기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
하이퍼파라미터 튜닝 작업 구성 및 시작
중요
Amazon SageMaker Studio 또는 Amazon SageMaker Studio Classic에서 Amazon SageMaker 리소스를 생성할 수 있도록 허용하는 사용자 지정 IAM 정책도 해당 리소스에 태그를 추가할 수 있는 권한을 부여해야 합니다. Studio와 Studio Classic은 만드는 리소스에 태그를 자동으로 지정하기 때문에 리소스에 태그를 추가할 권한이 필요합니다. IAM 정책이 Studio 및 Studio Classic에서 리소스를 만들도록 허용하지만 태그 지정은 허용하지 않는 경우 리소스 만들기를 시도할 때 'AccessDenied' 오류가 발생할 수 있습니다. 자세한 내용은 SageMaker AI 리소스에 태그를 지정할 수 있는 권한 제공 섹션을 참조하세요.
AWS Amazon SageMaker AI에 대한 관리형 정책 는 SageMaker 리소스를 생성할 수 있는 권한을 부여합니다. 여기에는 해당 리소스를 생성하는 동안 태그를 추가할 수 있는 권한이 이미 포함되어 있습니다.
하이퍼파라미터는 모델 훈련 중 학습 프로세스에 영향을 미치는 상위 수준 파라미터입니다. 최상의 모델 예측을 가져오기 위해 하이퍼파라미터 구성을 최적화하거나 하이퍼파라미터 값을 설정할 수 있습니다. 최적의 구성을 찾는 과정을 하이퍼파라미터 튜닝이라고 합니다. 하이퍼파라미터 튜닝 작업을 구성 및 시작하려면 이 안내서에 있는 단계를 완료하세요.
하이퍼파라미터 튜닝 작업 설정
하이퍼파라미터 튜닝 작업에 대한 설정을 지정하려면 튜닝 작업을 생성할 때 JSON 객체를 정의합니다. 이 JSON 객체를 HyperParameterTuningJobConfig 파라미터 값으로 CreateHyperParameterTuningJob API에 전달합니다.
이 JSON 객체에서 다음을 지정합니다.
이 JSON 객체는 다음을 지정합니다.
-
HyperParameterTuningJobObjective- 하이퍼파라미터 튜닝 작업에서 시작한 훈련 작업 성능 평가 시 사용되는 목표 지표. -
ParameterRanges- 튜닝 가능 하이퍼파라미터가 최적화 중에 사용할 수 있는 값의 범위. 자세한 내용은 하이퍼파라미터 범위 정의 섹션을 참조하세요. -
RandomSeed- 의사 난수 생성기 초기화 시 사용되는 값. 임의 시드 설정 시 하이퍼파라미터 튜닝 검색 전략을 통해 동일한 튜닝 작업에 대해 보다 일관된 구성을 생성할 수 있습니다(선택 사항). -
ResourceLimits- 하이퍼파라미터 튜닝 작업에서 사용할 수 있는 최대 훈련 및 병렬 훈련 작업 수.
참고
SageMaker AI 기본 제공 알고리즘이 아닌 하이퍼파라미터 튜닝에 자체 알고리즘을 사용하는 경우 알고리즘에 대한 지표를 정의해야 합니다. 자세한 내용은 지표 정의 단원을 참조하십시오.
다음 코드 예제에서는 내장된 XGBoost 알고리즘을 사용하여 하이퍼파라미터 튜닝 작업을 구성하는 방법을 알아보겠습니다. 코드 예제에서 eta, alpha, min_child_weight, max_depth 하이퍼파라미터 범위를 정의하는 방법을 알아보겠습니다. 이러한 하이퍼파라미터 및 기타 하이퍼파라미터에 대한 자세한 정보는 XGBoost 파라미터
이 코드 예제에서 하이퍼파라미터 튜닝 작업의 목표 지표는 validation:auc을(를) 극대화하는 하이퍼파라미터 구성을 찾습니다. SageMaker AI 기본 제공 알고리즘은 CloudWatch Logs에 목표 지표를 자동으로 기록합니다. 또한 다음 코드 예제에서 RandomSeed을(를) 설정하는 방법을 알아보겠습니다.
