Aurora PostgreSQL과 함께 Amazon Aurora 기계 학습 사용
Amazon Aurora 기계 학습을 Aurora PostgreSQL DB 클러스터와 함께 사용하면 필요에 따라 Amazon Comprehend, Amazon SageMaker AI 또는 Amazon Bedrock을 사용할 수 있습니다. 이러한 서비스는 각각 구체적인 기계 학습 사용 사례를 지원합니다.
Aurora 기계 학습은 특정 AWS 리전 및 Aurora PostgreSQL의 특정 버전에서만 지원됩니다. Aurora 기계 학습을 설정하기 전에 사용 중인 리전에서 Aurora PostgreSQL 버전의 사용 가능 여부를 확인하세요. 세부 정보는 Aurora PostgreSQL을 사용하는 Aurora 기계 학습을 참조하세요.
주제
Aurora PostgreSQL과 함께 Aurora 기계 학습을 사용할 때 요구 사항
AWS 기계 학습 서비스는 자체 프로덕션 환경에서 설정되고 실행되는 관리형 서비스입니다. Aurora 기계 학습은 Amazon Comprehend, SageMaker AI, Amazon Bedrock과의 통합을 지원합니다. Aurora 기계 학습을 사용하도록 Aurora PostgreSQL DB 클러스터를 설정하기 전에 다음 요구 사항 및 사전 조건을 이해해야 합니다.
Amazon Comprehend, SageMaker AI, Amazon Bedrock 서비스는 Aurora PostgreSQL DB 클러스터와 동일한 AWS 리전에서 실행되어야 합니다. 다른 리전의 Aurora PostgreSQL DB 클러스터에서는 Amazon Comprehend, Amazon SageMaker AI 또는 Amazon Bedrock 서비스를 사용할 수 없습니다.
Aurora PostgreSQL DB 클러스터가 Amazon Comprehend 및 SageMaker AI 서비스와 다른 Amazon VPC 서비스 기반 Virtual Public Cloud(VPC)에 있는 경우 VPC의 보안 그룹은 대상 Aurora 기계 학습 서비스에 대한 아웃바운드 연결을 허용해야 합니다. 자세한 내용은 Amazon Aurora에서 다른 AWS 서비스로의 네트워크 통신 활성화 단원을 참조하십시오.
SageMaker AI의 경우 추론에 사용할 기계 학습 구성 요소를 설정하고 사용할 준비가 되어 있어야 합니다. Aurora PostgreSQL DB 클러스터에 대한 구성 프로세스 동안 SageMaker AI 엔드포인트의 Amazon 리소스 이름(ARN)을 사용할 수 있어야 합니다. 팀의 데이터 과학자는 SageMaker AI와 협력하여 모델을 준비하고 그 외의 작업을 처리하는 데 가장 잘 대처할 수 있을 것입니다. Amazon SageMaker AI를 시작하려면 Get Started with Amazon SageMaker AI를 참조하세요. 추론 및 엔드포인트에 대한 자세한 내용은 Real-time inference(실시간 추론)를 참조하세요.
-
Amazon Bedrock의 경우 Aurora PostgreSQL DB 클러스터 구성 과정에서 추론에 사용할 수 있는 Bedrock 모델의 모델 ID가 있어야 합니다. 팀의 데이터 과학자가 Bedrock을 사용하여 활용할 모델을 결정하고, 필요한 경우 미세 조정하고, 그 외의 작업을 처리하는 업무를 가장 잘 수행할 수 있습니다. Amazon Bedrock을 시작하려면 Bedrock을 설정하는 방법을 참조하세요.
-
Amazon Bedrock 사용자가 모델을 사용하려면 우선 모델에 대한 액세스 권한을 요청해야 합니다. 텍스트, 채팅, 이미지 생성을 위한 추가 모델을 추가하려면 Amazon Bedrock의 모델에 대한 액세스 권한을 요청해야 합니다. 자세한 내용은 모델 액세스를 참조하세요.
Aurora PostgreSQL을 사용하는 Aurora 기계 학습의 지원 기능 및 제한 사항
Aurora 기계 학습은 ContentType의 text/csv 값을 통해 쉼표로 구분된 값(CSV) 형식을 읽고 쓸 수 있는 모든 SageMaker AI 엔드포인트를 지원합니다. 현재 이 형식을 허용하는 내장 SageMaker AI 알고리즘은 다음과 같습니다.
Linear Learner
랜덤 컷 포레스트
XGBoost
이러한 알고리즘에 대해 자세히 알아보려면 Amazon SageMaker AI Developer Guide의 Choose an Algorithm을 참조하세요.
Aurora 기계 학습과 함께 Amazon Bedrock을 사용하는 경우 다음과 같은 제한 사항이 적용됩니다.
-
사용자 정의 함수(UDF)는 Amazon Bedrock과 상호 작용하는 기본 방법을 제공합니다. UDF에는 특정 요청 또는 응답 요구 사항이 없으므로, 모든 모델을 사용할 수 있습니다.
-
UDF를 사용하여 원하는 워크플로를 구축할 수 있습니다. 예를 들어, 기본 프리미티브(예:
pg_cron)를 결합하여 쿼리를 실행하고 데이터를 가져오며 추론을 생성하고 테이블에 기록하여 쿼리를 직접 제공할 수 있습니다. -
UDF는 일괄 또는 병렬 호출을 지원하지 않습니다.
-
Aurora 기계 학습 확장은 벡터 인터페이스를 지원하지 않습니다. 확장의 일환으로 모델 응답의 임베딩을
float8[]형식으로 출력하여 Aurora에 저장하는 기능을 사용할 수 있습니다.float8[]사용에 대한 자세한 내용은 Aurora PostgreSQL DB 클러스터와 함께 Amazon Bedrock 사용 섹션을 참조하세요.
Aurora 기계 학습을 사용하도록 Aurora PostgreSQL DB 클러스터 설정
Aurora 기계 학습이 Aurora PostgreSQL DB 클러스터와 함께 작동하려면 사용하려는 각 서비스에 대해 AWS Identity and Access Management(IAM) 역할을 생성해야 합니다. IAM 역할을 사용하면 Aurora PostgreSQL DB 클러스터가 클러스터를 대신하여 Aurora 기계 학습 서비스를 사용할 수 있습니다. 또한 Aurora 기계 학습 확장을 설치해야 합니다. 다음 주제에서는 이러한 Aurora 기계 학습 서비스 각각에 대한 설정 절차를 찾을 수 있습니다.
주제
Amazon Bedrock을 사용하도록 Aurora PostgreSQL 설정
다음 절차에서는 먼저 클러스터를 대신하여 Amazon Bedrock을 사용하도록 Aurora PostgreSQL에 권한을 부여하는 IAM 역할 및 정책을 생성합니다. 그런 다음 Aurora PostgreSQL DB 클러스터가 Amazon Bedrock과 함께 작동하기 위해 사용하는 IAM 역할에 정책을 연결합니다. 간소화를 위해 이 절차에서는 AWS Management Console을 사용하여 모든 작업을 완료합니다.
Amazon Bedrock을 사용하도록 Aurora PostgreSQL DB 클러스터를 설정하는 방법
AWS Management Console에 로그인하여 https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. AWS Identity and Access Management(IAM) 콘솔 메뉴에서 정책(액세스 관리 아래)을 선택합니다.
