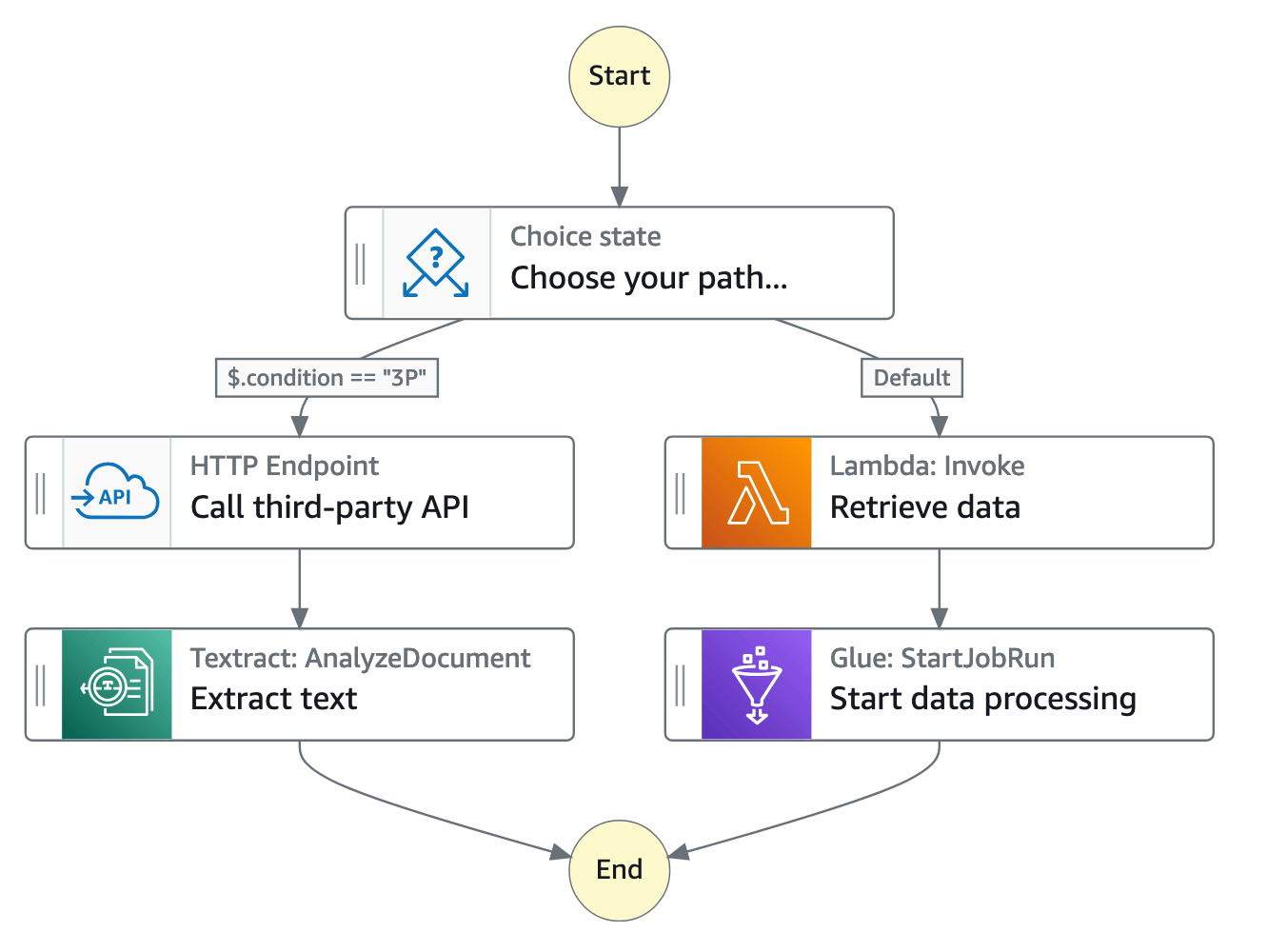
Step Functions のコンソールでは、アプリケーションのワークフローを視覚化、編集、デバッグできます。ワークフロー内の各ステップの状態を調べて、アプリケーションが期待どおりに実行されていることを確認します。
ユースケースに応じて、Step Functions で Lambda などの AWSサービスを呼び出してタスクを実行できます。Step Functions に抽出、変換AWS Glue、ロードワークフローの作成などのAWSサービスを制御させることができます。また、手動による介入が必要なアプリケーション用に実行時間が長い自動化されたワークフローを作成することもできます。
Step Functions が利用可能なAWSリージョンの完全なリストについては、AWS「リージョンテーブル
Step Functions を使用する方法について
まず、このガイドの「入門チュートリアル」から始めます。高度なトピックやユースケースについては、「Step Functions ワークショップ
Standard ワークフローと Express ワークフローのタイプ
Step Functions には 2 つのワークフロータイプがあります。
-
Standard ワークフローは、実行履歴と視覚的なデバッグを示すため、実行時間が長い監査可能なワークフローに最適です。
Standard ワークフローでは 1 度だけワークフローが実行され、最大 1 年間実行できます。つまり、標準ワークフローの各ステップは 1 回だけ実行されます。
-
Express ワークフローは、ストリーミングデータ処理や IoT のデータインジェストなど、イベントレートの高いワークロードに最適です。
Express ワークフローは、ワークフローを 1 度以上実行し、最大 5 分間実行できます。つまり、Express ワークフローの 1 つ以上のステップが複数回実行される可能性があり、ワークフロー内の各ステップは少なくとも 1 回実行されます。
| Standard ワークフロー | Express ワークフロー |
|---|---|
| 毎秒 2,000 の実行レート | 毎秒 100,000 の実行レート |
| 毎秒 4,000 のステート移行レート | ほぼ無制限のステート移行レート |
| ステート移行別の価格設定 | 実行回数および実行期間別の価格設定 |
| 実行履歴と視覚的なデバッグの表示 | [ログレベル] に基づいて、実行履歴と視覚的なデバッグを表示 |
| Step Functions で実行履歴を確認 |
CloudWatch |
| すべてのサービスとの統合をサポート 一部のサービスとの最適化された統合をサポート。 |
すべてのサービスとの統合をサポート。 |
| すべてのサービスのリクエストレスポンスパターンをサポート 特定のサービスでジョブの実行やコールバックの待機パターンをサポート (詳細については、次のセクションを参照してください) |
すべてのサービスのリクエストレスポンスパターンをサポート |
Step Functions の料金とワークフロータイプの選択の詳細については、以下を参照してください。
他の のサービスとの統合
Step Functions は複数の AWSサービスと統合されます。他の AWSサービスを呼び出すには、次の 2 つの統合タイプを使用できます。
Step Functions と他のサービスを組み合わせるには、次の 3 つのサービス統合パターンを使用します。
-
サービスを呼び出し、Step Functions が HTTP レスポンスを取得した直後に次のステップに進むことができるようにします。
-
サービスを呼び出し、ジョブが完了するまで Step Functions が待機するようにします。
-
タスクトークンを使用してコールバックを待機 (.waitForTaskToken)
タスクトークンでサービスを呼び出し、タスクトークンがコールバックとともに返されるまで Step Functions を待機させます。
