As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treine e avalie DeepRacer modelos da AWS usando o DeepRacer console da AWS
Para treinar um modelo de aprendizado por reforço, você pode usar o DeepRacer console da AWS. No console, crie uma tarefa de treinamento, escolha uma estrutura compatível e um algoritmo disponível, adicione uma função de recompensa e configure as definições de treinamento. Você também pode assistir o progresso do treinamento em um simulador. Você pode encontrar as step-by-step instruções emTreine seu primeiro DeepRacer modelo da AWS .
Esta seção explica como treinar e avaliar um DeepRacer modelo da AWS. Também mostra como criar e melhorar uma função de recompensa, como um espaço de ação afeta o desempenho do modelo e como os hiperparâmetros afetam o desempenho de treinamento. Também é possível aprender como clonar um modelo de treinamento para estender uma sessão de treinamento, como usar o simulador para avaliar o desempenho de treinamento e como abordar alguns dos desafios da simulação para o mundo real.
Tópicos
Criar uma função de recompensa
Uma função de recompensa descreve o feedback imediato (como recompensa ou pontuação de penalidade) quando seu DeepRacer veículo da AWS se move de uma posição na pista para uma nova posição. A finalidade da função é encorajar o veículo a se movimentar ao longo da pista para alcançar um destino rapidamente, sem acidentes ou infrações. Um movimento desejável conquista uma pontuação mais alta para a ação ou seu estado de desejável. Um movimento ilegal ou desnecessário conquista uma pontuação mais baixa. Ao treinar um DeepRacer modelo da AWS, a função de recompensa é a única parte específica do aplicativo.
Em geral, a função de recompensa é projetada para atuar como um plano de incentivo. Diferentes estratégias de incentivo podem resultar em diferentes comportamentos do veículo. Para fazer com que o veículo ande mais rápido, a função deve conceder recompensas para que o veículo siga o caminho. A função deve distribuir penalidades quando o veículo levar muito tempo para concluir uma volta ou quando sair da pista. Para evitar padrões de condução em zigue-zague, ela pode recompensar o veículo por esterçar menos em partes retas da pista. A função de recompensa pode conceder pontuações positivas quando o veículo ultrapassar determinados marcos, conforme medido por waypoints. Isso pode atenuar a espera ou a condução na direção errada. Também é provável que você altere a função de recompensa para considerar as condições da pista. No entanto, quanto mais sua função de recompensa considerar as informações específicas do ambiente, maior será a probabilidade de que o modelo treinado seja superajustado e pouco genérico. Para tornar o modelo mais aplicável de modo geral, explore o espaço de ação.
Se um plano de incentivo não for cuidadosamente considerado, ela pode gerar consequências não intencionais de efeito oposto
Uma boa prática para criar uma função de recompensa é começar com uma função simples que abrange cenários básicos. Você pode melhorar a função para lidar com mais ações. Vejamos agora algumas funções de recompensa simples.
Exemplos de funções de recompensa simples
Podemos começar a criar a função de recompensa considerando a situação mais básica. A situação é andar em uma pista reta do início ao fim sem sair da pista. Nesse cenário, a lógica da função de recompensa depende apenas de on_track e progress. Como teste, você pode começar com a seguinte lógica:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Essa lógica penaliza o agente quando ele se movimenta para fora da pista. Ela recompensa o agente quando alcança a linha de chegada. É razoável para alcançar o objetivo estabelecido. No entanto, o agente anda livremente entre o ponto de partida e a linha de chegada, inclusive andando de ré na pista. Não apenas o treinamento poderia demorar para ser concluído, mas também o modelo treinado causaria uma condução menos eficiente quando implantado em um veículo real.
Na prática, um agente aprende de forma mais eficaz se puder fazer isso bit-by-bit durante o curso do treinamento. Isso significa que uma função de recompensa deve conceder recompensas menores passo a passo ao longo da pista. Para que o agente se movimente na pista reta, podemos melhorar a função de recompensa da seguinte forma:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Com essa função, o agente obtém mais recompensas quanto mais próximo estiver de alcançar a linha de chegada. Isso deve reduzir ou eliminar tentativas improdutivas de dirigir em marcha à ré. No geral, queremos que a função de recompensa distribua as recompensas com mais uniformidade pelo espaço de ações. Criar uma função de recompensa eficaz pode ser uma tarefa desafiadora. Comece com uma função simples e, progressivamente, aperfeiçoe ou melhore ela. Com experimentos sistemáticos, a função pode se tornar mais robusta e eficiente.