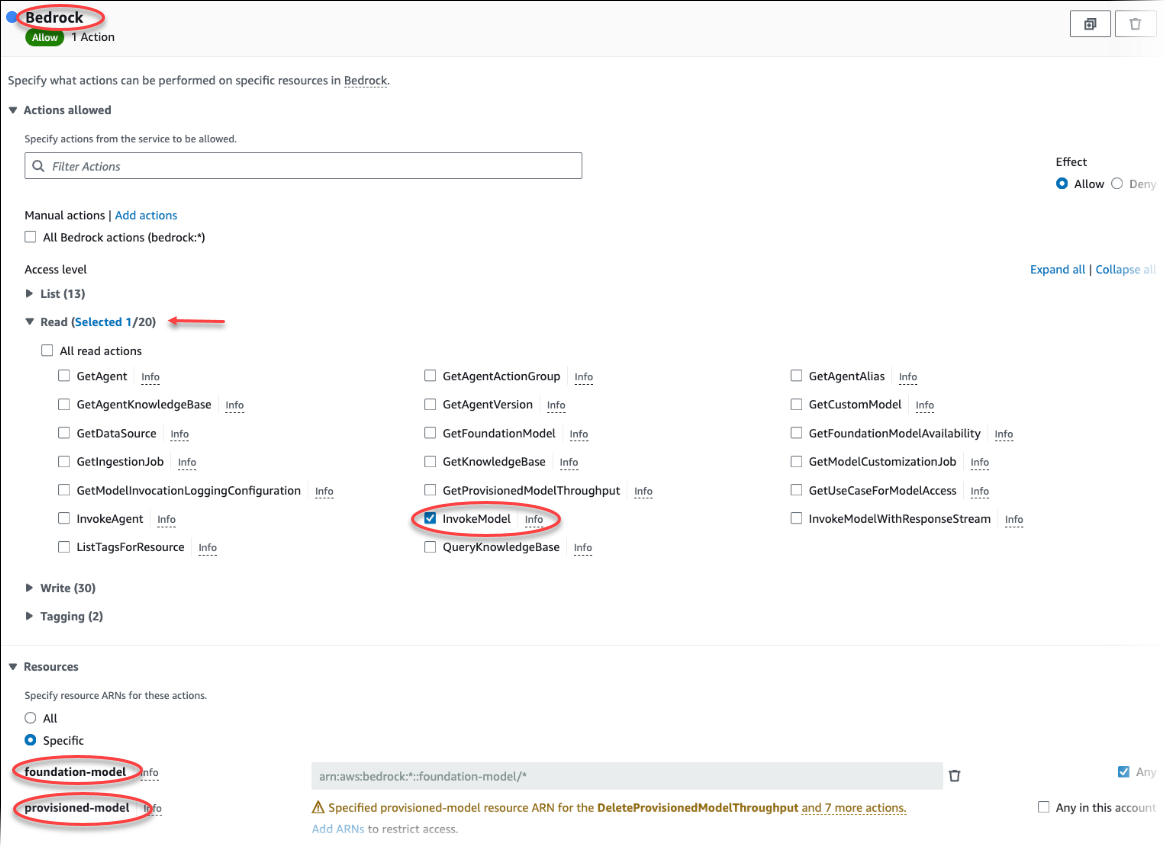
정책 생성을 선택합니다. 비주얼 에디터 페이지에서 서비스를 선택한 다음 서비스 선택 필드에 Bedrock을 입력합니다. 읽기 액세스 수준을 확장합니다. Amazon Bedrock 읽기 설정에서 InvokeModel을 선택합니다.
정책을 통해 읽기 액세스 권한을 부여하려는 파운데이션/프로비저닝 모델을 선택합니다.
다음: 태그를 선택하고 원하는 태그를 정의합니다(선택 사항). 다음: 검토를 선택합니다. 다음 이미지와 같이 정책의 이름과 설명을 입력합니다.
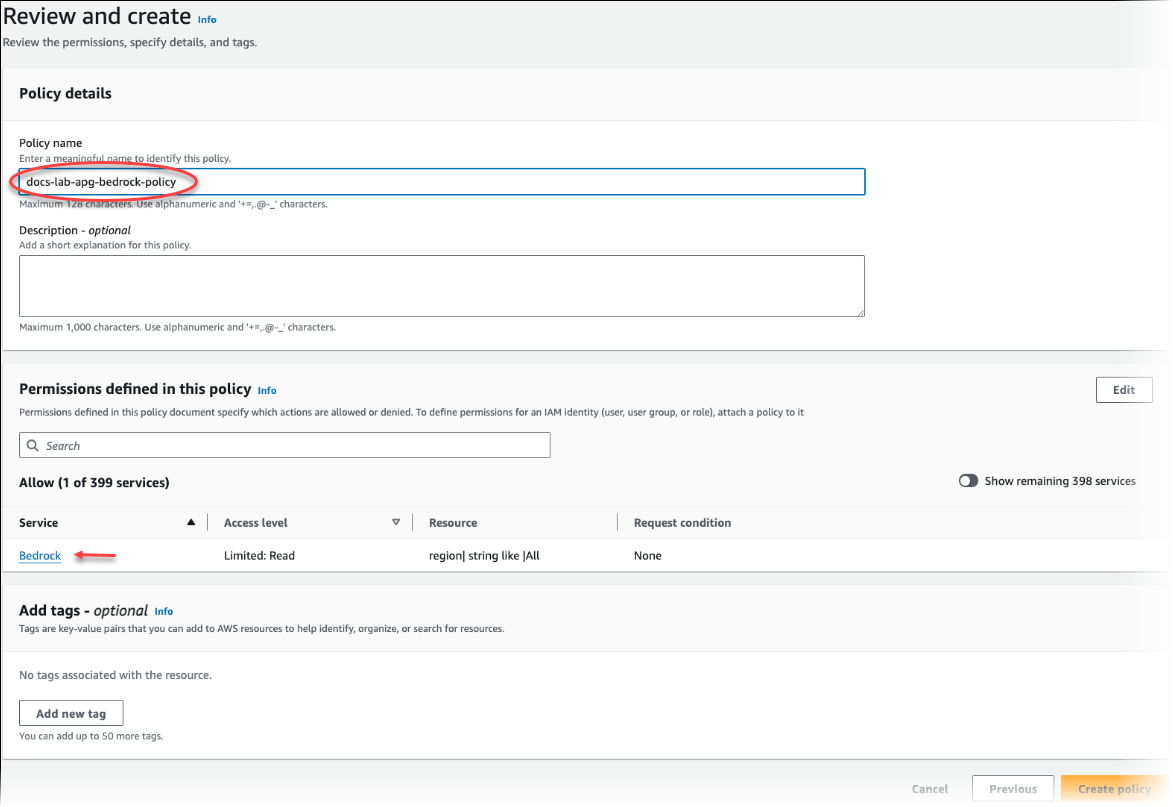
정책 생성을 선택합니다. 정책이 저장되면 콘솔에 알림이 표시됩니다. 정책 목록에서 저장한 정책을 찾을 수 있습니다.
IAM 콘솔에서 역할(액세스 관리 아래)을 선택합니다.
역할 생성을 선택합니다.
신뢰할 수 있는 엔터티 선택 페이지에서 AWS 서비스 타일을 선택한 다음 RDS를 선택하여 선택기를 엽니다.
RDS – 데이터베이스에 역할 추가를 선택합니다.
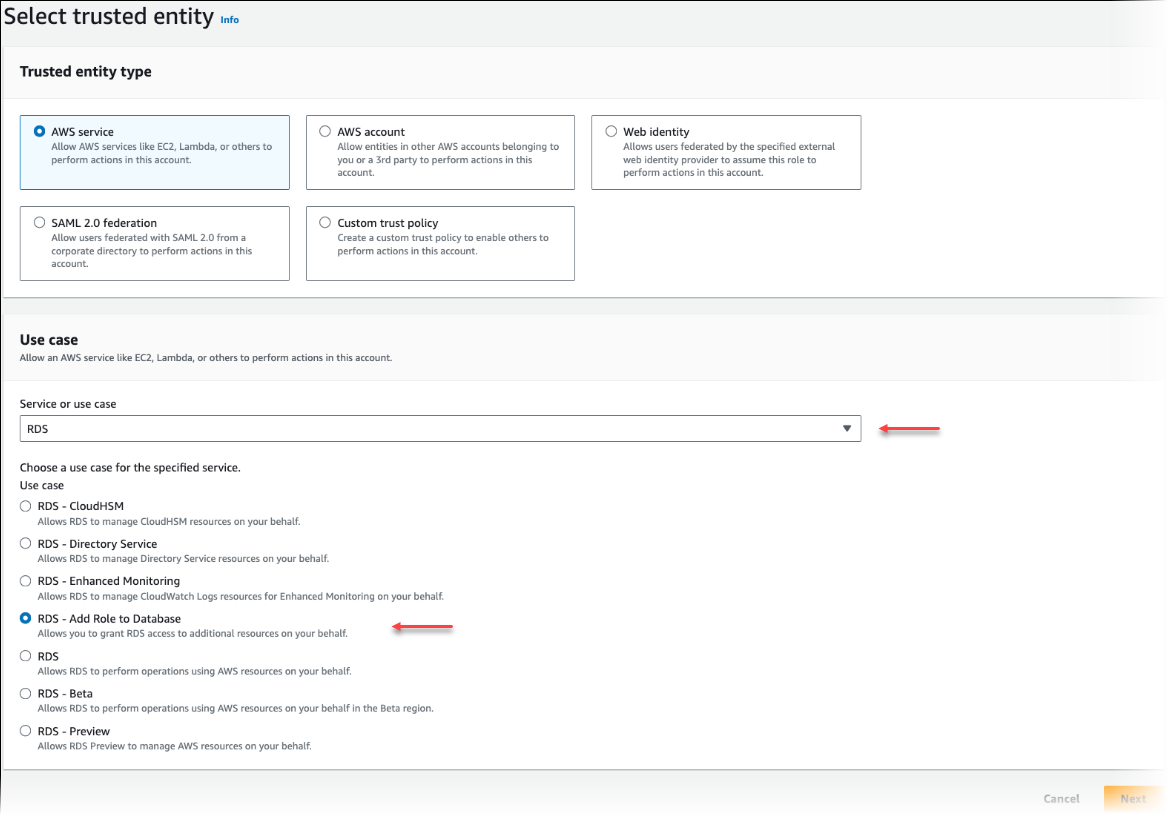
Next(다음)를 선택합니다. 권한 추가 페이지에서 이전 단계에서 만든 정책을 찾아 나열된 정책 중에서 선택합니다. Next(다음)를 선택합니다.
