本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
目标情绪
目标情绪可让您详细了解与输入文档中特定实体(例如品牌或产品)关联的情绪。
目标情绪和情绪之间的区别在于输出数据的粒度级别。情绪分析确定每个输入文档的主导情绪,但不提供用于进一步分析的数据。目标情绪分析确定每个输入文档中特定实体的实体级情绪。您可以分析输出数据以确定获得正面或负面反馈的特定产品和服务。
例如,在一组餐厅评论中,一位顾客提供了以下评论:“炸玉米饼很好吃,工作人员也很友善。” 对该评论的分析得出以下结果:
情绪分析将确定每条餐厅评论中的总体情绪是积极、消极、中性或混合。在此示例中,总体情绪是积极的。
目标情绪分析可以确定顾客在评论中提到的对于餐厅实体和属性的情绪。在此示例中,客户对“炸玉米饼”和“员工”给予了积极评价。
目标情绪为每项分析任务提供以下输出:
文档中提及的实体的身份。
-
每个提及的实体的实体类型分类。
提及的每个实体的情绪和情绪分数。
对应于单个实体的提及组(共同引用组)。
您可以使用控制台或 API 来运行目标情绪分析。控制台和 API 支持针对目标情绪的实时分析和异步分析。
Amazon Comprehend 支持对英语文档进行目标情绪分析。
有关定向情绪的更多信息(包括教程),请参阅机器学习博客中的使用 Amazon Comprehend 目标情绪在文本中提取精细情绪
实体类型
目标情绪可识别以下实体类型。如果实体不属于任何其他类别,则它会分配实体类型 OTHER。输出文件中提及的每个实体都包括实体类型,例如 "Type": "PERSON"。
| 实体类型 | 定义 |
|---|---|
| 个人 | 示例包括个人、群体、昵称、虚构人物和动物名称。 |
| LOCATION | 地理位置,例如国家、城市、州、地址、地质构造、水体、自然地标和天文位置。 |
| 组织 | 示例包括政府、公司、运动队和宗教。 |
| FACILITY | 建筑物、机场、高速公路、桥梁和其他永久性人造结构和房地产改造。 |
| BRAND | 特定商业项目或产品系列的组织、团体或生产商。 |
| COMMERCIAL_ITEM | 任何非通用可购买或可获得的物品,包括车辆和仅生产一件物品的大型产品。 |
