As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Melhores práticas operacionais para o Amazon OpenSearch Service
Este capítulo fornece as melhores práticas para operar domínios do Amazon OpenSearch Service e inclui diretrizes gerais que se aplicam a muitos casos de uso. Cada workload é única e tem características particulares, portanto, nenhuma recomendação genérica é exatamente certa para cada caso de uso. A prática recomendada mais importante é implantar, testar e ajustar seus domínios em um ciclo contínuo para encontrar a configuração, a estabilidade e o custo ideais para a workload.
Monitoramento e alertas
As práticas recomendadas a seguir se aplicam ao monitoramento de seus domínios OpenSearch de serviço.
Configurar CloudWatch alarmes
OpenSearch O serviço emite métricas de desempenho para a Amazon CloudWatch. Analise regularmente as métricas do cluster e da instância e configure CloudWatch os alarmes recomendados com base no desempenho da sua carga de trabalho.
Habilitar a publicação de logs
OpenSearch O serviço expõe registros OpenSearch de erros, pesquisa registros lentos, indexação de registros lentos e registros de auditoria no Amazon CloudWatch Logs. Os logs lentos de pesquisa, logs lentos de indexação e logs de erros são úteis para solucionar problemas de performance e estabilidade. Os logs de auditoria, que estarão disponíveis apenas se você habilitar o controle de acesso detalhado para rastrear a atividade do usuário. Para obter mais informações, consulte Registros
Logs lentos de pesquisa e logs lentos de indexação são ferramentas importantes para que você entenda e solucione problemas relacionados à performance de suas operações de pesquisa e indexação. Habilite a entrega de logs de lentidão de pesquisa e indexação para todos os domínios de produção. Você também deve configurar limites de registro — caso contrário, CloudWatch não capturará os registros.
Estratégia de fragmentação
Os fragmentos distribuem sua carga de trabalho pelos nós de dados em seu domínio OpenSearch de serviço. Índices configurados corretamente podem auxiliar no aumento da performance geral do domínio.
Quando você envia dados para o OpenSearch Serviço, você envia esses dados para um índice. Um índice é semelhante a uma tabela de banco de dados, com documentos como linhas e campos como colunas. Ao criar o índice, você OpenSearch informa quantos fragmentos primários deseja criar. Os fragmentos primários são partições independentes do conjunto de dados completo. OpenSearch O serviço distribui automaticamente seus dados pelos fragmentos primários em um índice. Você também pode configurar réplicas do índice. Cada fragmento de réplica compreende um conjunto completo de cópias dos fragmentos primários desse índice.
OpenSearch O serviço mapeia os fragmentos de cada índice nos nós de dados do seu cluster. Ele garante que os fragmentos primários e de réplica do índice sejam inerentes a nós de dados diferentes. A primeira réplica garante que você tenha duas cópias dos dados no índice. Você sempre deve usar pelo menos uma réplica. Réplicas adicionais fornecem redundância e capacidade de leitura adicionais.
OpenSearch envia solicitações de indexação para todos os nós de dados que contêm fragmentos que pertencem ao índice. Ele envia solicitações de indexação primeiro para nós de dados que contenham fragmentos primários e depois para nós de dados que contenham fragmentos de réplica. As solicitações de pesquisa são encaminhadas pelo nó coordenador para um fragmento primário ou de réplica para todos os fragmentos pertencentes ao índice.
Por exemplo, para um índice com cinco fragmentos primários e uma réplica, cada solicitação de indexação toca em dez fragmentos. Por outro lado, as solicitações de pesquisa são enviadas para n fragmentos, onde n é o número de fragmentos primários. Para um índice com cinco fragmentos primários e uma réplica, cada consulta de pesquisa toca em cinco fragmentos (primários ou de réplica) desse índice.
Determinar as contagens de fragmentos e de nós de dados
Use as seguintes práticas recomendadas para determinar contagens de fragmentos e nós de dados para seu domínio.