다음: 검토. 이미지의 이름과 설명을 입력합니다.
https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. Aurora PostgreSQL DB 클러스터가 있는 AWS 리전 위치로 이동합니다.
-
탐색 창에서 데이터베이스를 선택한 다음 Bedrock과 함께 사용할 Aurora PostgreSQL DB 클러스터를 선택합니다.
-
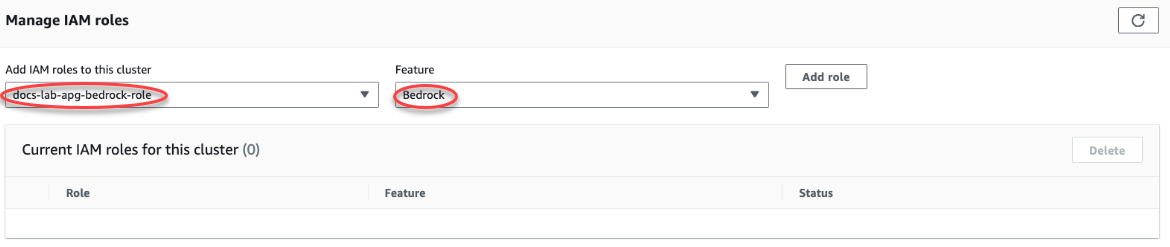
연결 및 보안 탭을 선택하고 스크롤하여 페이지의 IAM 역할 관리 섹션을 찾습니다. 이 클러스터에 IAM 역할 추가 선택기에서 이전 단계에서 생성한 역할을 선택합니다. 기능 선택기에서 Bedrock을 선택한 다음 역할 추가를 선택합니다.
역할(정책 포함)은 Aurora PostgreSQL DB 클러스터와 연결됩니다. 프로세스가 완료되면 다음 이미지와 같이 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
Amazon Bedrock에 대한 IAM 설정이 완료되었습니다. Aurora 기계 학습 확장 설치에 설명된 대로 확장을 설치하여 Aurora 기계 학습과 함께 작동하도록 Aurora PostgreSQL 설정을 계속하세요.
Amazon Comprehend를 사용하도록 Aurora PostgreSQL 설정
다음 절차에서는 먼저 클러스터를 대신하여 Amazon Comprehend를 사용하도록 Aurora PostgreSQL에 권한을 부여하는 IAM 역할 및 정책을 생성합니다. 그런 다음 Aurora PostgreSQL DB 클러스터가 Amazon Comprehend와 함께 작동하기 위해 사용하는 IAM 역할에 정책을 연결합니다. 간단히 하기 위해 이 절차에서는 AWS Management Console을 사용하여 모든 작업을 완료합니다.
Amazon Comprehend를 사용하도록 Aurora PostgreSQL DB 클러스터를 설정하는 방법
AWS Management Console에 로그인하여 https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. AWS Identity and Access Management(IAM) 콘솔 메뉴에서 정책(액세스 관리 아래)을 선택합니다.
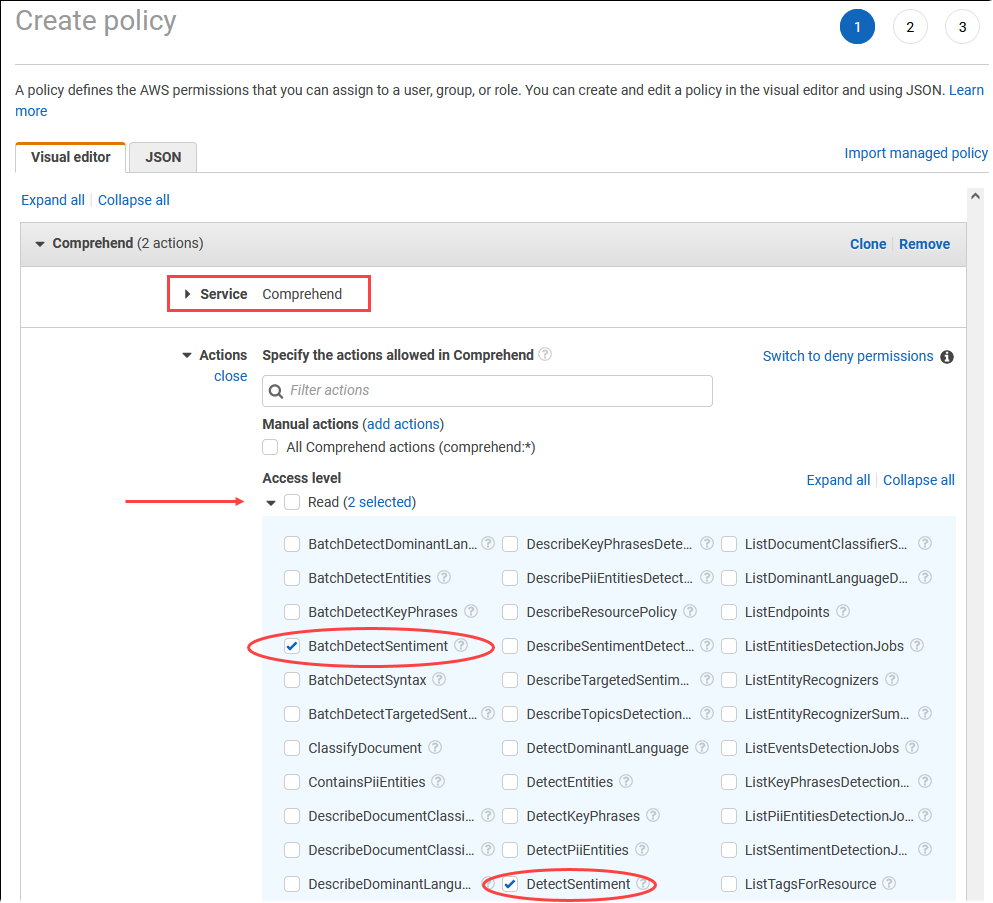
정책 생성을 선택합니다. 비주얼 에디터 페이지에서 서비스를 선택한 다음 서비스 선택 필드에 Comprehend를 입력합니다. 읽기 액세스 수준을 확장합니다. Amazon Comprehend 읽기 설정에서 BatchDetectSentiment 및 DetectSentiment를 선택합니다.
다음: 태그를 선택하고 원하는 태그를 정의합니다(선택 사항). 다음: 검토를 선택합니다. 다음 이미지와 같이 정책의 이름과 설명을 입력합니다.
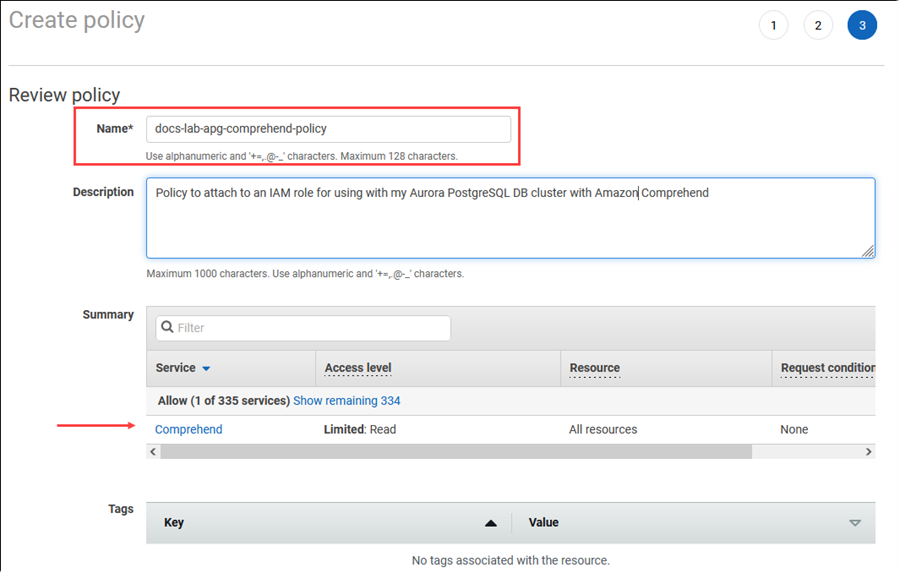
정책 생성을 선택합니다. 정책이 저장되면 콘솔에 알림이 표시됩니다. 정책 목록에서 저장한 정책을 찾을 수 있습니다.
IAM 콘솔에서 역할(액세스 관리 아래)을 선택합니다.
역할 생성을 선택합니다.
신뢰할 수 있는 엔터티 선택 페이지에서 AWS 서비스 타일을 선택한 다음 RDS를 선택하여 선택기를 엽니다.
RDS – 데이터베이스에 역할 추가를 선택합니다.