Standard ワークフローと Express ワークフローは、同じ統合をサポートしますが、同じ統合パターンはサポートしていません。
-
Standard ワークフローは、リクエストのレスポンスの統合をサポートします。特定のサービスでは、ジョブの実行 (.sync) またはコールバックの待機 (.waitForTaskToken)、および場合によってはその両方をサポートしています。詳細については、次の最適化された統合テーブルを参照してください。
-
Express ワークフローは、リクエストのレスポンスの統合のみをサポートします。
2 つのタイプ間の決定については、「Step Functions でワークフロータイプを選択する」を参照してください。
AWSStep Functions での SDK 統合
| 統合された サービス | レスポンスのリクエスト | ジョブの実行 - .sync | コールバックの待機 - .waitForTaskToken |
|---|---|---|---|
| 200 を超えるサービス | Standard と Express | サポートされません | Standard |
Step Functions での統合最適化
| 統合された サービス | レスポンスのリクエスト | ジョブの実行 - .sync | コールバックの待機 - .waitForTaskToken |
|---|---|---|---|
| Amazon API Gateway | Standard と Express | サポートされません | Standard |
| Amazon Athena | Standard と Express | Standard | サポートされません |
| AWS Batch | Standard と Express | Standard | サポートされません |
| Amazon Bedrock | Standard と Express | Standard | Standard |
| AWS CodeBuild | Standard と Express | Standard | サポートされません |
| Amazon DynamoDB | Standard と Express | サポートされません | サポートされません |
| Amazon ECS/Fargate | Standard と Express | Standard | Standard |
| Amazon EKS | Standard と Express | Standard | Standard |
| Amazon EMR | Standard と Express | Standard | サポートされません |
| Amazon EMR on EKS | Standard と Express | Standard | サポートされません |
| Amazon EMR Serverless | Standard と Express | Standard | サポートされません |
| Amazon EventBridge | Standard と Express | サポートされません | Standard |
| AWS Glue | Standard と Express | Standard | サポートされません |
| AWS Glue DataBrew | Standard と Express | Standard | サポートされません |
| AWS Lambda | Standard と Express | サポートされません | Standard |
| AWS Elemental MediaConvert | Standard と Express | Standard | サポートされません |
| Amazon SageMaker AI | Standard と Express | Standard | サポートされません |
| Amazon SNS | Standard と Express | サポートされません | Standard |
| Amazon SQS | Standard と Express | サポートされません | Standard |
