기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
신제품 수요 예측 모범 사례
이 섹션에서는 신제품 수요 예측을 위한 다음 모범 사례를 설명합니다.
데이터 기반 NPI 수요 예측을 위한 데이터 준비 요구 사항 충족
NPI 수요 예측을 위한 데이터 기반 접근 방식을 채택하려면 조직은 데이터 과학 또는 분석 부서, 공급망, 마케팅 및 IT의 관리자 등 모든 관련 이해관계자의 지원을 받아야 합니다. 그러면 조직에서 다음을 식별해야 합니다.
-
기존 내부 데이터 및 관련 외부 데이터의 소스
-
이러한 데이터 소스의 소유자
-
이니셔티브에 이러한 데이터 소스를 사용하는 데 필요한 절차 및 권한
다음과 같은 종류의 필수 및 선택적 데이터 세트를 기준으로 데이터 준비 상태를 평가할 수 있습니다. 선택 사항인 종류를 포함하여 가능한 한 많은 데이터 세트를 사용하면 기계 학습 모델이 보다 정확한 NPI 수요 예측을 생성하는 데 도움이 됩니다.
다음은 필수 내부 데이터 소스의 예입니다.
-
출시 중인 신제품과 유사한 속성을 가진 모든 제품 또는 제품의 하위 집합에 대한 판매 기록(제품 출시부터 중단까지)을 작성합니다. 판매 내역은 여러 판매 채널에서 가져오거나 모든 채널에서 결합할 수 있습니다.
-
시작 중인 신제품과 속성이 유사한 제품의 하위 집합을 식별하기 위한 제품 속성 매핑입니다.
다음은 선택적 내부 데이터 소스의 예입니다.
-
유사한 제품에 대한 프로모션 및 할인을 추적하는 마케팅 데이터. 이 데이터는 판매 기록의 길이보다 크거나 같아야 합니다.
-
제품 리뷰, 등급 및 웹 트래픽 데이터. 이 데이터는 판매 기록의 길이보다 크거나 같아야 합니다.
-
소비자 인구 통계 데이터
다음은 내부 데이터를 보완할 수 있는 선택적 외부 데이터 소스의 예입니다.
-
소비자 인덱스 데이터
-
경쟁자 판매 데이터
-
설문 조사 데이터
비용 효율적인 데이터 수집 메커니즘 구축
데이터 준비 요구 사항이 충족되면 조직은 가장 적합한 데이터 수집 및 데이터 스토리지 메커니즘을 선택할 수 있습니다. 조직의 주요 판매 데이터 소스가 다양한 채널에서 매일 수집되는 경우 배치 데이터 수집을 고려하세요. 스트리밍 데이터 수집은 최신 데이터를 보유하면 도움이 되는 셀프 서비스 예측을 원하는 경우 또 다른 옵션입니다.
원시 데이터 수집 파이프라인은 가벼운 변환을 위해 추출, 변환 및 로드(ETL) 파이프라인을 사용해야 합니다. 파이프라인은 데이터 품질 검사를 수행하고 처리된 데이터를 다운스트림 소비를 위해 데이터베이스에 저장해야 합니다.
AWS Glue, AWS Glue Data Catalog, Amazon Data Firehose 및 Amazon Simple Storage Service(Amazon S3) AWS 서비스와 같은를 사용하여 비용 효율적인 데이터 수집 및 스토리지를 제공할 수 있습니다. AWS Glue는 다양한 데이터 스토어 간에 데이터를 분류, 정리, 변환 및 안정적으로 전송하는 데 도움이 되는 완전 관리형 서버리스 ETL 서비스입니다. 의 핵심 구성 요소는 로 알려진 중앙 메타데이터 리포지토리 AWS Glue Data Catalog와 Python 및 Scala 코드를 자동으로 생성하고 ETL 작업을 관리하는 ETL 작업 시스템으로 AWS Glue 구성됩니다. Amazon Data Firehose는 모든 규모의 실시간 스트리밍 데이터를 수집, 처리 및 분석할 수 있도록 지원합니다. Firehose는 실시간 스트리밍 데이터를 데이터 레이크(예: Amazon S3), 데이터 스토어 및 분석 서비스에 직접 전달하여 추가 처리를 수행할 수 있습니다. Amazon S3는 업계 최고의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다.