| MOVIE | 电影或电视节目。实体可以是全名、昵称或副标题。 |
| MUSIC | 一首歌曲,全部或部分歌曲。此外,还有个人音乐创作的集合,例如专辑或选集。 |
| BOOK | 一本书,专业出版或自行出版。 |
| SOFTWARE | 正式发布的软件产品。 |
| GAME | 一种游戏,例如电子游戏、棋盘游戏、普通游戏或体育运动。 |
| PERSONAL_TITLE | 官方头衔和荣誉,例如校长、博士学位或博士. |
| EVENT | 示例包括节日、音乐会、选举、战争、会议和宣传活动。 |
| DATE | 对日期或时间的任何引用,无论是具体的还是一般的,无论是绝对的还是相对的。 |
| 数量 | 所有测量值及其单位(货币、百分比、数字、字节等)。 |
| ATTRIBUTE | 实体的一种属性、特征或特性,例如产品的“质量”、手机的“价格”或 CPU 的“速度”。 |
| OTHER | 不属于任何其他类别的实体。 |
共同引用组
目标情绪标识每个输入文档中的共同引用组。共同引用组是文档中对应于一个现实世界实体的一组提及。
在以下客户评论示例中,“spa”是实体,其实体类型是 FACILITY。该实体还有两次作为代词(“it”)被提及。

输出文件组织
目标情绪分析任务会创建一个 JSON 文本输出文件。该文件包含每个输入文档的一个 JSON 对象。每个 JSON 对象包含以下字段:
-
实体:在文档中找到的实体数组。
-
文件:输入文档的文件名。
-
行:如果输入文件每行一个文档,则实体包含文件中该文档的行号。
注意
如果目标情绪在输入文本中未识别出任何实体,则它将返回一个空数组作为实体结果。
以下示例显示了包含三行输入的输入文件的实体。输入格式为每行一个文档,因此每行输入都是一个文档。
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}实体数组中的实体包括文档中检测到的实体提及的逻辑分组(称为共同引用组)。每个实体的总体结构如下:
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} 实体包含以下字段:
-
