Usar machine learning do Amazon Aurora com o Aurora PostgreSQL
Ao usar o machine learning do Amazon Aurora com o cluster de banco de dados do Aurora PostgreSQL, é possível usar o Amazon Comprehend, o Amazon SageMaker AI ou o Amazon Bedrock, dependendo das necessidades. Esses serviços oferecem compatibilidade com casos de uso de machine learning específicos.
O machine learning do Aurora é compatível somente com determinadas Regiões da AWS e versões específicas do Aurora PostgreSQL. Antes de tentar configurar o machine learning do Aurora, confira a disponibilidade de sua versão do Aurora PostgreSQL e sua região. Para obter detalhes, consulte Machine learning do Aurora com o Aurora PostgreSQL.
Tópicos
Requisitos para usar o machine learning do Aurora com o Aurora PostgreSQL
Recursos compatíveis e limitações do machine learning do Aurora com o Aurora PostgreSQL
Configurar o cluster de banco de dados do Aurora PostgreSQL para usar machine learning do Aurora
Usar o Amazon Bedrock com o cluster de banco de dados do Aurora PostgreSQL
Usar o Amazon Comprehend com o cluster de banco de dados do Aurora PostgreSQL
Uso do SageMaker AI com o cluster de banco de dados do Aurora PostgreSQL
Exportar dados ao Amazon S3 para treinamento de modelos do SageMaker AI (avançado)
Considerações sobre performance para usar o machine learning do Aurora com o Aurora PostgreSQL
Requisitos para usar o machine learning do Aurora com o Aurora PostgreSQL
Os serviços do AWS Machine Learning são serviços gerenciados que são configurados e executados em seus próprios ambientes de produção. O machine learning do Aurora é compatível com a integração ao Amazon Comprehend, ao SageMaker AI e ao Amazon Bedrock. Antes de tentar configurar o cluster de banco de dados do Aurora PostgreSQL para usar o machine learning do Aurora, entenda os requisitos e pré-requisitos a seguir.
Os serviços Amazon Comprehend, SageMaker AI e Amazon Bedrock devem estar em execução na mesma Região da AWS que o cluster de banco de dados do Aurora PostgreSQL. Não é possível usar os serviços Amazon Comprehend, SageMaker AI e Amazon Bedrock de um cluster de banco de dados do Aurora PostgreSQL em uma região diferente.
Se o cluster de banco de dados do Aurora PostgreSQL estiver em uma nuvem pública virtual (VPC) baseada no serviço Amazon VPC diferente dos serviços Amazon Comprehend e SageMaker AI, o grupo de segurança da VPC precisará permitir conexões de saída com o serviço de machine learning do Aurora de destino. Para ter mais informações, consulte Permitir a comunicação de rede do Amazon Aurora com outros serviços da AWS.
Para o SageMaker AI, os componentes de machine learning que você deseja usar para inferências devem estar configurados e prontos para uso. Durante o processo de configuração do cluster de banco de dados do Aurora PostgreSQL, é necessário ter o nome do recurso da Amazon (ARN) do endpoint do SageMaker AI disponível. Os cientistas de dados de sua equipe provavelmente estão mais aptos a trabalhar com o SageMaker AI para preparar os modelos e realizar outras tarefas desse tipo. Para começar a usar o Amazon SageMaker AI, consulte Comece a usar o Amazon SageMaker AI. Para obter mais informações sobre inferências e endpoints, consulte Real-time Inference.
-
Para o Amazon Bedrock, é necessário ter o ID dos modelos do Bedrock que você deseja usar para inferências disponíveis durante o processo de configuração do cluster de banco de dados do Aurora PostgreSQL. Os cientistas de dados da equipe provavelmente estão mais aptos a trabalhar com o Bedrock para decidir quais modelos usar, ajustá-los se necessário e realizar outras tarefas desse tipo. Para começar a usar o Amazon Bedrock, consulte How to setup Bedrock.
-
Os usuários do Amazon Bedrock precisam solicitar acesso aos modelos antes que eles estejam disponíveis para uso. Se você quiser adicionar modelos adicionais para geração de texto, bate-papo e imagem, precisará solicitar acesso aos modelos no Amazon Bedrock. Para ter mais informações, consulte Model access.
Recursos compatíveis e limitações do machine learning do Aurora com o Aurora PostgreSQL
Atualmente, o machine learning do Aurora é compatível com qualquer endpoint do SageMaker AI que possa ler e gravar no formato de valores separados por vírgula (CSV), por meio de um valor de ContentType de text/csv. Os formatos incorporados do SageMaker AI que atualmente aceitam esse formato são os seguintes.
Aprendizagem linear
Random Cut Forest
XGBoost
Para saber mais sobre esses algoritmos, consulte Selecionar um algoritmo no Guia do desenvolvedor do Amazon SageMaker AI.
Ao usar o Amazon Bedrock com o machine learning do Aurora, existem as seguintes limitações:
-
As funções definidas pelo usuário (UDFs) oferecem um modo nativo de interagir com o Amazon Bedrock. As UDFs não têm requisitos específicos de solicitação ou resposta, portanto, podem usar qualquer modelo.
-
É possível usar UDFs para criar qualquer fluxo de trabalho desejado. Por exemplo, é possível combinar primitivas básicas, como
pg_cron, executar uma consulta, buscar dados, gerar inferências e gravar em tabelas para atender a consultas diretamente. -
As UDFs não são compatíveis com chamadas em lote ou paralelas.
-
A extensão de Machine Learning do Aurora não é compatível com interfaces de vetor. Como parte da extensão, uma função está disponível para gerar as incorporações da resposta do modelo no formato
float8[]para armazenar essas incorporações no Aurora. Para ter mais informações sobre o uso defloat8[], consulte Usar o Amazon Bedrock com o cluster de banco de dados do Aurora PostgreSQL.
Configurar o cluster de banco de dados do Aurora PostgreSQL para usar machine learning do Aurora
Para que o machine learning do Aurora funcione com seu cluster de banco de dados do Aurora PostgreSQL, você precisa criar um perfil do AWS Identity and Access Management (IAM) para cada um dos serviços que você deseja usar. O perfil do IAM permite que seu cluster de banco de dados do Aurora PostgreSQL use o serviço de machine learning do Aurora em nome do cluster. Você também precisa instalar a extensão de machine learning do Aurora. Nos tópicos a seguir, você pode encontrar procedimentos de configuração para cada um desses serviços de machine learning do Aurora.
Tópicos
Configurar o Aurora PostgreSQL para usar o Amazon Bedrock
No procedimento a seguir, primeiro crie o perfil do IAM e a política que concede permissão ao Aurora PostgreSQL para usar o Amazon Bedrock em nome do cluster. Depois, anexe a política a um perfil do IAM que o cluster de banco de dados do Aurora PostgreSQL usa para trabalhar com o Amazon Bedrock. Para simplificar, esse procedimento usa o AWS Management Console para concluir todas as tarefas.
Como configurar o cluster de banco de dados do Aurora PostgreSQL para usar o Amazon Bedrock
Faça login no AWS Management Console e abra o console do IAM, em https://console.aws.amazon.com/iam/
. Abra o console do IAM, em https://console.aws.amazon.com/iam/
. Selecione Policies (Políticas) [em Access management (Gerenciamento de acesso)] no menu do console do AWS Identity and Access Management (IAM).
Escolha Criar política. Na página Editor visual, selecione Serviço e, depois, insira Bedrock no campo Selecionar um serviço. Expanda o nível de acesso de leitura. Selecione InvokeModel nas configurações de leitura do Amazon Bedrock.
Selecione o modelo de base/provisionado ao qual você deseja conceder acesso de leitura por meio da política.