NPI 수요를 예측하기 위한 실행 가능한 ML 접근 방식 결정
특정 사용 사례에 따라 조직은 다양한 예측 옵션을 고려할 수 있습니다.
Bass 확산 모델
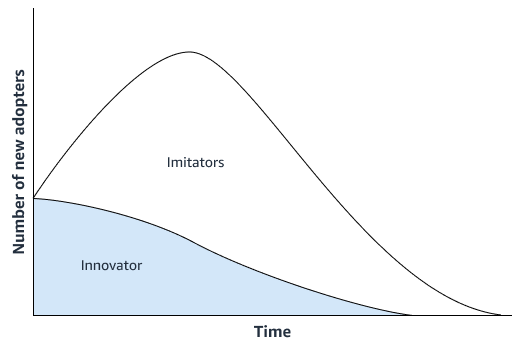
신제품에 중요한 혁신이 없는 경우 조직은 신제품과 가장 유사한 제품의 판매 기록에 따라 작동하는 시계열 예측 모델을 사용할 수 있습니다. 여러 유사 제품의 시계열 판매 데이터를 사용할 수 있는 Amazon SageMaker AI DeepAR 예측 알고리즘과 같은 ML 기반 예측 알고리즘을 사용할 수 있습니다. 이는 콜드 스타트 예측 시나리오에 적합합니다. 콜드 스타트 예측 시나리오는 시계열에 대한 예측을 생성하려고 하지만 기존 기록 데이터가 거의 없거나 전혀 없는 시나리오입니다. 다음 이미지는 관련 제품의 시계열 데이터를 사용하여 새롭고 유사한 제품에 대한 예측을 생성하는 방법을 보여줍니다.
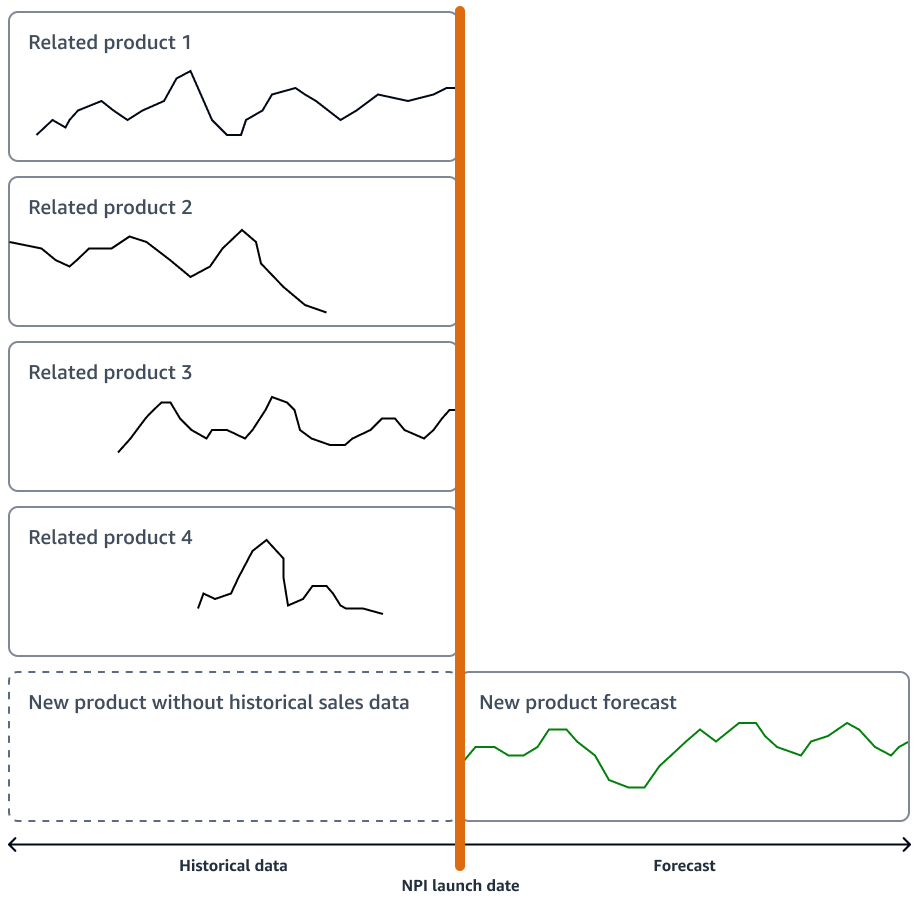
신제품 출시 일정에 맞는 예측을 생성하는 것이 좋습니다. 로지스틱 수정에 충분한 버퍼를 허용하기 위해 미리 예측을 생성합니다.
