Amazon RDS의 모범 사례
Amazon RDS 작업 모범 사례에 대해서 알아봅니다. 새로운 모범 사례가 확인되는 대로 이 섹션을 업데이트할 예정입니다.
주제
참고
Amazon RDS에 대한 일반적인 권장 사항은 Amazon RDS의 권장 사항 단원을 참조하십시오.
Amazon RDS 기본 운영 지침
다음은 Amazon RDS로 작업할 때 모든 사용자가 따라야 하는 기본 운영 지침입니다. Amazon RDS 서비스 수준 계약에 다음 지침을 따르도록 명시되어 있습니다.
-
지표를 사용하여 메모리, CPU, 복제본 지연 및 스토리지 사용량을 모니터링합니다. 사용 패턴이 변경되거나 배포 용량 한도에 거의 도달했을 때 알림을 받도록 Amazon CloudWatch를 설정하여 시스템 성능 및 가용성을 유지할 수 있습니다.
-
스토리지 용량 한도에 도달할 경우 DB 인스턴스를 확장합니다. 스토리지 및 메모리에 어느 정도 버퍼가 있어야만 애플리케이션에서 수요가 예기치 않게 늘어날 경우 이를 수용할 수 있습니다.
-
자동 백업을 활성화하고 일일 쓰기 IOPS가 낮은 동안 백업 창이 열리도록 설정합니다. 이때 백업이 데이터베이스 사용에 최소한의 영향을 미칩니다.
-
데이터베이스 작업량으로 인해 프로비저닝한 I/O보다 많이 필요할 경우 장애 조치 또는 데이터베이스 오류가 발생한 후에 복구 속도가 느려집니다. DB 인스턴스의 I/O 용량을 늘리려면 다음 중 일부 항목이나 모든 항목을 수행하십시오.
I/O 용량이 높은 다른 DB 인스턴스 클래스로 마이그레이션합니다.
필요한 증분 양에 따라 마그네틱 스토리지를 범용 또는 프로비저닝된 IOPS 스토리지로 변환합니다. 사용 가능한 스토리지 유형에 대한 자세한 내용은 Amazon RDS 스토리지 유형 단원을 참조하십시오.
프로비저닝된 IOPS 스토리지로 변환할 경우 프로비저닝된 IOPS에 최적화된 DB 인스턴스 클래스를 사용해야 합니다. 프로비저닝된 IOPS에 대한 자세한 내용은 프로비저닝된 IOPS SSD 스토리지 단원을 참조하십시오.
이미 프로비저닝된 IOPS 스토리지를 사용하고 있는 경우 추가 처리 용량을 프로비저닝합니다.
-
클라이언트 애플리케이션이 DB 인스턴스의 DNS(Domain Name Service) 데이터를 캐시하는 경우 TTL(Time-to-Live) 값을 30초 미만으로 설정합니다. 장애 조치 후에 DB 인스턴스의 기본 IP 주소가 변경될 수 있습니다. DNS 데이터를 장기간 캐시하면 연결이 실패할 수 있습니다. 애플리케이션이 더 이상 사용되지 않는 IP 주소에 연결을 시도할 수 있습니다.
-
DB 인스턴스의 장애 조치를 테스트하여 특정 사용 사례 절차에 소요되는 시간을 파악하세요. 또한 장애 조치를 테스트하여 DB 인스턴스에 액세스하는 애플리케이션이 장애 조치 후 자동으로 새 DB 인스턴스에 연결되는지 확인하세요.
DB 인스턴스 RAM 권장 사항
작업 집합이 거의 완전히 메모리에 상주하도록 RAM을 충분히 할당하는 것이 Amazon RDS 성능 모범 사례에 따르는 길입니다. 작업 집합은 인스턴스에서 자주 사용되는 데이터 및 인덱스입니다. DB 인스턴스를 많이 사용할수록 작업 집합이 커집니다.
작업 집합이 거의 전부 메모리에 있는지 확인하려면 (Amazon CloudWatch를 사용하여) DB 인스턴스에 작업 부하가 걸려 있는 동안 ReadIOPS 메트릭을 확인하십시오. ReadIOPS의 값은 작고 안정적이어야 합니다. 경우에 따라 DB 인스턴스 클래스를 RAM이 더 많은 클래스로 스케일 업하면 ReadIOPS가 대폭 떨어질 수 있습니다. 이러한 경우 작업 세트가 메모리에 거의 완전히 저장되지 않았습니다. 규모 조정 작업 후 ReadIOPS가 더 이상 대폭 떨어지지 않을 때까지 계속 확장합니다. 그렇지 않으면 ReadIOPS가 매우 작은 양으로 감소됩니다. DB 인스턴스의 메트릭 모니터링에 대한 자세한 내용은 Amazon RDS 콘솔에서 지표 보기 단원을 참조하십시오.
데이터베이스 엔진 버전을 최신 상태로 유지
데이터베이스 엔진 버전을 정기적으로 업그레이드하여 보안, 성능 및 규정 준수를 유지합니다. Amazon RDS는 보안 패치, 성능 향상 및 새로운 기능을 포함하는 새로운 마이너 및 메이저 버전을 릴리스합니다. 오래된 데이터베이스 엔진을 실행하면 워크로드가 알려진 취약성, 호환성 문제에 노출되고 AWS 및 데이터베이스 공급업체의 지원이 감소할 수 있습니다.
중단을 최소화하려면 업그레이드를 계획할 때 다음 사항을 고려합니다.
-
스테이징 환경에서 테스트 - 프로덕션 데이터베이스를 업그레이드하기 전에 워크로드에 대해 새 버전을 검증합니다.
-
Amazon RDS 관리형 업그레이드 사용 - 더 쉬운 패치 적용을 위해 마이너 버전 자동 업그레이드를 사용 설정합니다.