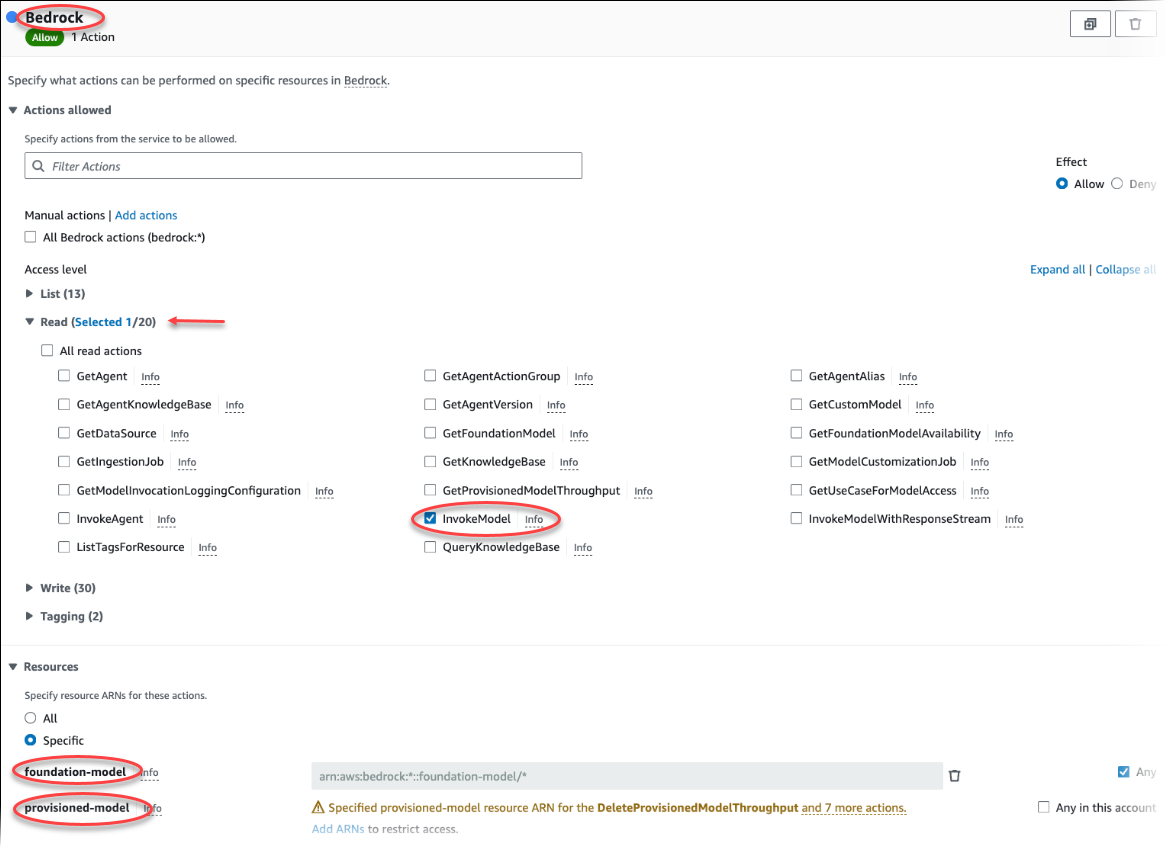
Selecione Next: Tags (Próximo: tags) e defina todas as tags (isso é opcional). Escolha Próximo: revisar. Insira um nome para a política e uma descrição, conforme mostrado na imagem.
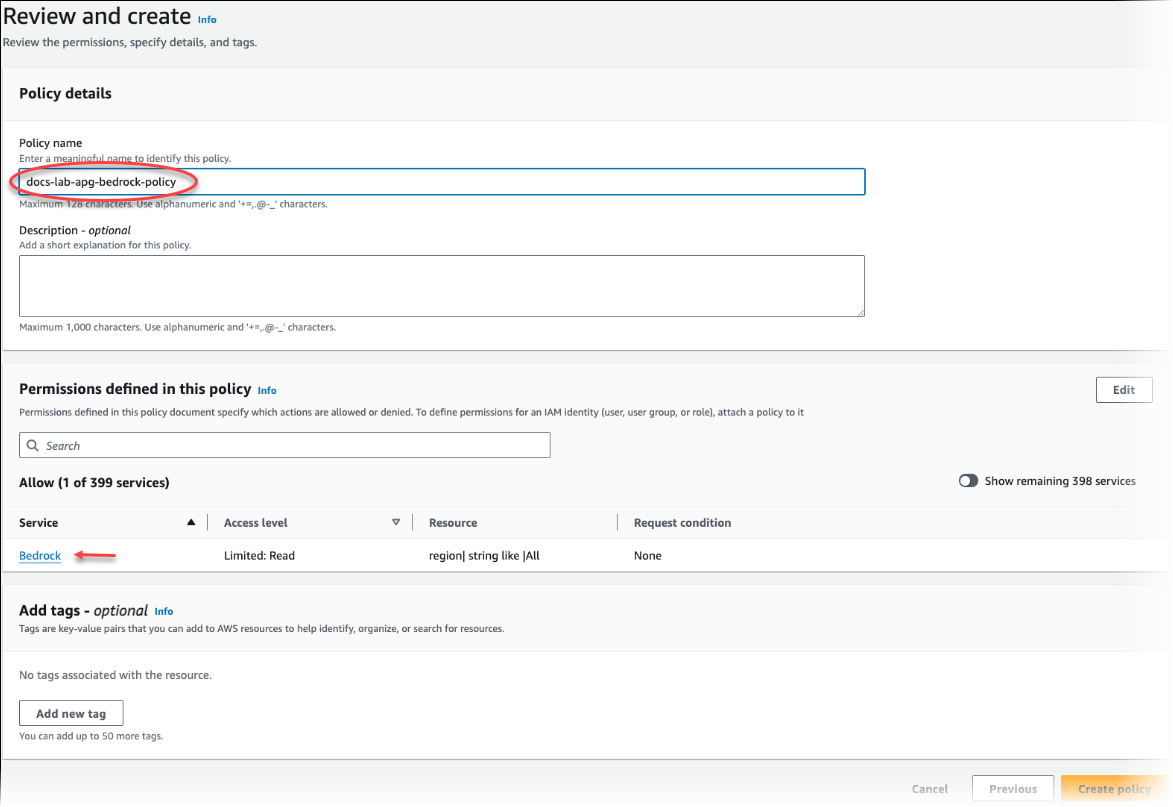
Escolha Criar política. O console exibe um alerta quando a política é salva. Você pode encontrá-la na lista de políticas.
Selecione Roles (Perfis) [em Access management (Gerenciamento de acesso)] no menu do console do IAM.
Selecione Criar perfil.
Na página Selecionar entidade confiável, escolha o bloco Serviço da AWS e, depois, selecione RDS para abrir o seletor.
Selecione RDS – Add Role to Database (RDS: adicionar função ao banco de dados)
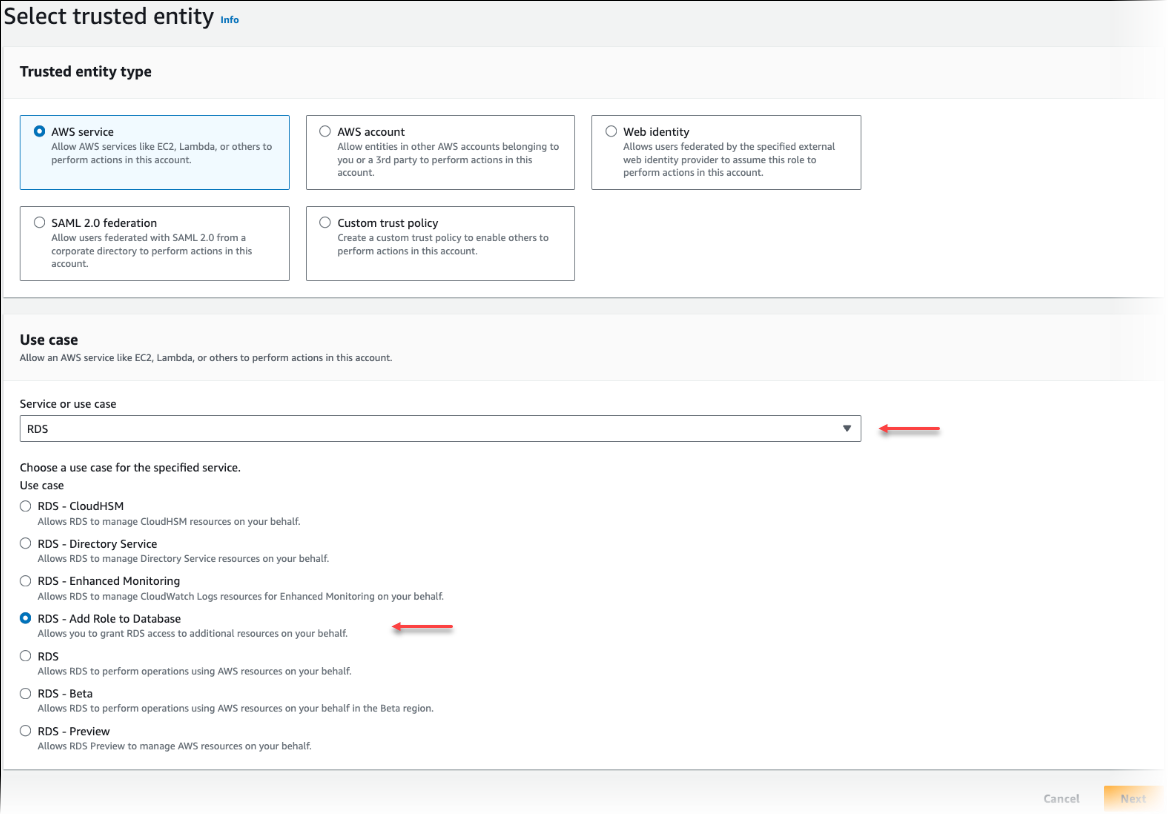
Escolha Próximo. Na página Add permissions (Adicionar permissões), localize a política que você criou na etapa anterior e selecione-a entre as listadas. Escolha Próximo.