예측 효과 조정 및 추적
NPI 수요 예측에 대한 개념 증명을 완료한 후 솔루션은 결국 추가 제품과 여러 리전을 포함하도록 확장되어야 합니다. 인공 지능 및 기계 학습(AI/ML) 프레임워크를 사용하여 데이터를 준비하고 모델을 개발, 배포 및 모니터링합니다.
다음 다이어그램은 조직의 NPI 예측 솔루션이 성숙함에 따라 시작 및 확장 전략을 보여줍니다.
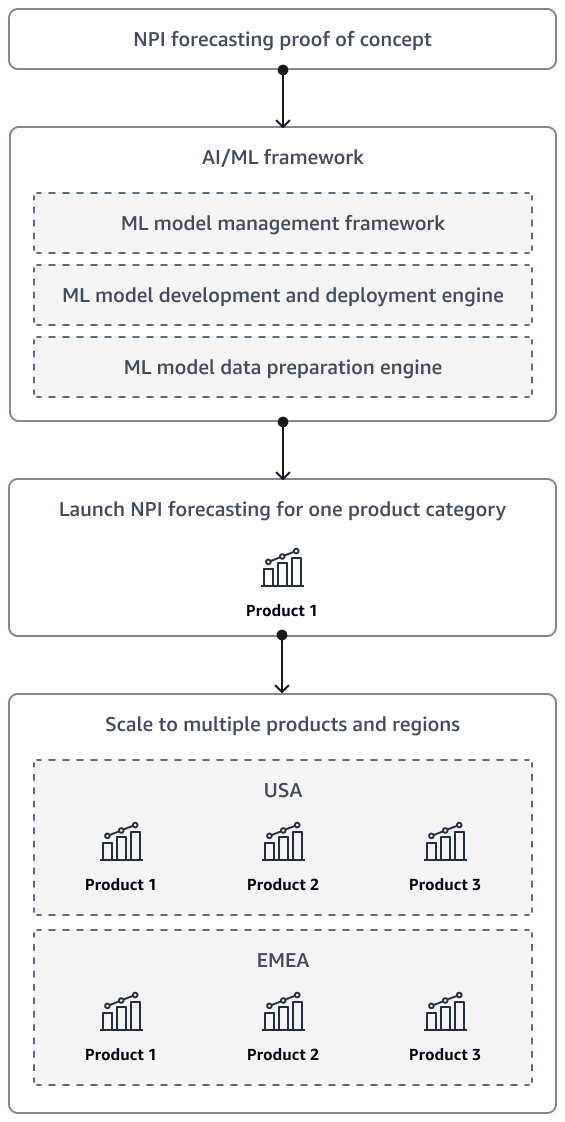
또한 경영진과 이해관계자가 예측을 자체 처리할 수 있도록 솔루션을 설계하는 것이 좋습니다. 예를 들어, 이해관계자가 최신 예측에 온디맨드로 액세스할 수 있도록 Amazon QuickSight 대시보드를 생성할 수 있습니다.
예측 정확도를 면밀히 모니터링하고 편차를 철저히 조사하여 합리적인 투자 수익률을 보장합니다(ROI). Amazon SageMaker AI 모델 모니터를 사용하여 모델 모니터링을 설정하는 경우 라이브 데이터에 대한 실시간 예측을 수행할 때 모델의 성능을 추적할 수 있습니다. Amazon SageMaker 모델 대시보드를 사용하여 데이터 품질, 모델 품질, 편향 및 설명 가능성에 대해 설정한 임계값을 위반하는 모델을 찾을 수 있습니다. 자세한 내용은 Amazon SageMaker AI 설명서에서 거버넌스를 사용하여 권한 관리 및 모델 성능 추적을 참조하세요.