Tamanho do fragmento: o tamanho dos dados no disco é um resultado direto do tamanho dos dados de origem e se altera à medida que você indexa mais dados. A source-to-index proporção pode variar muito, de 1:10 a 10:1 ou mais, mas geralmente é em torno de 1:1,10. Você pode usar essa proporção para prever o tamanho do índice no disco. Você pode indexar alguns dados e recuperar os tamanhos reais do índice para determinar a proporção de sua workload. Após prever um tamanho de índice, defina uma contagem de fragmentos de modo que cada fragmento tenha entre 10 e 30 GiB (para workloads de pesquisa) ou entre 30 e 50 GiB (para workloads de logs). O máximo deve ser 50 GiB; não se esqueça de planejar o crescimento.
Contagem de fragmentos: a distribuição de fragmentos para nós de dados tem um grande impacto na performance de um domínio. Quando você tem índices com vários fragmentos, tente fazer com que a contagem de fragmentos seja um múltiplo da contagem de nós de dados. Isso ajuda a garantir que os fragmentos sejam distribuídos uniformemente entre os nós de dados e evita os nós quentes. Por exemplo, se você tiver 12 fragmentos primários, sua contagem de nós de dados deverá ser 2, 3, 4, 6 ou 12. No entanto, a contagem de fragmentos é secundária ao tamanho do fragmento. Se você tiver 5 GiB de dados, ainda deverá usar um único fragmento.
Fragmentos por nó de dados: o número total de fragmentos que um nó pode conter é proporcional à memória heap da máquina virtual Java (JVM) do nó. Busque 25 fragmentos ou menos para cada GiB de memória heap. Por exemplo, um nó com 32 GiB de memória heap não deve conter mais de 800 fragmentos. Embora a distribuição de fragmentos possa variar de acordo com seus padrões de carga de trabalho, há um limite de 1.000 fragmentos por nó para o Elasticsearch e de OpenSearch 1,1 a 2,15 e 4.000 para 2,17 e superior. OpenSearch A API cat/allocation
Proporção de fragmentos para CPU: quando um fragmento está envolvido em uma solicitação de indexação ou pesquisa, ele utiliza uma vCPU para processar a solicitação. Como prática recomendada, use um ponto de escala inicial de 1,5 vCPU por fragmento. Se o tipo de instância tiver 8 vCPUs, defina a contagem de nós de dados para que cada nó tenha no máximo seis fragmentos. Observe que isso é uma aproximação. Certifique-se de testar sua workload e escalar seu cluster adequadamente.
Para obter recomendações sobre volume de armazenamento, tamanho do fragmento e tipo de instância, consulte os seguintes recursos:
Evitar distorções de armazenamento
A distorção de armazenamento ocorre quando um ou mais nós de um cluster mantêm uma proporção maior de armazenamento para um ou mais índices do que para outros. Podem indicar distorções de armazenamento: utilização de CPU desigual, latência intermitente e desigual e enfileiramento desigual entre nós de dados. Para determinar se você tem problemas de distorção, consulte as seguintes seções de resolução de problemas:
Estabilidade
As melhores práticas a seguir se aplicam à manutenção de um domínio de OpenSearch serviço estável e íntegro.
Mantenha-se atualizado com OpenSearch
Atualizações de software de serviço
OpenSearch O serviço lança regularmente atualizações de software que adicionam recursos ou melhoram seus domínios. As atualizações não alteram a versão do mecanismo OpenSearch ou do Elasticsearch. Recomendamos que você agende um horário recorrente para executar a operação da DescribeDomainAPI e inicie uma atualização do software de serviço, se for o UpdateStatus caso. ELIGIBLE Se você não atualizar seu domínio dentro de um determinado período de tempo (normalmente duas semanas), o OpenSearch Serviço executará a atualização automaticamente.
OpenSearch atualizações de versão
OpenSearch O serviço adiciona regularmente suporte para versões mantidas pela comunidade do. OpenSearch Sempre atualize para as OpenSearch versões mais recentes quando elas estiverem disponíveis.