tuning_job_config = { "ParameterRanges": { "CategoricalParameterRanges": [], "ContinuousParameterRanges": [ { "MaxValue": "1", "MinValue": "0", "Name": "eta" }, { "MaxValue": "2", "MinValue": "0", "Name": "alpha" }, { "MaxValue": "10", "MinValue": "1", "Name": "min_child_weight" } ], "IntegerParameterRanges": [ { "MaxValue": "10", "MinValue": "1", "Name": "max_depth" } ] }, "ResourceLimits": { "MaxNumberOfTrainingJobs": 20, "MaxParallelTrainingJobs": 3 }, "Strategy": "Bayesian", "HyperParameterTuningJobObjective": { "MetricName": "validation:auc", "Type": "Maximize" }, "RandomSeed" : 123 }
훈련 작업 구성
하이퍼파라미터 튜닝 작업은 하이퍼파라미터의 최적 구성을 찾기 위한 훈련 작업을 시작합니다. 이러한 훈련 작업은 SageMaker AI CreateHyperParameterTuningJob API를 사용하여 구성해야 합니다.
훈련 작업을 구성하려면 JSON 객체를 정의하고 CreateHyperParameterTuningJob 안에 있는 TrainingJobDefinition 내부 파라미터 값으로 전달합니다.
이 JSON 객체에서는 다음을 지정할 수 있습니다.
-
AlgorithmSpecification- 훈련 알고리즘 및 관련 메타데이터를 포함하는 도커 이미지의 레지스트리 경로. 알고리즘을 지정하려면 Docker컨테이너 또는 SageMaker AI 내장 알고리즘(필수) 내에서 자체 사용자 지정 구축 알고리즘을 사용할 수 있습니다. SageMaker -
InputDataConfig- 훈련 및 테스트 데이터에 대한ChannelName,ContentType, 데이터 소스를 포함한 입력 구성(필수). -
InputDataConfig- 훈련 및 테스트 데이터에 대한ChannelName,ContentType, 데이터 소스를 포함한 입력 구성(필수). -
알고리즘 출력 저장 위치 훈련 작업의 출력을 저장하려는 S3 버킷
-
RoleArn- SageMaker AI가 작업을 수행하는 데 사용하는 (IAM) 역할의 Amazon 리소스 이름 AWS Identity and Access Management (ARN)입니다. 작업에는 입력 데이터 읽기, 도커 이미지 다운로드, S3 버킷에 모델 아티팩트 쓰기, Amazon CloudWatch Logs에 로그 쓰기, Amazon CloudWatch에 지표 쓰기가 포함됩니다(필수). -
StoppingCondition- 훈련 작업 중지 전 실행 가능한 최대 런타임(초). 이 값은 모델 훈련에 필요한 시간보다 커야 합니다(필수). -
MetricDefinitions- 훈련 작업에서 내보내는 모든 지표를 정의하는 이름 및 정규 표현식. 사용자 지정 훈련 알고리즘을 사용하는 경우에만 지표를 정의합니다. 다음 코드의 예제에서는 이미 지표가 정의되어 있는 기본 제공 알고리즘을 사용합니다. 지표 정의(선택 사항) 관련 정보는 지표 정의에서 확인하세요. -
TrainingImage- 훈련 알고리즘을 지정하는 Docker컨테이너 이미지(선택 사항). -
StaticHyperParameters– 튜닝 작업에서 튜닝되지 않는 하이퍼파라미터의 이름과 값(선택 사항).
다음 코드 예제에서는 Amazon SageMaker AI를 사용한 XGBoost 알고리즘 기본 제공 알고리즘의 eval_metric, num_round, objective, rate_drop 및 tweedie_variance_power 파라미터에 대해 정적 값을 설정합니다.
