Use Ground Truth to Label 3D Point Clouds
Create a 3D point cloud labeling job to have workers label objects in 3D point clouds generated from 3D sensors like Light Detection and Ranging (LiDAR) sensors and depth cameras, or generated from 3D reconstruction by stitching images captured by an agent like a drone.
3D Point Clouds
Point clouds are made up of three-dimensional (3D) visual data that consists of
points. Each point is described using three coordinates, typically
x, y, and z. To add color or variations in
point intensity to the point cloud, points may be described with additional attributes,
such as i for intensity or values for the red (r), green
(g), and blue (b) 8-bit color channels. When you create a Ground Truth
3D point cloud labeling job, you can provide point cloud and, optionally, sensor fusion
data.
The following image shows a single, 3D point cloud scene rendered by Ground Truth and displayed in the semantic segmentation worker UI.
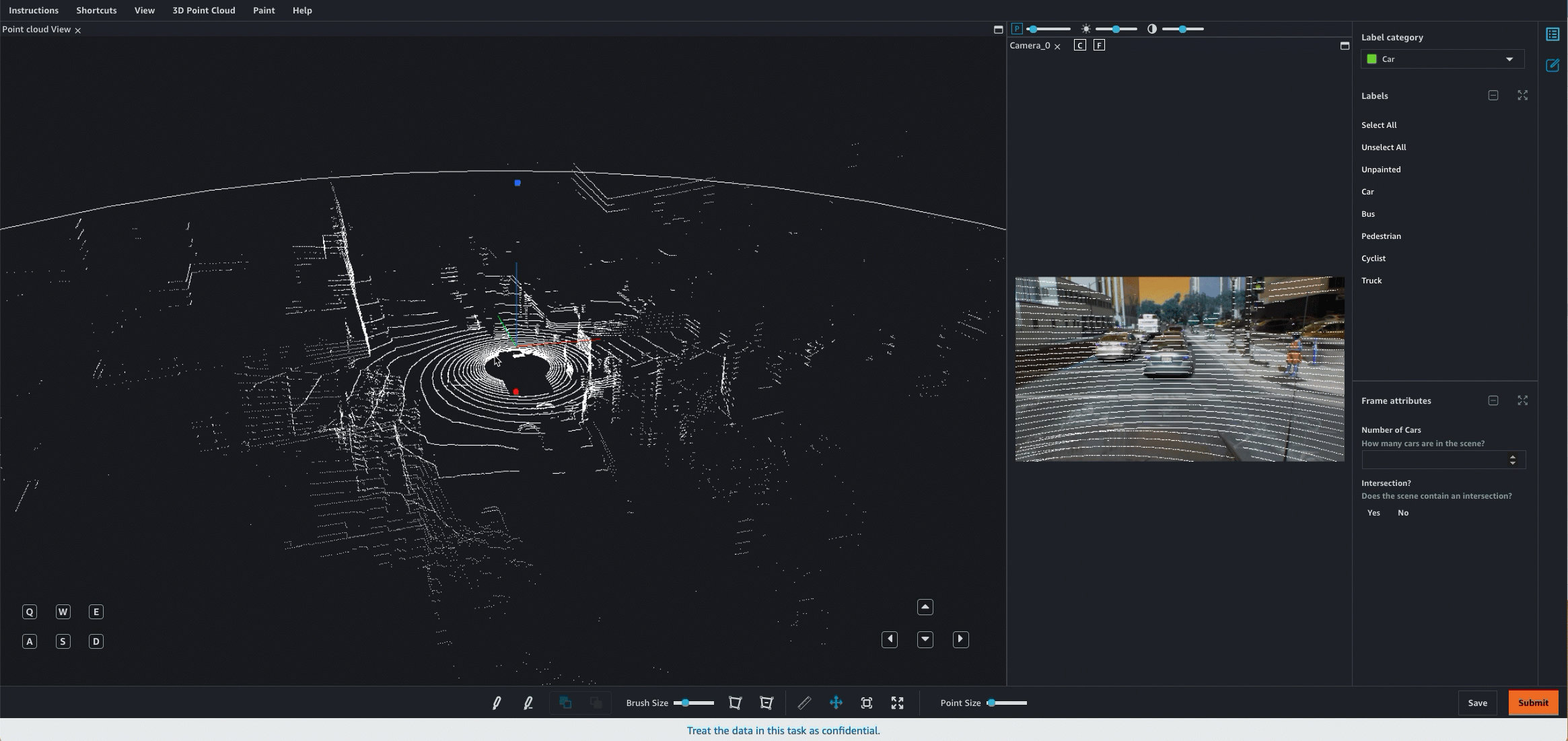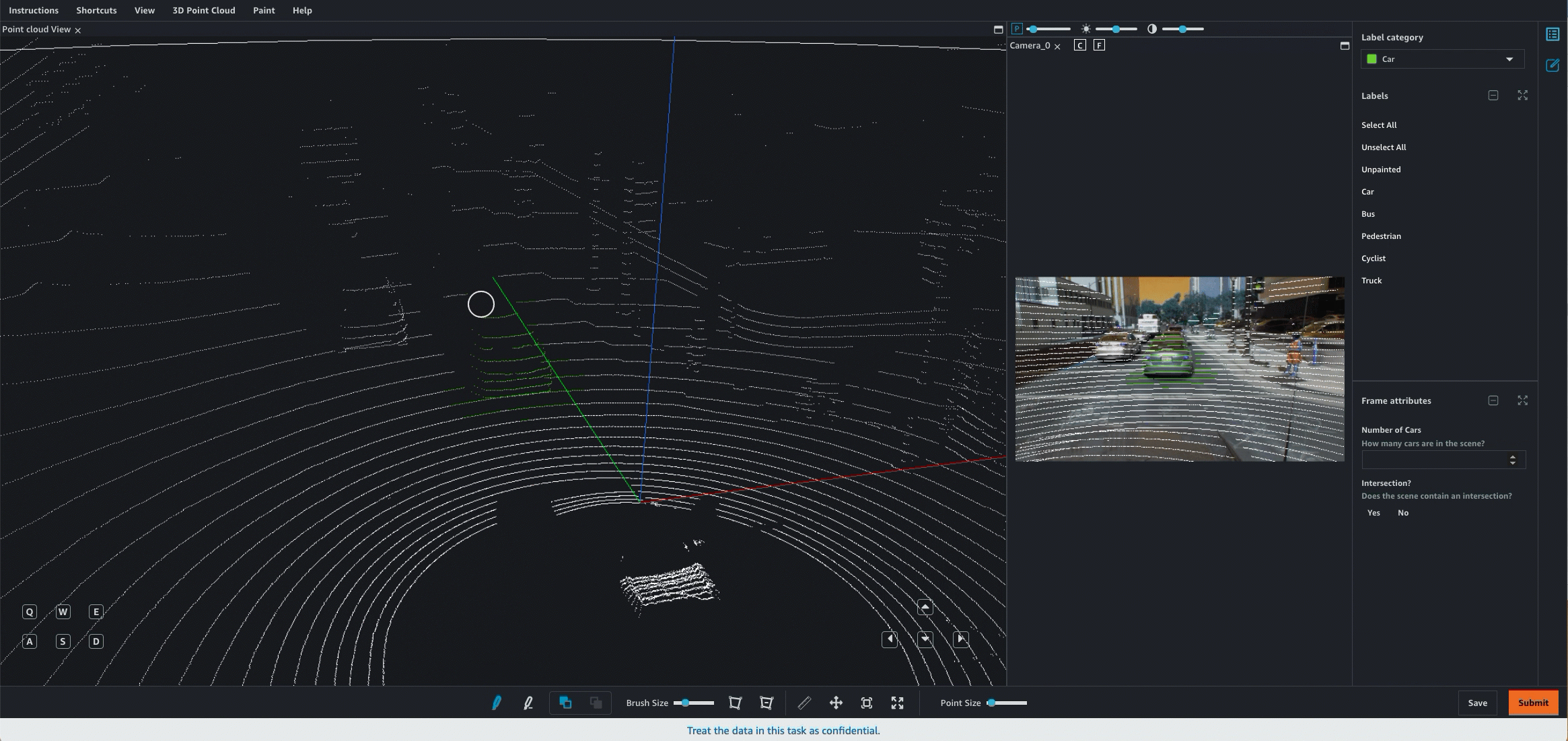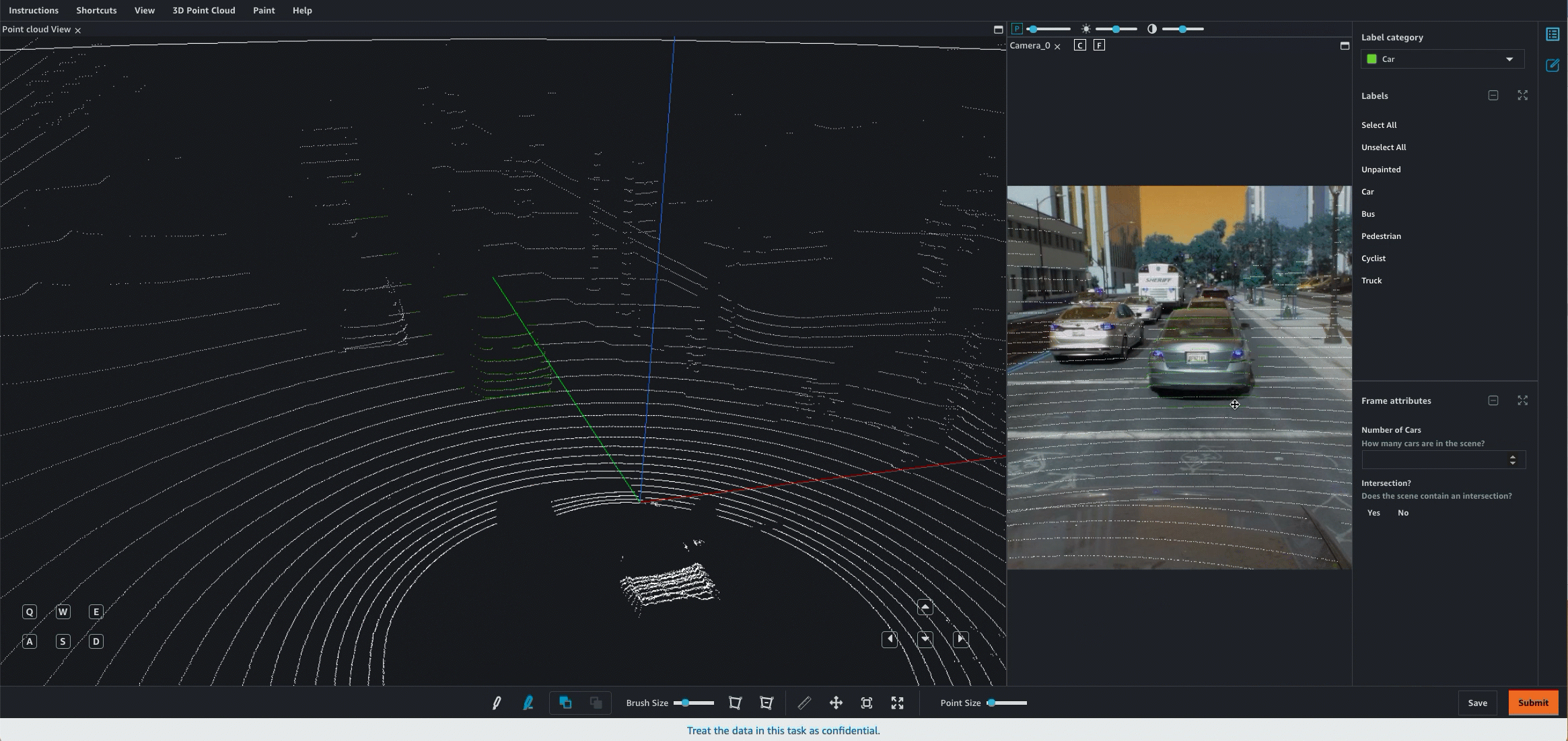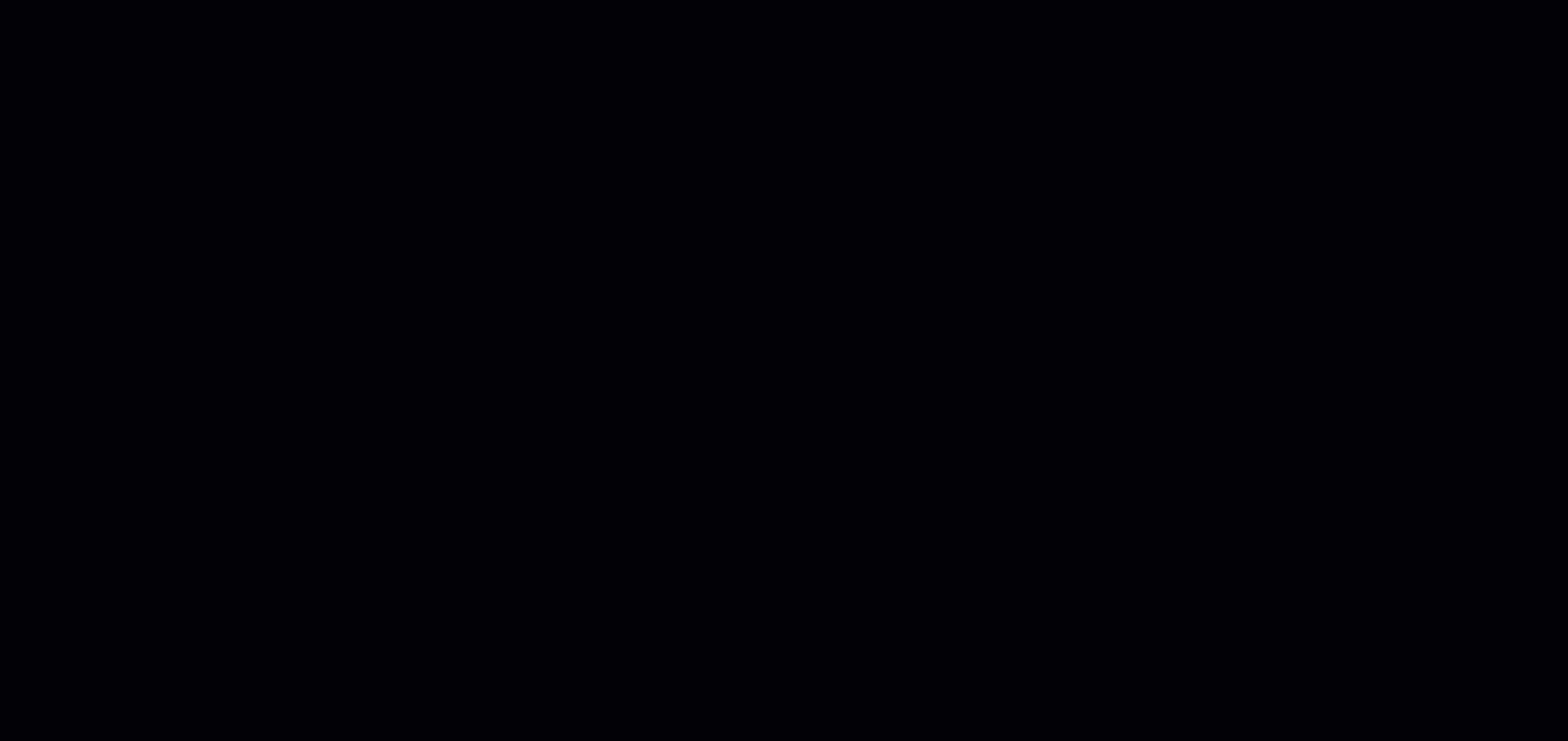
LiDAR
A Light Detection and Ranging (LiDAR) sensor is a common type of sensor used to collect measurements that are used to generate point cloud data. LiDAR is a remote sensing method that uses light in the form of a pulsed laser to measure the distances of objects from the sensor. You can provide 3D point cloud data generated from a LiDAR sensor for a Ground Truth 3D point cloud labeling job using the raw data formats described in Accepted Raw 3D Data Formats.
Sensor Fusion
Ground Truth 3D point cloud labeling jobs include a sensor fusion feature that supports video camera sensor fusion for all task types. Some sensors come with multiple LiDAR devices and video cameras that capture images and associate them with a LiDAR frame. To help annotators visually complete your tasks with high confidence, you can use the Ground Truth