OpenSearch O serviço atualiza simultaneamente os OpenSearch OpenSearch painéis (ou o Elasticsearch e o Kibana, se seu domínio estiver executando um mecanismo legado). Se o cluster tiver nós principais dedicados, as atualizações serão concluídas sem tempo de inatividade. Caso contrário, o cluster pode não responder por vários segundos após a atualização enquanto elege um nó principal. OpenSearch Os painéis podem estar indisponíveis durante parte ou toda a atualização.
Há duas maneiras de atualizar um domínio:
-
Atualização no local: esta opção é mais fácil porque você mantém o mesmo cluster.
-
Atualização de snapshot/restauração: esta opção serve para testar novas versões em um novo cluster ou realizar migrações entre clusters.
Independentemente do processo de atualização usado, recomendamos manter um domínio exclusivamente para desenvolvimento e teste e atualizá-lo para a nova versão antes de atualizar o domínio de produção. Escolha Desenvolvimento e teste como tipo de implantação ao criar o domínio de teste. Certifique-se de atualizar todos os clientes para versões compatíveis imediatamente após a atualização do domínio.
Melhore a performance do snapshot
Para evitar que seu snapshot fique preso no processamento, o tipo de instância do nó principal dedicado deve corresponder à contagem de fragmentos. Para obter mais informações, consulte Escolher tipos de instâncias para nós principais dedicados. Além disso, cada nó não deve ter mais de 25 fragmentos recomendados por GiB de memória heap de Java. Para obter mais informações, consulte Como escolher o número de fragmentos.
Habilite nós principais dedicados
Os nós principais dedicados melhoram a estabilidade do cluster. Um nó principal dedicado executa tarefas de gerenciamento de cluster, mas não retém dados de índice nem responde a solicitações de clientes. Essa transferência de tarefas de gerenciamento de cluster aumenta a estabilidade de seu domínio e possibilita que algumas alterações de configuração ocorram sem tempo de inatividade.
Habilite e use três nós principais dedicados para obter estabilidade de domínio ideal em três zonas de disponibilidade. A implantação com multi-AZ com modo de espera configura três nós principais dedicados para você. Para obter recomendações sobre tipos de instâncias, consulte Escolher tipos de instâncias para nós principais dedicados.
Implantar em diversas zonas de disponibilidade
Para evitar a perda de dados e minimizar o tempo de inatividade do cluster em caso de interrupção do serviço, você pode distribuir nós em duas ou três zonas de disponibilidade na mesma Região da AWS. A melhor prática é implantar o multi-AZ com modo de espera, que configura três zonas de disponibilidade, com duas zonas ativas e uma atuando em espera, e com dois fragmentos de réplica por índice. Essa configuração permite que o OpenSearch Service distribua fragmentos de réplica para fragmentos AZs diferentes dos principais correspondentes. Não há cobranças de transferência de dados entre AZs para comunicações de cluster entre zonas de disponibilidade.
As zonas de disponibilidade são vários locais isolados dentro de cada região da . Com uma configuração de duas AZ (zonas de disponibilidade), perder uma zona de disponibilidade significa que você perde metade de toda a capacidade do domínio. A mudança para três zonas de disponibilidade reduz ainda mais o impacto da perda de uma única zona de disponibilidade.
Controlar o fluxo de ingestão e o armazenamento em buffer
Recomendamos limitar a contagem geral de solicitações usando a operação de API _bulk_bulk contendo 5 mil documentos do que enviar 5 mil solicitações contendo um único documento.
Para uma estabilidade operacional ideal, às vezes é necessário limitar ou até mesmo pausar o fluxo de envio de informação de solicitações de indexação. Limitar a taxa de solicitações de indexação é um mecanismo importante para lidar com picos inesperados ou ocasionais nas solicitações que poderiam sobrecarregar o cluster. Considere a criação de um mecanismo de controle de fluxo em sua arquitetura de envio de informação.
O diagrama a seguir mostra diversas opções de componentes para uma arquitetura de ingestão de log. Configure a camada de agregação para permitir espaço suficiente para armazenar em buffer os dados de entrada para picos de tráfego repentinos e breve manutenção de domínio.