하이퍼파라미터 튜닝 작업 이름 지정 및 시작
하이퍼파라미터 튜닝 작업 구성 후 CreateHyperParameterTuningJob API를 호출하여 시작할 수 있습니다. 다음 코드 예제에서는 tuning_job_config 및 training_job_definition을(를) 사용합니다. 이는 이전 두 코드 예제에서 하이퍼파라미터 튜닝 작업을 생성하기 위해 정의되었습니다.
tuning_job_name = "MyTuningJob" smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name, HyperParameterTuningJobConfig = tuning_job_config, TrainingJobDefinition = training_job_definition)
훈련 작업의 상태 보기
하이퍼파라미터 튜닝 작업이 시작한 훈련 작업의 상태를 보려면
-
하이퍼파라미터 튜닝 작업 목록에서 시작한 작업을 선택합니다.
-
훈련 작업을 선택합니다.

-
각 훈련 작업의 상태를 봅니다. 작업에 대한 자세한 내용을 살펴보려면 훈련 작업 목록에서 작업을 선택합니다. 하이퍼파라미터 튜닝 작업이 시작한 모든 훈련 작업의 상태에 대한 요약을 보려면 훈련 작업 상태 카운터를 참조하세요.
훈련 작업은 다음과 같을 수 있습니다.
-
Completed-훈련 작업 완료. -
InProgress-훈련 작업 진행 중. -
Stopped-훈련 작업 완료 전 수동 중지. -
Failed (Retryable)-훈련 작업 실패. 재시도 가능. 실패한 훈련 작업은 내부 서비스 오류가 발생해 실패한 경우에만 다시 시도할 수 있습니다. -
Failed (Non-retryable)-훈련 작업 실패. 재시도 불가능. 클라이언트 오류가 발생한 경우에는 실패한 훈련 작업을 다시 시도할 수 없습니다.
참고
하이퍼파라미터 튜닝 작업을 중지하고 기본 리소스를 삭제할 수 있지만 작업 자체는 삭제할 수 없습니다.
-
최적의 훈련 작업 보기
하이퍼파라미터 튜닝 작업은 각 훈련 작업에서 반환하는 목표 지표를 사용하여 훈련 작업을 평가합니다. 하이퍼파라미터 튜닝 작업이 진행 중인 경우에는 지금까지 최고의 목표 지표를 반환한 훈련 작업이 최적의 작업입니다. 하이퍼파라미터 튜닝 작업이 완료된 경우에는 지금까지 최고의 목표 지표를 반환한 훈련 작업이 최적의 작업입니다.
최적의 훈련 작업을 보려면 최고 훈련 작업을 선택합니다.
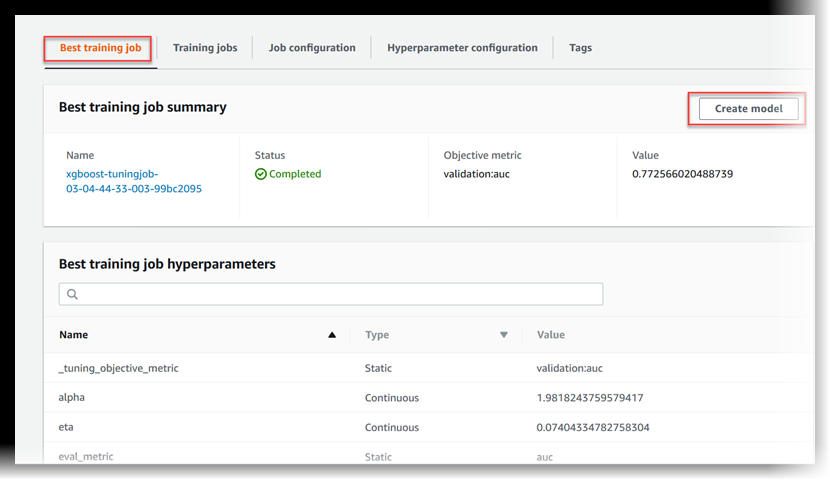
SageMaker AI 엔드포인트에서 호스팅할 수 있는 모델로 최상의 훈련 작업을 배포하려면 모델 생성을 선택합니다.
다음 단계