-
메이저 버전 업그레이드 예약 - 릴리스 정보를 검토하고, 애플리케이션 호환성을 테스트하고, 제어된 업그레이드 기간을 계획합니다.
정기적인 업그레이드를 통해 데이터베이스를 안전하게 유지하고 최적화하며 AWS 모범 사례에 맞게 조정할 수 있습니다.
AWS 데이터베이스 드라이버
애플리케이션 연결에 AWS 드라이버 제품군을 사용하는 것이 좋습니다. 더 빠른 전환 및 장애 조치 시간, AWS Secrets Manager, AWS Identity and Access Management(IAM) 및 페더레이션 ID를 사용한 인증을 지원하도록 설계된 드라이버입니다. AWS 드라이버는 DB 인스턴스 상태 모니터링과 인스턴스 토폴로지 파악을 통해 새 라이터를 결정합니다. 이 접근 방식은 전환 및 장애 조치 시간을 오픈 소스 드라이버의 경우 수십 초였던 것에 비해 10초 미만으로 단축합니다.
새로운 서비스 기능이 도입됨에 따라 AWS 드라이버 제품군의 목표는 이러한 서비스 기능에 대한 지원을 기본 제공하는 것입니다.
자세한 내용은 AWS 드라이버를 사용하여 DB 인스턴스에 연결 섹션을 참조하세요.
Enhanced Monitoring을 통한 운영 체제 문제 식별
확장 모니터링이 활성화되어 있으면 Amazon RDS는 DB 인스턴스가 실행되는 운영 체제(OS)에 대한 측정치를 실시간으로 제공합니다. 콘솔을 사용하여 DB 인스턴스에 대한 지표를 볼 수 있습니다. 또한 선택한 모니터링 시스템에서 Amazon CloudWatch Logs의 Enhanced Monitoring JSON 출력을 사용할 수 있습니다. Enhanced Monitoring에 대한 자세한 내용은 Enhanced Monitoring을 사용하여 OS 지표 모니터링 단원을 참조하세요.
지표를 통해 성능 문제 식별
리소스 부족이나 기타 일반적인 병목으로 인해 발생하는 성능 문제를 식별하기 위해 Amazon RDS DB 인스턴스에서 사용할 수 있는 지표를 모니터링할 수 있습니다.
성능 지표 보기
다양한 기간 동안의 평균, 최대, 최소 측정값을 보려면 성능 지표를 정기적으로 모니터링해야 합니다. 이렇게 하면 성능이 저하된 시점을 식별할 수 있습니다. 또한 특정 지표 임계값에 대해 Amazon CloudWatch 경보를 설정하여 해당 임계값에 이를 경우 알리도록 할 수 있습니다.
성능 문제를 해결하기 위해서는 시스템의 기준 성능을 파악해야 합니다. DB 인스턴스를 설정하고 일반적인 워크로드로 실행하는 경우 모든 성능 지표의 평균, 최댓값, 최솟값을 캡처합니다. 다양한 간격(예: 1시간, 24시간, 1주, 2주)으로 캡처하세요. 그러면 무엇이 정상인지를 알 수 있습니다. 이렇게 하면 작업의 최고 피크와 최저 피크 시간을 비교할 수 있습니다. 그런 다음 이 정보를 사용하여 성능이 표준 수준 이하로 떨어진 때를 식별할 수 있습니다.
다중 AZ DB 클러스터를 사용하는 경우 리더 DB 인스턴스에서 가장 최근에 적용된 트랜잭션과 라이터 DB 인스턴스에서 가장 최근 트랜잭션 사이의 시간 차이를 모니터링합니다. 이 차이를 복제본 지연이라고 부릅니다. 자세한 내용은 복제본 지연 시간 및 다중 AZ DB 클러스터 섹션을 참조하세요.
성능 개선 도우미 대시보드에서 결합된 성능 개선 도우미 및 CloudWatch 지표를 확인하고 DB 인스턴스를 모니터링할 수 있습니다. 이 모니터링 보기를 사용하려면 DB 인스턴스에서 성능 개선 도우미가 켜져 있어야 합니다. 이 모니터링에 대한 자세한 내용은 성능 개선 도우미 대시보드와 결합된 지표 보기 섹션을 참조하세요.
특정 기간에 대한 성과 분석 보고서를 생성하고 식별된 인사이트와 문제 해결을 위한 권장 사항을 볼 수 있습니다. 자세한 내용은 성능 개선 도우미에서 성과 분석 보고서 생성 섹션을 참조하세요.
성능 지표를 보려면
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. 탐색 창에서 데이터베이스를 선택한 후 DB 인스턴스를 선택합니다.
모니터링을 선택합니다.
대시보드는 성능 지표를 제공합니다. 지표는 기본적으로 지난 3시간 동안의 정보를 표시합니다.
오른쪽 상단의 숫자 버튼을 사용하여 다른 페이지의 지표를 보거나, 설정을 조정하여 더 많은 지표를 표시합니다.
다른 날짜의 데이터를 보려면 성능 지표의 시간 범위를 조정합니다. [Statistic], [Time Range] 및 [Period] 값을 변경하여 표시되는 정보를 조정할 수 있습니다. 예를 들어 지난 2주 동안 각 날짜의 지표에 대한 피크 값을 보고 싶을 수 있습니다. 그렇다면 통계를 최대로, 시간 범위를 지난 2주로, 기간을 일로 설정합니다.
CLI 또는 API를 사용하여 성능 지표를 볼 수도 있습니다. 자세한 내용은 Amazon RDS 콘솔에서 지표 보기 섹션을 참조하세요.
CloudWatch 경보를 설정하려면
-
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 데이터베이스를 선택한 후 DB 인스턴스를 선택합니다.
-
Logs & events(로그 및 이벤트)를 선택합니다.