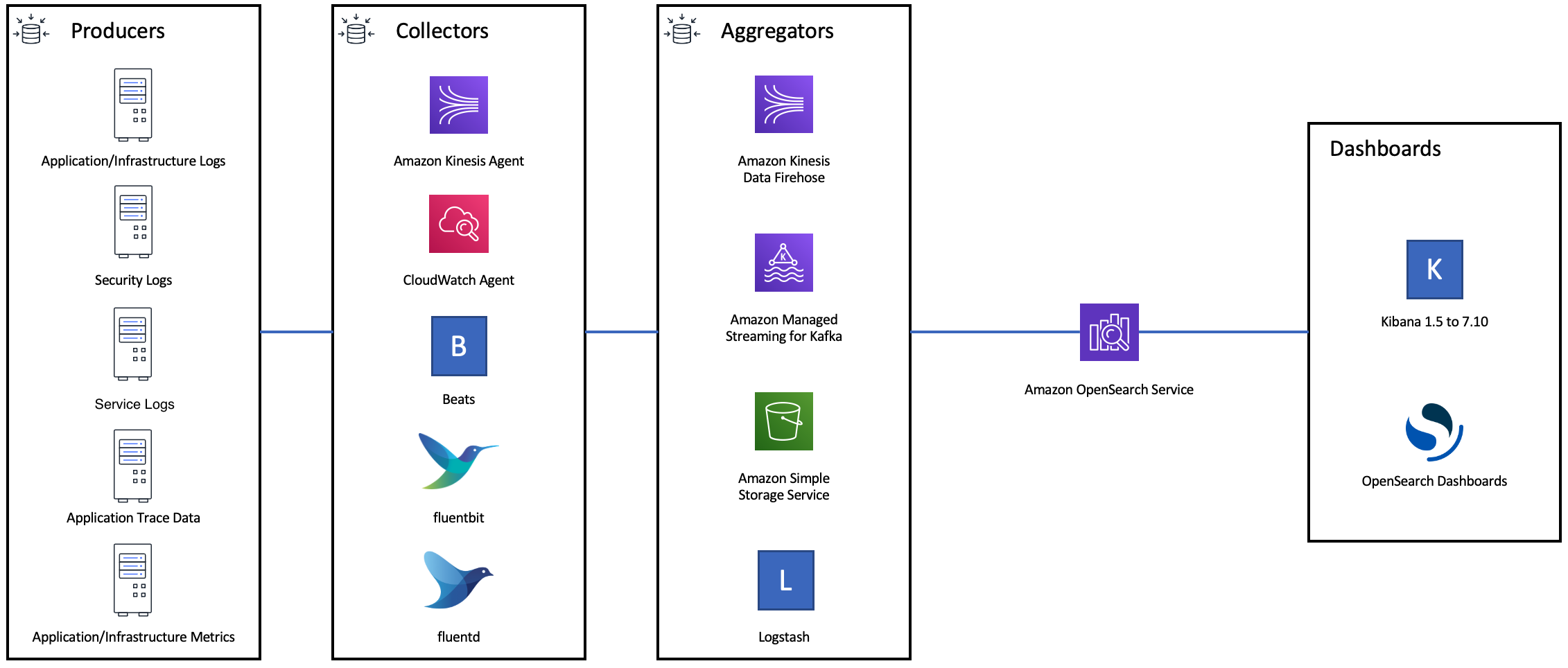
Criar mapeamentos para workloads de pesquisa
Para cargas de trabalho de pesquisa, crie mapeamentosdynamic como strict para evitar adicionar novos campos acidentalmente.
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Usar modelos de índice
Você pode usar um modelo de índice
As configurações a seguir são úteis para configurar em modelos:
-
Número de fragmentos primários e de réplica
-
Intervalo de atualização (com que frequência atualizar e realizar alterações recentes no índice disponível para pesquisa)
-
Controle de mapeamento dinâmico
-
Mapeamentos de campos explícitos
O modelo de exemplo a seguir contém cada uma destas configurações:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Mesmo que raramente mudem, ter configurações e mapeamentos definidos centralmente OpenSearch é mais simples de gerenciar do que atualizar vários clientes upstream.