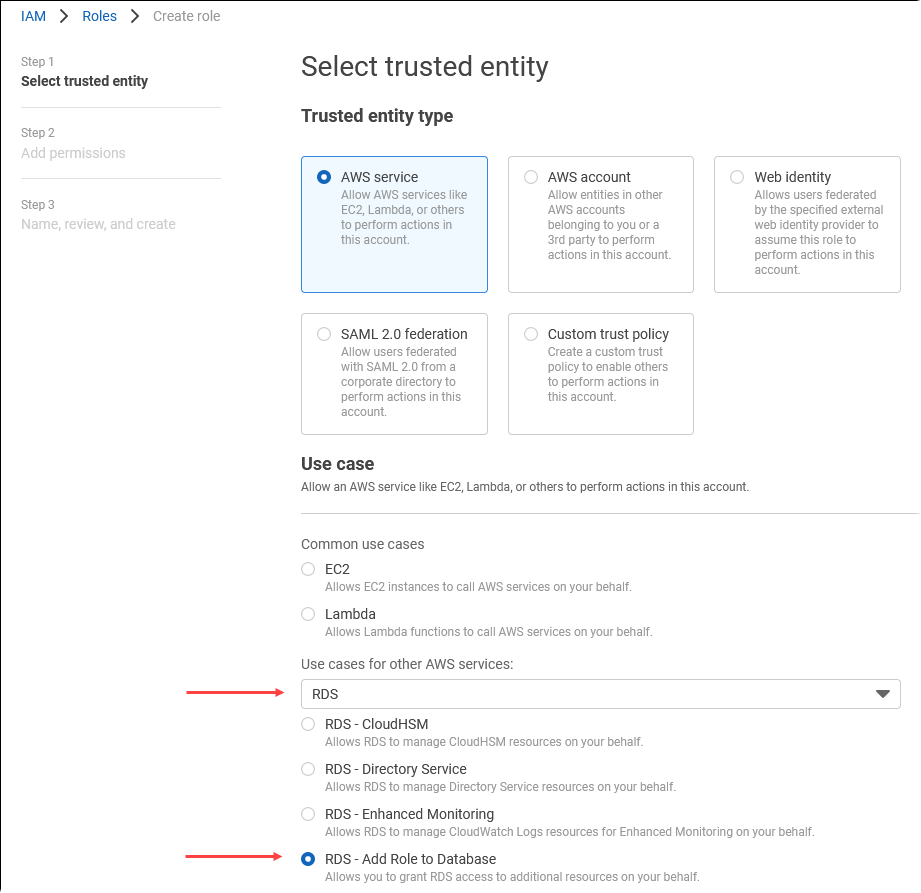
Next(다음)를 선택합니다. 권한 추가 페이지에서 이전 단계에서 만든 정책을 찾아 나열된 정책 중에서 선택합니다. 다음을 선택합니다.
다음: 검토. 이미지의 이름과 설명을 입력합니다.
https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. Aurora PostgreSQL DB 클러스터가 있는 AWS 리전 위치로 이동합니다.
-
탐색 창에서 데이터베이스를 선택한 다음 Amazon Comprehend와 함께 사용하려는 Aurora PostgreSQL DB 클러스터를 선택합니다.
-
연결 및 보안 탭을 선택하고 스크롤하여 페이지의 IAM 역할 관리 섹션을 찾습니다. 이 클러스터에 IAM 역할 추가 선택기에서 이전 단계에서 생성한 역할을 선택합니다. 기능 선택기에서 Comprehend를 선택한 다음 역할 추가를 선택합니다.
역할(정책 포함)은 Aurora PostgreSQL DB 클러스터와 연결됩니다. 프로세스가 완료되면 다음 이미지와 같이 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
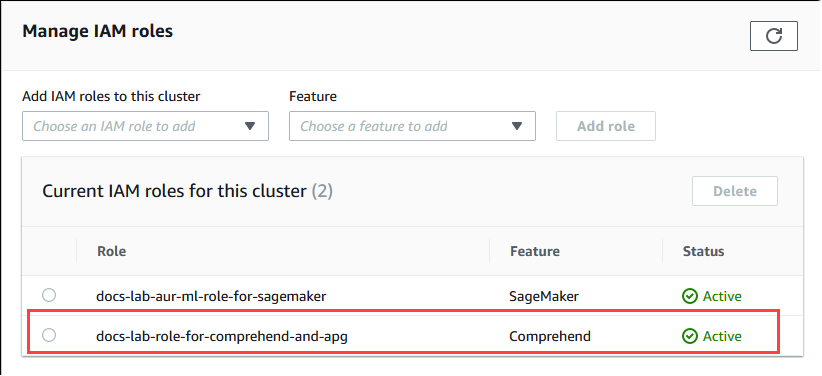
Amazon Comprehend에 대한 IAM 설정이 완료되었습니다. Aurora 기계 학습 확장 설치에 설명된 대로 확장을 설치하여 Aurora 기계 학습과 함께 작동하도록 Aurora PostgreSQL 설정을 계속하세요.
Amazon SageMaker AI를 사용하도록 Aurora PostgreSQL 설정
Aurora PostgreSQL DB 클러스터의 IAM 정책과 역할을 만들려면 먼저 SageMaker AI 모델을 설정하고 엔드포인트를 사용할 수 있어야 합니다.
SageMaker AI를 사용하도록 Aurora PostgreSQL DB 클러스터를 설정하는 방법
AWS Management Console에 로그인하여 https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. AWS Identity and Access Management(IAM) 콘솔 메뉴에서 정책(액세스 관리 아래)을 선택한 후 정책 생성을 선택합니다. 비주얼 에디터의 서비스에서 SageMaker를 선택합니다. 작업의 경우 읽기 선택기(액세스 수준 아래)를 열고 InvokeEndpoint를 선택합니다. 이렇게 하면 경고 아이콘이 표시됩니다.
리소스 선택기를 열고 InvokeEndpoint 작업에 대한 엔드포인트 리소스 ARN 지정 아래에서 액세스를 제한할 ARN 추가 링크를 선택합니다.
SageMaker AI 리소스의 AWS 리전 및 엔드포인트 이름을 입력합니다. AWS 계정이 미리 입력되었습니다.

추가를 선택하여 저장합니다. 다음: 태그 및 다음: 검토를 선택하여 정책 생성 프로세스의 마지막 페이지로 이동합니다.
정책의 이름과 설명을 입력한 다음 정책 생성을 선택합니다. 정책이 생성되고 정책 목록에 추가됩니다. 그러면 콘솔에 알림이 표시됩니다.
IAM 콘솔에서 역할을 선택합니다.
역할 생성을 선택합니다.
신뢰할 수 있는 엔터티 선택 페이지에서 AWS 서비스 타일을 선택한 다음 RDS를 선택하여 선택기를 엽니다.
RDS – 데이터베이스에 역할 추가를 선택합니다.
Next(다음)를 선택합니다. 권한 추가 페이지에서 이전 단계에서 만든 정책을 찾아 나열된 정책 중에서 선택합니다. 다음을 선택합니다.
다음: 검토. 이미지의 이름과 설명을 입력합니다.
https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. Aurora PostgreSQL DB 클러스터가 있는 AWS 리전 위치로 이동합니다.
-
탐색 창에서 데이터베이스를 선택한 다음 SageMaker AI와 함께 사용하려는 Aurora PostgreSQL DB 클러스터를 선택합니다.
-
연결 및 보안 탭을 선택하고 스크롤하여 페이지의 IAM 역할 관리 섹션을 찾습니다. 이 클러스터에 IAM 역할 추가 선택기에서 이전 단계에서 생성한 역할을 선택합니다. 기능 선택기에서 SageMaker AI를 선택한 다음 역할 추가를 선택합니다.
역할(정책 포함)은 Aurora PostgreSQL DB 클러스터와 연결됩니다. 프로세스가 완료되면 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
SageMaker AI에 대한 IAM 설정이 완료되었습니다. Aurora 기계 학습 확장 설치에 설명된 대로 확장을 설치하여 Aurora 기계 학습과 함께 작동하도록 Aurora PostgreSQL 설정을 계속하세요.
Amazon S3 for SageMaker AI를 사용하도록 Aurora PostgreSQL 설정(고급)
SageMaker AI에서 제공하는 사전 구축된 구성 요소를 사용하는 대신 자체 모델과 함께 SageMaker AI를 사용하려면 Aurora PostgreSQL DB 클러스터에서 사용할 Amazon Simple Storage Service(Amazon S3) 버킷을 설정해야 합니다. 이 주제는 고급 주제이며, 이 Amazon Aurora 사용 설명서에 완전히 설명되어 있지는 않습니다. 일반적인 프로세스는 다음과 같이 SageMaker AI 지원 통합 프로세스와 동일합니다.
Amazon S3 대한 IAM 정책 및 역할을 생성합니다.