-
CloudWatch 경보 섹션에서 경보 생성을 선택합니다.
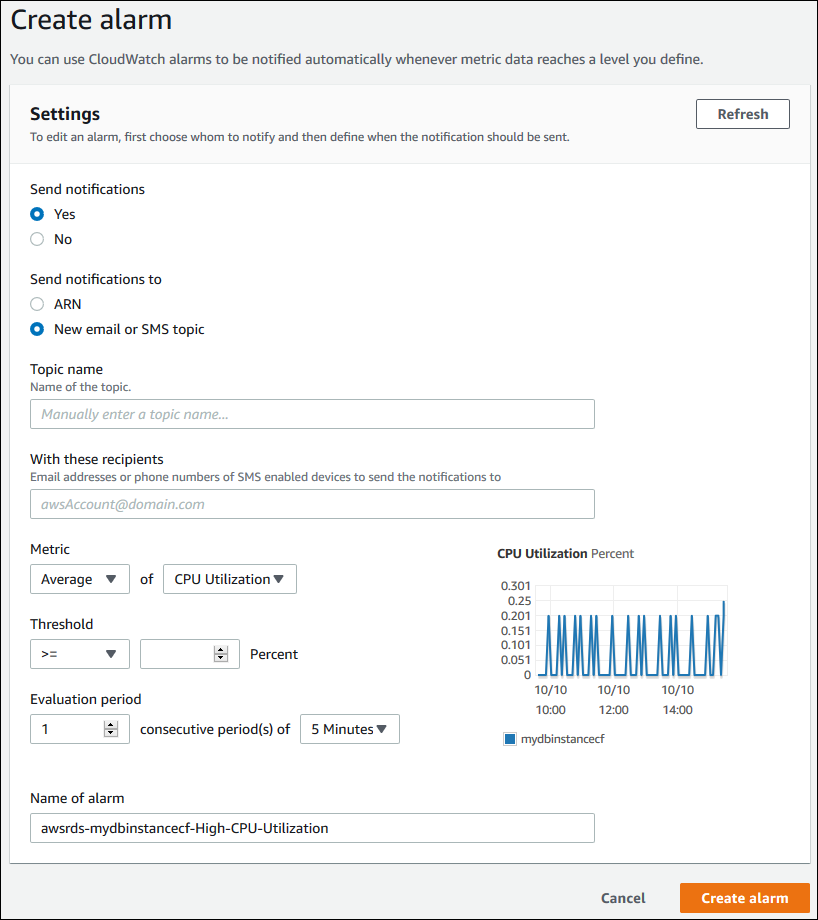
-
Send notifications(알림 보내기)에서 예를 선택하고 알림 받을 대상에서 New email or SMS topic(새로운 이메일 또는 SMS 주제)을 선택합니다.
-
주제 이름에 알림의 이름을 입력하고, 수신자에 이메일 주소 혹은 전화번호 목록을 쉼표로 구분하여 입력합니다.
-
지표에서 설정할 경보 통계 및 지표를 선택합니다.
-
임계값에서 지표가 임계값보다 크거나 작아야 하는지 아니면 임계값과 같아야 하는지 지정하고 임계값을 지정합니다.
-
평가 기간은 경보에 대한 평가 기간을 선택합니다. consecutive period(s) of(연속 기간) 상자에서 임계값이 얼마나 유지되어야 경보를 발생할지 기간을 선택합니다.
-
경보 이름에 경보 이름을 입력합니다.
-
[Create Alarm]을 선택합니다.
CloudWatch 경보 섹션에 경보가 나타납니다.
성능 지표 평가
한 개의 DB 인스턴스에는 서로 다른 많은 카테고리의 지표가 있으며, 허용되는 값을 결정하는 방법은 지표에 따라 다릅니다.
CPU
CPU 사용률 – 사용된 컴퓨터 처리 용량의 백분율입니다.
메모리
-
여유 메모리 – DB 인스턴스에서 사용 가능한 RAM을 바이트 단위로 나타냅니다. [Monitoring] 탭 지표의 붉은색 선이 CPU, 메모리 및 스토리지 지표의 75%에 표시됩니다. 인스턴스 메모리 소비가 주기적으로 이 선을 넘는 경우 이는 워크로드를 확인하거나 인스턴스를 업그레이드해야 함을 나타냅니다.
스왑 사용량 – DB 인스턴스에서 사용하는 스왑 공간을 바이트 단위로 나타냅니다.
디스크 공간
여유 스토리지 공간 – DB 인스턴스에서 현재 사용하지 않고 있는 디스크 공간을 메가바이트 단위로 나타냅니다.
입력/출력 작업
IOPS 읽기, IOPS 쓰기 – 초당 디스크 읽기 또는 쓰기 작업의 평균 횟수입니다.
읽기 지연 시간, 쓰기 지연 시간 – 읽기 또는 쓰기 작업의 평균 시간(밀리초)입니다.
읽기 처리량, 쓰기 처리량 – 초당 디스크에서 읽거나 디스크에 쓴 평균 크기(메가바이트)입니다.
대기열 길이 – 디스크에 쓰기 위해 또는 디스크에서 읽기 위해 대기 중인 I/O 작업의 수입니다.
네트워크 트래픽
네트워크 수신 처리량, 네트워크 전송 처리량 – DB 인스턴스에 대한 수신 또는 전송 네트워크 트래픽 속도(초당 바이트)입니다.
데이터베이스 연결
DB 연결 – DB 인스턴스에 연결된 클라이언트 세션의 수입니다.
사용 가능한 각 성능 지표에 대한 자세한 내용은 Amazon CloudWatch로 Amazon RDS 지표 모니터링 단원을 참조하십시오.