Next: Review (Próximo: revisar). Digite um nome para o perfil do IAM e uma descrição.
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. Navegue até a Região da AWS onde está seu cluster de banco de dados do Aurora PostgreSQL.
-
No painel de navegação, selecione Bancos de dados e, depois, selecione o cluster de banco de dados do Aurora PostgreSQL que deseja usar com o Bedrock.
-
Selecione a guia Connectivity & security (Conectividade e segurança) e role para baixo até a seção Manage IAM roles (Gerenciar perfis do IAM) da página. Em Add IAM roles to this cluster (Adicionar perfis do IAM a este seletor de cluster), selecione a função que você criou nas etapas anteriores. No seletor Recurso, selecione Bedrock e, depois, Adicionar perfil.
O perfil (com sua política) é associado ao cluster de banco de dados do Aurora PostgreSQL. Quando o processo for concluído, o perfil será exibido na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster), conforme mostrado a seguir.
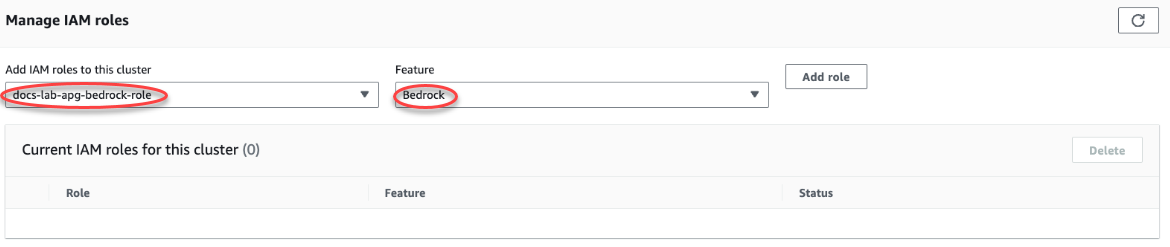
A configuração do IAM para o Amazon Bedrock está concluída. Continue configurando o Aurora PostgreSQL para trabalhar com o machine learning do Aurora instalando a extensão conforme detalhado em Instalar a extensão de machine learning do Aurora
Configurar o Aurora PostgreSQL para usar o Amazon Comprehend
No procedimento a seguir, você primeiro cria o perfil do IAM e a política que concede permissão ao Aurora PostgreSQL para usar o Amazon Comprehend em nome do cluster. Depois, anexe a política a um perfil do IAM que seu cluster de banco de dados do Aurora PostgreSQL usa para trabalhar com o Amazon Comprehend. Para simplificar, esse procedimento usa o AWS Management Console para concluir todas as tarefas.
Como configurar o cluster de banco de dados do Aurora PostgreSQL para usar o Amazon Comprehend
Faça login no AWS Management Console e abra o console do IAM, em https://console.aws.amazon.com/iam/
. Abra o console do IAM, em https://console.aws.amazon.com/iam/
. Selecione Policies (Políticas) [em Access management (Gerenciamento de acesso)] no menu do console do AWS Identity and Access Management (IAM).
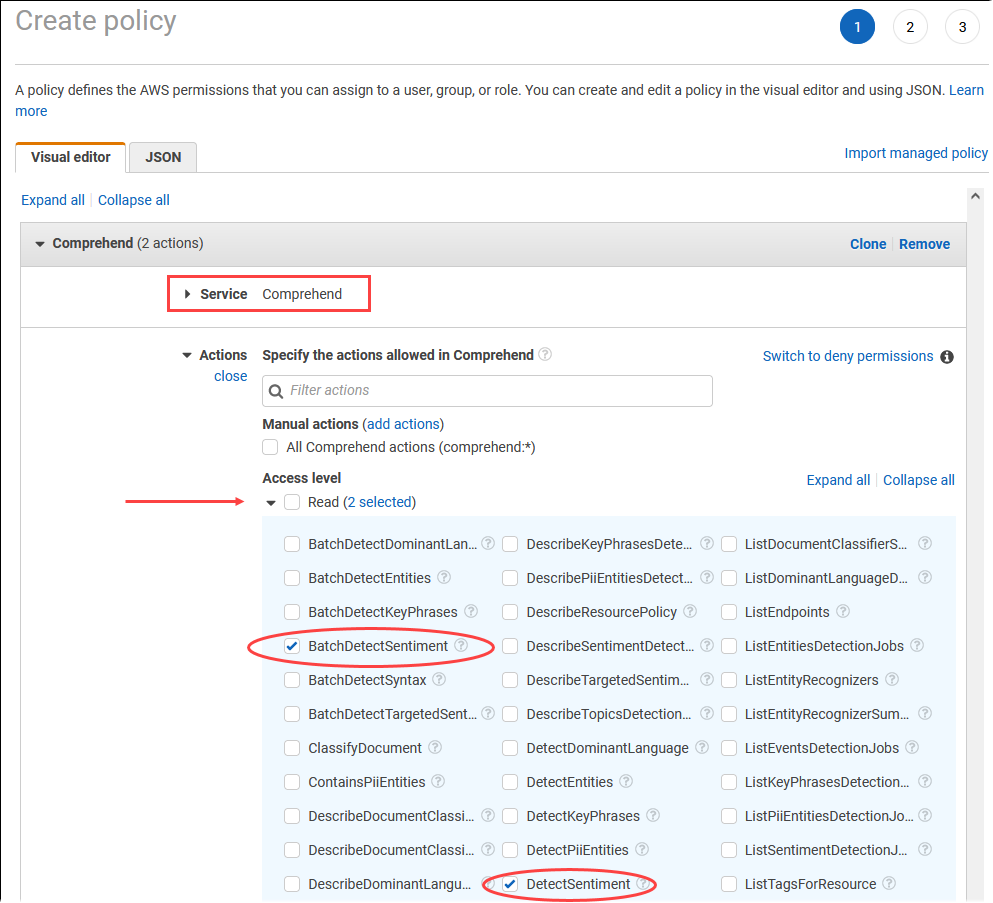
Escolha Criar política. Na página Visual editor (Editor visual), selecione Service (Serviço) e depois insira Comprehend no campo Select a service (Selecionar um serviço). Expanda o nível de acesso de leitura. Selecione BatchDetectSentiment e DetectSentiment nas configurações de leitura do Amazon Comprehend.
Selecione Next: Tags (Próximo: tags) e defina todas as tags (isso é opcional). Escolha Próximo: revisar. Insira um nome para a política e uma descrição, conforme mostrado na imagem.
