Perform advanced analytics using Amazon Redshift ML
Po Hong and Chyanna Antonio, Amazon Web Services
Summary
On the Amazon Web Services (AWS) Cloud, you can use Amazon Redshift machine learning (Amazon Redshift ML) to perform ML analytics on data stored in either an Amazon Redshift cluster or on Amazon Simple Storage Service (Amazon S3). Amazon Redshift ML supports supervised learning, which is typically used for advanced analytics. Use cases for Amazon Redshift ML include revenue forecasting, credit card fraud detection, and customer lifetime value (CLV) or customer churn predictions.
Amazon Redshift ML makes it easy for database users to create, train, and deploy ML models by using standard SQL commands. Amazon Redshift ML uses Amazon SageMaker Autopilot to automatically train and tune the best ML models for classification or regression based on your data, while you retain control and visibility.
All interactions between Amazon Redshift, Amazon S3, and Amazon SageMaker are abstracted away and automated. After the ML model is trained and deployed, it becomes available as a user-defined function (UDF) in Amazon Redshift and can be used in SQL queries.
This pattern complements the Create, train, and deploy ML models in Amazon Redshift using SQL with Amazon Redshift ML
Prerequisites and limitations
Prerequisites
An active AWS account
Existing data in an Amazon Redshift table
Skills
Familiarity with terms and concepts used by Amazon Redshift ML, including machine learning, training, and prediction. For more information about this, see Training ML models in the Amazon Machine Learning (Amazon ML) documentation.
Experience with Amazon Redshift user setup, access management, and standard SQL syntax. For more information about this, see Getting started with Amazon Redshift in the Amazon Redshift documentation.
Knowledge and experience with Amazon S3 and AWS Identity and Access Management (IAM).
Experience running commands in AWS Command Line Interface (AWS CLI) is also beneficial but not required.
Limitations
The Amazon Redshift cluster and S3 bucket must be located in the same AWS Region.
This pattern’s approach only supports supervised learning models such as regression, binary classification, and multiclass classification.
Architecture
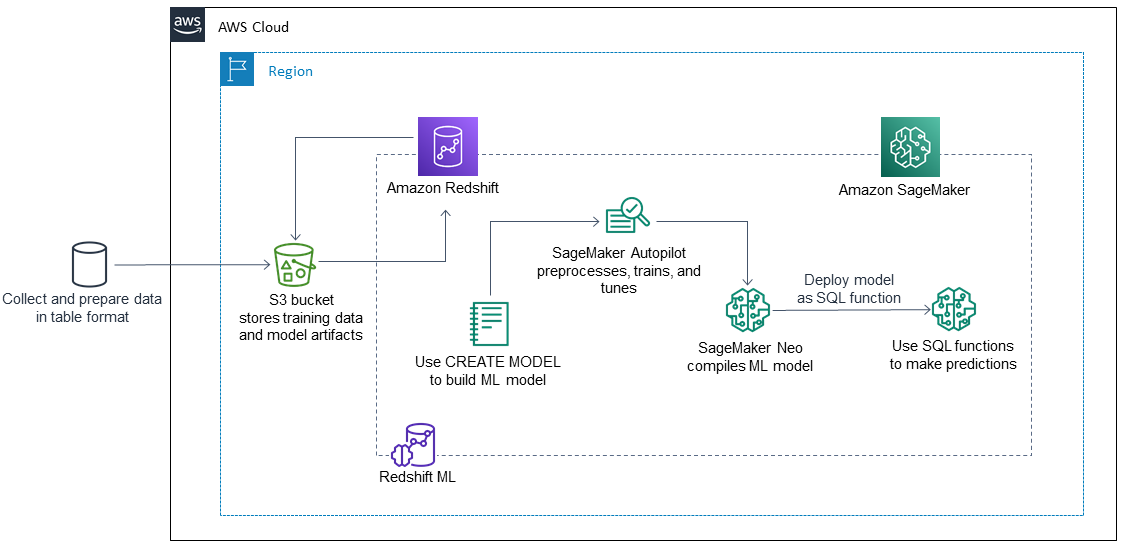
The following steps explain how Amazon Redshift ML works with SageMaker to build, train, and deploy an ML model:
Amazon Redshift exports training data to an S3 bucket.