sensor fusion feature to project annotations (labels) from a 3D point cloud to 2D camera images and vice versa using 3D scanner (such as LiDAR) extrinsic matrix and camera extrinsic and intrinsic matrices. To learn more, see Sensor Fusion.
Label 3D Point Clouds
Ground Truth provides a user interface (UI) and tools that workers use to label or annotate 3D point clouds. When you use the object detection or semantic segmentation task types, workers can annotate a single point cloud frame. When you use object tracking, workers annotate a sequence of frames. You can use object tracking to track object movement across all frames in a sequence.
The following demonstrates how a worker would use the Ground Truth worker portal and tools to annotate a 3D point cloud for an object detection task. For similar visual examples of other task types, see 3D Point Cloud Task types.
Assistive Labeling Tools for Point Cloud Annotation
Ground Truth offers assistive labeling tools to help workers complete your point cloud annotation tasks faster and with more accuracy. For details about assistive labeling tools that are included in the worker UI for each task type, select a task type and refer to the View the Worker Task Interface section of that page.
Next Steps
You can create six types of tasks when you use Ground Truth 3D point cloud labeling jobs. Use the topics in 3D Point Cloud Task types to learn more about these task types and to learn how to create a labeling job using the task type of your choice.
The 3D point cloud labeling job is different from other Ground Truth labeling modalities. Before creating a labeling job, we recommend that you read 3D point cloud labeling jobs overview. Additionally, review input data quotas in 3D Point Cloud and Video Frame Labeling Job Quotas.
Important
If you use a notebook instance created before June 5th, 2020 to run this notebook, you must stop and restart that notebook instance for the notebook to work.