Aurora PostgreSQL DB 클러스터의 연결 및 보안 탭에서 IAM 역할과 Amazon S3 가져오기 또는 내보내기를 기능으로 추가합니다.
Aurora DB 클러스터의 사용자 지정 DB 클러스터 파라미터 그룹에 역할의 ARN을 추가합니다.
기본적인 사용 정보는 SageMaker AI 모델 훈련을 위해 Amazon S3로 데이터 내보내기(고급) 섹션을 참조하세요.
Aurora 기계 학습 확장 설치
Aurora 기계 학습 확장 aws_ml 1.0은 Amazon Comprehend를 간접 호출하는 데 사용할 수 있는 2가지 함수를 제공하고, SageMaker AI 서비스와 aws_ml 2.0은 Amazon Bedrock 서비스를 간접 호출하는 데 사용할 수 있는 2가지 추가 함수를 제공합니다. Aurora PostgreSQL DB 클러스터에 확장을 설치하면 해당 기능에 대한 관리자 역할도 생성됩니다.
참고
이러한 함수의 사용은 Aurora 기계 학습을 사용하도록 Aurora PostgreSQL DB 클러스터 설정에 자세히 설명된 대로 Aurora 기계 학습 서비스(Amazon Comprehend, SageMaker AI, Amazon Bedrock)에 대한 IAM 설정을 완료했는지에 따라 달라집니다.
aws_comprehend.detect_sentiment - 이 함수를 사용하여 Aurora PostgreSQL DB 클러스터의 데이터베이스에 저장된 텍스트에 감성 분석을 적용합니다.
aws_sagemaker.invoke_endpoint - SQL 코드에서 이 함수를 사용하여 클러스터에서 SageMaker AI 엔드포인트와 통신합니다.
aws_bedrock.invoke_model - SQL 코드에서 이 함수를 사용하여 클러스터에 있는 Bedrock 모델과 통신합니다. 이 함수의 응답은 TEXT 형식이므로, 모델이 JSON 본문 형식으로 응답하면 이 함수의 출력은 문자열 형식으로 최종 사용자에게 전달됩니다.
aws_bedrock.invoke_model_get_embeddings – SQL 코드에서 이 함수를 사용하여 JSON 응답 내에서 출력 임베딩을 반환하는 Bedrock 모델을 간접 호출할 수 있습니다. 이 기능은 json-key와 직접 연결된 임베딩을 추출하여 자체 관리형 워크플로로 응답을 간소화하려는 경우에 활용할 수 있습니다.
Aurora PostgreSQL DB 클러스터에 Aurora 기계 학습 확장을 설치하는 방법
psql을 사용하여 Aurora PostgreSQL DB 클러스터의 라이터 인스턴스에 연결합니다.aws_ml확장을 설치할 특정 데이터베이스에 연결합니다.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
aws_ml 확장을 설치하면 다음과 같이 aws_ml 관리 역할과 3개의 스키마도 새로 생성됩니다.
aws_comprehend- Amazon Comprehend 서비스에 대한 스키마와detect_sentiment함수 소스(aws_comprehend.detect_sentiment)aws_sagemaker- SageMaker AI 서비스에 대한 스키마와invoke_endpoint함수 소스(aws_sagemaker.invoke_endpoint)aws_bedrock- Amazon Bedrock 서비스에 대한 스키마와invoke_model(aws_bedrock.invoke_model)및invoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings)함수 소스입니다.
rds_superuser 역할에는 aws_ml 관리자 역할이 부여되며 이 3개의 Aurora 기계 학습 스키마의 OWNER가 됩니다. 다른 데이터베이스 사용자가 Aurora 기계 학습 함수에 액세스할 수 있도록 하려면 rds_superuser가 Aurora 기계 학습 함수에 대한 EXECUTE 권한을 부여해야 합니다. 기본적으로 두 Aurora 기계 학습 스키마의 함수에 대한 EXECUTE 권한이 PUBLIC으로부터 취소됩니다.
멀티 테넌트 데이터베이스 구성에서는 보호하려는 특정 Aurora 기계 학습 스키마에서 REVOKE USAGE를 사용하여 테넌트가 Aurora 기계 학습 함수에 액세스하지 못하도록 할 수 있습니다.
Aurora PostgreSQL DB 클러스터와 함께 Amazon Bedrock 사용
Aurora PostgreSQL의 경우 Aurora 기계 학습은 텍스트 데이터를 사용하기 위한 다음 Amazon Bedrock 함수를 제공합니다. 이 함수는 aws_ml 2.0 확장을 설치하고 모든 설정 절차를 완료한 후에만 사용할 수 있습니다. 자세한 내용은 Aurora 기계 학습을 사용하도록 Aurora PostgreSQL DB 클러스터 설정 단원을 참조하십시오.
- aws_bedrock.invoke_model
-
이 함수는 JSON 형식의 텍스트를 입력으로 받아 Amazon Bedrock에서 호스팅되는 다양한 모델에 맞게 처리하고 모델로부터 JSON 텍스트 응답을 가져옵니다. 이 응답에는 텍스트, 이미지 또는 임베딩이 포함될 수 있습니다. 함수 설명서의 요약은 다음과 같습니다.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
이 함수의 입력과 출력은 다음과 같습니다.
-
model_id– 모델 식별자입니다. content_type– Bedrock 모델에 대한 요청 유형입니다.accept_type– Bedrock 모델에서 기대할 수 있는 응답 유형입니다. 일반적으로 대부분의 모델에는 애플리케이션/JSON이 사용됩니다.model_input– 프롬프트로, content_type에 지정된 형식의 모델에 대한 특정 입력 집합입니다. 모델이 허용하는 요청 형식/구조에 대한 자세한 내용은 파운데이션 모델의 추론 파라미터를 참조하세요.model_output- Bedrock 모델의 텍스트 출력입니다.
다음 예제는 invoke_model을 사용하여 Bedrock에 대한 Anthropic Claude 2 모델을 간접 호출하는 방법을 보여줍니다.
예: Amazon Bedrock 함수를 사용하는 간단한 쿼리
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
모델 출력은 경우에 따라 벡터 임베딩을 가리킬 수 있습니다. 모델마다 응답이 다르므로 invoke_model과 똑같이 작동하지만, 적절한 json-key를 지정하여 임베딩을 출력하는 invoke_model_get_embeddings라는 또 다른 함수를 활용할 수 있습니다.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
이 함수의 입력과 출력은 다음과 같습니다.
-
model_id– 모델 식별자입니다. content_type– Bedrock 모델에 대한 요청 유형입니다. 여기서는 accept_type이 기본값(application/json)으로 설정되어 있습니다.model_input– 프롬프트로, content_type에 지정된 형식의 모델에 대한 특정 입력 집합입니다. 모델이 허용하는 요청 형식/구조에 대한 자세한 내용은 파운데이션 모델의 추론 파라미터를 참조하세요.json_key- 임베딩을 추출할 필드에 대한 참조입니다. 임베딩 모델이 변경되면 달라질 수 있습니다.-
model_output– Bedrock 모델의 출력은 16비트 십진수로 구성된 임베딩 배열입니다.
다음 예제는 PostgreSQL I/O 모니터링 뷰라는 문구에 대한 Titan Embeddings G1 – Text 임베딩 모델을 사용하여 임베딩을 생성하는 방법을 보여줍니다.
예: Amazon Bedrock 함수를 사용하는 간단한 쿼리
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Aurora PostgreSQL DB 클러스터와 함께 Amazon Comprehend 사용
Aurora PostgreSQL의 경우 Aurora 기계 학습은 텍스트 데이터를 사용하기 위한 다음 Amazon Comprehend 함수를 제공합니다. 이 함수는 aws_ml 확장을 설치하고 모든 설정 절차를 완료한 후에만 사용할 수 있습니다. 자세한 내용은 Aurora 기계 학습을 사용하도록 Aurora PostgreSQL DB 클러스터 설정 단원을 참조하십시오.
- aws_comprehend.detect_sentiment
-
이 함수는 텍스트를 입력으로 받아 텍스트의 감정 태도가 긍정적인지, 부정적인지, 중립적인지 또는 혼합되어 있는지 평가합니다. 그런 다음 평가를 위한 신뢰도와 함께 이 감정을 출력합니다. 함수 설명서의 요약은 다음과 같습니다.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
이 함수의 입력과 출력은 다음과 같습니다.
-
input_text- 감정을 평가하고 할당할 텍스트(부정, 긍정, 중립, 혼합) language_code- 해당하는 경우 필요에 따라 리전 하위 태그가 있는 2자리 ISO 639-1 식별자 또는 ISO 639-2 세 글자 코드를 사용하여 식별된input_text의 언어. 예를 들어,en은 영어 코드이고zh는 중국어 간체 코드입니다. 자세한 내용은 Amazon Comprehend 개발자 안내서의 지원되는 언어를 참조하세요.max_rows_per_batch- 배치 모드 처리를 위한 배치당 최대 행 수 자세한 내용은 배치 모드 및 Aurora 기계 학습 함수의 이해 단원을 참조하십시오.sentiment- 긍정, 부정, 중립 또는 혼합으로 식별되는 입력 텍스트의 감정confidence- 지정된sentiment의 정확성에 대한 신뢰도. 값의 범위는 0.0~1.0입니다.