Aprimorar a função de recompensa
Depois de treinar com sucesso seu DeepRacer modelo da AWS para a pista reta simples, o DeepRacer veículo da AWS (virtual ou físico) pode dirigir sozinho sem sair da pista. Se você deixar o veículo percorrer em um circuito, ele não permanecerá na pista. A função de recompensa ignorou as ações de fazer curvas para seguir a pista.
Para fazer com que o veículo lide com essas ações, é necessário aprimorar a função de recompensa. A função deve conceder uma recompensa quando o agente fizer uma curva permitida e produzir uma penalidade se o agente fizer uma curva ilegal. Em seguida, você está pronto para iniciar outra rodada de treinamento. Para aproveitar o treinamento anterior, inicie o novo treinamento clonando o modelo treinado anteriormente, transmitindo o conhecimento adquirido anteriormente. Você pode seguir esse padrão para adicionar gradualmente mais recursos à função de recompensa para treinar seu DeepRacer veículo da AWS para dirigir em ambientes cada vez mais complexos.
Para obter funções de recompensa mais avançadas, consulte os seguintes exemplos:
Explorar o espaço de ação para treinar um modelo robusto
Como regra geral, treine o modelo para ser o mais robusto possível para que possa ser aplicado no máximo de ambientes possíveis. Um modelo robusto é aquele capaz de ser aplicado em uma ampla gama de formatos e condições de pista. De modo geral, um modelo robusto não é "inteligente" pois sua função de recompensa não tem a capacidade de conter conhecimento explícito sobre um ambiente específico. Caso contrário, é provável que o modelo só possa ser aplicado em ambientes semelhantes àquele em que foi treinado.
A incorporação explícita de informações específicas ao ambiente na função de recompensa equivale a engenharia de recursos. A engenharia de recursos ajuda a reduzir o tempo de treinamento e pode ser útil em soluções personalizadas para um ambiente específico. No entanto, para treinar um modelo de aplicabilidade geral, evite utilizar uma grande quantidade de engenharia de recursos.
Por exemplo, ao treinar um modelo em uma pista circular, não espere obter um modelo treinado aplicável a qualquer pista não circular se tiver essas propriedades geométricas explicitamente incorporadas na função de recompensa.
Como você abordaria o treinamento de um modelo o mais robusto possível enquanto mantém a função de recompensa a mais simples possível? Uma maneira é explorar o espaço de ação que abrange as ações que o agente pode realizar. Outra é testar os hiperparâmetros do algoritmo de treinamento subjacente. Muitas vezes, você pode fazer ambos. Aqui, nos concentramos em como explorar o espaço de ação para treinar um modelo robusto para seu DeepRacer veículo da AWS.
No treinamento de um DeepRacer modelo da AWS, uma ação (a) é uma combinação de velocidade (tmetros por segundo) e ângulo de direção (sem graus). O espaço de ação do agente define os intervalos de velocidade e ângulo de esterçamento que o agente pode assumir. Para um espaço de ação discreto com m velocidades, (v1, .., vn) e n ângulos de esterçamento, (s1, ..,
sm), há m*n possíveis ações no espaço de ação:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
Os valores reais de (vi,
sj) dependem dos intervalos de vmax e |smax| e não são uniformemente distribuídos.
Cada vez que você começar a treinar ou iterar seu DeepRacer modelo da AWS, você deve primeiro especificar o nm,, vmax |smax| e/ou concordar em usar seus valores padrão. Com base na sua escolha, o DeepRacer serviço da AWS gera as ações disponíveis que seu agente pode escolher no treinamento. As ações geradas não são distribuídas uniformemente pelo espaço de ação.
Em geral, um número maior de ações e intervalos de ação maiores oferecem mais espaço ou opções ao agente para reagir a condições de pista mais variadas, como uma pista curvada com direções ou ângulos de curva irregulares. Quanto mais opções estiverem disponíveis para o agente, maior será a prontidão com que ele lidará com variações de pista. Como resultado, você pode esperar que o modelo treinado seja mais amplamente aplicável, mesmo usando uma função de recompensa simples.