提及:文档中提及该实体的数组。该数组代表一个共同引用组。有关示例,请参阅 共同引用组。提及数组中提及的顺序是它们在文档中的位置(偏移量)顺序。每次提及都包括该提及的情绪分数和小组分数。小组分数表示这些提及属于同一实体的置信度。
-
DescriptiveMentionIndex— “提及” 数组中的一个或多个索引,该索引为实体组提供最佳名称。例如,一个实体可能有三个提及,其文本值为“ABC 酒店”、“ABC 酒店”和“it”。最好的名字是 “ABC Hotel”,其 DescriptiveMentionIndex 值为 [0,1]。
每次提及都包含以下字段
-
BeginOffset— 提及开始处的文档文本中的偏移量。
-
EndOffset— 文档文本中提及结束处的偏移量。
GroupScore— 确信该组中提到的所有实体都与同一个实体有关。
文本:文档中用于标识实体的文本。
类型1:实体的类型。Amazon Comprehend 支持多种实体类型。
分数:对实体相关性的置信度进行建模。值范围为 0 到 1,其中 1 表示置信度最高。
MentionSentiment— 包含提及的情绪和情绪分数。
情绪:提及的情绪。值包括:积极、中性、消极和混合。
SentimentScore— 为每种可能的情绪提供模型信心。值范围为 0 到 1,其中 1 表示置信度最高。
情绪值具有以下含义:
-
积极:提及的实体表达积极的情绪。
-
消极:提及的实体表示消极的情绪。
-
混合:提及的实体既表达了积极情绪,也表达了消极情绪。
-
中性:提及的实体不表达积极或消极的情绪。
在以下示例中,一个实体在输入文档中只有一个提及,因此 DescriptiveMentionIndex为零(提及数组中的第一个提及)。被识别的实体是一个名为“I”的人,情绪分数是中性的。
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
使用控制台进行实时分析
您可以使用 Amazon Comprehend 控制台实时运行 目标情绪。使用示例文本或将您自己的文本粘贴到输入文本框中,然后选择分析。
在见解面板中,控制台显示目标情绪分析的三个视图:
-