Gerenciar índices com o Index State Management
Se você estiver gerenciando logs ou dados de séries temporais, recomendamos usar o ISM – Gerenciamento de estados de índice. O ISM permite automatizar tarefas regulares de gerenciamento do ciclo de vida do índice. Com o ISM, você pode criar políticas que invocam sobreposições de alias de índice, obter snapshots de índices, mover índices entre camadas de armazenamento e excluir índices antigos. Você pode até mesmo usar a operação de sobreposição
Primeiro, configure uma política de ISM. Por exemplo, consulte Políticas de exemplo. Em seguida, anexe a política a um ou mais índices. Se você incluir um campo de modelo ISM na política, o OpenSearch Service aplicará automaticamente a política a qualquer índice que corresponda ao padrão especificado.
Remover índices não utilizados
Revise regularmente os índices em seu cluster e identifique os que não estão em uso. Obtenha um snapshot desses índices para que sejam armazenados no S3 e depois exclua-os. Ao remover os índices não utilizados, você reduz a contagem de fragmentos e permite uma distribuição mais equilibrada de armazenamento e utilização de recursos entre os nós. Mesmo quando estão ociosos, os índices consomem alguns recursos durante as atividades internas de manutenção do índice.
Em vez de excluir manualmente os índices não utilizados, você pode usar o ISM para obter automaticamente um snapshot e excluir índices após um determinado período.
Usar vários domínios para alta disponibilidade
Para alcançar alta disponibilidade além de 99,9% de tempo de atividade
Projete seus aplicativos de envio e recebimento de informação com o failover em mente. Certifique-se de testar o processo de failover junto com outros processos de recuperação de desastres.
Performance
As práticas recomendadas a seguir se aplicam ao ajuste de seus domínios para obter uma performance ideal.
Otimizar o tamanho e a compactação de solicitações em massa
O dimensionamento em massa depende dos dados, da análise e da configuração do cluster, mas um bom ponto de partida é de 3 a 5 MiB por solicitação em massa.
Envie solicitações e receba respostas de seus OpenSearch domínios usando a compressão gzip para reduzir o tamanho da carga útil das solicitações e respostas. Você pode usar a compactação gzip com o cliente OpenSearch Python ou incluir os seguintes cabeçalhos do lado do cliente:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Para otimizar os tamanhos das solicitações em massa, comece com um tamanho de solicitação em massa de 3 MiB. Em seguida, aumente aos poucos o tamanho da solicitação até que a performance da indexação deixe de melhorar.
nota
Para habilitar a compactação gzip em domínios que executam o Elasticsearch versão 6.x, você deve definir http_compression.enabled no nível do cluster. Essa configuração é verdadeira por padrão nas versões 7.x do Elasticsearch e em todas as versões do. OpenSearch
Reduzir o tamanho das respostas de solicitações em massa
Para reduzir o tamanho das OpenSearch respostas, exclua campos desnecessários com o filter_path parâmetro. Verifique se não filtrou os campos necessários para identificar ou repetir as solicitações com falha. Para ter mais informações e exemplos, consulte Redução do tamanho da resposta.
Ajustar os intervalos de atualização
OpenSearch os índices têm uma eventual consistência de leitura. Uma operação de atualização disponibiliza todas as atualizações executadas em um índice para pesquisa. O intervalo de atualização padrão é de um segundo, o que significa que ele OpenSearch executa uma atualização a cada segundo enquanto um índice está sendo gravado.
Quanto menor a frequência com que você atualizar um índice (maior intervalo de atualização), melhor será a performance geral da indexação. A desvantagem de aumentar o intervalo de atualização é que há um atraso maior entre uma atualização de índice e quando os novos dados estão disponíveis para pesquisa. Defina o intervalo de atualização mais alto possível para melhorar a performance geral.
Recomendamos definir o parâmetro refresh_interval de todos os seus índices para 30 segundos ou mais.