Por exemplo, o agente pode aprender rapidamente a lidar com pistas em linha reta usando um espaço de ação granulado com uma pequena quantidade de velocidades e ângulos de esterçamento. Em uma pista curvada, esse espaço de ação granulado provavelmente fará com que o agente ultrapasse e saia da pista nas curvas. Isso ocorre porque não há opções suficientes à disposição para ajustar a velocidade e o esterçamento. Aumente o número de velocidades ou ângulos de esterçamento, ou ambos, o agente deverá ser mais capaz de manobrar em curvas e se manter na pista. Da mesma forma, se o agente se mover em zigue-zague, você pode tentar aumentar o número de ângulos de esterçamento para reduzir curvas drásticas em qualquer etapa.
Quando o espaço de ação for muito grande, o desempenho do treinamento poderá sofrer, pois levará mais tempo para explorar o espaço de ação. Lembre-se de equilibrar os benefícios da aplicabilidade geral de um modelo em relação aos requisitos de desempenho do treinamento. Essa otimização envolve experimentos sistemáticos.
Ajustar sistematicamente os hiperparâmetros
Uma maneira de melhorar o desempenho do modelo é colocar em prática um processo de treinamento melhor e mais eficaz. Por exemplo, para obter um modelo robusto, o treinamento deve fornecer ao agente uma amostragem mais ou menos uniformemente distribuída pela espaço de ação do agente. Isso requer uma mistura suficiente de pesquisa e exploração. As variáveis que afetam isso incluem a quantidade de dados de treinamento usados (number of episodes between each
training e batch size), a velocidade com que o agente aprende (learning rate), a parte da exploração (entropy). Para tornar o treinamento prático, você pode acelerar o processo de aprendizado. As variáveis que afetam isso incluem learning rate, batch size, number of
epochs e discount factor.
As variáveis que afetam o processo de treinamento são conhecidas como hiperparâmetros do treinamento. Esses atributos de algoritmo não são propriedades do modelo subjacente. Infelizmente, os hiperparâmetros são empíricos por natureza. Seus valores ótimos não são conhecidos para todos os efeitos práticos e exigem experimentação sistemática para derivar.
Antes de discutir os hiperparâmetros que podem ser ajustados para ajustar o desempenho do treinamento do seu DeepRacer modelo da AWS, vamos definir a seguinte terminologia.
- Ponto de dados
-
Um ponto de dados, também conhecido como uma experiência, é uma tupla de (s,a,r,s’), onde s representa uma observação (ou estado) capturada pela câmera, a uma ação executada pelo veículo, r é a recompensa esperada incorrida pela ação referida e s' é a nova observação depois que a ação foi realizada.
- Episódio
-
Um episódio é um período no qual o veículo começa a partir de um ponto de partida e acaba por concluir a pista ou sair dela. Ele incorpora uma sequência de experiências. Diferentes episódios podem ter diferentes comprimentos.
- Buffer de experiências
-
Um buffer de experiências consiste em um número de pontos de dados ordenados, coletados ao longo de uma quantidade fixa de episódios com vários comprimentos durante o treinamento. Para a AWS DeepRacer, corresponde às imagens capturadas pela câmera montada em seu DeepRacer veículo da AWS e às ações tomadas pelo veículo e serve como a fonte da qual a entrada é extraída para atualizar as redes neurais subjacentes (políticas e valores).
- Lote
-
Um lote é uma lista ordenada de experiências, que representa uma parte da simulação ao longo de um período, usado para atualizar os pesos da rede de políticas. É um subconjunto do buffer de experiências.
- Dados de treinamento
-
Dados de treinamento são um conjunto de lotes amostrados aleatoriamente a partir de um buffer de experiências e usados para treinar os pesos da rede de políticas.
| Hiperparâmetros | Descrição |
|---|---|
|
Gradient descent batch size (Tamanho de lote da descida de gradiente) |
O número de experiências recentes do veículo amostradas aleatoriamente a partir de um buffer de experiências e usadas para atualizar os pesos da rede neural de aprendizado profundo subjacente. A amostragem aleatória ajuda a reduzir as correlações inerentes nos dados de entrada. Use um tamanho de lote maior para promover atualizações mais estáveis e suave nos pesos da rede neural, mas lembre-se da possibilidade de que o treinamento poderá ser mais longo ou mais lento.