아래에서 이 함수를 사용하는 방법의 예를 찾아볼 수 있습니다.
예: Amazon Comprehend 함수를 사용하는 간단한 쿼리
다음은 이 함수를 호출하여 지원 팀에 대한 고객 만족도를 평가하는 간단한 쿼리의 예입니다. 도움 요청이 있을 때마다 고객 피드백을 저장하는 데이터베이스 테이블(support)이 있다고 가정해 봅시다. 이 예시 쿼리는 테이블 feedback 열의 텍스트에 aws_comprehend.detect_sentiment 함수를 적용하고 감정 및 감정에 대한 신뢰도를 출력합니다. 이 쿼리는 결과를 내림차순으로 출력합니다.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
테이블 행당 두 번 이상 감성 분석 요금이 청구되지 않도록 결과를 구체화할 수 있습니다. 관심있는 행에 대해 이 작업을 수행하십시오. 예를 들어, 임상의의 메모를 업데이트하여 프랑스어(fr)로 된 텍스트만 감정 감지 함수를 사용할 수 있도록 합니다.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
함수 호출 최적화에 대한 자세한 내용은 Aurora PostgreSQL을 사용하는 Aurora 기계 학습의 성능 고려 사항 단원을 참조하십시오.
Aurora PostgreSQL DB 클러스터와 함께 SageMaker AI 사용
Amazon SageMaker AI를 사용하도록 Aurora PostgreSQL 설정 에서 설명된 대로 SageMaker AI 환경을 설정하고 Aurora PostgreSQL과 통합한 후에 aws_sagemaker.invoke_endpoint 함수를 사용하여 작업을 간접 호출할 수 있습니다. aws_sagemaker.invoke_endpoint 함수는 동일한 AWS 리전의 모델 엔드포인트에만 연결됩니다. 데이터베이스 인스턴스가 여러 AWS 리전에 복제본을 가지고 있는 경우 각 SageMaker AI 모델을 AWS 리전마다 설정하고 배포해야 합니다.
aws_sagemaker.invoke_endpoint에 대한 직접 호출은 Aurora PostgreSQL DB 클러스터를 설정 프로세스 중에 제공한 SageMaker AI 서비스 및 엔드포인트와 연결하도록 설정한 IAM 역할을 사용하여 인증됩니다. SageMaker AI 모델 엔드포인트는 개별 계정으로 범위가 지정되며 공개되지 않습니다. endpoint_name URL에 계정 ID를 포함하지 않습니다. SageMaker AI는 데이터베이스 인스턴스의 SageMaker AI IAM 역할에서 제공하는 인증 토큰에서 계정 ID를 확인합니다.
- aws_sagemaker.invoke_endpoint
이 함수는 SageMaker AI 엔드포인트를 입력으로 사용하고 일괄 처리해야 하는 행 수를 사용합니다. 또한 SageMaker AI 모델 엔드포인트에서 기대하는 다양한 파라미터를 입력으로 사용합니다. 이 함수의 참조 문서는 다음과 같습니다.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
이 함수의 입력과 출력은 다음과 같습니다.
endpoint_name- AWS 리전에 독립적인 엔드포인트 URLmax_rows_per_batch- 배치 모드 처리를 위한 배치당 최대 행 수 자세한 내용은 배치 모드 및 Aurora 기계 학습 함수의 이해 단원을 참조하십시오.model_input- 모델에 대한 하나 이상의 입력 파라미터. SageMaker AI 모델에 필요한 모든 데이터 형식이 될 수 있습니다. PostgreSQL을 사용하면 함수에 대해 최대 100개의 입력 파라미터를 지정할 수 있습니다. 배열 데이터 형식은 1차원이어야 하지만 SageMaker AI 모델에서 예상하는 만큼 많은 요소를 포함할 수 있습니다. SageMaker AI 모델에 대한 입력 수는 SageMaker AI 메시지 크기 제한인 6MB로만 제한됩니다.model_output- SageMaker AI 모델의 텍스트 출력
SageMaker AI 모델을 간접 호출하는 사용자 정의 함수 만들기
각 SageMaker AI 모델에 대해 aws_sagemaker.invoke_endpoint를 직접 호출하는 별도의 사용자 정의 함수를 만듭니다. 사용자 정의 함수는 이 모델을 호스팅하는 SageMaker AI 엔드포인트를 나타냅니다. 이 aws_sagemaker.invoke_endpoint 함수는 사용자 정의 함수 내에서 실행됩니다. 사용자 정의 함수는 다음과 같은 많은 장점을 제공합니다.
-
모든 SageMaker AI 모델에 대해
aws_sagemaker.invoke_endpoint를 직접 호출하는 대신 SageMaker AI 모델에 고유한 이름을 지정할 수 있습니다. -
SQL 애플리케이션 코드의 한 곳에만 모델 엔드포인트 URL을 지정할 수 있습니다.
-
각 Aurora 기계 학습 함수에 대한
EXECUTE권한을 독립적으로 제어할 수 있습니다. -
SQL 유형을 사용하여 모델 입력 및 출력 유형을 선언할 수 있습니다. SQL은 SageMaker AI 모델에 전달된 인수의 수와 유형을 적용하고 필요한 경우 유형 변환을 수행합니다. SQL 유형을 사용하면
SQL NULL이 SageMaker AI 모델에서 예상되는 적절한 기본값으로 변환됩니다. -
처음 몇 행을 조금 더 빨리 반환하려면 최대 배치 크기를 줄일 수 있습니다.
사용자 정의 함수를 지정하려면 SQL 데이터 정의 언어(DDL) 문 CREATE FUNCTION을 사용합니다. 함수를 정의할 때 다음을 지정합니다.
-
모델에 대한 입력 파라미터
-
간접 호출할 특정 SageMaker AI 엔드포인트
-
반환 유형
사용자 정의 함수에서는 입력 파라미터에 근거하여 모델을 실행한 후에 SageMaker AI 엔드포인트가 계산한 추론을 반환합니다. 다음 예시에서는 두 개의 입력 파라미터가 있는 SageMaker AI 모델에 대해 사용자 정의 함수를 만듭니다.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;다음을 참조하십시오.
-
aws_sagemaker.invoke_endpoint함수 입력은 모든 데이터 형식에 대한 하나 이상의 파라미터가 될 수 있습니다. -
이 예제에서는 INT 출력 유형을 사용합니다.
varchar유형에서 다른 유형으로 출력을 캐스팅하는 경우INTEGER,REAL,FLOAT또는NUMERIC등의 PostgreSQL 기본 제공 스칼라 유형으로 캐스팅해야 합니다. 이러한 유형에 대한 자세한 내용은 PostgreSQL 설명서의 데이터 형식을 참조하십시오. -
병렬 쿼리 처리를 활성화하려면
PARALLEL SAFE를 지정합니다. 자세한 내용은 병렬 쿼리 처리를 통한 응답 시간 개선 섹션을 참조하세요. -
함수 실행 비용을 예상하도록
COST 5000을 지정합니다. 함수의 예상 실행 비용을cpu_operator_cost단위로 제공하는 양수를 사용합니다.
SageMaker AI 모델에 대한 입력으로 배열 전달
aws_sagemaker.invoke_endpoint 함수는 PostgreSQL 함수의 한계인 최대 100개의 입력 파라미터를 가질 수 있습니다. SageMaker AI 모델에 동일한 유형의 파라미터가 100개 이상 필요한 경우 모델 파라미터를 배열로 전달하세요.
다음 예시에서는 배열을 SageMaker AI 회귀 모델에 대한 입력으로 전달하는 함수를 정의합니다. 출력은 REAL 값으로 변환됩니다.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
SageMaker AI 모델 간접 호출 시 배치 크기 지정
다음 예시에서는 배치 크기 기본값을 NULL로 설정하는 SageMaker AI 모델에 대한 사용자 정의 함수를 만듭니다. 이 함수를 사용하면 호출할 때 다른 배치 크기를 제공할 수도 있습니다.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;다음을 참조하십시오.
-
선택적
max_rows_per_batch파라미터를 사용하여 배치 모드 함수 호출에 대한 행 수를 제어합니다. NULL 값을 사용하는 경우 쿼리 최적화 프로그램이 자동으로 최대 배치 크기를 선택합니다. 자세한 내용은 배치 모드 및 Aurora 기계 학습 함수의 이해 단원을 참조하십시오. -
기본적으로 파라미터의 값으로 NULL을 전달하면 SageMaker AI에 전달하기 전에 빈 문자열로 변환됩니다. 이 예제의 경우 입력에 다양한 유형이 있습니다.