Habilitar o Auto-Tune
O Auto-Tune usa métricas de desempenho e uso do seu OpenSearch cluster para sugerir alterações nos tamanhos das filas, nos tamanhos do cache e nas configurações da máquina virtual Java (JVM) nos seus nós. Essas alterações opcionais melhoram a velocidade e a estabilidade do cluster. Você pode voltar às configurações padrão do OpenSearch Serviço a qualquer momento. O Auto-Tune é habilitado por padrão em novos domínios, a menos que você o desabilite explicitamente.
Recomendamos habilitar o Auto-Tune em todos os domínios e definir uma janela de manutenção recorrente ou revisar periodicamente as recomendações.
Segurança
As práticas recomendadas a seguir se aplicam à proteção de seus domínios.
Habilite o controle de acesso detalhado
O controle de acesso refinado permite que você controle quem pode acessar determinados dados em um OpenSearch domínio do Serviço. Comparado ao controle de acesso generalizado, o controle de acesso detalhado fornece a cada cluster, índice, documento e campo sua própria política de acesso especificada. Os critérios de acesso podem ser baseados em vários fatores, como o perfil da pessoa que solicita o acesso e a ação que ela pretende realizar nos dados. Por exemplo, você pode conceder a um usuário acesso para gravar em um índice, e outro usuário pode receber acesso apenas para ler os dados no índice sem fazer alterações.
O controle de acesso detalhado permite que dados com diferentes requisitos de acesso existam no mesmo espaço de armazenamento sem problemas de segurança ou conformidade.
Recomendamos habilitar o controle de acesso detalhado em seus domínios.
Implantar domínios em uma VPC
Colocar seu domínio de OpenSearch serviço em uma nuvem privada virtual (VPC) ajuda a permitir a comunicação segura entre o OpenSearch serviço e outros serviços dentro da VPC, sem a necessidade de um gateway de internet, dispositivo NAT ou conexão VPN. Todo o tráfego permanece seguro na nuvem. AWS Devido ao seu isolamento lógico, os domínios que residem em uma VPC contam com uma camada adicional de segurança se comparados aos domínios que utilizam endpoints públicos.
Recomendamos que você crie seus domínios em uma VPC.
Aplicar uma política de acesso restritiva
Mesmo que seu domínio esteja implantado em uma VPC, uma prática recomendada é implementar a segurança em camadas. Certifique-se de verificar a configuração de suas políticas de acesso atuais.
Aplique uma política restritiva de acesso baseada em recursos aos seus domínios e siga o princípio do menor privilégio ao conceder acesso à API de configuração e às operações da API. OpenSearch Como regra geral, evite usar o código "Principal": {"AWS": "*" } da entidade principal do usuário anônimo em suas políticas de acesso.
No entanto, há algumas situações em que é aceitável usar uma política de acesso aberta, como quando você habilita o controle de acesso detalhado. Uma política de acesso aberta pode permitir que você acesse o domínio nos casos em que a assinatura da solicitação é difícil ou impossível, como de determinados clientes e ferramentas.
Habilite a criptografia em repouso
OpenSearch Os domínios de serviço oferecem criptografia de dados em repouso para ajudar a impedir o acesso não autorizado aos seus dados. A criptografia em repouso usa AWS Key Management Service (AWS KMS) para armazenar e gerenciar suas chaves de criptografia e o algoritmo Advanced Encryption Standard com chaves de 256 bits (AES-256) para realizar a criptografia.
Se seu domínio armazena dados confidenciais, habilite a criptografia de dados em repouso.
Ativar node-to-node criptografia
Node-to-node a criptografia fornece uma camada adicional de segurança além dos recursos de segurança padrão do OpenSearch Serviço. Ele implementa o Transport Layer Security (TLS) para todas as comunicações entre os nós que são provisionados nele. OpenSearch Node-to-nodecriptografia, todos os dados enviados ao seu domínio de OpenSearch serviço por HTTPS permanecem criptografados em trânsito enquanto são distribuídos e replicados entre os nós.
Se o seu domínio armazenar dados confidenciais, ative a node-to-node criptografia.