일반적으로 성능 지표에 허용되는 값은 기준이 무엇인지 그리고 애플리케이션 무엇을 수행하는지에 따라 다릅니다. 기준과의 일관된 차이 또는 추세를 조사하십시오. 특정 지표 유형에 대한 참고 정보는 다음과 같습니다.
CPU 또는 RAM 사용량이 많음 - CPU 또는 RAM 사용량 값을 높게 설정하는 것이 적합할 수 있습니다. 예를 들어 해당 애플리케이션의 목표(처리량 또는 동시성)와 일치하고 예상되는 결과라면 그럴 수 있습니다.
디스크 공간 사용량 – 총 디스크 용량의 85퍼센트 이상이 계속 사용될 경우 디스크 공간 사용량을 검사합니다. 인스턴스에서 데이터를 삭제할 수 있는지 또는 다른 시스템에 데이터를 아카이브하여 공간을 확보할 수 있는지 확인합니다.
네트워크 트래픽 – 네트워크 트래픽의 경우 시스템 관리자에게 문의하여 해당 도메인 네트워크 및 인터넷 연결의 기대 처리량을 확인합니다. 처리량이 기대값보다 항상 낮으면 네트워크 트래픽을 검사합니다.
데이터베이스 연결 – 인스턴스 성능 저하 및 응답 시간 지연과 함께 사용자 연결 수가 많을 경우 데이터베이스 연결 제한을 고려해 봅니다. DB 인스턴스에 대한 최적의 사용자 연결 수는 해당 인스턴스 클래스와, 수행하는 작업의 복잡성에 따라 다릅니다. 데이터베이스 연결 수를 지정하려면 DB 인스턴스를 파라미터 그룹과 연결합니다. 이 그룹에서 사용자 연결 파라미터를 0(무제한) 이외의 값으로 설정합니다. 기존 파라미터 그룹을 사용하거나 새로 하나 만들 수 있습니다. 자세한 내용은 Amazon RDS의 파라미터 그룹 섹션을 참조하세요.
IOPS 지표 – IOPS 지표의 기대값은 디스크 사양 및 서버 구성에 따라 다르므로 해당 기준에 일반적인 값을 파악합니다. 값이 기준과 계속 차이가 나는지 검사합니다. 최적의 IOPS 성능을 위해, 일반적인 작업 세트가 메모리에 적합하고 읽기 및 쓰기 작업을 최소화하는지 확인합니다.
성능 지표와 관련된 문제의 경우 성능을 개선하기 위한 첫 번째 단계는 가장 많이 사용되고 비용이 가장 많이 드는 쿼리를 튜닝하는 것입니다. 그러한 쿼리를 튜닝하여 시스템 리소스에 대한 부담이 낮아지는지 확인하세요. 자세한 내용은 쿼리 튜닝 섹션을 참조하세요.
쿼리가 조정되었는데도 문제가 지속되면 Amazon RDS DB 인스턴스 클래스를 업그레이드하는 것을 고려해 보세요. 문제와 관련된 리소스(CPU, RAM, 디스크 공간, 네트워크 대역폭, I/O 용량)를 추가하여 업그레이드할 수 있습니다.
쿼리 튜닝
DB 인스턴스 성능을 향상하는 가장 좋은 방법 중 하나는 일반적으로 가장 많이 사용하는 쿼리와 리소스를 가장 많이 사용하는 쿼리를 튜닝하는 것입니다. 이때 실행 비용이 절감되도록 튜닝합니다. 쿼리 개선에 대한 자세한 내용은 다음 리소스를 사용하세요.
-
MySQL – MySQL 설명서에서 SELECT 문 최적화
를 참조하세요. 추가 쿼리 튜닝 리소스에 대한 내용은 MySQL 성능 튜닝 및 최적화 리소스 를 참조하세요. -
Oracle – Oracle Database 설명서의 데이터베이스 SQL 튜닝 안내서
를 참조하세요. -
SQL Server – Microsoft 설명서의 쿼리 분석
을 참조하세요. 또한 Microsoft 설명서의 시스템 동적 관리 보기 에서 설명한 실행 관련, 인덱스 관련 및 I/O 관련 데이터 관리 보기(DMV)를 사용하여 SQL Server 쿼리 문제를 해결할 수도 있습니다. 쿼리 튜닝의 공통적인 부분은 효율적인 인덱스를 만드는 것입니다. DB 인스턴스의 인덱스 개선에 대한 자세한 내용은 Microsoft 설명서의 데이터베이스 엔진 튜닝 관리자
를 참조하세요. RDS for SQL Server에서 튜닝 관리자 사용에 대한 자세한 내용은 데이터베이스 엔진 튜닝 관리자를 사용하여 Amazon RDS for SQL Server DB 인스턴스의 데이터베이스 워크로드 분석 섹션을 참조하세요. -
PostgreSQL – 쿼리 계획을 분석하는 방법은 PostgreSQL 설명서에서 EXPLAIN 사용
을 참조하세요. 이 정보를 참조하여 쿼리 성능을 높이기 위해 쿼리나 기본 테이블을 수정할 수 있습니다. 최상의 성능을 위해 쿼리에 조인을 지정하는 방법에 대한 자세한 내용은 명시적 JOIN 절을 사용하여 플래너 제어
를 참조하세요. -
MariaDB – MariaDB 설명서에서 쿼리 최적화
를 참조하세요.
MySQL 작업 모범 사례
MySQL 데이터베이스의 테이블 크기와 테이블 개수는 모두 성능에 영향을 미칠 수 있습니다.
테이블 크기
일반적으로 파일 크기에 대한 운영 체제 제약 조건에 따라 MySQL 데이터베이스의 유효 최대 테이블 크기가 결정됩니다. 즉, 이 한도는 일반적으로 내부 MySQL 제약 조건에 의해 결정되지 않습니다.