-
텍스트가 아닌 입력 또는 빈 문자열이 아닌 다른 값으로 기본값을 설정해야 하는 텍스트 입력이 있는 경우
COALESCE문을 사용합니다.COALESCE를 호출할 때aws_sagemaker.invoke_endpoint를 사용하여 NULL을 원하는 NULL 대체 값으로 변환합니다. 이 예제에 있는amount파라미터의 경우 NULL 값은 0.0으로 변환됩니다.
다중 출력이 있는 SageMaker AI 모델 간접 호출
다음 예시에서는 다중 출력을 반환하는 SageMaker AI 모델에 대한 사용자 정의 함수를 만듭니다. 함수는 aws_sagemaker.invoke_endpoint 함수의 출력을 해당 데이터 형식으로 캐스팅해야 합니다. 예를 들어 (x,y) 쌍이나 사용자 정의 복합 유형에 대해 기본 제공 PostgreSQL 포인트 유형을 사용할 수 있습니다.
이 사용자 정의 함수는 출력에 대한 복합 유형을 사용하여 여러 출력을 반환하는 모델에서 값을 반환합니다.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
복합 유형의 경우 모델 출력에 나타나는 순서와 동일한 순서로 필드를 사용하고 aws_sagemaker.invoke_endpoint의 출력을 복합 유형으로 캐스팅합니다. 호출자는 이름 또는 PostgreSQL ".*" 표기법으로 개별 필드를 추출할 수 있습니다.
SageMaker AI 모델 훈련을 위해 Amazon S3로 데이터 내보내기(고급)
자체 모델을 훈련시키는 대신 제공된 알고리즘과 예시를 사용하여 Aurora 기계 학습과 SageMaker AI에 익숙해지는 것이 좋습니다. 자세한 내용은 Get Started with Amazon SageMaker AI를 참조하세요.
SageMaker AI 모델을 훈련하려면 데이터를 Amazon S3 버킷으로 내보냅니다. Amazon S3 버킷은 모델이 배포되기 전에 SageMaker AI에서 모델을 훈련하는 데 사용됩니다. Aurora PostgreSQL DB 클러스터에서 데이터를 쿼리한 후 Amazon S3 버킷에 저장된 텍스트 파일에 직접 저장할 수 있습니다. 그런 다음 SageMaker AI에서 훈련을 위해 Amazon S3 버킷의 데이터를 사용합니다. SageMaker AI 모델 훈련에 대한 자세한 내용은 Train a model with Amazon SageMaker AI를 참조하세요.
참고
SageMaker AI 모델 훈련 또는 배치 점수 계산을 위해 Amazon S3 버킷을 만들 때는 Amazon S3 버킷 이름에 sagemaker를 포함하세요. 자세한 내용은 Amazon SageMaker AI Developer Guide의 Specify a Amazon S3 Bucket to Upload Training Datasets and Store Output Data를 참조하세요.
데이터 내보내기에 대한 자세한 내용은 Aurora PostgreSQL DB 클러스터에서 Amazon S3로 데이터 내보내기 단원을 참조하십시오.
Aurora PostgreSQL을 사용하는 Aurora 기계 학습의 성능 고려 사항
Amazon Comprehend 및 SageMaker AI 서비스는 Aurora 기계 학습 함수에서 간접 호출할 때 대부분의 작업을 수행합니다. 즉, 필요에 따라 독립적으로 리소스를 확장할 수 있습니다. Aurora PostgreSQL DB 클러스터의 경우 함수 호출을 최대한 효율적으로 만들 수 있습니다. 다음은 Aurora PostgreSQL에서 Aurora 기계 학습을 사용할 때 참고해야 할 몇 가지 성능 고려 사항입니다.
배치 모드 및 Aurora 기계 학습 함수의 이해
일반적으로 PostgreSQL은 한 번에 한 행씩 함수를 실행합니다. Aurora 기계 학습은 배치 모드 실행이라는 접근 방식을 사용하여 많은 행에 대한 외부 Aurora 기계 학습 서비스 호출을 배치로 결합하여 이러한 오버헤드를 줄일 수 있습니다. 배치 모드에서는 Aurora 기계 학습에서 입력 행 배치에 대한 응답을 수신한 다음 응답을 실행 중인 쿼리에 한 번에 한 행씩 다시 전달합니다. 이 최적화는 PostgreSQL 쿼리 최적화 프로그램을 제한하지 않고 Aurora 쿼리의 처리량을 향상시킵니다.
함수가 SELECT 목록, WHERE 절 또는 HAVING 절에서 참조되는 경우 Aurora는 자동으로 배치 모드를 사용합니다. 최상위 단순 CASE 표현식은 배치 모드 실행에 적합합니다. 또한 최상위 검색 CASE 표현식은 첫 번째 WHEN 절이 배치 모드 함수 호출이 있는 간단한 술어인 경우 배치 모드 실행에 적합합니다.
사용자 정의 함수는 LANGUAGE SQL 함수여야 하며 PARALLEL SAFE 및 COST 5000을 지정해야 합니다.
SELECT 문에서 FROM 절로 함수 마이그레이션
일반적으로 배치 모드 실행에 적합한 aws_ml 함수는 Aurora에 의해 자동으로 FROM 절로 마이그레이션됩니다.
적합한 배치 모드 함수를 FROM 절로 마이그레이션하는 작업은 쿼리별 수준에서 수동으로 검사할 수 있습니다. 이렇게 하려면 EXPLAIN 문(및 ANALYZE와 VERBOSE)을 사용하고 각 배치 모드 Function Scan에서 “배치 처리” 정보를 찾습니다. 쿼리를 실행하지 않고 EXPLAIN(VERBOSE와 함께)을 사용할 수도 있습니다. 그런 다음 함수에 대한 호출이 원래 문에 지정되지 않은 중첩 루프 조인 아래에 Function
Scan으로 표시되는지 여부를 관찰합니다.
다음 예에서 계획의 중첩 루프 조인 연산자는 Aurora가 anomaly_score 함수를 마이그레이션했음을 보여줍니다. 이 함수를 SELECT 목록에서 배치 모드 실행에 적합한 FROM 절로 마이그레이션했습니다.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)배치 모드 실행을 비활성화하려면 apg_enable_function_migration 파라미터를 false로 설정합니다. 이렇게 하면 aws_ml 함수가 SELECT에서 FROM 절로 마이그레이션되는 것을 방지할 수 있습니다. 아래에서는 이 작업을 수행하는 방법을 보여줍니다.
SET apg_enable_function_migration = false;apg_enable_function_migration 파라미터는 쿼리 계획 관리를 위해 Aurora PostgreSQL apg_plan_mgmt 확장에서 인식하는 Grand Unified Configuration(GUC) 파라미터입니다. 세션에서 함수 마이그레이션을 비활성화하려면 쿼리 계획 관리를 사용하여 결과 계획을 approved 계획으로 저장합니다. 런타임 시 쿼리 계획 관리는 해당 approved 설정으로 apg_enable_function_migration 계획을 적용합니다. 이 적용은 apg_enable_function_migration GUC 파라미터 설정에 관계없이 발생합니다. 자세한 내용은 Aurora PostgreSQL용 쿼리 실행 계획 관리 섹션을 참조하세요.
max_rows_per_batch 파라미터 사용
aws_comprehend.detect_sentiment 및 aws_sagemaker.invoke_endpoint 함수 모두에 max_rows_per_batch 파라미터가 있습니다. 이 파라미터는 Aurora 기계 학습 서비스에 전송할 수 있는 행 수를 지정합니다. 함수에 의해 처리되는 데이터 세트가 클수록 배치 크기가 커질 수 있습니다.
배치 모드 함수는 많은 수의 행에 Aurora 기계 학습 함수 호출 비용을 분산시키는 행 배치를 구축하여 효율성을 향상시킵니다. 그러나 SELECT 절로 인해 LIMIT 문이 일찍 끝나는 경우 쿼리에서 사용하는 것보다 많은 행에 배치를 구성할 수 있습니다. 이 방법을 사용하면 AWS 계정에 추가 요금이 부과될 수 있습니다. 배치 모드 실행의 이점을 이용하면서 너무 큰 배치를 작성하지 않으려면 함수 호출에서 max_rows_per_batch 파라미터에 대해 더 작은 값을 사용하십시오.
배치 모드 실행을 사용하는 쿼리의 EXPLAIN(VERBOSE, ANALYZE)을 수행하면 중첩 루프 조인 아래에 FunctionScan 연산자가 표시됩니다. EXPLAIN에서 보고한 루프 수는 FunctionScan 연산자에서 행을 가져온 횟수와 같습니다. 명령문에서 LIMIT 절을 사용하는 경우 가져오기 수가 일정합니다. 배치 크기를 최적화하려면 max_rows_per_batch 파라미터를 이 값으로 설정합니다. 그러나 배치 모드 함수가 WHERE 절 또는 HAVING 절의 술어에서 참조되면 가져오기 수를 미리 알 수 없습니다. 이 경우 루프를 지침으로 사용하고 max_rows_per_batch를 사용하여 성능을 최적화하는 설정을 찾습니다.