Monitor com AWS Security Hub
Monitore seu uso do OpenSearch Serviço no que se refere às melhores práticas de segurança usando AWS Security Hub. O Security Hub usa controles de segurança para avaliar configurações de recursos e padrões de segurança que ajudam você a cumprir vários frameworks de conformidade. Para obter mais informações sobre como usar o Security Hub para avaliar os recursos do OpenSearch Serviço, consulte Amazon OpenSearch Service os controles no Guia AWS Security Hub do Usuário.
Otimização de custo
As melhores práticas a seguir se aplicam à otimização e economia em seus custos OpenSearch de serviço.
Use os tipos de instâncias de última geração
OpenSearch O serviço está sempre adotando novos tipos de EC2 instâncias da Amazon que oferecem melhor desempenho a um custo menor. Recomendamos sempre usar as instâncias de última geração.
Evite usar instâncias T2 ou t3.small para domínios de produção, porque elas podem se tornar instáveis sob cargas pesadas sustentadas. As instâncias r6g.large são uma opção para pequenas workloads de produção (tanto como nós de dados quanto como nós principais dedicados).
Usar os volumes gp3 do Amazon EBS gp3
OpenSearch os nós de dados exigem armazenamento de baixa latência e alta taxa de transferência para fornecer indexação e consulta rápidas. Ao usar os volumes gp3 do Amazon EBS, você obtém maior desempenho básico (IOPS e throughput) a um custo 9,6% menor do que com o tipo de volume Amazon EBS gp2 oferecido anteriormente. É possível provisionar IOPS e throughput adicionais, independentemente do tamanho do volume, usando gp3. Esses volumes também são mais estáveis do que os volumes da geração anterior, pois não usam créditos intermitentes. O tipo de volume gp3 também dobra os limites de tamanho do per-data-node volume do tipo de volume gp2. Com esses volumes maiores, você pode reduzir o custo dos dados passivos, aumentando a quantidade de armazenamento por nó de dados.
Uso UltraWarm e armazenamento refrigerado para dados de registro de séries temporais
Se você estiver usando OpenSearch para análise de registros, mova seus dados para UltraWarm um armazenamento refrigerado para reduzir custos. Use o Index State Management (ISM) para migrar dados entre camadas de armazenamento e gerenciar a retenção de dados.
UltraWarmfornece uma maneira econômica de armazenar grandes quantidades de dados somente para leitura no Service. OpenSearch UltraWarm usa o Amazon S3 para armazenamento, o que significa que os dados são imutáveis e somente uma cópia é necessária. Você paga apenas pelo armazenamento que é equivalente ao tamanho dos fragmentos primários dos índices. As latências UltraWarm das consultas aumentam com a quantidade de dados do S3 necessária para atender à consulta. Depois que os dados são armazenados em cache nos nós, as consultas aos UltraWarm índices têm um desempenho semelhante às consultas aos índices ativos.
O armazenamento frio também é apoiado pelo S3. Quando precisar consultar dados frios, você pode anexá-los seletivamente aos UltraWarm nós existentes. Os dados frios incorrem no mesmo custo de armazenamento gerenciado UltraWarm, mas os objetos no armazenamento frio não consomem recursos UltraWarm do nó. Portanto, o armazenamento a frio fornece uma quantidade significativa de capacidade de armazenamento sem afetar o tamanho ou a contagem de UltraWarm nós.
UltraWarm torna-se econômico quando você tem aproximadamente 2,5 TiB de dados para migrar do armazenamento dinâmico. Monitore sua taxa de preenchimento e planeje transferir os índices para UltraWarm antes de atingir esse volume de dados.
Revisar as recomendações para instâncias reservadas
Considere comprar Instâncias Reservadas (RIs) depois de ter uma boa linha de base sobre seu desempenho e consumo de computação. Os descontos começam em torno de 30% para reservas não antecipadas de um ano e podem aumentar em até 50% para todas as reservas antecipadas de três anos.
Depois de observar uma operação estável por pelo menos 14 dias, consulte Como acessar as recomendações de reserva no Guia AWS Cost Management do usuário. O título do Amazon OpenSearch Service exibe recomendações específicas de compra de RI e economias projetadas.
