신규 고객은 Amazon Forecast를 더 이상 사용할 수 없습니다. Amazon Forecast의 기존 고객은 평소와 같이 서비스를 계속 사용할 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
예측기 정확성 평가
Amazon Forecast는 예측기를 평가하고 예측 생성에 사용할 지표를 선택하는 데 도움이 되는 정확도 지표를 생성합니다. Forecast는 평균 제곱근 오차(RMSE), 가중 분위수 손실(wQL), 평균 절대 백분율 오차(MAPE), 평균 절대 조정 오차(MASE), 가중 절대 백분율 오차(WAPE) 지표를 사용하여 예측기를 평가합니다.
Amazon Forecast는 백테스트를 사용하여 파라미터를 튜닝하고 정확도 지표를 생성합니다. 백테스트 중에 Forecast는 시계열 데이터를 훈련 세트와 테스트 세트의 두 세트로 자동으로 분할합니다. 훈련 세트는 모델을 훈련시킨 다음 테스트 세트의 데이터 포인트에 대한 예측을 생성하는 데 사용됩니다. Forecast는 예측값을 테스트 세트의 관측값과 비교하여 모델의 정확도를 평가합니다.
Forecast를 사용하면 다양한 예측 유형(분위수 예측 세트 및 평균 예측)을 사용하여 예측기를 평가할 수 있습니다. 평균 예측은 점 추정을 제공하는 반면, 분위수 예측은 일반적으로 가능한 결과 범위를 제공합니다.
Python 노트북
예측기 지표 평가에 대한 단계별 지침은 항목 수준 백테스트를 사용한 지표 계산
주제
정확도 지표 해석
Amazon Forecast는 평균 제곱근 오차(RMSE), 가중 분위수 손실(wQL), 평균 가중 분위수 손실(평균 wQL), 평균 절대 조정 오차(MASE), 평균 절대 백분율 오차(MAPE), 가중 절대 백분율 오차(WAPE) 지표를 제공하여 예측기를 평가합니다. Forecast는 전체 예측기에 대한 지표와 함께 각 백테스트 기간의 지표를 계산합니다.
Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 예측기의 정확도 지표를 볼 수 있습니다.
참고
평균 wQL, wQL, RMSE, MASE, MAPE, WAPE 지표의 경우 값이 낮을수록 모델이 우수함을 나타냅니다.
주제
가중 분위수 손실(wQL)
가중 분위수 손실(wQL) 지표는 지정된 분위수에서 모델의 정확도를 측정합니다. 과소 예측과 과대 예측으로 인한 비용이 서로 다를 때 특히 유용합니다. wQL 함수의 가중치(τ)를 설정하면 과소 예측과 과대 예측의 서로 다른 페널티를 자동으로 통합할 수 있습니다.
손실 함수는 다음과 같이 계산됩니다.
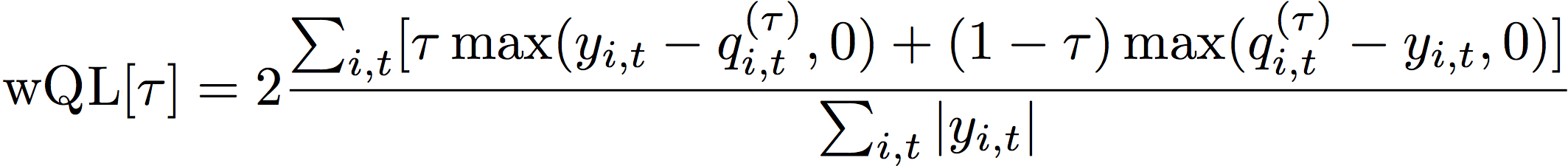
- 위치:
-
τ - 집합 {0.01, 0.02, ..., 0.99}의 분위수
qi,t(τ) - 모델이 예측하는 τ-분위수.
yi,t - 점 (i,t)에서 관측된 값
wQL의 분위수 (τ)는 0.01(P1)에서 0.99(P99)까지일 수 있습니다. 평균 예측을 위한 wQL 지표는 계산할 수 없습니다.
기본적으로 Forecast는 0.1(P10), 0.5(P50), 0.9(P90)에서 wQL을 계산합니다.
-
P10(0.1): 10%의 확률로 참값이 예측값보다 낮을 것으로 기대됩니다.
-
P50(0.5): 50%의 확률로 참값이 예측값보다 낮을 것으로 기대됩니다. 이를 중앙값 예측이라고도 합니다.