|
|
Number of epochs (Número de epochs) |
O número de passagens pelos dados de treinamento para atualizar os pesos da rede neural durante a descida de gradiente. Os dados de treinamento correspondem a amostras aleatórias do buffer de experiências. Use um número maior de epochs para promover atualizações mais estáveis, mas espere um treinamento mais lento. Quando o tamanho do lote for pequeno, use um número menor de epochs
|
|
Learning rate (Taxa de aprendizado) |
Durante cada atualização, uma parte do novo peso pode vir da contribuição da descida de gradiente (ou subida) e o restante do valor de peso existente. A taxa de aprendizado controla a quantidade de contribuição da atualização da descida de gradiente (ou subida) para os pesos da rede. Use uma taxa de aprendizado mais alta para incluir mais contribuições da descida de gradiente para treinamento mais rápido, mas esteja ciente da possibilidade de que a recompensa esperada possa não convergir se a taxa de aprendizado for muito grande.
|
Entropy |
Um grau de incerteza usado para determinar quando adicionar aleatoriedade à distribuição de políticas. A incerteza adicional ajuda o DeepRacer veículo da AWS a explorar o espaço de ação de forma mais ampla. Um valor maior de entropia incentiva o veículo a explorar o espaço de ação minuciosamente.
|
| Discount factor (Fator de desconto) |
Um fator especifica a quantidade da contribuição das recompensas futuras para a recompensa esperada. Quanto maior for o valor do Fator de desconto, maior será a quantidade de contribuições consideradas pelo veículo para realizar um movimento e mais lento será o treinamento. Com o fator de desconto de 0,9, o veículo inclui recompensas a partir de uma ordem de 10 etapas futuras para fazer um movimento. Com o fator de desconto de 0,999, o veículo considera recompensas a partir de uma ordem de 1.000 etapas futuras para fazer um movimento. Os valores de fator de desconto recomendados são 0,99, 0,999 e 0,9999.
|
| Loss type (Tipo de perda) |
Tipo da função objetiva usada para atualizar os pesos da rede. Um bom algoritmo de treinamento deve fazer alterações incrementais na estratégia do agente para que ele faça a transição gradual de ações aleatórias para ações estratégicas a fim de aumentar a recompensa. Mas se isso gerar uma alteração muito grande, o treinamento se torna instável e o agente acaba não aprendendo. Os tipos Huber loss (Perda de Huber)
|
| Number of experience episodes between each policy-updating iteration (Número de episódios de experiência entre cada iteração de atualização de política) | O tamanho do buffer de experiências para obtenção de dados de treinamento para os pesos da rede de políticas de aprendizado. Um episódio de experiência é um período no qual o agente começa a partir de um ponto de partida e acaba por concluir a pista ou sair dela. Ele consiste em uma sequência de experiências. Diferentes episódios podem ter diferentes comprimentos. Para problemas de aprendizado por reforço simples, um buffer de experiências pequeno poderá ser suficiente e o aprendizado será rápido. Para problemas mais complexos que têm mais local maxima, um buffer de experiências maior será necessário para oferecer mais pontos de dados não correlacionados. Nesse caso, o treinamento é mais lento, porém mais estável. Os valores recomendados são 10, 20 e 40.
|
Examine o progresso do trabalho DeepRacer de treinamento na AWS
Após iniciar o trabalho de treinamento, você poderá examinar as métricas de treinamento de recompensas e a conclusão da pista por episódio para verificar o desempenho do trabalho de treinamento do modelo. No DeepRacer console da AWS, as métricas são exibidas no gráfico de recompensas, conforme mostrado na ilustração a seguir.