MySQL DB 인스턴스에서 데이터베이스의 테이블이 너무 크게 늘어나지 않도록 합니다. 스토리지는 일반적으로 64TiB로 제한되기는 하지만 프로비저닝 스토리지 제한에 따라 MySQL 테이블 파일의 최대 크기를 16TB로 제한합니다. 파일 크기가 16TB 제한을 넘지 않도록 라지 테이블을 분할합니다. 이 접근 방식을 수행하면 성능 및 복구 시간도 향상할 수 있습니다. 자세한 내용은 Amazon RDS의 MySQL 파일 크기 제한 섹션을 참조하세요.
크기가 100GB 이상인 매우 큰 테이블은 읽기 및 쓰기(DML 문 포함, 특히 DDL 문 포함)의 성능에 부정적인 영향을 미칠 수 있습니다. larges 테이블의 인덱스는 선택 성능을 크게 높일 수 있지만 DML 문의 성능을 저하시킬 수도 있습니다. ALTER TABLE과 같은 DDL 문은 큰 테이블에 대해 상당히 느려질 수 있습니다. 해당 작업은 경우에 따라 테이블을 완전히 다시 작성할 수 있기 때문입니다. 이러한 DDL 문은 작업을 실행하는 동안 테이블을 잠글 수 있습니다.
MySQL의 읽기 및 쓰기에 필요한 메모리 용량은 작업에 관련된 테이블에 따라 달라집니다. 적어도 많이 사용되는 테이블의 인덱스를 유지하기에는 충분한 RAM을 확보하는 것이 좋습니다. 데이터베이스에서 가장 큰 10개의 테이블과 인덱스를 찾으려면 다음 쿼리를 사용합니다.
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
테이블 수
기본 파일 시스템에서는 테이블을 나타내는 파일 수가 제한될 수 있습니다. 그러나 MySQL에는 테이블 수에 제한이 없습니다. 그럼에도 불구하고 MySQL InnoDB 스토리지 엔진의 총 테이블 수는 해당 테이블의 크기에 관계없이 성능 저하의 원인이 될 수 있습니다. 운영 체제에 미치는 영향을 최소화하기 위해 동일한 MySQL DB 인스턴스의 여러 데이터베이스에 걸쳐 테이블을 분할할 수 있습니다. 이렇게 하면 디렉터리의 파일 수가 제한되지만 전반적인 문제는 해결되지 않습니다.
많은 수의 테이블(10,000개 이상)로 인해 성능 저하가 발생하는 경우, 이는 MySQL이 스토리지 파일을 열고 닫는 것을 비롯하여 스토리지 파일을 작업에 사용하기 때문에 발생합니다. 이 문제를 해결하기 위해 table_open_cache 및 table_definition_cache 파라미터의 크기를 늘릴 수 있습니다. 하지만 이들 파라미터의 값을 늘리면 MySQL이 사용하는 메모리 용량이 크게 늘어날 수 있으며 가용 메모리를 전부 사용하게 될 수도 있습니다. 자세한 내용은 MySQL 설명서의 MySQL에서 테이블을 열고 닫는 방법
또한 테이블이 너무 많으면 MySQL 시작 시간에 크게 영향을 미칠 수 있습니다. 정상 종료 및 재시작과 충돌 복구가 모두 영향을 받을 수 있습니다. 특히 MySQL 8.0 이전 버전에서는 더욱 그렇습니다.
DB 인스턴스의 모든 데이터베이스에 걸쳐 총 테이블 수를 1만 개 미만으로 유지하는 것이 좋습니다. MySQL 데이터베이스에 많은 수의 테이블이 있는 사용 사례는 MySQL 8.0의 테이블 백만 개
스토리지 엔진
Amazon RDS for MySQL의 특정 시점으로 복구 및 스냅샷 복원 기능을 사용하려면 충돌 복구 가능 스토리지 엔진이 필요합니다. 이러한 기능은 InnoDB 스토리지 엔진에만 지원됩니다. MySQL은 다양한 기능을 가진 여러 스토리지 엔진을 지원하지만, 모든 엔진이 충돌 복구와 데이터 내구성에 최적화되어 있지는 않습니다. 예를 들어 MyISAM 스토리지 엔진은 안정적인 충돌 복구를 지원하지 않으며, 이로 인해 특정 시점으로 복구 또는 스냅샷 복원이 의도한 대로 작동하지 못할 수 있습니다. 그 결과 충돌 후 MySQL을 다시 시작하면 데이터가 손실되거나 손상될 수 있습니다.
InnoDB는 Amazon RDS에서 MySQL DB 인스턴스용으로 권장되고 지원되는 스토리지 엔진입니다. InnoDB 인스턴스는 Aurora로 마이그레이션할 수 있지만, MyISAM 인스턴스는 마이그레이션할 수 없습니다. 하지만 MyISAM은 강력한 전체 텍스트 검색 기능이 필요한 경우 InnoDB보다 나은 성능을 발휘합니다. 그래도 Amazon RDS와 함께 MyISAM을 사용하도록 선택할 경우 지원되지 않는 MySQL 스토리지 엔진에 대한 자동 백업에 개략적으로 설명되어 있는 단계를 따르면 특정한 시나리오에서 스냅샷 복원 기능에 유용할 수 있습니다.
기존 MyISAM 테이블을 InnoDB 테이블로 변환하려면 MySQL 설명서의 MyISAM에서 InnoDB로 테이블 변환
또한 연동 스토리지 엔진은 현재 Amazon RDS for MySQL에서 지원되지 않습니다.
MariaDB 작업 모범 사례
MariaDB 데이터베이스의 테이블 크기와 테이블 개수는 모두 성능에 영향을 미칠 수 있습니다.
테이블 크기
일반적으로 파일 크기에 대한 운영 체제 제약 조건에 따라 MariaDB 데이터베이스의 유효 최대 테이블 크기가 결정됩니다. 즉, 이 한도는 일반적으로 내부 MariaDB 제약 조건에 의해 결정되지 않습니다.