SageMaker Autopilot automatically preprocesses the training data.
After the
CREATE MODELstatement is invoked, Amazon Redshift ML uses SageMaker for training.SageMaker Autopilot searches for and recommends the ML algorithm and optimal hyper-parameters that optimize the evaluation metrics.
Amazon Redshift ML registers the output ML model as a SQL function in the Amazon Redshift cluster.
The ML model's function can be used in a SQL statement.
Technology stack
Amazon Redshift
SageMaker
Amazon S3
Tools
Amazon Redshift – Amazon Redshift is an enterprise-level, petabyte scale, fully managed data warehousing service.
Amazon Redshift ML – Amazon Redshift machine learning (Amazon Redshift ML) is a robust, cloud-based service that makes it easy for analysts and data scientists of all skill levels to use ML technology.
Amazon S3 – Amazon Simple Storage Service (Amazon S3) is storage for the internet.
Amazon SageMaker – SageMaker is a fully managed ML service.
Amazon SageMaker Autopilot – SageMaker Autopilot is a feature-set that automates key tasks of an automatic machine learning (AutoML) process.
Code
You can create a supervised ML model in Amazon Redshift by using the following code:
"CREATE MODEL customer_churn_auto_model FROM (SELECT state, account_length, area_code, total_charge/account_length AS average_daily_spend, cust_serv_calls/account_length AS average_daily_cases, churn FROM customer_activity WHERE record_date < '2020-01-01' ) TARGET churn FUNCTION ml_fn_customer_churn_auto IAM_ROLE 'arn:aws:iam::XXXXXXXXXXXX:role/Redshift-ML' SETTINGS ( S3_BUCKET 'your-bucket' );")
Note
The SELECT state can refer to Amazon Redshift regular tables, Amazon Redshift Spectrum external tables, or both.
Epics
| Task | Description | Skills required |
|---|---|---|
Prepare a training and test dataset. | Sign in to the AWS Management Console and open the Amazon SageMaker console. Follow the instructions from the Build, train, and deploy a machine learning model NoteWe recommend that you shuffle and split the raw dataset into a training set for the model’s training (70 percent) and a test set for the model’s performance evaluation (30 percent). | Data scientist |
| Task | Description | Skills required |
|---|---|---|
Create and configure an Amazon Redshift cluster. | On the Amazon Redshift console, create a cluster according to your requirements. For more information about this, see Create a cluster in the Amazon Redshift documentation. ImportantAmazon Redshift clusters must be created with the | DBA, Cloud architect |
Create an S3 bucket to store training data and model artifacts. | On the Amazon S3 console, create an S3 bucket for the training and test data. For more information about creating an S3 bucket, see Create an S3 bucket from AWS Quick Starts. ImportantMake sure that your Amazon Redshift cluster and S3 bucket are in the same Region. | DBA, Cloud architect |
Create and attach an IAM policy to the Amazon Redshift cluster. | Create an IAM policy to allow the Amazon Redshift cluster to access SageMaker and Amazon S3. For instructions and steps, see Cluster setup for using Amazon Redshift ML in the Amazon Redshift documentation. | DBA, Cloud architect |
Allow Amazon Redshift users and groups to access schemas and tables. | Grant permissions to allow users and groups in Amazon Redshift to access internal and external schemas and tables. For steps and instructions, see Managing permissions and ownership in the Amazon Redshift documentation. | DBA |
| Task | Description | Skills required |
|---|---|---|
Create and train the ML model in Amazon Redshift. | Create and train your ML model in Amazon Redshift ML. For more information, see the | Developer, Data scientist |
| Task | Description | Skills required |
|---|---|---|
Perform inference using the generated ML model function. | For more information about performing inference by using the generated ML model function, see Prediction in the Amazon Redshift documentation. | Data scientist, Business intelligence user |
Related resources
Prepare a training and test dataset
Prepare and configure the technology stack
Create and train the ML model in Amazon Redshift
Perform batch inference and prediction in Amazon Redshift
Other resources