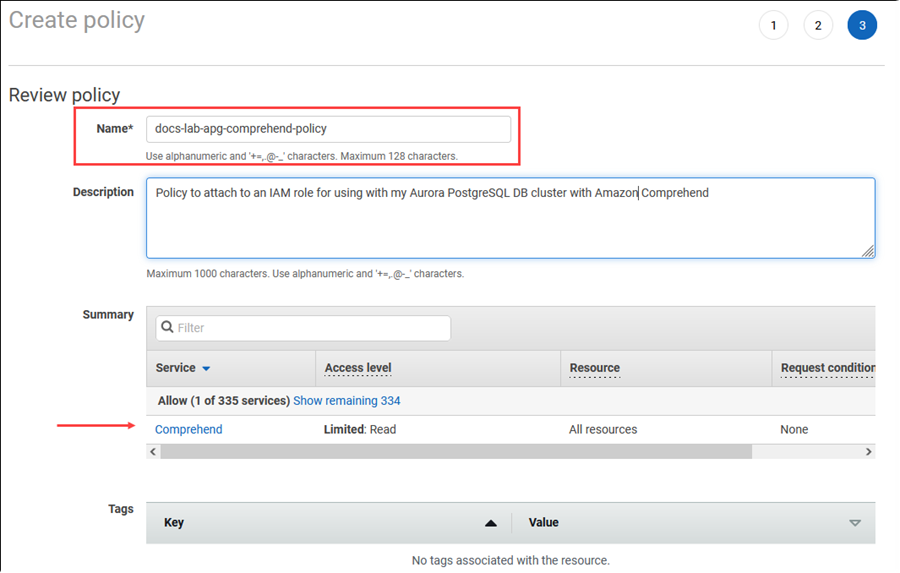
Escolha Criar política. O console exibe um alerta quando a política é salva. Você pode encontrá-la na lista de políticas.
Selecione Roles (Perfis) [em Access management (Gerenciamento de acesso)] no menu do console do IAM.
Selecione Criar perfil.
Na página Selecionar entidade confiável, escolha o bloco Serviço da AWS e, depois, selecione RDS para abrir o seletor.
Selecione RDS – Add Role to Database (RDS: adicionar função ao banco de dados)
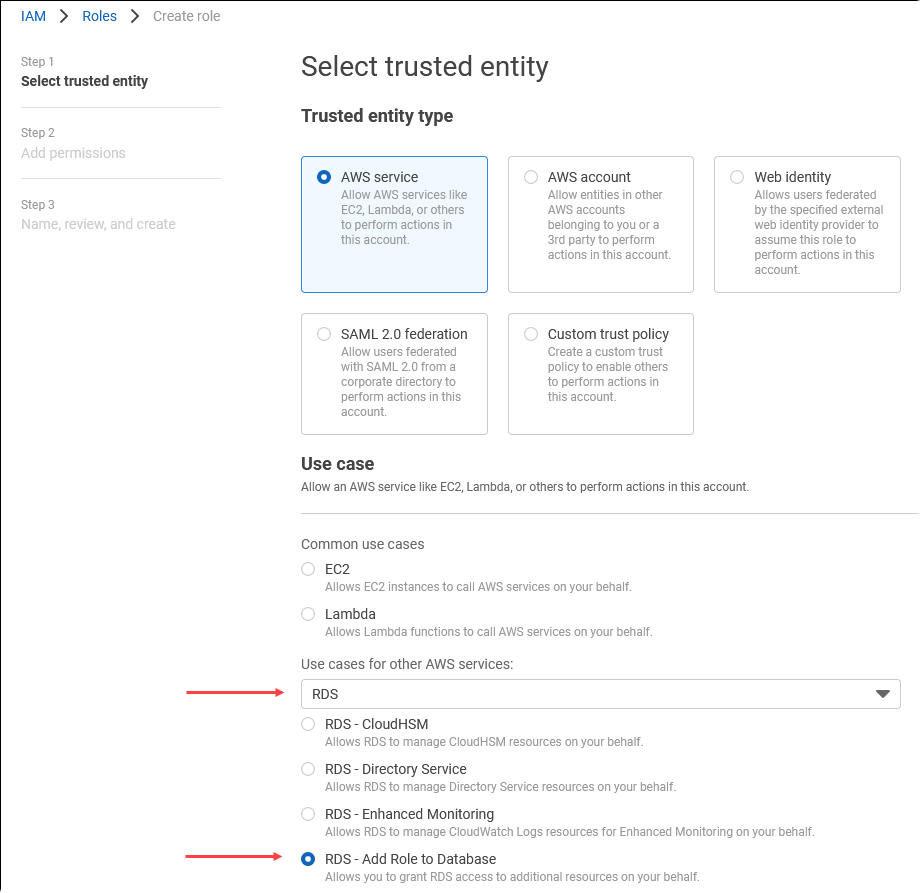
Escolha Próximo. Na página Add permissions (Adicionar permissões), localize a política que você criou na etapa anterior e selecione-a entre as listadas. Escolha Next (Próximo).
Next: Review (Próximo: revisar). Digite um nome para o perfil do IAM e uma descrição.
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. Navegue até a Região da AWS onde está seu cluster de banco de dados do Aurora PostgreSQL.
-
No painel de navegação, selecione Databases (Bancos de dados) e selecione o cluster de banco de dados do Aurora PostgreSQL que deseja usar com o Amazon Comprehend.
-
Selecione a guia Connectivity & security (Conectividade e segurança) e role para baixo até a seção Manage IAM roles (Gerenciar perfis do IAM) da página. Em Add IAM roles to this cluster (Adicionar perfis do IAM a este seletor de cluster), selecione a função que você criou nas etapas anteriores. No seletor Recurso, escolha Comprehend e depois Adicionar perfil.
O perfil (com sua política) é associado ao cluster de banco de dados do Aurora PostgreSQL. Quando o processo for concluído, o perfil será exibido na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster), conforme mostrado a seguir.
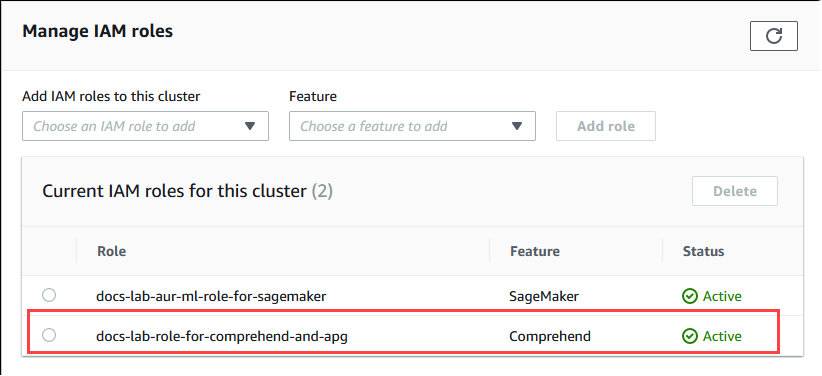
A integração do IAM para o Amazon Comprehend está concluída. Continue configurando o Aurora PostgreSQL para trabalhar com o machine learning do Aurora instalando a extensão conforme detalhado em Instalar a extensão de machine learning do Aurora
Configuração do Aurora PostgreSQL para usar o Amazon SageMaker AI
Antes de criar a política e o perfil do IAM para seu cluster de banco de dados do Aurora PostgreSQL, você precisa ter seu modelo do SageMaker AI configurado e seu endpoint disponíveis.
Como configurar o cluster de banco de dados do Aurora PostgreSQL para usar o SageMaker AI
Faça login no AWS Management Console e abra o console do IAM, em https://console.aws.amazon.com/iam/
. Selecione Policies (Políticas) [em Access management (Gerenciamento de acesso)] no menu do console do AWS Identity and Access Management (IAM) e depois selecione Create policy (Criar política). No editor visual, selecione SageMaker para o serviço. Em Actions (Ações), abra o seletor de leitura [em Access level (Nível de acesso)] e selecione InvokeEndpoint. Ao fazer isso, um ícone de aviso é exibido.
Abra o seletor Resources (Recursos) e clique no link Add ARN to restrict access (Adicionar ARN para restringir o acesso) em Specify endpoint resource ARN (Especificar ARN do recurso de endpoint) para a ação InvokeEndpoint.
Insira a Região da AWS dos recursos do SageMaker AI e o nome do endpoint. Sua conta AWS é pré-preenchida.
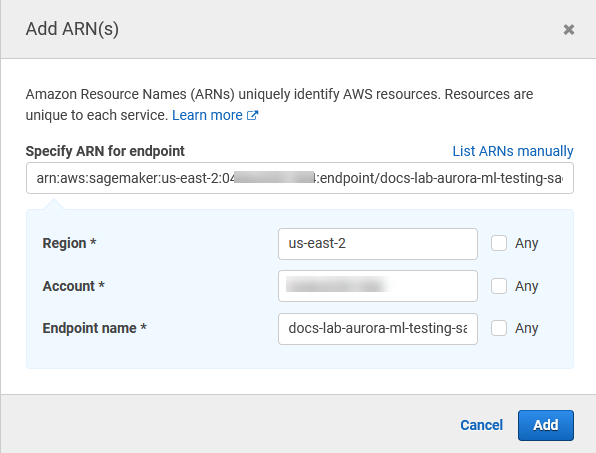
Selecione Add (Adicionar) para salvar. Selecione Next: Tags (Próximo: tags) e Next: Review (Próximo: revisar) para acessar a última página do processo de criação da política.