MariaDB DB 인스턴스에서 데이터베이스의 테이블이 너무 크게 늘어나지 않도록 합니다. 스토리지는 일반적으로 64TiB로 제한되기는 하지만 프로비저닝 스토리지 제한에 따라 MariaDB 테이블 파일의 최대 크기를 16TB로 제한합니다. 파일 크기가 16TB 제한을 넘지 않도록 라지 테이블을 분할합니다. 이 접근 방식을 수행하면 성능 및 복구 시간도 향상할 수 있습니다.
크기가 100GB 이상인 매우 큰 테이블은 읽기 및 쓰기(DML 문 포함, 특히 DDL 문 포함)의 성능에 부정적인 영향을 미칠 수 있습니다. larges 테이블의 인덱스는 선택 성능을 크게 높일 수 있지만 DML 문의 성능을 저하시킬 수도 있습니다. ALTER TABLE과 같은 DDL 문은 큰 테이블에 대해 상당히 느려질 수 있습니다. 해당 작업은 경우에 따라 테이블을 완전히 다시 작성할 수 있기 때문입니다. 이러한 DDL 문은 작업을 실행하는 동안 테이블을 잠글 수 있습니다.
MariaDB의 읽기 및 쓰기에 필요한 메모리 용량은 작업에 관련된 테이블에 따라 달라집니다. 적어도 많이 사용되는 테이블의 인덱스를 유지하기에는 충분한 RAM을 확보하는 것이 좋습니다. 데이터베이스에서 가장 큰 10개의 테이블과 인덱스를 찾으려면 다음 쿼리를 사용합니다.
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
테이블 수
기본 파일 시스템에서는 테이블을 나타내는 파일 수가 제한될 수 있습니다. 그러나 MariaDB에는 테이블 수에 제한이 없습니다. 그럼에도 불구하고 MariaDB InnoDB 스토리지 엔진의 총 테이블 수는 해당 테이블의 크기에 관계없이 성능 저하의 원인이 될 수 있습니다. 운영 체제에 미치는 영향을 최소화하기 위해 동일한 MariaDB DB 인스턴스의 여러 데이터베이스에 걸쳐 테이블을 분할할 수 있습니다. 이렇게 하면 디렉터리의 파일 수가 제한되지만 전반적인 문제는 해결되지 않습니다.
많은 수의 테이블(1만 개 이상)로 인해 성능 저하가 발생하는 경우, 이는 MariaDB가 스토리지 파일을 작업에 사용하기 때문에 발생합니다. 이 작업에는 MariaDB 스토리지가 파일을 열고 닫는 작업이 포함됩니다. 이 문제를 해결하기 위해 table_open_cache 및 table_definition_cache 파라미터의 크기를 늘릴 수 있습니다. 하지만 이들 파라미터의 값을 늘리면 MariaDB가 사용하는 메모리 용량이 크게 늘어날 수 있으며 사용 가능한 메모리를 모두 사용할 수도 있습니다. 자세한 내용은 MariaDB 설명서의 table_open_cache 최적화
또한 테이블이 너무 많으면 MariaDB 시작 시간에 크게 영향을 미칠 수 있습니다. 정상 종료 및 재시작과 충돌 복구가 모두 영향을 받을 수 있습니다. DB 인스턴스의 모든 데이터베이스에 걸쳐 총 테이블 수를 1만 개 미만으로 유지하는 것이 좋습니다.
스토리지 엔진
Amazon RDS for MariaDB의 특정 시점으로 복구 및 스냅샷 복원 기능을 사용하려면 충돌 복구 가능 스토리지 엔진이 필요합니다. MariaDB는 다양한 기능을 가진 여러 스토리지 엔진을 지원하지만, 모든 엔진이 충돌 복구와 데이터 내구성에 최적화되어 있지는 않습니다. 예를 들어, Aria가 충돌 안정성을 개선한 MyISAM 대체 스토리지 엔진이지만, 여전히 특정 시점으로 복구 또는 스냅샷 복원이 의도한 대로 작동하지 못할 수 있습니다. 그 결과 충돌 후 MariaDB를 다시 시작하면 데이터가 손실되거나 손상될 수 있습니다. InnoDB는 Amazon RDS에서 MariaDB DB 인스턴스용으로 권장되고 지원되는 스토리지 엔진입니다. 그래도 Amazon RDS와 함께 Aria를 사용하도록 선택할 경우 지원되지 않는 MariaDB 스토리지 엔진에 대한 자동 백업에 개략적으로 설명되어 있는 단계를 따르면 특정한 시나리오에서 스냅샷 복원 기능에 유용할 수 있습니다.
기존 MyISAM 테이블을 InnoDB 테이블로 변환하려면 MariaDB 설명서의 MyISAM에서 InnoDB로 테이블 변환
Oracle 작업의 모범 사례
Amazon RDS for Oracle 작업의 모범 사례에 대한 자세한 내용은 Amazon Web Services에서 Oracle Database 실행의 모범 사례를 참조하세요.
2020 AWS 가상 워크숍에는 Amazon RDS에서 프로덕션 Oracle 데이터베이스를 실행하는 방법에 대한 프레젠테이션이 포함되어 있습니다. 프레젠테이션 비디오는 여기에서 볼 수 있습니다:
PostgreSQL로 작업하기 위한 모범 사례
RDS for PostgreSQL로 성능을 향상할 수 있는 두 가지 중요한 영역 중 하나는 DB 인스턴스에 데이터를 로드할 때입니다. 또 다른 하나는 PostgreSQL Autovacuum 기능을 사용할 때입니다. 다음 섹션에서는 이런 영역에 대해 권장하는 모범 사례를 다룹니다.