배치 모드 실행 확인
배치 모드에서 함수가 실행되었는지 확인하려면 EXPLAIN ANALYZE를 사용합니다. 배치 모드 실행이 사용된 경우 쿼리 계획은 “일괄 처리” 섹션에 정보를 포함합니다.
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273이 예에서는 3,333개의 행을 포함하는 배치가 1개 있었는데 처리하는 데 146.273ms가 걸렸습니다. “배치 처리” 섹션에는 다음이 표시됩니다.
-
이 함수 스캔 작업과 관련된 배치 수
-
배치 크기 평균, 최소 및 최대값
-
배치 실행 시간 평균, 최소 및 최대값
일반적으로 최종 배치는 나머지 배치보다 작기 때문에 평균보다 훨씬 작은 최소 배치 크기가 됩니다.
처음 몇 개의 행을 더 빨리 반환하려면 max_rows_per_batch 파라미터를 더 작은 값으로 설정하십시오.
사용자 정의 함수에서 LIMIT를 사용할 때 ML 서비스에 대한 배치 모드 호출 수를 줄이려면 max_rows_per_batch 파라미터를 더 작은 값으로 설정하십시오.
병렬 쿼리 처리를 통한 응답 시간 개선
많은 수의 행에서 최대한 빠르게 결과를 얻으려면 병렬 쿼리 처리와 배치 모드 처리를 함께 사용할 수 있습니다. SELECT, CREATE TABLE AS SELECT 및 CREATE
MATERIALIZED VIEW 문에 대해 병렬 쿼리 처리를 사용할 수 있습니다.
참고
PostgreSQL은 아직 데이터 조작 언어(DML) 문에 대한 병렬 쿼리를 지원하지 않습니다.
병렬 쿼리 처리는 데이터베이스 내 및 ML 서비스 내에서 모두 발생합니다. 데이터베이스의 인스턴스 클래스에 있는 코어 수는 쿼리 실행 중에 사용할 수 있는 병렬 처리 정도를 제한합니다. 데이터베이스 서버는 병렬 작업자 세트 간에 작업을 분할하는 병렬 쿼리 실행 계획을 구성할 수 있습니다. 그런 다음 각 작업자는 수만 개의 행(또는 각 서비스에서 허용하는 만큼)을 포함하는 배치 요청을 작성할 수 있습니다.
모든 병렬 작업자의 배치 요청은 SageMaker AI의 엔드포인트로 전송됩니다. 엔드포인트가 지원할 수 있는 병렬 처리 정도는 이를 지원하는 인스턴스의 수와 유형으로 제한됩니다. K 정도의 병렬 처리를 위해서는 코어가 K 이상인 데이터베이스 인스턴스 클래스가 필요합니다. 또한 충분한 고성능 인스턴스 클래스의 K 초기 인스턴스가 존재하도록 모델에 대해 SageMaker AI 엔드포인트를 구성해야 합니다.
병렬 쿼리 처리를 사용하려면 전달하려는 데이터가 포함된 테이블의 parallel_workers 스토리지 파라미터를 설정할 수 있습니다. parallel_workers를 aws_comprehend.detect_sentiment와 같은 배치 모드 함수로 설정합니다. 최적화 프로그램에서 병렬 쿼리 계획을 선택하는 경우 AWS 기계 학습 서비스를 배치 및 병렬로 호출할 수 있습니다.
aws_comprehend.detect_sentiment 함수와 함께 다음 파라미터를 사용하여 4방향 병렬 처리가 있는 계획을 얻을 수 있습니다. 다음 두 파라미터 중 하나를 변경할 경우 변경 사항을 적용하려면 데이터베이스 인스턴스를 다시 시작해야 합니다.
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;병렬 쿼리 제어에 대한 자세한 내용은 PostgreSQL 설명서의 Parallel plans
구체화된 보기 및 구체화된 열 사용
데이터베이스에서 SageMaker AI 또는 Amazon Comprehend와 같은 AWS 서비스를 간접 호출하면 해당 서비스의 요금 정책에 따라 계정에 요금이 청구됩니다. 계정에 대한 요금을 최소화하기 위해 AWS 서비스를 호출한 결과를 구체화된 열로 구체화하여 AWS 서비스가 입력 행당 두 번 이상 호출되지 않도록 할 수 있습니다. 원하는 경우 materializedAt 타임스탬프 열을 추가하여 열이 구체화된 시간을 기록할 수 있습니다.
일반적인 단일 행 INSERT 문의 지연 시간은 일반적으로 배치 모드 함수를 호출하는 지연 시간보다 훨씬 짧습니다. 따라서 애플리케이션이 수행하는 모든 단일 행 INSERT에 대해 배치 모드 함수를 호출하면 애플리케이션의 지연 시간 요구 사항을 충족하지 못할 수 있습니다. AWS 서비스를 구체화된 열로 호출한 결과를 구체화하려면 일반적으로 고성능 애플리케이션이 구체화된 열을 채워야 합니다. 이를 위해 동시에 많은 행 배치에서 작동하는 UPDATE 문을 주기적으로 발행합니다.
UPDATE는 실행 중인 애플리케이션에 영향을 줄 수 있는 행 수준 잠금을 사용합니다. 따라서 SELECT ... FOR UPDATE SKIP LOCKED를 사용하거나 MATERIALIZED
VIEW를 사용해야 할 수도 있습니다.
실시간으로 많은 수의 행에서 작동하는 분석 쿼리에서는 배치 모드 구체화와 실시간 처리를 함께 사용할 수 있습니다. 이를 위해 이러한 쿼리는 구체화된 결과가 아직 없는 행에 대한 쿼리를 사용하여 미리 구체화된 결과 중 UNION ALL 하나를 어셈블합니다. 경우에 따라 여러 위치에서 이러한 UNION ALL이 필요하거나 타사 애플리케이션에서 쿼리가 생성됩니다. 이 경우 VIEW를 생성하여 UNION ALL 작업을 캡슐화하면 이 세부 정보가 나머지 SQL 애플리케이션에 노출되지 않도록 할 수 있습니다.
구체화된 보기를 사용하여 스냅샷에서 임의의 SELECT 문의 결과를 구체화할 수 있습니다. 또한 나중에 언제든지 구체화된 보기를 새로 고칠 때도 사용할 수 있습니다. 현재 PostgreSQL은 증분 새로 고침을 지원하지 않으므로 구체화된 보기를 새로 고칠 때마다 구체화된 보기가 완전히 다시 계산됩니다.
배타적 잠금을 수행하지 않고 구체화된 보기의 콘텐츠를 업데이트하는 CONCURRENTLY 옵션을 사용하여 구체화된 보기를 새로 고칠 수 있습니다. 이렇게 하면 SQL 애플리케이션이 구체화된 보기를 새로 고치는 동안 구체화된 보기에서 읽을 수 있습니다.
Aurora 기계 학습 모니터링
사용자 지정 DB 클러스터 파라미터 그룹의 track_functions 파라미터를 all로 설정하여 aws_ml 함수를 모니터링할 수 있습니다. 기본적으로 이 파라미터는 프로시저 언어 함수만 추적하도록 pl로 설정됩니다. 이를 all로 변경하면 aws_ml 함수도 추적됩니다. 자세한 내용은 PostgreSQL 설명서에서 Run-time Statistics
Aurora 기계 학습 함수에서 직접 호출하는 SageMaker AI 작업의 성능을 모니터링하는 방법에 대한 자세한 내용은 Amazon SageMaker AI Developer Guide에서 Monitor Amazon SageMaker AI를 참조하세요.
track_functions를 all로 설정하면 pg_stat_user_functions 보기를 쿼리하여 Aurora 기계 학습 서비스를 호출하기 위해 정의하고 사용하는 함수에 대한 통계를 가져올 수 있습니다. 보기에는 각 함수에 대한 calls, total_time 및 self_time의 숫자가 표시됩니다.
aws_sagemaker.invoke_endpoint 및 aws_comprehend.detect_sentiment 함수의 통계를 보려면 다음 쿼리를 사용하여 스키마 이름을 기준으로 결과를 필터링할 수 있습니다.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
통계를 지우려면 다음 작업을 수행하세요.
SELECT pg_stat_reset();
PostgreSQL pg_proc 시스템 카탈로그를 쿼리하여 aws_sagemaker.invoke_endpoint 함수를 호출하는 SQL 함수의 이름을 가져올 수 있습니다. 이 카탈로그에는 함수, 절차 등에 대한 정보가 저장됩니다. 자세한 내용은 PostgreSQL 설명서의 pg_procprosrc)에 invoke_endpoint라는 텍스트가 포함된 함수(proname)의 이름을 가져오기 위해 테이블을 쿼리하는 예입니다.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