Insira um nome e uma descrição para essa política e depois selecione Create policy (Criar política). A política é criada e adicionada à lista Policies (Políticas). Você vê um alerta no console quando isso ocorre.
No console do IAM, selecione Roles (Funções).
Selecione Criar perfil.
Na página Selecionar entidade confiável, escolha o bloco Serviço da AWS e, depois, selecione RDS para abrir o seletor.
Selecione RDS – Add Role to Database (RDS: adicionar função ao banco de dados)
Escolha Próximo. Na página Add permissions (Adicionar permissões), localize a política que você criou na etapa anterior e selecione-a entre as listadas. Escolha Next (Próximo).
Next: Review (Próximo: revisar). Digite um nome para o perfil do IAM e uma descrição.
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. Navegue até a Região da AWS onde está seu cluster de banco de dados do Aurora PostgreSQL.
-
No painel de navegação, selecione Bancos de dados e o cluster de banco de dados do Aurora PostgreSQL que deseja usar com o SageMaker AI.
-
Selecione a guia Connectivity & security (Conectividade e segurança) e role para baixo até a seção Manage IAM roles (Gerenciar perfis do IAM) da página. Em Add IAM roles to this cluster (Adicionar perfis do IAM a este seletor de cluster), selecione a função que você criou nas etapas anteriores. No seletor Recurso, selecione SageMaker AI e depois Adicionar perfil.
O perfil (com sua política) é associado ao cluster de banco de dados do Aurora PostgreSQL. Quando o processo for concluído, o perfil será exibido na lista Current IAM roles for this cluster (Perfis atuais do IAM para esse cluster).
A configuração do IAM para o SageMaker AI foi concluída. Continue configurando o Aurora PostgreSQL para trabalhar com o machine learning do Aurora instalando a extensão conforme detalhado em Instalar a extensão de machine learning do Aurora
Configuração do Aurora PostgreSQL para usar o Amazon S3 para SageMaker AI (avançado)
Para usar o SageMaker AI com seus próprios modelos em vez de usar componentes pré-criados fornecidos pelo SageMaker AI, é necessário configurar um bucket do Amazon Simple Storage Service (Amazon S3) para o cluster de banco de dados do Aurora PostgreSQL usar. Esse é um tópico avançado e não está totalmente documentado neste Guia do usuário do Amazon Aurora. O processo geral é o mesmo para integrar o suporte para o SageMaker AI, da seguinte forma.
Crie a política e o perfil do IAM para o Amazon S3.
Adicione o perfil do IAM e a importação ou a exportação do Amazon S3 como um recurso na guia Connectivity & security (Conectividade e segurança) do cluster de banco de dados do Aurora PostgreSQL.
Adicione o ARN do perfil do IAM ao grupo de parâmetros do cluster de banco de dados personalizado para cada cluster de banco de dados do Aurora.
Para obter informações de uso básicas, consulte Exportar dados ao Amazon S3 para treinamento de modelos do SageMaker AI (avançado).
Instalar a extensão de machine learning do Aurora
As extensões de machine learning do Aurora aws_ml 1.0 fornecem duas funções que você pode usar para invocar os serviços Amazon Comprehend e SageMaker AI e aws_ml 2.0 fornece duas funções adicionais que você pode usar para invocar os serviços do Amazon Bedrock. A instalação dessas extensões no cluster de banco de dados do Aurora PostgreSQL também cria um perfil administrativo para o recurso.
nota
O uso dessas funções depende da conclusão da configuração do IAM para o serviço de machine learning do Aurora (Amazon Comprehend, SageMaker AI, Amazon Bedrock), conforme detalhado em Configurar o cluster de banco de dados do Aurora PostgreSQL para usar machine learning do Aurora.
aws_comprehend.detect_sentiment: você usa essa função para aplicar a análise de sentimentos ao texto armazenado no banco de dados do cluster de banco de dados do Aurora PostgreSQL.
aws_sagemaker.invoke_endpoint: você usa essa função em seu código SQL para se comunicar com o endpoint do SageMaker AI a partir de seu cluster.
aws_bedrock.invoke_model: use essa função no código SQL para se comunicar com os modelos do Bedrock por meio do cluster. A resposta dessa função será no formato de um TEXTO, portanto, se um modelo responder no formato de um corpo JSON, a saída dessa função será retransmitida no formato de string para o usuário final.
aws_bedrock.invoke_model_get_embeddings: use essa função no código SQL para invocar modelos do Bedrock que exibem incorporações de saída em uma resposta JSON. Isso pode ser utilizado quando você deseja extrair as incorporações diretamente associadas à chave json para agilizar a resposta com qualquer fluxo de trabalho autogerenciado.
Como instalar a extensão de machine learning do Aurora no cluster de banco de dados do Aurora PostgreSQL
Use o
psqlpara se conectar à instância do gravador do cluster de banco de dados do Aurora PostgreSQL. Conecte-se ao banco de dados específico no qual a extensãoaws_mlserá instalada.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
A instalação das extensões aws_ml também cria a função administrativa aws_ml e três esquemas, da forma a seguir.
aws_comprehend: esquema para o serviço Amazon Comprehend e fonte da funçãodetect_sentiment(aws_comprehend.detect_sentiment).aws_sagemaker: esquema para o serviço SageMaker AI e fonte da funçãoinvoke_endpoint(aws_sagemaker.invoke_endpoint).aws_bedrock: esquema para o serviço do Amazon Bedrock e origem das funçõesinvoke_model(aws_bedrock.invoke_model)einvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings).
O perfil rds_superuser recebe a função administrativa aws_ml e torna-se o OWNER desses três esquemas de machine learning do Aurora. Para permitir que outros usuários do banco de dados acessem as funções de machine learning do Aurora, o rds_superuser precisa conceder privilégios EXECUTE nas funções de machine learning do Aurora. Por padrão, os privilégios EXECUTE são revogados de PUBLIC nas funções nos dois esquemas de machine learning do Aurora.
Em uma configuração de banco de dados multilocatário, você pode impedir que os locatários acessem as funções de machine learning do Aurora usando REVOKE USAGE no esquema específico de machine learning do Aurora que você deseja proteger.
Usar o Amazon Bedrock com o cluster de banco de dados do Aurora PostgreSQL
Para o Aurora PostgreSQL, o machine learning do Aurora oferece a função do Amazon Bedrock a seguir para trabalhar com os dados de texto. Essa função está disponível somente após a instalação da extensão aws_ml 2.0 e a conclusão de todos os procedimentos de configuração. Para ter mais informações, consulte Configurar o cluster de banco de dados do Aurora PostgreSQL para usar machine learning do Aurora.
- aws_bedrock.invoke_model
-
Essa função usa texto formatado em JSON como entrada, o processa para vários modelos hospedados no Amazon Bedrock e recupera a resposta de texto JSON do modelo. Essa resposta pode conter texto, imagem ou incorporações. Veja um resumo da documentação da função.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
As entradas e as saídas dessa função são as seguintes.
-
model_id: identificador do modelo. content_type: o tipo da solicitação ao modelo do Bedrock.accept_type: o tipo da resposta que se espera do modelo do Bedrock. Normalmente a aplicação/JSON para a maioria dos modelos.model_input: prompts; um conjunto específico de entradas para o modelo no formato especificado por content_type. Para ter mais informações sobre o formato/estrutura da solicitação que o modelo aceita, consulte Inference parameters for foundation models.model_output: a saída do modelo do Bedrock como texto.
O exemplo a seguir mostra como invocar um modelo do Anthropic Claude 2 para o Bedrock usando invoke_model.
exemplo Exemplo: uma consulta simples utilizando as funções do Amazon Bedrock
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
A saída do modelo pode apontar para incorporações de vetores em alguns casos. Como a resposta varia de acordo com o modelo, pode ser utilizada outra função invoke_model_get_embeddings, que funciona exatamente como a invoke_model, mas gera as incorporações especificando a chave json apropriada.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
As entradas e as saídas dessa função são as seguintes.