-
P90(0.9): 90%의 확률로 참값이 예측값보다 낮을 것으로 기대됩니다.
소매업에서는 재고 부족 비용이 과잉 재고 비용보다 높은 경우가 많으므로 P75(τ = 0.75)로 예측하는 것이 중앙값 분위수 (P50)으로 예측하는 것보다 더 많은 정보를 얻을 수 있습니다. 이 경우 wQL[0.75]는 과소 예측 (0.75)에 더 큰 페널티 가중치를 할당하고 과다 예측 (0.25)에는 더 작은 페널티 가중치를 할당합니다.
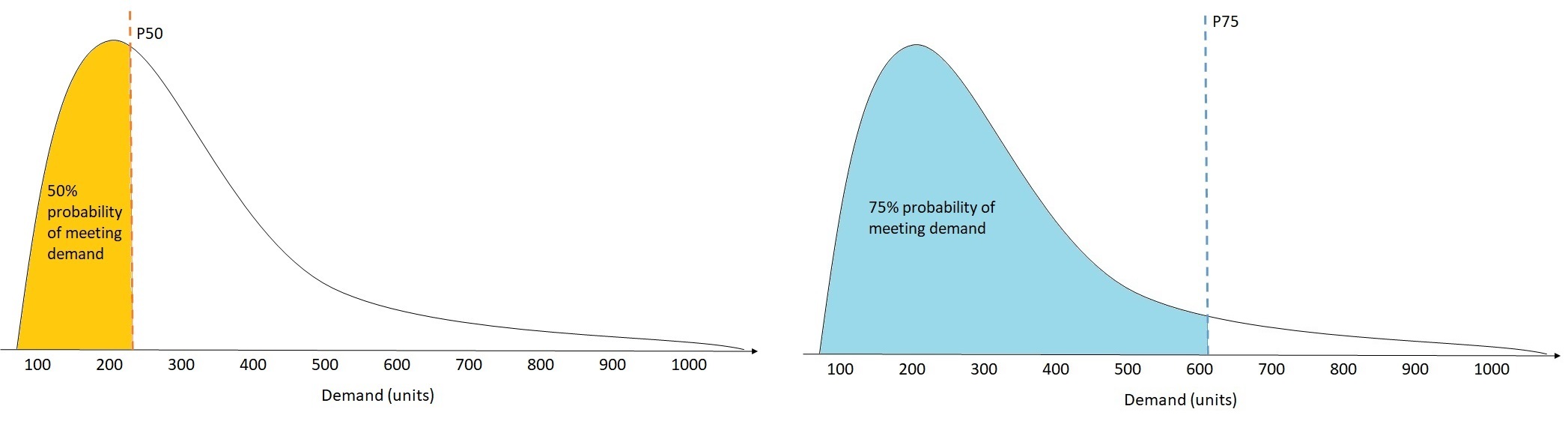
위 그림은 wQL [0.50]과 wQL [0.75]의 서로 다른 수요 예측을 보여줍니다. P75의 예측 값은 P50의 예측 값보다 훨씬 높습니다. P75 예측은 75%의 확률로 수요를 충족시킬 것으로 기대되는 반면 P50 예측은 50%의 확률로 수요를 충족시킬 것으로 기대되기 때문입니다.
모든 항목과 모든 시점에 걸쳐 관측된 값의 합계가 주어진 백테스트 기간에 약 0이면 가중치 분위수 손실 식이 정의되지 않습니다. 이 경우 Forecast는 wQL 식에서 분자인 비가중 분위수 손실을 출력합니다.
또한 Forecast는 지정된 모든 분위수에 대한 가중 분위수 손실의 평균값인 평균 wQL을 계산합니다. 기본적으로 이 값은 wQL[0.10], wQL[0.50], wQL[0.90]의 평균입니다.
가중 절대 백분율 오차(WAPE)
가중 절대 백분율 오차(WAPE)는 관측값으로부터의 예측값의 전체적 편차를 측정합니다. 관측값의 합과 예측값의 합을 구하고 두 값 사이의 오차를 계산함으로써 WAPE를 계산할 수 있습니다. 값이 낮을수록 모델이 더 정확함을 나타냅니다.
주어진 백테스트 기간에 모든 시점과 모든 항목의 관측값의 합이 거의 0이면 가중 절대 백분율 오차 식이 정의되지 않습니다. 이 경우 Forecast는 WAPE 식의 분자인 비가중 절대 오차 합계를 출력합니다.