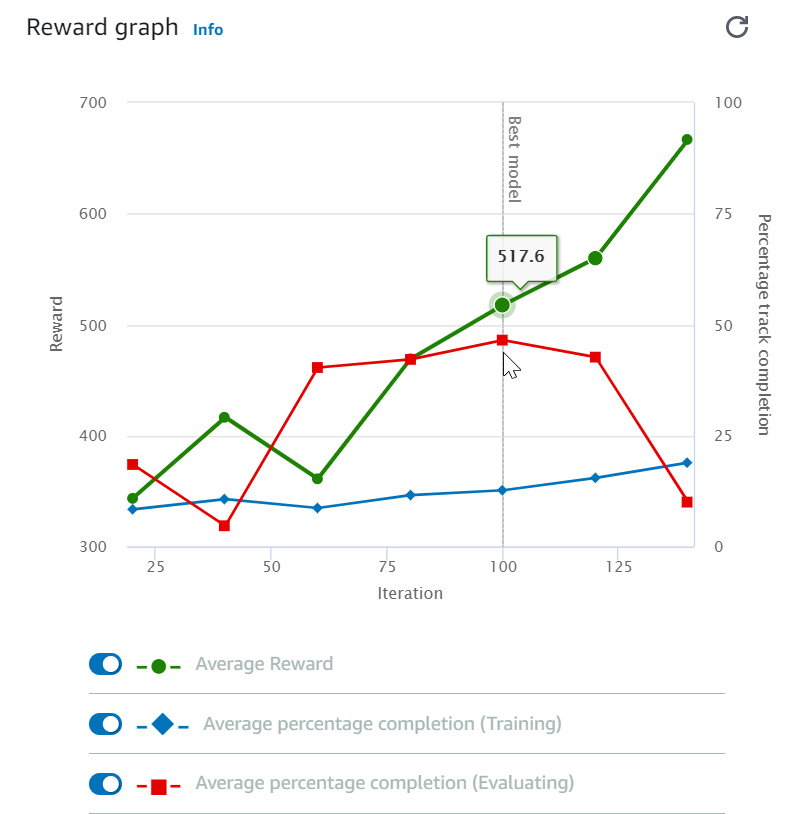
Você pode optar por visualizar a recompensa obtida por episódio, a recompensa média por iteração, o progresso por episódio, o progresso médio por iteração ou qualquer combinação dessas opções. Para fazer isso, mude as alternâncias Reward (Episode, Average) (Recompensa (episódio, média)) ou Progress (Episode, Average) (Progresso (episódio, média)) na parte inferior do Reward graph (Gráfico de recompensa). A recompensa e o progresso por episódio são exibidos como gráficos de dispersão em cores diferentes. As médias de recompensa e conclusão da pista são exibidas por gráficos de linha e começam após a primeira iteração.
O intervalo de recompensas é mostrado no lado esquerdo do gráfico e o intervalo de progresso (0 a 100) está no lado direito. Para ler o valor exato de uma métrica de treinamento, mova o mouse para perto do ponto de dados no gráfico.
Os gráficos são atualizados automaticamente a cada 10 segundos enquanto o treinamento está em andamento. É possível escolher o botão de atualização para atualizar manualmente a exibição da métrica.
Um trabalho de treinamento é bom se a recompensa média e a conclusão da pista mostrarem tendências que convergem. Em particular, o modelo provavelmente convergiu se o progresso por episódio atinge continuamente 100% e a recompensa se nivela. Caso contrário, clone o modelo e treine-o novamente.
Clonar um modelo treinado para iniciar uma nova passagem do treinamento
Se você clonar um modelo previamente treinado como ponto de partida para uma nova rodada de treinamento, poderá melhorar a eficiência do treinamento. Para isso, modifique os hiperparâmetros a fim de usar o conhecimento já obtido.
Nesta seção, você aprende a clonar um modelo treinado usando o DeepRacer console da AWS.
Para iterar o treinamento, o modelo de aprendizado por reforço usando o console da AWS DeepRacer
-
Faça login no DeepRacer console da AWS, caso ainda não tenha feito login.
-
Na página Models (Modelos), escolha um modelo treinado e selecione Clone (Clonar) na lista do menu suspenso Action (Ação).
-
Em Model details (Detalhes do modelo), faça o seguinte:
-
Digite
RL_model_1em Model name (Nome do modelo), se não quiser que um nome seja gerado para o modelo clonado. -
Opcionalmente, forneça uma descrição para o to-be-cloned modelo em Descrição do modelo - opcional.
-
-
Em Simulação do ambiente, escolha outra opção de pista.
-
Em Reward function (Função de recompensa), escolha um dos exemplos de função de recompensa disponíveis. Modifique a função de recompensa. Por exemplo, considere o esterçamento.
-
Expanda as Configurações do algoritmo e teste diferentes opções. Por exemplo, altere o valor do tamanho de lote da descida de gradiente de 32 para 64 ou aumente a Learning rate (Taxa de aprendizado) para acelerar o treinamento.
-
Teste várias opções de Stop conditions (Condições de parada).
-
Escolha Start training (Iniciar o treinamento) para começar uma nova rodada de treinamento.
Assim como ocorre com o treinamento de um modelo de machine learning robusto em geral, é importante conduzir experimentos sistemáticos para encontrar a melhor solução.