-
model_id: identificador do modelo. content_type: o tipo da solicitação ao modelo do Bedrock. Aqui, o accept_type é definido como o valor padrãoapplication/json.model_input: prompts; um conjunto específico de entradas para o modelo no formato especificado por content_type. Para ter mais informações sobre o formato/estrutura da solicitação que o modelo aceita, consulte Inference parameters for foundation models.json_key: referência ao campo do qual extrair a incorporação. Isso pode variar se o modelo de incorporação mudar.-
model_output: a saída do modelo do Bedrock como uma matriz de incorporações com decimais de 16 bits.
O exemplo a seguir mostra como gerar uma incorporação usando o modelo de incorporação de texto do Titan Embeddings G1 para a frase de visualizações de monitoramento de E/S do PostgreSQL.
exemplo Exemplo: uma consulta simples utilizando as funções do Amazon Bedrock
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Usar o Amazon Comprehend com o cluster de banco de dados do Aurora PostgreSQL
Para o Aurora PostgreSQL, o machine learning do Aurora fornece a função do Amazon Comprehend a seguir para trabalhar com seus dados de texto. Essa função está disponível somente após a instalação da extensão aws_ml e a conclusão de todos os procedimentos de configuração. Para obter mais informações, consulte Configurar o cluster de banco de dados do Aurora PostgreSQL para usar machine learning do Aurora.
- aws_comprehend.detect_sentiment
-
Essa função usa o texto como entrada e avalia se ele tem uma postura emocional positiva, negativa, neutra ou mista. Ela gera esse sentimento junto com um nível de confiança para sua avaliação. Veja um resumo da documentação da função.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
As entradas e as saídas dessa função são as seguintes.
-
input_text: o texto para avaliar e atribuir o sentimento (negativo, positivo, neutro, misto). language_code: o idioma doinput_textidentificado usando o identificador ISO 639-1 de duas letras com subtag regional (conforme necessário) ou o código ISO 639-2 de três letras, conforme apropriado. Por exemplo,ené o código para inglês,zhé o código para chinês simplificado. Para obter mais informações, consulte Linguagens compatíveis no Guia do desenvolvedor do Amazon Comprehend.max_rows_per_batch: o número máximo de linhas por lote para processamento no modo em lote. Para obter mais informações, consulte Noções básicas sobre o modo em lote e as funções de machine learning do Aurora.sentiment: o sentimento do texto de entrada, identificado como POSITIVO, NEGATIVO, NEUTRO ou MISTO.confidence: o nível de confiança na precisão dosentimentespecificado. Os valores variam de 0,0 a 1,0.
Veja exemplos de como usar essa função.
exemplo Exemplo: uma consulta simples utilizando as funções do Amazon Comprehend
Veja a seguir um exemplo de uma consulta simples que invoca essa função para avaliar a satisfação do cliente com sua equipe de atendimento. Suponha que você tenha uma tabela de banco de dados (support) que armazene o feedback do cliente após cada solicitação de ajuda. Essa consulta de exemplo aplica a função aws_comprehend.detect_sentiment ao texto na coluna feedback da tabela e gera o sentimento e o nível de confiança desse sentimento. Essa consulta também gera resultados em ordem decrescente.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Para evitar que você seja cobrado pela detecção de sentimento mais de uma vez por linha da tabela, você pode materializar os resultados. Faça isso nas linhas de interesse. Por exemplo, as anotações do médico estão sendo atualizadas para que somente as em francês (fr) usem a função de detecção de sentimento.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Para obter mais informações sobre como otimizar suas chamadas de função, consulte Considerações sobre performance para usar o machine learning do Aurora com o Aurora PostgreSQL.
Uso do SageMaker AI com o cluster de banco de dados do Aurora PostgreSQL
Depois de configurar seu ambiente do SageMaker AI e integrá-lo ao Aurora PostgreSQL, conforme descrito em Configuração do Aurora PostgreSQL para usar o Amazon SageMaker AI , você pode invocar as operações utilizando a função aws_sagemaker.invoke_endpoint. A função aws_sagemaker.invoke_endpoint se conecta somente a um endpoint de modelo na mesma Região da AWS. Se sua instância de banco de dados tiver réplicas em várias Regiões da AWS, configure e implante todos os modelos do SageMaker AI em cada Região da AWS.
As chamadas para aws_sagemaker.invoke_endpoint são autenticadas utilizando o perfil do IAM que você configurou para associar o cluster de banco de dados do Aurora PostgreSQL ao serviço SageMaker AI e ao endpoint fornecido durante o processo de configuração. Os endpoints de modelos do SageMaker AI têm o escopo de uma conta individual e não são públicos. A URL endpoint_name não contém o ID da conta. O SageMaker AI determina o ID da conta no token de autenticação fornecido pelo perfil do IAM do SageMaker AI da instância do banco de dados.
- aws_sagemaker.invoke_endpoint
Essa função usa o endpoint do SageMaker AI como entrada e o número de linhas que devem ser processadas como um lote. Ele também usa como entrada os vários parâmetros esperados pelo endpoint do modelo do SageMaker AI. A documentação de referência dessa função é a seguinte.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
As entradas e as saídas dessa função são as seguintes.
endpoint_name: um URL de um endpoint que é independente da Região da AWS.max_rows_per_batch: o número máximo de linhas por lote para processamento no modo em lote. Para obter mais informações, consulte Noções básicas sobre o modo em lote e as funções de machine learning do Aurora.model_input: um ou mais parâmetros de entrada para o modelo. Esses podem ser qualquer tipo de dados necessário para o modelo do SageMaker AI. O PostgreSQL permite especificar até 100 parâmetros de entrada para uma função. Os tipos de dados de matriz devem ser unidimensionais, mas podem conter tantos elementos quantos forem esperados pelo modelo do SageMaker AI. O número de entradas para um modelo do SageMaker AI é restringido apenas pelo limite de tamanho de mensagem de 6 MB do SageMaker AI.model_output: a saída do modelo do SageMaker AI como texto.
Criação de uma função definida pelo usuário para chamar um modelo do SageMaker AI
Crie uma função definida pelo usuário separada para chamar aws_sagemaker.invoke_endpoint para cada um de seus modelos do SageMaker AI. A função definida pelo usuário representa o endpoint do SageMaker AI que hospeda o modelo. A função aws_sagemaker.invoke_endpoint é executada dentro da função definida pelo usuário. As funções definidas pelo usuário oferecem muitas vantagens:
-
É possível dar um nome próprio a seu modelo do SageMaker AI em vez de somente chamar
aws_sagemaker.invoke_endpointpara todos os seus modelos do SageMaker AI. -
É possível especificar o URL do endpoint do modelo em apenas um lugar no código do aplicativo SQL.
-
É possível controlar privilégios
EXECUTEpara cada função de machine learning do Aurora de forma independente. -
É possível declarar os tipos de entrada e saída do modelo usando tipos SQL. O SQL impõe o número e o tipo de argumentos transmitidos ao modelo do SageMaker AI e executa a conversão de tipo, se necessário. O uso de tipos SQL também converterá
SQL NULLno valor padrão apropriado esperado pelo modelo do SageMaker AI. -
Você pode reduzir o tamanho máximo do lote se quiser retornar as primeiras linhas um pouco mais rápido.
Para especificar uma função definida pelo usuário, use a instrução da linguagem de definição de dados (DDL) do SQ CREATE FUNCTION. Ao definir a função, você especifica o seguinte:
-
Os parâmetros de entrada para o modelo.
-
O endpoint específico do SageMaker AI a ser invocado.
-
O tipo de retorno.
A função definida pelo usuário retorna a inferência computada pelo endpoint do SageMaker AI após a execução do modelo com os parâmetros de entrada. O exemplo a seguir cria uma função definida pelo usuário para um modelo do SageMaker AI com dois parâmetros de entrada.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Observe o seguinte:
-
A entrada da função
aws_sagemaker.invoke_endpointpode ser um ou mais parâmetros de qualquer tipo de dados. -
Este exemplo usa um tipo de saída INT. Se você converter a saída de um tipo
varcharem outro tipo, ela deverá ser convertida para um tipo escalar integrado do PostgreSQL, comoINTEGER,REAL,FLOATouNUMERIC. Para obter mais informações sobre esses tipos, consulte Tipos de dadosna documentação do PostgreSQL. -
Especifique
PARALLEL SAFEpara habilitar o processamento da consulta paralela. Para obter mais informações, consulte Melhorar os tempos de resposta com o processamento de consultas paralelas. -
Especifique
COST 5000para estimar o custo da execução da função. Use um número positivo dando o custo de execução estimado para a função, em unidades decpu_operator_cost.