| AWS Step Functions | Standard と Express | Standard | Standard |
ワークフローのユースケースの例
Step Functions はアプリケーションのコンポーネントとロジックを管理するため、コードの書き込みを減らし、アプリケーションの迅速な構築と更新に集中することができます。次の図は、Step Functions ワークフローの 6 つのユースケースを示しています。

-
タスクのオーケストレーション - 一連のタスクまたはステップを特定の順序でオーケストレーションするワークフローを作成できます。例えば、タスク A は、タスク B の別の Lambda 関数の入力を提供する Lambda 関数である場合があります。ワークフローの最後のステップで、最終結果が得られます。
-
データに基づくタスクの選択 -
Choice状態を使って、状態の入力に基づいた判断を Step Functions にさせることができます。例えば、顧客がクレジット制限額の引き上げをリクエストするとします。リクエストが事前承認した顧客のクレジット上限を超える場合は、Step Functions から顧客のリクエストをマネージャーに送信してサインオフを求めることができます。リクエストが事前承認した顧客のクレジット上限を下回っている場合は、Step Functions でリクエストを自動的に承認することができます。 -
エラー処理 (
Retry/Catch) - 失敗したタスクを再試行したり、失敗したタスクをキャッチして代替ステップを自動的に実行したりできます。例えば、顧客がユーザー名をリクエストすると、検証サービスへの最初の呼び出しが失敗する可能性があるため、ワークフローはリクエストを再試行することがあります。2 番目のリクエストが成功すると、ワークフローを続行できます。
または、顧客が無効または使用できないユーザー名をリクエストした場合、
Catchステートメントによって代替ユーザー名を提案する Step Functions ワークフローステップが発生する可能性があります。RetryとCatchの例については、「Step Functions ワークフローでのエラー処理」を参照してください。 -
ヒューマンインザループ - Step Functions は、ワークフローに人間による承認ステップを含めることができます。例えば、銀行の顧客が友人に資金を送信しようとしているとします。コールバックとタスクトークンを使用すると、顧客の友人が転送を確認するまで Step Functions を待機させることができ、その後 Step Functions はワークフローを続行して、転送が完了したことを銀行顧客に通知します。
例については、Amazon SQS、Amazon SNS、Lambda を使ってコールバックパターンの例を作成するを参照してください。
-
データを並列ステップで処理 - Step Functions は、
Parallel状態を使用して入力データを並列ステップで処理できます。例えば、顧客が動画ファイルを複数の表示解像度に変換する必要がある場合、ビューワーは複数のデバイスで動画を視聴できます。ワークフローでは、元の動画ファイルを複数の Lambda 関数に送信したり、最適化されたAWS Elemental MediaConvert統合を使用して動画を複数のディスプレイ解像度に同時に処理したりできます。 -
データ要素を動的に処理 - Step Functions は、
Map状態を使用して、データセット内の各項目に対して一連のワークフローステップを実行できます。反復は並列で実行されるため、データセットを迅速に処理できます。例えば、顧客が 30 個の商品を注文する場合、システムは同じワークフローを適用して各商品を配送用に準備する必要があります。すべての商品が収集され、配送用にパッケージ化されたら、次のステップとして、追跡情報が記載された確認 E メールをお客様にすばやく送信できます。スターターテンプレートの例については、「Map を使用してデータを処理する」を参照してください。
