Migrate Oracle CLOB values to individual rows in PostgreSQL on AWS
Sai Krishna Namburu and Sindhusha Paturu, Amazon Web Services
Summary
This pattern describes how to split Oracle character large object (CLOB) values into individual rows in Amazon Aurora PostgreSQL-Compatible Edition and Amazon Relational Database Service (Amazon RDS) for PostgreSQL. PostgreSQL doesn’t support the CLOB data type.
Tables with interval partitions are identified in the source Oracle database, and the table name, the type of partition, the interval of the partition, and other metadata are captured and loaded into the target database. You can load CLOB data that is less than 1 GB in size into target tables as text by using AWS Database Migration Service (AWS DMS), or you can export the data in CSV format, load it into an Amazon Simple Storage Service (Amazon S3) bucket, and migrate it to your target PostgreSQL database.
After migration, you can use the custom PostgreSQL code that is provided with this pattern to split the CLOB data into individual rows based on the new line character identifier (CHR(10)) and populate the target table.
Prerequisites and limitations
Prerequisites
An Oracle database table that has interval partitions and records with a CLOB data type.
An Aurora PostgreSQL-Compatible or Amazon RDS for PostgreSQL database that has a table structure that’s similar to the source table (same columns and data types).
Limitations
The CLOB value cannot exceed 1 GB.
Each row in the target table must have a new line character identifier.
Product versions
Oracle 12c
Aurora Postgres 11.6
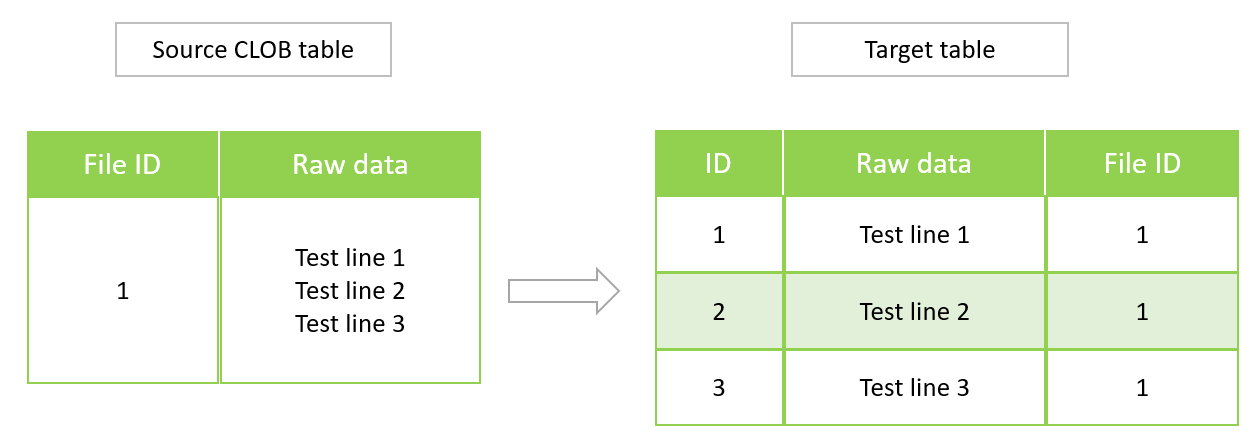
Architecture
The following diagram shows a source Oracle table with CLOB data, and the equivalent PostgreSQL table in Aurora PostgreSQL-Compatible version 11.6.
Tools
AWS services
Amazon Aurora PostgreSQL-Compatible Edition is a fully managed, ACID-compliant relational database engine that helps you set up, operate, and scale PostgreSQL deployments.
Amazon Relational Database Service (Amazon RDS) for PostgreSQL helps you set up, operate, and scale a PostgreSQL relational database in the AWS Cloud.
AWS Database Migration Service (AWS DMS) helps you migrate data stores into the AWS Cloud or between combinations of cloud and on-premises setups.
Amazon Simple Storage Service (Amazon S3) is a cloud-based object storage service that helps you store, protect, and retrieve any amount of data.
