Change Python and Perl applications to support database migration from Microsoft SQL Server to Amazon Aurora PostgreSQL-Compatible Edition
Dwarika Patra and Deepesh Jayaprakash, Amazon Web Services
Summary
This pattern describes changes to application repositories that might be required when you migrate databases from Microsoft SQL Server to Amazon Aurora PostgreSQL-Compatible Edition. The pattern assumes that these applications are Python-based or Perl-based, and provides separate instructions for these scripting languages.
Migrating SQL Server databases to Aurora PostgreSQL-Compatible involves schema conversion, database object conversion, data migration, and data loading. Because of the differences between PostgreSQL and SQL Server (relating to data types, connection objects, syntax, and logic), the most difficult migration task involves making the necessary changes to the code base so that it works correctly with PostgreSQL.
For a Python-based application, connection objects and classes are scattered throughout the system. Also, the Python code base might use multiple libraries to connect to the database. If the database connection interface changes, the objects that run the application’s inline queries also require changes.
For a Perl-based application, changes involve connection objects, database connection drivers, static and dynamic inline SQL statements, and how the application handles complex dynamic DML queries and results sets.
When you migrate your application, you can also consider possible enhancements on AWS, such as replacing the FTP server with Amazon Simple Storage Service (Amazon S3) access.
The application migration process involves the following challenges:
Connection objects. If connection objects are scattered in the code with multiple libraries and function calls, you might have to find a generalized way to change them to support PostgreSQL.
Error or exception handling during record retrieval or updates. If you have conditional create, read, update, and delete (CRUD) operations on the database that return variables, results sets, or data frames, any errors or exceptions might result in application errors with cascading effects. These should be handled carefully with proper validations and save points. One such save point is to call large inline SQL queries or database objects inside
BEGIN...EXCEPTION...ENDblocks.Controlling transactions and their validation. These includes manual and automatic commits and rollbacks. The PostgreSQL driver for Perl requires you to always explicitly set the auto-commit attribute.
Handling dynamic SQL queries. This requires a strong understanding of the query logic and iterative testing to ensure that queries work as expected.
Performance. You should ensure that code changes don’t result in degraded application performance.
This pattern explains the conversion process in detail.
Prerequisites and limitations
Prerequisites
Working knowledge of Python and Perl syntax.
Basic skills in SQL Server and PostgreSQL.
Understanding of your existing application architecture.
Access to your application code, SQL Server database, and PostgreSQL database.
Access to Windows or Linux (or other Unix) development environment with credentials for developing, testing, and validating application changes.
For a Python-based application, standard Python libraries that your application might require, such as Pandas to handle data frames, and psycopg2 or SQLAlchemy for database connections.
For a Perl-based application, required Perl packages with dependent libraries or modules. The Comprehensive Perl Archive Network (CPAN) module can support most application requirements.
All required dependent customized libraries or modules.
Database credentials for read access to SQL Server and read/write access to Aurora.
PostgreSQL to validate and debug application changes with services and users.
Access to development tools during application migration such as Visual Studio Code, Sublime Text, or pgAdmin.
Limitations
Some Python or Perl versions, modules, libraries, and packages aren’t compatible with the cloud environment.
Some third-party libraries and frameworks used for SQL Server cannot be replaced to support PostgreSQL migration.
Performance variations might require changes to your application, to inline Transact-SQL (T-SQL) queries, database functions, and stored procedures.
PostgreSQL supports lowercase names for table names, column names, and other database objects.
Some data types, such as UUID columns, are stored in lowercase only. Python and Perl applications must handle such case differences.
Character encoding differences must be handled with the correct data type for the corresponding text columns in the PostgreSQL database.