Avalie DeepRacer modelos da AWS em simulações
Avaliar um modelo é testar o desempenho de um modelo treinado. Na AWS DeepRacer, a métrica de desempenho padrão é o tempo médio de finalização de três voltas consecutivas. Usando essa métrica, para quaisquer dois modelos, será melhor aquele que fizer o agente se deslocar mais rápido na mesma pista.
Em geral, avaliar um modelo envolve as seguintes tarefas:
-
Configurar e iniciar uma tarefa de avaliação.
-
Observar o progresso da avaliação enquanto a tarefa está em execução. Isso pode ser feito no DeepRacer simulador da AWS.
-
Inspecionar o resumo da avaliação depois que a tarefa de avaliação for concluída. Você pode encerrar uma tarefa de avaliação em andamento a qualquer momento.
nota
O tempo de avaliação depende dos critérios selecionados. Se seu modelo não atender aos critérios de avaliação, a avaliação continuará sendo executada até atingir o limite de 20 minutos.
-
Opcionalmente, envie o resultado da avaliação para uma tabela de DeepRacer classificação elegível da AWS. A classificação no placar permite saber quão bom é o desempenho de seu modelo em relação aos outros participantes.
Teste um DeepRacer modelo da AWS com um DeepRacer veículo da AWS dirigindo em uma pista física, consulteOpere seu DeepRacer veículo da AWS .
Otimize os DeepRacer modelos de treinamento da AWS para ambientes reais
Muitos fatores afetam o desempenho no mundo real de um modelo treinado, incluindo a escolha do espaço de ação, a função de recompensa, os hiperparâmetros usados no treinamento e a calibração do veículo, além das condições da pista real. Além disso, a simulação é apenas uma aproximação (muitas vezes bruta) do mundo real. Eles criam o desafio de treinar um modelo em simulação, aplicá-lo ao mundo real e alcançar um desempenho satisfatório.
Treinar um modelo para alcançar um desempenho sólido no mundo real requer várias iterações para explorar a função de recompensa, espaços de ação, hiperparâmetros e a avaliação na simulação e o teste em um ambiente real. A última etapa envolve a chamada transferência simulation-to-real mundial (sim2real) e pode parecer complicada.
Para ajudar a abordar os desafios da sim2real, tenha as seguintes considerações em mente:
-
Certifique-se de que o veículo esteja bem calibrado.
Isso é importante pois o ambiente simulado é uma representação parcial do ambiente real. Além disso, o agente executa uma ação com base na condição da pista atual, conforme capturada por uma imagem da câmera, em cada etapa. Ela não enxerga longe o suficiente para planejar a rota em alta velocidade. Para acomodar isso, a simulação impõe limites para a velocidade e o esterçamento. Para garantir que o modelo treinado funciona no mundo real, o veículo deve ser calibrado corretamente para corresponder a essa e outras configurações de simulação. Para obter mais informações sobre a calibração do veículo, consulte Calibre seu veículo da AWS DeepRacer .
-
Teste o veículo com o modelo padrão primeiro.
Seu DeepRacer veículo da AWS vem com um modelo pré-treinado carregado em seu mecanismo de inferência. Antes de testar seu próprio modelo no mundo real, verifique se o veículo apresenta um desempenho razoavelmente bom com o modelo padrão. Se esse não for o caso, verifique a configuração da pista física. Testar um modelo em uma pista física construída incorretamente provavelmente acarretará desempenho ruim. Nesses casos, reconfigure ou conserte a pista antes de começar ou retomar os testes.
nota
Ao executar seu DeepRacer veículo da AWS, as ações são inferidas de acordo com a rede de políticas treinada sem invocar a função de recompensa.
-
Verifique se o modelo funciona na simulação.
Se o modelo não funcionar bem no mundo real, é possível que o modelo ou a pista estejam com defeitos. Para descobrir as causas raiz, primeiro avalie o modelo em simulações para verificar se o agente simulado pode concluir pelo menos um ciclo sem sair da pista. Faça isso inspecionando a convergência das recompensas enquanto observa a trajetória do agente no simulador. Se a recompensa atingir o máximo quando o agente simulado concluir um ciclo sem falhas, o modelo provavelmente está bom.
-
Não treine o modelo excessivamente.
Continuar o treinamento depois que o modelo tiver concluído consistentemente a pista na simulação fará com que ocorra um excesso de ajuste no modelo. Um modelo com excesso de treinamento não apresentará bom desempenho no mundo real pois não conseguirá lidar nem mesmo com pequenas variações entre a pista simulada e o ambiente real.