Transmissão de uma matriz como entrada para um modelo do SageMaker AI
A função aws_sagemaker.invoke_endpoint pode ter até 100 parâmetros de entrada, que é o limite para funções do PostgreSQL. Se o modelo do SageMaker AI exigir mais de 100 parâmetros do mesmo tipo, passe os parâmetros do modelo como uma matriz.
O exemplo a seguir define uma função que transmite uma matriz como entrada para o modelo de regressão do SageMaker AI. A saída é convertida em um valor REAL.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Especificação do tamanho do lote ao chamar um modelo do SageMaker AI
O exemplo a seguir cria uma função definida pelo usuário para um modelo do SageMaker AI que define o padrão do tamanho do lote como NULL. A função também permite fornecer um tamanho de lote diferente ao chamá-la.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Observe o seguinte:
-
Use o parâmetro opcional
max_rows_per_batchpara fornecer controle sobre o número de linhas para uma chamada de função em modo de lote. Se você usar um valor de NULL, o otimizador de consulta escolherá automaticamente o tamanho máximo do lote. Para ter mais informações, consulte Noções básicas sobre o modo em lote e as funções de machine learning do Aurora. -
Por padrão, passar NULL como o valor de um parâmetro é convertido em uma string vazia antes de ser passado para o SageMaker AI. Para este exemplo, as entradas têm tipos diferentes.
-
Se você tiver uma entrada que não seja de texto ou uma entrada de texto que precise ser padronizada para um valor diferente de uma string vazia, use a instrução
COALESCE. UseCOALESCEpara converter NULL no valor de substituição nulo desejado na chamada paraaws_sagemaker.invoke_endpoint. Para o parâmetroamountneste exemplo, um valor NULL é convertido em 0.0.
Invocação de um modelo do SageMaker AI que tem várias saídas
O exemplo a seguir cria uma função definida pelo usuário para um modelo do SageMaker AI que retorna várias saídas. A função precisa converter a saída da função aws_sagemaker.invoke_endpoint em um tipo de dados correspondente. Por exemplo, você pode usar o tipo de ponto integrado do PostgreSQL para pares (x, y) ou um tipo composto definido pelo usuário.
Essa função definida pelo usuário retorna valores de um modelo que retorna várias saídas usando um tipo composto para as saídas.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Para o tipo composto, use campos na mesma ordem como aparecem na saída do modelo e converta a saída de aws_sagemaker.invoke_endpoint para o tipo composto. O chamador pode extrair os campos individuais por nome ou com a notação “.*” do PostgreSQL.
Exportar dados ao Amazon S3 para treinamento de modelos do SageMaker AI (avançado)
Recomendamos que você se familiarize com o machine learning do Aurora e o SageMaker AI utilizando os algoritmos e os exemplos fornecidos em vez de tentar treinar seus próprios modelos. Para obter mais informações, consulte Conceitos básicos do Amazon SageMaker AI.
Para treinar modelos do SageMaker AI, exporte os dados para um bucket do Amazon S3. O bucket do Amazon S3 é usado pelo SageMaker AI para treinar seu modelo antes que ele seja implantado. Você pode consultar dados de um cluster de banco de dados do Aurora PostgreSQL e salvá-los diretamente em arquivos de texto armazenados em um bucket do Amazon S3. O SageMaker AI consome os dados do bucket do Amazon S3 para treinamento. Para obter mais informações sobre o treinamento de modelos do SageMaker AI, consulte Treinar um modelo com o Amazon SageMaker AI.
nota
Quando você cria um bucket do Amazon S3 para treinamento de modelos do SageMaker AI ou para pontuação em lotes, use sagemaker no nome do bucket do Amazon S3. Para obter mais informações, consulte Especificar um bucket do Amazon S3 para fazer upload de conjuntos de dados de treinamento e armazenar dados de saída no Guia do desenvolvedor do Amazon SageMaker AI.
Para obter mais informações sobre como exportar os dados, consulte Exportar dados de um cluster de banco de dados do Aurora PostgreSQL para o Amazon S3.
Considerações sobre performance para usar o machine learning do Aurora com o Aurora PostgreSQL
Os serviços do Amazon Comprehend e do SageMaker AI fazem a maior parte do trabalho quando invocados por uma função de machine learning do Aurora. Isso significa que você pode escalar esses recursos conforme necessário, de forma independente. Para o cluster de banco de dados do Aurora PostgreSQL, você pode tornar suas chamadas de função o mais eficientes possível. A seguir, você encontrará algumas considerações sobre performance a serem observadas ao trabalhar com o machine learning do Aurora no Aurora PostgreSQL.
Tópicos
Noções básicas sobre o modo em lote e as funções de machine learning do Aurora
Normalmente, o PostgreSQL executa as funções uma linha por vez. O machine learning do Aurora pode reduzir essa sobrecarga, combinando as chamadas ao serviço externo de machine learning do Aurora para várias linhas em lotes com uma abordagem chamada de execução no modo em lotes. No modo em lotes, o machine learning do Aurora recebe as respostas para um lote de linhas de entrada e as entrega de volta para a consulta em execução, uma linha de cada vez. Essa otimização melhora a taxa de transferência de suas consultas do Aurora sem limitar o otimizador de consultas PostgreSQL.
O Aurora usará automaticamente o modo de lote se a função for referenciada na lista SELECT, em uma cláusula WHERE ou HAVING. Observe que as expressões CASE simples de nível superior são qualificadas para execução em modo de lote. As expressões CASE pesquisadas em nível superior também são qualificadas para execução em modo de lote, desde que a primeira cláusula WHEN seja um predicado simples com uma chamada de função em modo de lote.
Sua função definida pelo usuário deve ser uma função LANGUAGE SQL e deve especificar PARALLEL SAFE e COST 5000.
Migração de função da instrução SELECT para a cláusula FROM
Normalmente, uma função do aws_ml que é qualificada para execução em modo de lote é migrada automaticamente pelo Aurora para a cláusula FROM.
A migração de funções em modo de lote qualificadas para a cláusula FROM pode ser examinada manualmente em um nível por consulta. Para fazer isso, use instruções EXPLAIN (e ANALYZE e VERBOSE) e encontre as informações de “Batch processing (Processamento em lote)” abaixo de cada em modo de lot Function Scan. Você também pode usar EXPLAIN (com VERBOSE) sem executar a consulta. Observe se as chamadas para a função aparecem como um Function
Scan sob uma junção de loop aninhado que não foi especificado na instrução original.
No exemplo a seguir, o operador de junção de loop aninhado no plano mostra que o Aurora migrou a função anomaly_score. Ele migrou essa função da lista de SELECT para a cláusula FROM, onde é elegível para execução em modo de lote.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Para desabilitar a execução em modo de lote, defina o parâmetro apg_enable_function_migration como false. Isso impede a migração de funções do aws_ml de SELECT para a cláusula FROM. Veja a seguir como fazer isso.
SET apg_enable_function_migration = false;O parâmetro apg_enable_function_migration é um parâmetro GUC (Grand Unified Configuration) reconhecido pela extensão apg_plan_mgmt do Aurora PostgreSQL para gerenciamento do plano de consulta. Para desabilitar a migração de funções em uma sessão, use o gerenciamento de plano de consulta para salvar o plano resultante como um plano approved. Em tempo de execução, o gerenciamento de plano de consulta impõe o plano approved com sua configuração apg_enable_function_migration. Essa imposição ocorre independentemente da configuração do parâmetro apg_enable_function_migration. Para obter mais informações, consulte Gerenciar planos de execução de consultas do Aurora PostgreSQL.
Usar o parâmetro max_rows_per_batch
As funções aws_comprehend.detect_sentiment e aws_sagemaker.invoke_endpoint têm um parâmetro max_rows_per_batch. Esse parâmetro especifica o número de linhas que podem ser enviadas ao serviço de machine learning do Aurora. Quanto maior for o conjunto de dados processado pela função, maior será o tamanho do lote que poderá ser criado.