Product versions
Python 3.6 or later (use the version that supports your operating system)
Perl 5.8.3 or later (use the version that supports your operating system)
Aurora PostgreSQL-Compatible Edition 4.2 or later (see details)
Architecture
Source technology stack
Scripting (application programming) language: Python 2.7 or later, or Perl 5.8
Database: Microsoft SQL Server version 13
Operating system: Red Hat Enterprise Linux (RHEL) 7
Target technology stack
Scripting (application programming) language: Python 3.6 or later, or Perl 5.8 or later
Database: Aurora PostgreSQL-Compatible 4.2
Operating system: RHEL 7
Migration architecture
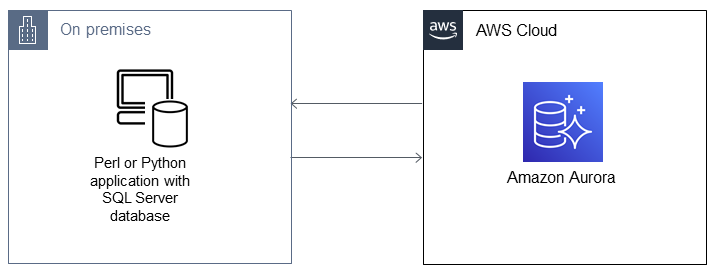
Tools
AWS services and tools
Aurora PostgreSQL–Compatible Edition is a fully managed, PostgreSQL-compatible, and ACID-compliant relational database engine that combines the speed and reliability of high-end commercial databases with the cost-effectiveness of open-source databases. Aurora PostgreSQL is a drop-in replacement for PostgreSQL and makes it easier and more cost-effective to set up, operate, and scale your new and existing PostgreSQL deployments.
AWS Command Line Interface (AWS CLI) is an open-source tool that enables you to interact with AWS services by using commands in your command-line shell.
Other tools
Python
and PostgresSQL database connection libraries such as psycopg2 and SQLAlchemy Perl
and its DBI modules
Epics
| Task | Description | Skills required |
|---|---|---|
Follow these code conversion steps to migrate your application to PostgreSQL. |
The following epics provide detailed instructions for some of these conversion tasks for Python and Perl applications. | App developer |
Use a checklist for each step of the migration. | Add the following to your checklist for each step of application migration, including the final step:
| App developer |
| Task | Description | Skills required |
|---|---|---|
Analyze your existing Python code base. | Your analysis should include the following to facilitate the application migration process:
| App developer |
Convert your database connections to support PostgreSQL. | Most Python applications use the pyodbc library to connect with SQL Server databases as follows.
Convert the database connection to support PostgreSQL as follows.
| App developer |
Change inline SQL queries to PostgreSQL. | Convert your inline SQL queries to a PostgreSQL-compatible format. For example, the following SQL Server query retrieves a string from a table.
After conversion, the PostgreSQL-compatible inline SQL query looks like the following.
| App developer |
Handle dynamic SQL queries. | Dynamic SQL can be present in one script or in multiple Python scripts. Earlier examples showed how to use Python’s string replace function to insert variables for constructing dynamic SQL queries. An alternate approach is to append the query string with variables wherever applicable. In the following example, the query string is constructed on the fly based on the values returned by a function.
These types of dynamic queries are very common during application migration. Follow these steps to handle dynamic queries:
| App developer |
Handle results sets, variables, and data frames. | For Microsoft SQL Server, you use Python methods such as pyodbc (Microsoft SQL Server)
In Aurora, to perform similar tasks such as connecting to PostgreSQL and fetching results sets, you can use either psycopg2 or SQLAlchemy. These Python libraries provide the connection module and cursor object to traverse through the PostgreSQL database records, as shown in the following example. psycopg2 (Aurora PostgreSQL-Compatible)
SQLAlchemy (Aurora PostgreSQL-Compatible)
| App developer |
Test your application during and after migration. | Testing the migrated Python application is an ongoing process. Because the migration includes connection object changes (psycopg2 or SQLAlchemy), error handling, new features (data frames), inline SQL changes, bulk copy functionalities (
| App developer |
| Task | Description | Skills required |
|---|---|---|
Analyze your existing Perl code base. | Your analysis should include the following to facilitate the application migration process. You should identify:
| App developer |
Convert the connections from the Perl application and DBI module to support PostgreSQL. | Perl-based applications generally use the Perl DBI module, which is a standard database access module for the Perl programming language. You can use the same DBI module with different drivers for SQL Server and PostgreSQL. For more information about required Perl modules, installations, and other instructions, see the DBD::Pg documentation
| App developer |
Change Inline SQL queries to PostgreSQL. | Your application might have inline SQL queries with In SQL Server:
For PostgreSQL, convert to:
| App developer |
Handle dynamic SQL queries and Perl variables. | Dynamic SQL queries are SQL statements that are built at application runtime. These queries are constructed dynamically when the application is running, depending on certain conditions, so the full text of the query isn’t known until runtime. An example is a financial analytics application that analyzes the top 10 shares on a daily basis, and these shares change every day. The SQL tables are created based on top performers, and the values aren’t known until runtime. Let’s say that the inline SQL queries for this example are passed to a wrapper function to get the results set in a variable, and then a variable uses a condition to determine whether the table exists:
Here’s an example of variable handling, followed by the SQL Server and PostgreSQL queries for this use case.