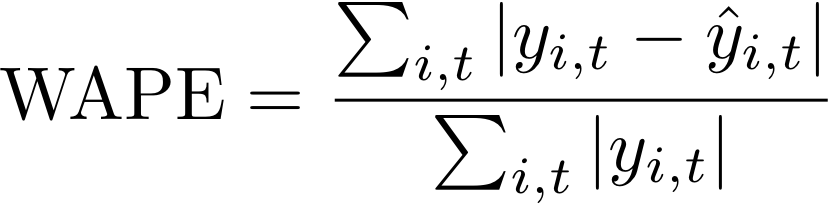
- 위치:
-
yi,t - 점 (i,t)에서 관측된 값
ŷi,t - 점 (i,t)에서 예측된 값
Forecast는 평균 예측을 예측값 ŷi,t로 사용합니다.
WAPE는 제곱 오차 대신 절대 오차를 사용하기 때문에 평균 제곱근 오차(RMSE)보다 이상치에 더 강합니다.
이전에는 Amazon Forecast에서 WAPE 지표를 절대 백분율 평균 오차(MAPE)라고 했고 예측 중앙값(P50)을 예측값으로 사용했습니다. 이제 Forecast는 평균 예측을 사용하여 WAPE를 계산합니다. 아래에 나온 것처럼 wQL[0.5] 지표는 WAPE[median] 지표와 동등합니다.
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
평균 제곱근 오차(RMSE)
평균 제곱근 오차(RMSE) 는 제곱 오차 평균의 제곱근이므로 다른 정확도 지표보다 이상치에 더 민감합니다. 값이 낮을수록 모델이 더 정확함을 나타냅니다.

- 위치:
-
yi,t - 점 (i,t)에서 관측된 값
ŷi,t - 점 (i,t)에서 예측된 값
nT - 테스트 세트의 데이터 포인트 수
Forecast는 평균 예측을 예측값 ŷi,t로 사용합니다. 예측 지표를 계산할 때 nT는 백테스트 기간에 있는 데이터 포인트의 수입니다.
RMSE는 잔차의 제곱 값을 사용하므로 이상치의 영향을 증폭합니다. 큰 예측 오류가 몇 개만 발생해도 비용이 많이 들 수 있는 사용 사례에서는 RMSE가 더 적절한 지표입니다.
2020년 11월 11일 이전에 생성된 예측기는 기본적으로 0.5분위수(P50)를 사용하여 RMSE를 계산했습니다. 이제 Forecast는 평균 예측을 사용합니다.
평균 절대 백분율 오차(MAPE)
평균 절대 백분율 오차(MAPE)는 각 시간 단위의 관측값과 예측값 사이의 백분율 오차의 절대값을 취하여 해당 값의 평균을 구합니다. 값이 낮을수록 모델이 더 정확함을 나타냅니다.
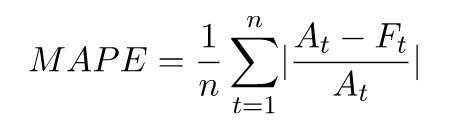
- 위치:
-
At - 점 t에서 관측된 값
Ft - 점 t에서 예측된 값
n - 시계열의 데이터 포인트 수
Forecast는 평균 예측을 예측값 Ft로 사용합니다.
MAPE는 시점 간에 값이 크게 다르고 이상치가 큰 영향을 미치는 경우에 유용합니다.
평균 절대 조정 오차(MASE)
평균 절대 조정 오차(MASE)는 평균 오차를 조정 인자로 나누어 계산합니다. 이 조정 인자는 예측 빈도를 기준으로 선택되는 계절성 값 m에 따라 달라집니다. 값이 낮을수록 모델이 더 정확함을 나타냅니다.
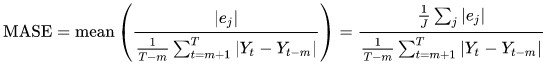
- 위치:
-
Yt - 점 t에서 관측된 값
Yt-m - 점 t-m에서 관측된 값
ej - 점 j에서의 오차(관측값 - 예측값)
m - 계절성 값
Forecast는 평균 예측을 예측값으로 사용합니다.
MASE는 본질적으로 주기적이거나 계절적 특성이 있는 데이터 세트에 적합합니다. 예를 들어 여름에는 수요가 많고 겨울에는 수요가 적은 항목을 예측할 때 계절적 영향을 고려하면 도움이 될 수 있습니다.
