Set up disaster recovery for Oracle JD Edwards EnterpriseOne with AWS Elastic Disaster Recovery
Thanigaivel Thirumalai, Amazon Web Services
Summary
Disasters that are triggered by natural catastrophes, application failures, or disruption of services harm revenue and cause downtime for corporate applications. To reduce the repercussions of such events, planning for disaster recovery (DR) is critical for firms that adopt JD Edwards EnterpriseOne enterprise resource planning (ERP) systems and other mission-critical and business-critical software.
This pattern explains how businesses can use AWS Elastic Disaster Recovery as a DR option for their JD Edwards EnterpriseOne applications. It also outlines the steps for using Elastic Disaster Recovery failover and failback to construct a cross-Region DR strategy for databases hosted on an Amazon Elastic Compute Cloud (Amazon EC2) instance in the AWS Cloud.
Note
This pattern requires the primary and secondary Regions for the cross-Region DR implementation to be hosted on AWS.
Oracle JD Edwards EnterpriseOne
AWS Elastic Disaster Recovery minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications by using affordable storage, minimal compute, and point-in-time recovery.
AWS provides four core DR architecture patterns. This document focuses on setup, configuration, and optimization by using the pilot light strategy. This strategy helps you create a lower-cost DR environment where you initially provision a replication server for replicating data from the source database, and you provision the actual database server only when you start a DR drill and recovery. This strategy removes the expense of maintaining a database server in the DR Region. Instead, you pay for a smaller EC2 instance that serves as a replication server.
Prerequisites and limitations
Prerequisites
An active AWS account.
A JD Edwards EnterpriseOne application running on Oracle Database or Microsoft SQL Server with a supported database in a running state on a managed EC2 instance. This application should include all JD Edwards EnterpriseOne base components (Enterprise Server, HTML Server, and Database Server) installed in one AWS Region.
An AWS Identity and Access Management (IAM) role to set up the Elastic Disaster Recovery service.
The network for running Elastic Disaster Recovery configured according to the required connectivity settings.
Limitations
You can use this pattern to replicate all tiers, unless the database is hosted on Amazon Relational Database Service (Amazon RDS), in which case we recommend that you use the cross-Region copy functionality of Amazon RDS.
Elastic Disaster Recovery isn’t compatible with CloudEndure Disaster Recovery, but you can upgrade from CloudEndure Disaster Recovery. For more information, see the FAQ in the Elastic Disaster Recovery documentation.
Amazon Elastic Block Store (Amazon EBS) limits the rate at which you can take snapshots. You can replicate a maximum number of 300 servers in a single AWS account by using Elastic Disaster Recovery. To replicate more servers, you can use multiple AWS accounts or multiple target AWS Regions. (You will have to set up Elastic Disaster Recovery separately for each account and Region.) For more information, see Best practices in the Elastic Disaster Recovery documentation.
The source workloads (the JD Edwards EnterpriseOne application and database) must be hosted on EC2 instances. This pattern doesn’t support workloads that are on premises or in other cloud environments.
This pattern focuses on the JD Edwards EnterpriseOne components. A full DR and business continuity plan (BCP) should include other core services, including:
Networking (virtual private cloud, subnets, and security groups)
Active Directory
Amazon WorkSpaces
Elastic Load Balancing
A managed database service such as Amazon Relational Database Service (Amazon RDS)
For additional information about prerequisites, configurations, and limitations, see the Elastic Disaster Recovery documentation.
Product versions
Oracle JD Edwards EnterpriseOne (Oracle and SQL Server supported versions based on Oracle Minimum Technical Requirements)
Architecture
Target technology stack
A single Region and single virtual private cloud (VPC) for production and non-production, and a second Region for DR
Single Availability Zones to ensure low latency between servers
An Application Load Balancer that distributes network traffic to improve the scalability and availability of your applications across multiple Availability Zones
Amazon Route 53 to provide Domain Name System (DNS) configuration
Amazon WorkSpaces to provide users with a desktop experience in the cloud
Amazon Simple Storage Service (Amazon S3) for storing backups, files, and objects
Amazon CloudWatch for application logging, monitoring, and alarms
Amazon Elastic Disaster Recovery for disaster recovery
Target architecture
The following diagram shows the cross-Region disaster recovery architecture for JD Edwards EnterpriseOne using Elastic Disaster Recovery.