Funções no modo em lote melhoram a eficiência, criando lotes de linhas que distribuem o custo das chamadas de função de machine learning do Aurora por um grande número de linhas. No entanto, se uma instrução SELECT terminar cedo devido a uma cláusula LIMIT, o lote poderá ser construído sobre mais linhas do que as usadas pela consulta. Essa abordagem pode resultar em cobranças adicionais em sua conta da AWS. Para obter os benefícios da execução em modo de lote, mas evitar a criação de lotes que são muito grandes, use um valor menor para o parâmetro max_rows_per_batch em suas chamadas de função.
Se você fizer um EXPLAIN (VERBOSE, ANALYZE) de uma consulta que usa execução em modo de lote, verá um operador de FunctionScan abaixo de uma junção de loop aninhado. O número de loops relatados por EXPLAIN equivale ao número de vezes que uma linha foi obtida pelo operador FunctionScan. Se uma instrução usar uma cláusula LIMIT, o número de buscas será consistente. Para otimizar o tamanho do lote, defina o parâmetro max_rows_per_batch como esse valor. No entanto, se a função em modo de lote for referenciada em um predicado na cláusula WHERE ou HAVING, você provavelmente não poderá saber o número de buscas antecipadamente. Nesse caso, use os loops como uma diretriz e experimente com max_rows_per_batch para encontrar uma configuração que otimize a performance.
Verificar a execução em modo de lote
Para ver se uma função foi executada no modo em lote, use EXPLAIN ANALYZE. Se a execução em modo de lote foi usada, o plano de consulta incluirá as informações em uma seção “Batch Processing (Processamento em lote)”.
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273Neste exemplo, havia um lote que continha 3.333 linhas, que levou 146,273 ms para ser processado. A seção “Batch Processing (Processamento em lote)” mostra o seguinte:
-
Quantos lotes havia para a operação de verificação da função
-
O tamanho médio, mínimo e máximo do lote
-
O tempo médio, mínimo e máximo de execução do lote
Normalmente, o lote final é menor do que o restante, o que geralmente resulta em um tamanho mínimo de lote que é muito menor do que a média.
Para retornar as primeiras linhas mais rapidamente, defina o parâmetro max_rows_per_batch como um valor menor.
Para reduzir o número de chamadas em modo de lote para o serviço de ML ao usar um LIMIT na função definida pelo usuário, defina o parâmetro max_rows_per_batch como um valor menor.
Melhorar os tempos de resposta com o processamento de consultas paralelas
Para obter resultados o mais rápido possível de um grande número de linhas, é possível combinar o processamento de consultas paralelas com o processamento no modo em lote. Você pode usar o processamento de consultas paralelas para instruções SELECT, CREATE TABLE AS SELECT e CREATE
MATERIALIZED VIEW.
nota
O PostgreSQL ainda não é compatível com consultas paralelas para instruções de linguagem de manipulação de dados (DML).
O processamento de consultas paralelas ocorre no banco de dados e dentro do serviço de ML. O número de núcleos na classe da instância de banco de dados limita o nível de paralelismo que pode ser usado ao executar uma consulta. O servidor de banco de dados pode construir um plano de execução de consulta paralela que particiona a tarefa entre um conjunto de operadores paralelos. Cada um desses operadores pode criar solicitações em lote contendo dezenas de milhares de linhas (ou quantas linhas cada serviço permitir).
As solicitações em lote de todos os operadores paralelos são enviadas ao endpoint do SageMaker AI. O nível de paralelismo com o qual o endpoint é compatível é limitado pelo número e pelo tipo de instâncias que o suportam. Para K graus de paralelismo, você precisa de uma classe de instância de banco de dados que tenha pelo menos núcleos K. Você também precisa configurar o endpoint do SageMaker AI para que seu modelo tenha K instâncias iniciais de uma classe de instância de performance suficientemente alta.
Para usar o processamento de consultas paralelas, você pode definir o parâmetro de armazenamento parallel_workers da tabela que contém os dados que você planeja passar. Você define parallel_workers para uma função em modo de lote como aws_comprehend.detect_sentiment. Se o otimizador escolher um plano de consulta paralelo, os serviços de ML da AWS podem ser chamados em lote e em paralelo.
Você pode usar os seguintes parâmetros com a função aws_comprehend.detect_sentiment para obter um plano com paralelismo de quatro vias. Se você alterar qualquer um dos dois parâmetros a seguir, deverá reiniciar a instância de banco de dados para que as alterações tenham efeito
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Para obter mais informações sobre como controlar consultas paralelas, consulte Parallel plans
Usar visualizações materializadas e colunas materializadas
Ao chamar um serviço da AWS, como o SageMaker AI ou o Amazon Comprehend, do banco de dados, sua conta é cobrada de acordo com a política de preço desse serviço. Para minimizar as cobranças em sua conta, é possível materializar o resultado da chamada do serviço da AWS em uma coluna materializada para que o serviço da AWS não seja chamado mais de uma vez por linha de entrada. Se desejar, você pode adicionar uma coluna de timestamp materializedAt para registrar a hora em que as colunas foram materializadas.
A latência de uma INSERT instrução de linha única comum geralmente é muito menor do que a latência de chamar uma função em modo de lote. Assim, talvez você não consiga atender aos requisitos de latência do seu aplicativo se invocar a função em modo de lote para cada linha única INSERT executada pelo aplicativo. Para materializar o resultado da chamada de um serviço da AWS em uma coluna materializada, os aplicativos de alto performance geralmente precisam preencher as colunas materializadas. Para fazer isso, eles emitem periodicamente uma instrução UPDATE que opera em um grande lote de linhas ao mesmo tempo.
UPDATEA usa um bloqueio em nível de linha que pode afetar um aplicativo em execução. Portanto, você pode precisar usar SELECT ... FOR UPDATE SKIP LOCKED ou MATERIALIZED
VIEW.
As consultas de análise que operam em um grande número de linhas em tempo real podem combinar a materialização no modo em lote com o processamento em tempo real. Para fazer isso, essas consultas montam uma UNION ALL dos resultados pré-materializados com uma consulta das linhas que ainda não têm resultados materializados. Em alguns casos, essa UNION ALL é necessária em vários locais, ou a consulta é gerada por um aplicativo de terceiros. Nesse caso, você pode criar uma VIEW para encapsular a operação UNION ALL para que esse detalhe não seja exposto ao restante do aplicativo SQL.
Você pode usar uma visualização materializada para materializar os resultados de uma instrução SELECT arbitrária em um snapshot no tempo. Você também pode usá-la para atualizar a visualização materializada a qualquer momento no futuro. Atualmente, o PostgreSQL é compatível com a atualização incremental, portanto, cada vez que a visualização materializada é atualizada, a visualização materializada é totalmente recalculada.
Você pode atualizar visualizações materializadas com a opção CONCURRENTLY, que atualiza o conteúdo da visualização materializada sem usar um bloqueio exclusivo. Isso permite que um aplicativo SQL leia a visualização materializada enquanto ela está sendo atualizada.
Monitorar o machine learning do Aurora
Você pode monitorar as funções aws_ml definindo o parâmetro track_functions em seu grupo de parâmetros de cluster de banco de dados personalizado como all. Por padrão, esse parâmetro é definido como pl, o que significa que somente as funções da linguagem do procedimento são monitoradas. Ao alterar isso para all, as funções aws_ml também são monitoradas. Para obter mais informações, consulte Run-time Statistics
Para obter informações sobre como monitorar a performance das operações do SageMaker chamadas em funções do machine learning do Aurora, consulte Monitorar o Amazon SageMaker AI no Guia do desenvolvedor do Amazon SageMaker AI.
Com track_functions definido como all, você pode consultar a visualização pg_stat_user_functions para obter estatísticas sobre as funções que você define e usa para invocar os serviços de machine learning do Aurora. Para cada função, a visualização fornece o número de calls, total_time e self_time.
Para ver as estatísticas das funções aws_sagemaker.invoke_endpoint e aws_comprehend.detect_sentiment, você pode filtrar os resultados pelo nome do esquema utilizando a consulta a seguir.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Para limpar as estatísticas, faça o seguinte.
SELECT pg_stat_reset();
É possível obter os nomes das funções SQL que chamam a função aws_sagemaker.invoke_endpoint consultando o catálogo do sistema pg_proc do PostgreSQL. Esse catálogo armazena informações sobre funções, procedimentos e muito mais. Para obter mais informações, consulte pg_procproname) cuja fonte (prosrc) inclui o texto invoke_endpoint.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