정확도 지표 내보내기
참고
내보내기 파일은 데이터 세트 가져오기의 정보를 직접 반환할 수 있습니다. 따라서 가져온 데이터에 수식이나 명령이 포함된 경우 파일이 CSV 삽입에 취약해집니다. 이러한 이유로, 파일을 내보내는 경우 보안 경고가 표시될 수 있습니다. 악의적인 활동을 방지하려면 내보낸 파일을 읽을 때 링크와 매크로를 비활성화하세요.
Forecast를 사용하면 백테스트 중에 생성된 예측값과 정확도 지표를 내보낼 수 있습니다.
이러한 내보내기를 사용하여 특정 시점 및 분위수에서 특정 항목을 평가하고 예측기를 더 잘 이해할 수 있습니다. 백테스트 내보내기는 지정된 S3 위치로 전송되며 다음 두 개의 폴더를 포합됩니다.
-
forecasted-values 각 백테스트의 예측 유형별 예측값이 포함된 CSV 또는 Parquet 파일을 포함합니다.
-
accuracy-metrics-values: 모든 백테스트의 평균과 함께 각 백테스트에 대한 지표가 포함된 CSV 또는 Parquet 파일을 포함합니다. 이러한 지표에는 각 분위수별 wQL, 평균 wQL, RMSE, MASE, MAPE, WAPE가 포함됩니다.
forecasted-values 폴더에는 각 백테스트 기간의 각 예측 유형별 예측값이 포함되어 있습니다. 또한 항목 ID, 차원, 타임스탬프, 대상 값, 백테스트 기간 시작 및 종료 시간에 대한 정보도 포함됩니다.
accuracy-metrics-values 폴더에는 각 백테스트 기간의 정확도 지표와 모든 백테스트 기간의 평균 지표가 포함되어 있습니다. 여기에는 지정된 각 분위수별 wQL 지표뿐만 아니라 평균 wQL, RMSE, MASE, MAPE, WAPE 지표가 포함되어 있습니다.
두 폴더 내의 파일은 다음과 같은 명명 규칙을 따릅니다. <ExportJobName>_<ExportTimestamp>_<PartNumber>.csv
Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 정확도 지표를 내보낼 수 있습니다.
예측 유형 선택
Amazon Forecast는 예측 유형을 사용하여 예측을 생성하고 예측기를 평가합니다. 예측 유형의 형식은 다음 두 가지입니다.
-
평균 예측 유형 - 평균을 기대값으로 사용하는 예측입니다. 일반적으로 특정 시점에 대한 점 예측으로 사용됩니다.
-
분위수 예측 유형 - 지정된 분위수에서의 예측입니다. 일반적으로 예측 구간을 제공하는 데 사용됩니다. 예측 구간은 예측 불확실성을 고려하기 위한 가능한 값의 범위입니다. 예를 들어
0.65분위수에서의 예측은 65%의 확률로 관측값보다 낮은 값을 추정합니다.
기본적으로 Forecast는 예측기 예측 유형에 0.1(P10), 0.5(P50), 0.9(P90) 값을 사용합니다. mean과 0.01(P1)부터 0.99(P99)까지의 분위수를 포함하여 최대 5개의 사용자 지정 예측 유형을 선택할 수 있습니다.
분위수는 예측의 상한과 하한을 제공할 수 있습니다. 예를 들어 예측 유형 0.1(P10)과 0.9(P90)을 사용하면 80% 신뢰 구간이라는 값 범위가 제공됩니다. 관측값은 10%의 확률로 P10 값보다 낮을 것으로 기대되며, P90 값은 90%의 확률로 관측값보다 높을 것으로 기대됩니다. P10과 P90에서 예측을 생성하면 참값이 80%의 확률로 이 한계 사이에 위치할 것으로 기대할 수 있습니다. 이 값 범위는 아래 그림의 P10과 P90 사이의 음영 영역으로 표시되어 있습니다.
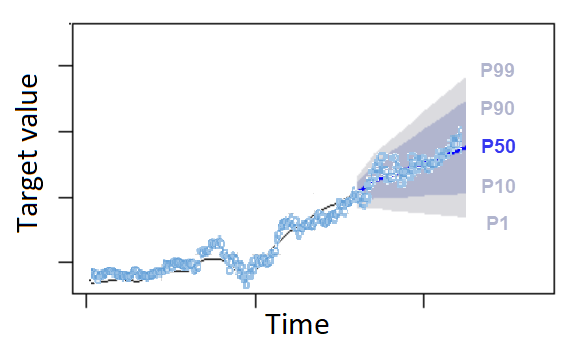
과소 예측으로 인한 비용이 과대 예측으로 인한 비용과 다른 경우 분위수 예측을 점 예측으로 사용할 수도 있습니다. 예를 들어 일부 소매업에서는 재고 부족 비용이 과잉 재고 비용보다 높습니다. 이러한 경우 0.65(P65)에서의 예측이 중앙값(P50) 또는 평균 예측보다 더 많은 정보를 제공합니다.