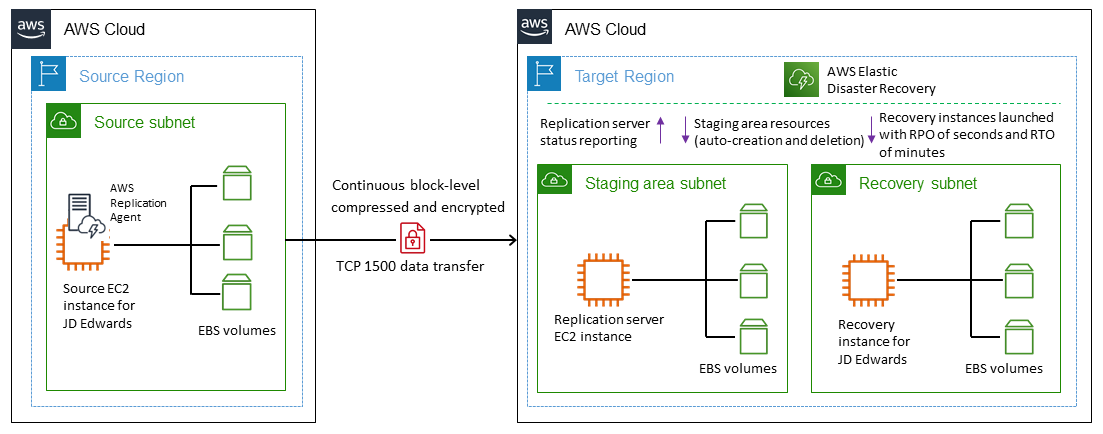
Procedure
Here is a high-level review of the process. For details, see the Epics section.
Elastic Disaster Recovery replication begins with an initial sync. During the initial sync, the AWS Replication Agent replicates all the data from the source disks to the appropriate resource in the staging area subnet.
Continuous replication continues indefinitely after the initial sync is complete.
You review the launch parameters, which include service-specific configurations and an Amazon EC2 launch template, after the agent has been installed and replication has started. When the source server is indicated as being ready for recovery, you can start instances.
When Elastic Disaster Recovery issues a series of API calls to begin the launch operation, the recovery instance is immediately launched on AWS according to your launch settings. The service automatically spins up a conversion server during startup.
The new instance is spun up on AWS after the conversion is complete and is ready for use. The source server state at the time of launch is represented by the volumes associated with the launched instance. The conversion process involves changes to the drivers, network, and operating system license to ensure that the instance boots natively on AWS.
After the launch, the newly created volumes are no longer kept in sync with the source servers. The AWS Replication Agent continues to routinely replicate changes made to your source servers to the staging area volumes, but the launched instances do not reflect those changes.
When you start a new drill or recovery instance, the data is always reflected in the most recent state that has been replicated from the source server to the staging area subnet.
When the source server is marked as being prepared for recovery, you can start instances.
Note
The process works both ways: for failover from a primary AWS Region to a DR Region, and to fail back to the primary site, when it has been recovered. You can prepare for failback by reversing the direction of data replication from the target machine back to the source machine in a fully orchestrated way.
The benefits of this process described in this pattern include:
Flexibility: Replication servers scale out and scale in based on dataset and replication time, so you can perform DR tests without disrupting source workloads or replication.
Reliability: The replication is robust, non-disruptive, and continuous.
Automation: This solution provides a unified, automated process for test, recovery, and failback.
Cost optimization: You can replicate only the needed volumes and pay for them, and pay for compute resources at the DR site only when those resources are activated. You can use a cost-optimized replication instance (we recommend that you use a compute-optimized instance type) for multiple sources or a single source with a large EBS volume.
Automation and scale
When you perform disaster recovery at scale, the JD Edwards EnterpriseOne servers will have dependencies on other servers in the environment. For example:
JD Edwards EnterpriseOne application servers that connect to a JD Edwards EnterpriseOne supported database on boot have dependencies on that database.
JD Edwards EnterpriseOne servers that require authentication and need to connect to a domain controller on boot to start services have dependencies on the domain controller.