SQL Server:
PostgreSQL:
The following example uses a Perl variable in inline SQL, which runs a SQL Server:
PostgreSQL:
| App developer |
| Task | Description | Skills required |
|---|---|---|
Convert additional SQL Server constructs to PostgreSQL. | The following changes apply to all applications, regardless of programming language.
| App developer |
| Task | Description | Skills required |
|---|---|---|
Take advantage of AWS services to make performance enhancements. | When you migrate to the AWS Cloud, you can refine your application and database design to take advantage of AWS services. For example, if the queries from your Python application, which is connected to an Aurora PostgreSQL-Compatible database server, is taking more time than your original Microsoft SQL Server queries, you could consider creating a feed of historical data directly to an Amazon Simple Storage Service (Amazon S3) bucket from the Aurora server, and use Amazon Athena-based SQL queries to generate reports and analytic data queries for your user dashboards. | App developer, Cloud architect |
Related resources
Additional information
Both Microsoft SQL Server and Aurora PostgreSQL-Compatible are ANSI SQL-complaint. However, you should still be aware of any incompatibilities in syntax, column data types, native database-specific functions, bulk inserts, and case sensitivity when you migrate your Python or Perl application from SQL Server to PostgreSQL.
The following sections provide more information about possible inconsistencies.
Data type comparison
Data type changes from SQL Server to PostgreSQL can lead to significant differences in the resulting data that applications operate on. For a comparison of data types, see the table on the Sqlines website
Native or built-in SQL functions
The behavior of some functions differs between SQL Server and PostgreSQL databases. The following table provides a comparison.
Microsoft SQL Server | Description | PostgreSQL |
|---|---|---|
| Converts a value from one data type to another. | PostgreSQL |
| Returns the current database system date and time, in a |
|
| Adds a time/date interval to a date. |
|
| Converts a value to a specific data format. |
|
| Returns the difference between two dates. |
|
| Limits the number of rows in a |
|
Anonymous blocks
A structured SQL query is organized into sections such as declaration, executables, and exception handling. The following table compares the Microsoft SQL Server and PostgreSQL versions of a simple anonymous block. For complex anonymous blocks, we recommend that you call a custom database function within your application.
Microsoft SQL Server | PostgreSQL |
|---|---|
|
|
Other differences
Bulk inserts of rows: The PostgreSQL equivalent of the Microsoft SQL Server bcp utility
is COPY . Case sensitivity: Column names are case-sensitive in PostgreSQL, so you have to convert your SQL Server column names to lowercase or uppercase. This becomes a factor when you extract or compare data, or place column names in results sets or variables. The following example identifies columns where values might be stored in uppercase or lowercase.
my $sql_qry = "SELECT $record_id FROM $exampleTable WHERE LOWER($record_name) = \'failed transaction\'";
Concatenation: SQL Server uses
+as an operator for string concatenation, whereas PostgreSQL uses||.Validation: You should test and validate inline SQL queries and functions before you use them in application code for PostgreSQL.
ORM Library inclusion : You can also look for including or replace existing database connection library with Python ORM libraries such as SQLAlchemy
and PynomoDB . This will help to easily query and manipulate data from a database using an object-oriented paradigm.