分析的文本:显示分析的文本并给每个实体加下划线。下划线的颜色表示分析分配给实体的情绪值(积极、中性、消极或混合)。控制台将颜色映射显示在分析文本框的右上角。如果将光标悬停在实体上,控制台会显示一个弹出式面板,其中包含该实体的分析值(实体类型、情绪分数)。
-
结果:显示一个表格,其中包含文本中标识的每个实体提及的一行。对于每个实体,该表显示了实体和实体分数。该行还包括主要情绪和每个情绪值的分数。如果多次提及同一个实体(称为 共同引用组),则表格会将这些提及显示为一组与主实体关联的可折叠行。
如果将鼠标悬停在结果表中的实体行上,则控制台会在分析文本面板中突出显示提及的实体。
-
应用程序集成:显示 API 请求的参数值以及 API 响应中返回的 JSON 对象的结构。有关 JSON 对象中字段的描述,请参阅 输出文件组织。
控制台实时分析示例
此示例使用以下文本作为输入,这是控制台提供的默认输入文本。
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
分析文本面板显示了此示例的以下输出。将鼠标悬停在文本 Zhang Wei 上方可查看该实体的弹出面板。
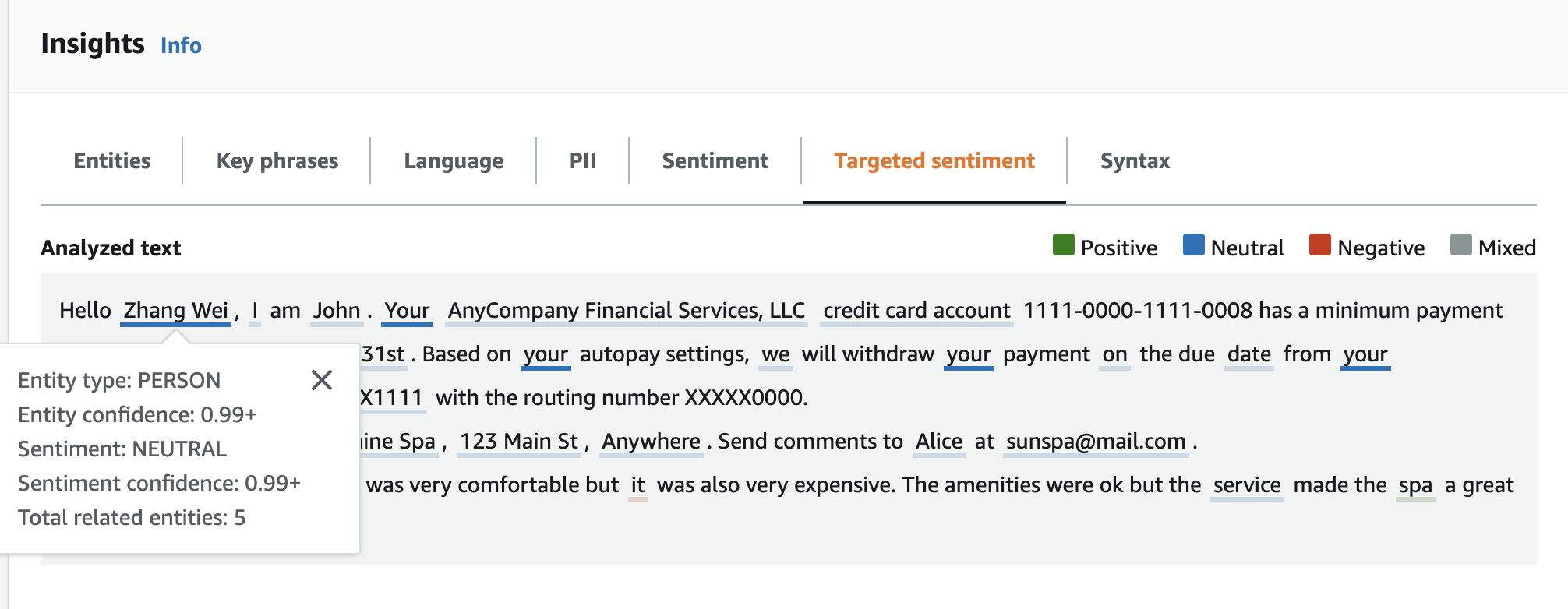
结果表提供了有关每个实体的更多详细信息,包括实体得分、主要情绪和每种情绪的分数。
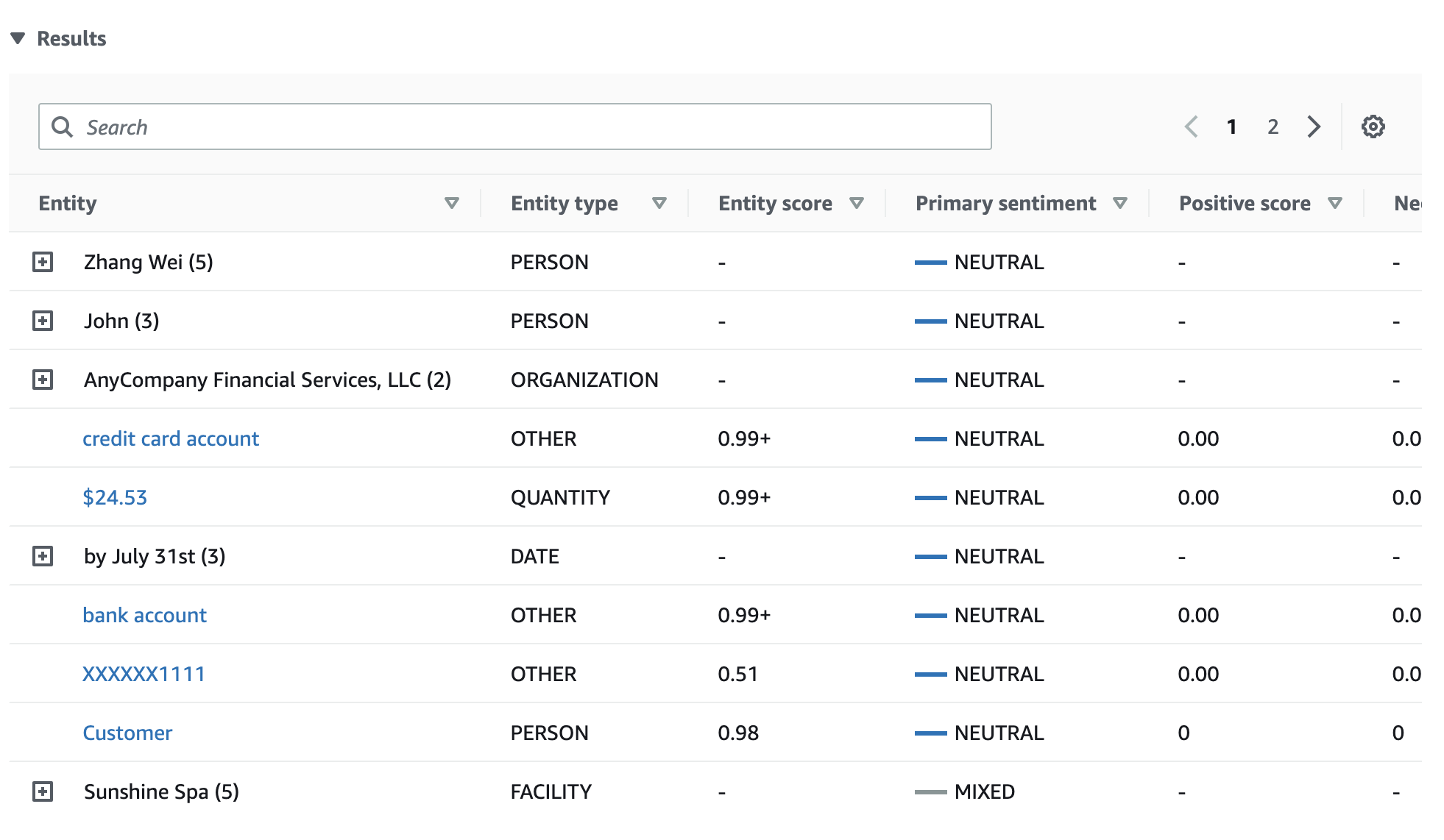
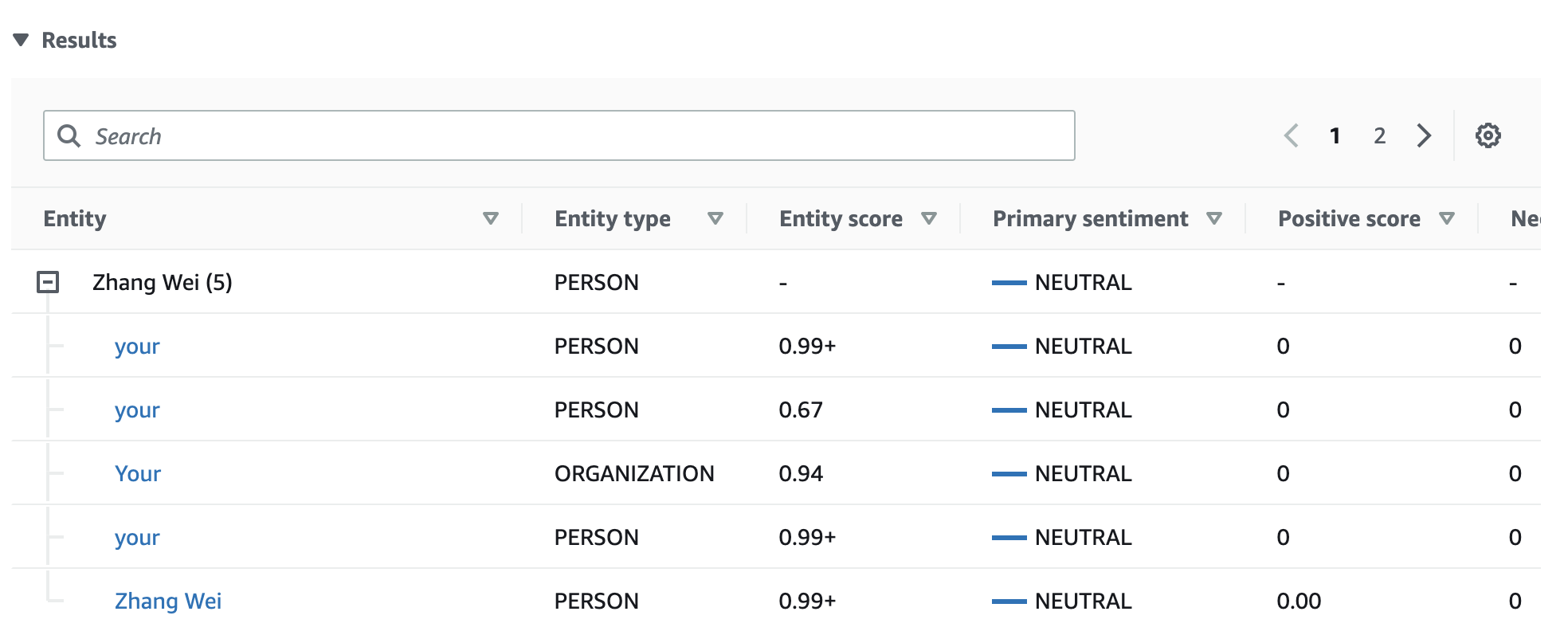
在本示例中,目标情绪分析可以识别出,在输入文本中每次提及你都是对人物实体张伟的引用。控制台将这些提及显示为一组与主实体关联的可折叠行。
应用程序集成面板显示 DetectTargetedSentiment API 生成的 JSON 对象。有关完整示例,请参阅下一节。
目标情绪输出示例
以下示例显示了目标情绪分析任务的输出文件。输入文件由三个简单的文档组成:
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
对该输入文件进行目标情绪分析会产生以下输出。
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}