For this reason, we recommend that you automate failover tasks. For example, you can use AWS Lambda or AWS Step Functions to automate the JD Edwards EnterpriseOne startup scripts and load balancer changes to automate the end-to-end failover process. For more information, see the blog post Creating a scalable disaster recovery plan with AWS Elastic Disaster Recovery
Tools
AWS services
Amazon Elastic Block Store (Amazon EBS) provides block-level storage volumes for use with EC2 instances.
Amazon Elastic Compute Cloud (Amazon EC2)
provides scalable computing capacity in the AWS Cloud. You can launch as many virtual servers as you need and quickly scale them up or down. AWS Elastic Disaster Recovery
minimizes downtime and data loss with fast, reliable recovery of on-premises and cloud-based applications using affordable storage, minimal compute, and point-in-time recovery. Amazon Virtual Private Cloud (Amazon VPC)
gives you full control over your virtual networking environment, including resource placement, connectivity, and security.
Best practices
General best practices
Have a written plan of what to do in the event of a real recovery event.
After you set up Elastic Disaster Recovery correctly, create an AWS CloudFormation template that can create the configuration on demand, should the need arise. Determine the order in which servers and applications should be launched, and record this in the recovery plan.
Perform a regular drill (standard Amazon EC2 rates apply).
Monitor the health of the ongoing replication by using the Elastic Disaster Recovery console or programmatically.
Protect the point-in-time snapshots and confirm before terminating the instances.
Create a IAM role for AWS Replication Agent installation.
Enable termination protection for recovery instances in a real DR scenario.
Do not use the Disconnect from AWS action in the Elastic Disaster Recovery console for servers that you launched recovery instances for, even in the case of a real recovery event. Performing a disconnect terminates all replication resources related to these source servers, including your point-in-time (PIT) recovery points.
Change the PIT policy to change the number of days for snapshot retention.
Edit the launch template in Elastic Disaster Recovery launch settings to set the correct subnet, security group, and instance type for your target server.
Automate the end-to-end failover process by using Lambda or Step Functions to automate JD Edwards EnterpriseOne startup scripts and load balancer changes.
JD Edwards EnterpriseOne optimization and considerations
Move PrintQueue into the database.
Move MediaObjects into the database.
Exclude the logs and temp folder from batch and logic servers.
Exclude the temp folder from Oracle WebLogic.
Create scripts for startup after the failover.
Exclude the tempdb for SQL Server.
Exclude the temp file for Oracle.
Epics
| Task | Description | Skills required |
|---|---|---|
Set up the replication network. | Implement your JD Edwards EnterpriseOne system in the primary AWS Region and identify the AWS Region for DR. Follow the steps in the Replication network requirements section of the Elastic Disaster Recovery documentation to plan and set up your replication and DR network. | AWS administrator |
Determine RPO and RTO. | Identify the recovery time objective (RTO) and recovery point objective (RPO) for your application servers and database. | Cloud architect, DR architect |
Enable replication for Amazon EFS. | If applicable, enable replication from the AWS primary to DR Region for shared file systems such as Amazon Elastic File System (Amazon EFS) by using AWS DataSync, rsync, or another appropriate tool. | Cloud administrator |
Manage DNS in case of DR. | Identify the process to update the Domain Name System (DNS) during the DR drill or actual DR. | Cloud administrator |
Create an IAM role for setup. | Follow the instructions in the Elastic Disaster Recovery initialization and permissions section of the Elastic Disaster Recovery documentation to create an IAM role to initialize and manage the AWS service. | Cloud administrator |
Set up VPC peering. | Make sure that the source and target VPCs are peered and accessible to each other. For configuration instructions, see the Amazon VPC documentation. | AWS administrator |
| Task | Description | Skills required |
|---|---|---|
Initialize Elastic Disaster Recovery. | Open the Elastic Disaster Recovery console | AWS administrator |
Set up replication servers. |
| AWS administrator |
Configure volumes and security groups. |
| AWS administrator |
Configure additional settings. |
| AWS administrator |
| Task | Description | Skills required |
|---|---|---|
Create an IAM role. | Create an IAM role that contains the | AWS administrator |
Check requirements. | Check and complete the prerequisites in the Elastic Disaster Recovery documentation for installing the AWS Replication Agent. | AWS administrator |
Install the AWS Replication Agent. | Follow the installation instructions for your operating system and install the AWS Replication Agent.