Amazon RDS에서 다른 일반적인 PostgreSQL DBA 태스크를 구현하는 방법에 대한 자세한 내용은 Amazon RDS for PostgreSQL의 일반적인 DBA 태스크 섹션을 참조하세요.
PostgreSQL DB 인스턴스에 데이터 로드
Amazon RDS PostgreSQL DB 인스턴스에 데이터를 로드할 때 DB 인스턴스 설정과 DB 파라미터 그룹 값을 수정합니다. 가장 효율적으로 DB 인스턴스에 데이터를 가져오도록 설정합니다.
DB 인스턴스 설정을 다음과 같이 수정합니다.
-
DB 인스턴스 백업 비활성화(backup_retention을 0으로 설정)
-
Multi-AZ 비활성화
다음 설정을 포함하도록 DB 파라미터 그룹을 수정합니다. 또한 파라미터 설정을 테스트하여 DB 인스턴스에 가장 효율적인 설정을 찾습니다.
-
maintenance_work_mem파라미터의 값을 늘립니다. PostgreSQL 리소스 사용 파라미터에 대한 자세한 내용은 PostgreSQL 설명서를 참조하세요. -
미리 쓰기(WAL) 로그에 대한 쓰기 수를 줄이도록
max_wal_size및checkpoint_timeout파라미터의 값을 늘립니다. -
synchronous_commit파라미터 비활성화 -
PostgreSQL autovacuum 파라미터를 비활성화합니다.
-
가져오려는 테이블 모두가 로깅되는지 확인합니다. 로깅되지 않는 테이블에 저장된 데이터는 장애 조치 중에 손실될 수 있습니다. 자세한 내용은 로그되지 않은 테이블 생성
을 참조하세요.
이런 설정과 함께 pg_dump -Fc(압축) 또는 pg_restore -j(병렬) 명령을 사용합니다.
로드 작업이 완료되면 DB 인스턴스와 DB 파라미터를 일반 설정으로 되돌립니다.
PostgreSQL Autovacuum 기능 사용
PostgreSQL 데이터베이스용 autovacuum 기능은 PostgreSQL DB 인스턴스의 상태를 유지 관리하는 데 사용할 것을 강력히 권장하는 중요한 기능입니다. Autovacuum은 VACUUM 및 ANALYZE 명령의 실행을 자동화합니다. PostgreSQL에서는 autovacuum을 반드시 사용해야 하며 Amazon RDS에서는 필수 사항은 아니지만 훌륭한 성능을 달성하는 데 매우 중요한 기능입니다. 이 기능은 모든 새로운 Amazon RDS for PostgreSQL DB 인스턴스에 대해 기본적으로 활성화되며, 관련 구성 파라미터는 적절히 기본적으로 설정됩니다.
데이터베이스 관리자는 이 유지 관리 작업을 파악하고 이해할 필요가 있습니다. Autovacuum에 대한 PostgreSQL 설명서는 Autovacuum 데몬
Autovacuum은 "리소스"를 일정 부분 사용하는 작업하지만, 백그라운드에서 작동하며 사용자 작업에 최대한 많은 리소스가 할당되도록 합니다. Autovacuum이 활성화되어 있을 때는 업데이트되거나 삭제된 튜플 수가 많은 테이블이 있는지 확인합니다. 또한 이 기능은 트랜잭션 ID 랩어라운드로 인해 매우 오래된 데이터가 손실되지 않도록 보호합니다. 자세한 내용은 트랜잭션 ID 랩어라운드 실패 방지
Autovacuum을 더 나은 성능을 위해 줄일 수 있는 높은 오버헤드 작업으로 생각하면 안 됩니다. 오히려, autovacuum을 실행하지 않으면 업데이트 및 삭제 속도가 빠른 테이블이 시간이 흐르면서 빠르게 성능이 저하됩니다.
중요
Autovacuum을 실행하지 않으면 훨씬 더 많은 주입식 vacuum 작업을 수행하기 위해 결국은 필연적으로 중단될 수 있습니다. 경우에 따라 autovacuum을 지나치게 보수적으로 사용하여 RDS for PostgreSQL DB 인스턴스를 사용할 수 없게 될 수 있습니다. 이러한 경우 PostgreSQL 데이터베이스는 자체 보호를 위해 종료됩니다. 그 시점에서 Amazon RDS는 DB 인스턴스에서 직접 단일 사용자 모드 전체 vacuum을 수행해야 합니다. 이렇게 전체 vacuum을 수행하면 몇 시간 동안 정전이 발생할 수 있습니다. 따라서 기본적으로 활성화되는 autovaccum은 아예 해제하지 않는 것이 좋습니다.
Autovacuum 파라미터에 따라 autovacuum의 작동 시점과 정도가 결정됩니다. autovacuum_vacuum_threshold 및 autovacuum_vacuum_scale_factor 파라미터에 따라 autovacuum 실행 시점이 결정됩니다. autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit 및 autovacuum_cost_delay 파라미터에 따라 autovacuum의 작동 정도가 결정됩니다. Autovacuum에 대한 자세한 정보, Autovacuum의 실행 조건, 필요한 파라미터에 관해서는 PostgreSQL 문서의 일상적인 Vacuuming
다음 쿼리를 통해 table1로 명명된 테이블에 있는 ‘사용되지 않는’ 튜플의 수를 알 수 있습니다.
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
쿼리의 결과는 다음과 같은 내용일 것입니다.
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Amazon RDS for PostgreSQL 모범 사례 동영상
2020 AWS re:Invent 컨퍼런스에는 Amazon RDS에서 PostgreSQL 작업의 새로운 기능과 모범 사례에 대한 프레젠테이션이 포함되었습니다. 프레젠테이션 비디오는 여기에서 볼 수 있습니다:
SQL Server로 작업하기 위한 모범 사례
SQL Server DB 인스턴스를 포함한 Multi-AZ 배포를 위한 모범 사례에는 다음이 포함됩니다.