-
Use vários modelos de diferentes iterações.
Uma sessão de treinamento típica produz uma variedade de modelos que se encaixam entre subajustado e superajustado. Como não há critérios a priori para determinar um modelo que está correto, escolha alguns modelos candidatos do momento em que o agente conclui um único ciclo no simulador até o momento em que passa a apresentar desempenho consistente.
-
Comece devagar e aumente a velocidade de condução gradualmente nos testes.
Ao testar o modelo implantado no veículo, comece com um valor baixo de velocidade máxima. Por exemplo, defina o limite de velocidade do teste para ser menor que 10% do limite de velocidade do treinamento. Depois, aumente gradualmente o limite de velocidade do teste até o veículo começar a se movimentar. Defina o limite de velocidade do teste ao calibrar o veículo usando o console de controle do dispositivo. Se o veículo for muito rápido, por exemplo, a velocidade exceder aquelas observadas durante o treinamento no simulador, o modelo provavelmente não apresentará bom desempenho no mundo real.
-
Teste um modelo com o veículo em diferentes posições iniciais.
O modelo aprende a tomar um caminho específico na simulação e pode ser sensível à sua posição na pista. Você deve iniciar os testes do veículo com diferentes posições dentro dos limites da pista (da esquerda para o centro e para a direita) para ver se o modelo apresenta bom desempenho a partir das posições definidas. A maioria dos modelos tende a fazer o veículo permanecer perto de uma das linhas brancas laterais. Para ajudar a analisar o trajeto do veículo, trace as posições do veículo (x, y) passo a passo da simulação para identificar os caminhos prováveis que serão realizados pelo veículo em um ambiente real.
-
Inicie os testes com uma pista reta.
Uma pista reta é muito mais fácil de navegar em relação a uma pista curvada. Iniciar o teste com uma pista reta é útil para descartar modelos ruins rapidamente. Se um veículo não conseguir seguir uma pista reta a maioria das vezes, o modelo também não apresentará bom desempenho em pistas curvadas.
-
Tome cuidado com um comportamento em que o veículo realiza apenas um tipo de ação,
Quando o veículo só conseguir realizar um tipo de ação, por exemplo, apenas virar para a esquerda, o modelo provavelmente está subajustado ou superajustado. Com certos parâmetros de modelo, muitas iterações no treinamento podem tornar o modelo superajustado. Poucas iterações podem torná-lo subajustado.
-
Observa a capacidade do veículo em corrigir seu trajeto ao longo de uma borda da pista.
Um bom modelo faz com que o veículo corrija a si mesmo ao se aproximar das bordas da pista. A maioria dos modelos bem treinados têm essa capacidade. Se o veículo puder se corrigir em ambas as bordas da pista, o modelo é considerado mais robusto e de melhor qualidade.
-
Observe comportamentos inconsistentes exibidos pelo veículo.
Um modelo de política representa uma distribuição de probabilidade para realizar uma ação em um estado específico. Com o modelo treinado carregado no mecanismo de inferência, um veículo selecionará a ação mais provável, uma etapa por vez, de acordo com a prescrição do modelo. Se as probabilidades de ação estiverem distribuídas uniformemente, o veículo poderá realizar qualquer ação de probabilidade igual ou semelhante. Isso causará um comportamento de condução errático. Por exemplo, quando o veículo segue um caminho reto às vezes (por exemplo, metade do tempo) e faz curvas desnecessárias em outros momentos, o modelo está subajustado ou superajustado.
-
Observe se o veículo realiza apenas um tipo de curva (esquerda ou direita).
Se o veículo fizer boas curvas para a esquerda mas não conseguir lidar com curvas para a direita, ou vice-versa, é necessário calibrar cuidadosamente ou recalibrar o esterçamento do veículo. Como alternativa, use um modelo que esteja treinado com configurações semelhantes às configurações físicas nos testes.
-
Observe se o veículo faz curvas bruscas e sai da pista.
Se o veículo segue o trajeto corretamente na maior parte do caminho, mas sai da pista repentinamente, isso provavelmente deve-se a distrações no ambiente. As distrações mais comuns incluem reflexões de luz inesperadas ou não intencionais. Nesses casos, use barreiras ao redor da pista ou outros meios para reduzir luzes brilhantes.