Repeat these steps for the remaining server. | AWS administrator |
Monitor the replication. | Return to the Elastic Disaster Recovery Source servers pane to monitor the replication status. The initial sync will take some time depending on the size of the data transfer. When the source server is fully synced, the server status will be updated to Ready. This means that a replication server has been created in the staging area, and the EBS volumes have been replicated from the source server to the staging area. | AWS administrator |
| Task | Description | Skills required |
|---|---|---|
Edit launch settings. | To update the launch settings for the drill and recovery instances, on the Elastic Disaster Recovery console | AWS administrator |
Configure general launch settings. | Revise the general launch settings according to your requirements.
For more information, see General launch settings in the Elastic Disaster Recovery documentation. | AWS administrator |
Configure the Amazon EC2 launch template. | Elastic Disaster Recovery uses Amazon EC2 launch templates to launch drill and recovery instances for each source server. The launch template is created automatically for each source server that you add to Elastic Disaster Recovery after you install the AWS Replication Agent. You must set the Amazon EC2 launch template as the default launch template if you want to use it with Elastic Disaster Recovery. For more information, see EC2 Launch Template in the Elastic Disaster Recovery documentation. | AWS administrator |
| Task | Description | Skills required |
|---|---|---|
Initiate Drill |
For more information, see Preparing for failover in the Elastic Disaster Recovery documentation. | AWS administrator |
Validate the drill. | In the previous step, you launched new target instances in the DR Region. The target instances are replicas of the source servers based on the snapshot taken when you initiated the launch. In this procedure, you connect to your Amazon EC2 target machines to confirm that they're running as expected.
| |
Initiate a failover. | A failover is the redirection of traffic from a primary system to a secondary system. Elastic Disaster Recovery helps you perform a failover by launching recovery instances on AWS. When the recovery instances have been launched, you redirect the traffic from your primary systems to these instances.
For more information, see Performing a failover in the Elastic Disaster Recovery documentation. | AWS administrator |
Initiate a failback. | The process for initiating a failback is similar to the process for initiating failover.
For more information, see Performing a failback in the Elastic Disaster Recovery documentation. | AWS administrator |
Start JD Edwards EnterpriseOne components. |
You will need to make incorporate the changes in Route 53 and Application Load Balancer for the JD Edwards EnterpriseOne link to work. You can automate these steps by using Lambda, Step Functions, and Systems Manager (Run Command). NoteElastic Disaster Recovery performs block-level replication of the source EC2 instance EBS volumes that host the operating system and file systems. Shared file systems that were created by using Amazon EFS aren’t part of this replication. You can replicate shared file systems to the DR Region by using AWS DataSync, as noted in the first epic, and then mount these replicated file systems in the DR system. | JD Edwards EnterpriseOne CNC |
Troubleshooting
| Issue | Solution |
|---|---|
Source server data replication status is Stalled and replication lags. If you check details, the data replication status displays Agent not seen. | Check to confirm that the stalled source server is running. NoteIf the source server goes down, the replication server is automatically terminated. For more information about lag issues, see Replication lag issues in the Elastic Disaster Recovery documentation. |
Installation of AWS Replication Agent in source EC2 instance fails in RHEL 8.2 after scanning the disks. | Before you install the AWS Replication Agent on RHEL 8, CentOS 8, or Oracle Linux 8, run:
For more information, see Linux installation requirements in the Elastic Disaster Recovery documentation. |
On the Elastic Disaster Recovery console, you see the source server as Ready with a lag and data replication status as Stalled. Depending on how long the AWS Replication Agent has been unavailable, the status might indicate high lag, but the issue remains the same. | Use an operating system command to confirm that the AWS Replication Agent is running in the source EC2 instance, or confirm that the instance is running. After you correct any issues, Elastic Disaster Recovery will restart scanning. Wait until all data has been synced and the replication status is Healthy before you start a DR drill. |
Initial replication with high lag. On the Elastic Disaster Recovery console, you can see that the initial sync status is extremely slow for a source server. | Check for the replication lag issues documented in the Replication lag issues section of the Elastic Disaster Recovery documentation. The replication server might be unable to handle the load because of intrinsic compute operations. In that case, try upgrading the instance type after consulting with the AWS Technical Support team |
Related resources
Creating a scalable disaster recovery plan with AWS Elastic Disaster Recovery
(AWS blog post) AWS Elastic Disaster Recovery - A Technical Introduction
(AWS Skill Builder course; requires login)