Other tools
You can use the following client tools to connect to, access, and manage your Aurora PostgreSQL-Compatible and Amazon RDS for PostgreSQL databases. (These tools aren’t used within this pattern.)
pgAdmin
is an open-source management tool for PostgreSQL. It provides a graphical interface that helps you create, maintain, and use database objects. DBeaver
is an open-source database tool for developers and database administrators. You can use the tool to manipulate, monitor, analyze, administer, and migrate your data.
Best practices
For best practices for migrating your database from Oracle to PostgreSQL, see the AWS blog post Best practices for migrating an Oracle database to Amazon RDS PostgreSQL or Amazon Aurora PostgreSQL: Migration process and infrastructure considerations
For best practices for configuring the AWS DMS task for migrating large binary objects, see Migrating large binary objects (LOBs) in the AWS DMS documentation.
Epics
| Task | Description | Skills required |
|---|---|---|
Analyze the CLOB data. | In the source Oracle database, analyze the CLOB data to see whether it contains column headers, so you can determine the method for loading the data into the target table. To analyze the input data, use the following query.
| Developer |
Load the CLOB data to the target database. | Migrate the table that has CLOB data to an interim (staging) table in the Aurora or Amazon RDS target database. You can use AWS DMS or upload the data as a CSV file to an Amazon S3 bucket. For information about using AWS DMS for this task, see Using an Oracle database as a source and Using a PostgreSQL database as a target in the AWS DMS documentation. For information about using Amazon S3 for this task, see Using Amazon S3 as a target in the AWS DMS documentation. | Migration engineer, DBA |
Validate the target PostgreSQL table. | Validate the target data, including headers, against the source data by using the following queries in the target database.
Compare the results against the query results from the source database (from the first step). | Developer |
Split the CLOB data into separate rows. | Run the custom PostgreSQL code provided in the Additional information section to split the CLOB data and insert it into separate rows in the target PostgreSQL table. | Developer |
| Task | Description | Skills required |
|---|---|---|
Validate the data in the target table. | Validate the data inserted into the target table by using the following queries.
| Developer |
Related resources
CLOB data type
(Oracle documentation) Data types
(PostgreSQL documentation)
Additional information
PostgreSQL function for splitting CLOB data
do $$ declare totalstr varchar; str1 varchar; str2 varchar; pos1 integer := 1; pos2 integer ; len integer; begin select rawdata||chr(10) into totalstr from clobdata_pg; len := length(totalstr) ; raise notice 'Total length : %',len; raise notice 'totalstr : %',totalstr; raise notice 'Before while loop'; while pos1 < len loop select position (chr(10) in totalstr) into pos2; raise notice '1st position of new line : %',pos2; str1 := substring (totalstr,pos1,pos2-1); raise notice 'str1 : %',str1; insert into clobdatatarget(data) values (str1); totalstr := substring(totalstr,pos2+1,len); raise notice 'new totalstr :%',totalstr; len := length(totalstr) ; end loop; end $$ LANGUAGE 'plpgsql' ;
Input and output examples
You can use the following examples to try out the PostgreSQL code before you migrate your data.
Create an Oracle database with three input lines.
CREATE TABLE clobdata_or ( id INTEGER GENERATED ALWAYS AS IDENTITY, rawdata clob ); insert into clobdata_or(rawdata) values (to_clob('test line 1') || chr(10) || to_clob('test line 2') || chr(10) || to_clob('test line 3') || chr(10)); COMMIT; SELECT * FROM clobdata_or;
This displays the following output.
id | rawdata |
1 | test line 1 test line 2 test line 3 |
Load the source data into a PostgreSQL staging table (clobdata_pg) for processing.
SELECT * FROM clobdata_pg; CREATE TEMP TABLE clobdatatarget (id1 SERIAL,data VARCHAR ); <Run the code in the additional information section.> SELECT * FROM clobdatatarget;
This displays the following output.
id1 | data |
1 | test line 1 |
2 | test line 2 |
3 | test line 3 |