Amazon RDS RDS DB 이벤트를 사용하여 장애 조치를 모니터링합니다. 예를 들어 DB 인스턴스가 장애 조치할 때 문자 메시지 또는 이메일로 알림 서비스를 받을 수 있습니다. Amazon RDS 이벤트에 대한 자세한 내용은 Amazon RDS 이벤트 알림 작업 단원을 참조하십시오.
애플리케이션이 DNS 값을 캐시하는 경우 TTL(time to live)을 30초 미만으로 설정합니다. TTL을 이렇게 설정하면 장애 조치가 발생할 경우 도움이 됩니다. 장애 조치 시 IP 주소가 바뀔 수 있으며 캐시된 값은 더 이상 사용하지 못할 수 있습니다.
다음 모드에서는 Multi-AZ에 필수적인 트랜잭션 로깅이 해제되므로, 이들 모드를 활성화하지 않는 것이 좋습니다.
-
단순 복구 모드
-
오프라인 모드
-
읽기 전용 모드
-
테스트를 통해 DB 인스턴스를 장애 조치하는 데 얼마나 오래 걸리는지 확인합니다. 장애 조치 시간은 데이터베이스의 유형, 인스턴스 클래스, 사용하는 스토리지 유형에 따라 변할 수 있습니다. 장애 조치가 발생할 경우 작업을 계속 수행할 수 있는 애플리케이션의 능력도 테스트해야 합니다.
장애 조치 시간을 단축하려면 다음을 수행합니다.
워크로드에 대해 충분한 프로비저닝된 IOPS가 할당되어 있는지 확인하십시오. I/O가 부적합하면 장애 조치 시간이 길어질 수 있습니다. 데이터베이스 복구에 I/O가 필요합니다.
더 작은 트랜잭션을 사용하십시오. 데이터베이스 복구는 트랜잭션에 의존하므로, 큰 트랜잭션을 여러 개의 작은 트랜잭션으로 나눌 수 있다면 장애 조치 시간이 단축될 것입니다.
장애 조치 중에 지연 시간이 증가할 것이라는 점을 고려하십시오. 장애 조치 프로세스의 일부로서, Amazon RDS는 데이터를 새 대기 인스턴스로 자동으로 복제합니다. 이 복제는 새 데이터가 서로 다른 두 DB 인스턴스로 커밋되고 있음을 의미합니다. 따라서 대기 DB 인스턴스가 새 기본 DB 인스턴스를 따라잡을 때까지 약간의 지연 시간이 발생할 수 있습니다.
모든 가용 영역에 애플리케이션을 배포합니다. 한 가용 영역이 다운되더라도 다른 가용 영역에 있는 애플리케이션을 계속 사용할 수 있습니다.
SQL Server의 다중 AZ 배포를 사용하여 작업할 때, Amazon RDS가 인스턴스에 있는 모든 SQL Server 데이터베이스의 복제본을 생성합니다. 특정 데이터베이스의 보조 복제본이 생기지 않도록 하려면 해당 데이터베이스에 대해 다중 AZ를 사용하지 않는 별개의 DB 인스턴스를 설정합니다.
Amazon RDS for SQL Server 모범 사례 동영상
2019년 AWS re:Invent 컨퍼런스에는 Amazon RDS에서 SQL Server 작업의 새로운 기능과 모범 사례에 대한 프레젠테이션이 포함되었습니다. 프레젠테이션 비디오는 여기에서 볼 수 있습니다:
DB 파라미터 그룹 작업
DB 파라미터 그룹 변경 내용을 프로덕션 DB 인스턴스에 적용하기 전에 테스트 DB 인스턴스에 적용해 보는 것이 좋습니다. DB 파라미터 그룹에 DB 엔진 파라미터를 잘못 설정하면 성능 저하나 시스템 불안정 등의 의도하지 않은 부작용이 있을 수 있습니다. DB 엔진 파라미터를 수정할 때 항상 주의를 기울이고 DB 파라미터 그룹을 수정하기 전에 DB 인스턴스를 백업하십시오.
DB 인스턴스 백업에 대한 자세한 내용은 데이터 백업, 복원 및 내보내기 단원을 참조하십시오.
DB 인스턴스 생성 자동화 모범 사례
기본 설정된 마이너 버전의 데이터베이스 엔진을 사용하여 DB 인스턴스를 생성하는 것이 Amazon RDS 모범 사례입니다. AWS CLI, Amazon RDS API 또는 AWS CloudFormation을 사용하여 DB 인스턴스 생성을 자동화할 수 있습니다. 이러한 방법을 사용하는 경우 메이저 버전만 지정하면 Amazon RDS에서 기본 설정된 마이너 버전으로 인스턴스가 자동으로 생성됩니다. 예를 들어 PostgreSQL 12.5가 기본 설정된 마이너 버전인 경우 create-db-instance(으)로 버전 12를 지정하면 DB 인스턴스는 버전 12.5가 됩니다.
기본 설정된 마이너 버전을 확인하려면 다음 예에서와 같이 describe-db-engine-versions 옵션을 사용하여 --default-only 명령을 실행하면 됩니다.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
프로그래밍 방식으로 DB 인스턴스를 생성하는 방법에 대한 자세한 내용은 다음 리소스를 참조하세요.
AWS CLI 사용 - create-db-instance
Amazon RDS API – CreateDBInstance 사용
AWS CloudFormation 사용 - AWS::RDS::DBInstance
Amazon RDS의 새로운 비디오 특성
2023 AWS re:Invent 컨퍼런스에는 새 Amazon RDS 특성에 관한 프레젠테이션이 포함되어 있습니다. 프레젠테이션 비디오는 여기에서 볼 수 있습니다:
