Amazon RDS에 대한 다중 AZ 인스턴스 배포
Amazon RDS는 단일 대기 DB 인스턴스와 함께 다중 AZ 배포를 사용하여 DB 인스턴스에 대한 고가용성 및 장애 조치 지원을 제공합니다. 이러한 유형의 배포를 다중 AZ DB 인스턴스 배포라고 합니다. Amazon RDS는 다양한 기술을 통해 장애 조치 지원을 제공합니다. MariaDB, MySQL, Oracle, RDS Custom for SQL Server DB인스턴스용 다중 AZ 배포는 Amazon의 장애 조치 기술을 사용합니다. Microsoft SQL Server DB 인스턴스는 SQL Server 데이터베이스 미러링(DBM) 또는 상시 가동 가용성 그룹(AG)을 사용합니다. 다중 AZ에 대한 SQL Server 버전 지원에 대한 자세한 내용은 Amazon RDS for Microsoft SQL Server의 다중 AZ 배포 섹션을 참조하세요. RDS Custom for SQL Server로 다중 AZ 작업을 수행하는 방법에 대한 내용은 RDS Custom for SQL Server에 대한 다중 AZ 배포 구성 및 관리 섹션을 참조하세요.
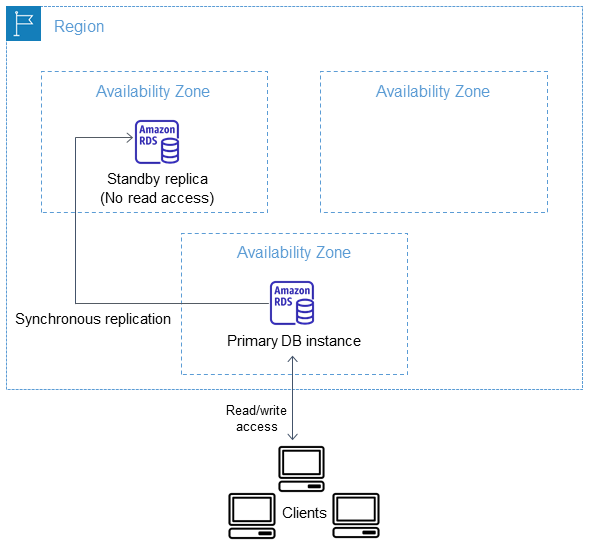
다중 AZ DB 인스턴스 배포에서 Amazon RDS는 자동으로 서로 다른 가용 영역에 동기식 대기 복제본을 프로비저닝하고 유지합니다. 프라이머리 DB 인스턴스는 전체 가용 영역에서 대기 복제본으로 동기식으로 복제되어 시스템 백업 중에 데이터 이중화를 제공하고 대기 시간 급증을 최소화합니다. DB 인스턴스를 고가용성으로 실행하면 계획된 시스템 유지 관리 중 가용성을 높일 수 있습니다. 또한, DB 인스턴스 오류 및 가용 영역 중단이 일어나지 않도록 방지할 수 있습니다. 가용 영역에 대한 자세한 내용은 리전, 가용 영역 및 로컬 영역 섹션을 참조하세요.
참고
고가용성 옵션은 읽기 전용 시나리오에서는 확장 솔루션이 아닙니다. 대기 복제본을 사용하여 읽기 트래픽을 처리할 수 없습니다. 읽기 전용 트래픽을 처리하려면 대신 다중 AZ DB 클러스터 또는 읽기 전용 복제본을 사용해야 합니다. 다중 AZ DB 클러스터에 대한 자세한 내용은 Amazon RDS용 다중 AZ DB 클러스터 배포 섹션을 참조하세요. 읽기 전용 복제본에 대한 자세한 내용은 DB 인스턴스 읽기 전용 복제본 작업을 참조하세요.
RDS 콘솔을 통해 DB 인스턴스 생성 시 다중 AZ를 지정하여 간편하게 다중 AZ DB 인스턴스 배포를 생성할 수 있습니다. 콘솔을 통해 DB 인스턴스를 수정하고 다중 AZ 옵션을 지정하여 기존 DB 인스턴스를 다중 AZ DB 인스턴스 배포로 변환할 수 있습니다. 또한, AWS CLI 또는 Amazon RDS API를 사용하여 다중 AZ DB 인스턴스 배포를 지정할 수도 있습니다. create-db-instance 또는 modify-db-instance CLI 명령을 사용하거나 CreateDBInstance 또는 ModifyDBInstance API 작업을 사용합니다.
RDS 콘솔에 예비 복제본(보조 AZ라고 함)의 가용 영역이 표시됩니다. 또한 describe-db-instances CLI 명령 또는 DescribeDBInstances API 작업을 사용하여 보조 AZ를 찾을 수도 있습니다.
다중 AZ DB 인스턴스 배포를 사용하는 DB 인스턴스는 단일 AZ 배포에 비해 쓰기 및 커밋 대기 시간이 길어질 수 있습니다. 이러한 현상은 동기식 데이터 복제가 발생하기 때문에 일어날 수 있습니다. AWS는 가용 영역 간 지연 시간이 짧은 네트워크 연결을 제공하도록 설계되었지만 배포가 예비 복제본으로 장애 조치될 경우 지연 시간이 변경될 수 있습니다. 프로덕션 워크로드의 경우 빠르고 일관된 성능을 제공할 수 있도록 프로비저닝된 IOPS(초당 입/출력 작업)를 사용하는 것이 좋습니다. DB 인스턴스 클래스에 대한 자세한 내용은 DB 인스턴스 클래스 섹션을 참조하세요.