예측기를 훈련할 때 Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 사용자 지정 예측 유형을 선택할 수 있습니다.
레거시 예측기 작업
백테스트 파라미터 설정
Forecast는 백테스트를 사용하여 정확도 지표를 계산합니다. 여러 백테스트를 실행하는 경우 Forecast는 모든 백테스트 기간에 걸쳐 각 지표의 평균을 구합니다. 기본적으로 Forecast는 백테스트 기간의 크기(테스트 세트)가 예측 기간의 길이(예측 윈도우)와 동일한 백테스트 하나를 계산합니다. 예측기를 훈련할 때 백테스트 기간 길이와 백테스트 시나리오 수를 모두 설정할 수 있습니다.
Forecast는 채워진 값을 백테스트 프로세스에서 생략하며, 지정된 백테스트 기간 내에 채워진 값이 있는 모든 항목은 해당 백테스트에서 제외됩니다. 이는 Forecast가 백테스트 중에 예측된 값과 관측된 값만 비교하고, 채워진 값은 관측된 값이 아니기 때문입니다.
백테스트 기간은 최소한 예측 기간만큼 커야 하고 전체 대상 시계열 데이터 세트 길이의 절반보다 작아야 합니다. 1~5개의 백테스트 중에서 선택할 수 있습니다.
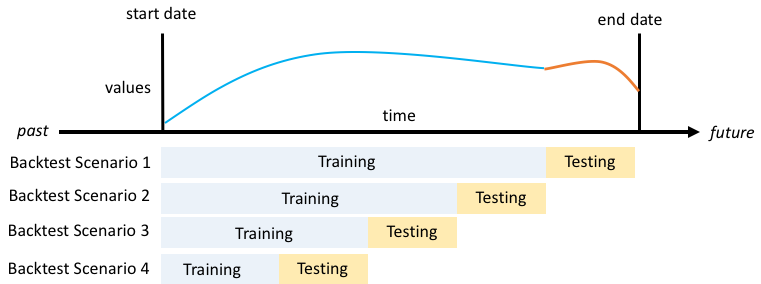
일반적으로 백테스트 수를 늘리면 더 신뢰할 수 있는 정확도 지표가 생성됩니다. 시계열의 더 많은 부분이 테스트 중에 사용되고 Forecast는 모든 백테스트에 걸쳐 지표의 평균을 구할 수 있기 때문입니다.
Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 백테스트 파라미터를 설정할 수 있습니다.

HPO 및 AutoML
기본적으로 Amazon Forecast는 하이퍼파라미터 최적화(HPO) 중의 하이퍼파라미터 튜닝과 AutoML 중의 모델 선택에 0.1(P10), 0.5(P50), 0.9(P90) 분위수를 사용합니다. 예측기를 생성할 때 사용자 지정 예측 유형을 지정하면 Forecast는 HPO 및 AutoML 중에 해당 예측 유형을 사용합니다.
사용자 지정 예측 유형이 지정된 경우 Forecast는 지정된 예측 유형을 사용하여 HPO 및 AutoML 중에 최적의 결과를 결정합니다. HPO 중에 Forecast는 첫 번째 백테스트 기간을 사용하여 최적의 하이퍼파라미터 값을 찾습니다. AutoML 중에 Forecast는 모든 백테스트 기간의 평균과 HPO의 최적 하이퍼파라미터 값을 사용하여 최적의 알고리즘을 찾습니다.
AutoML과 HPO 모두에서 Forecast는 예측 유형에 대한 평균 손실을 최소화하는 옵션을 선택합니다. 또한 AutoML 및 HPO 중에 평균 가중 분위수 손실(평균 wQL), 가중 절대 백분율 오차(WAPE), 평균 제곱근 오차(RMSE), 평균 절대 백분율 오차(MAPE) 또는 평균 절대 조정 오차(MASE) 중 하나를 사용하여 예측기를 최적화할 수 있습니다.
Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 최적화 지표를 선택할 수 있습니다.
