本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Personalize 生成个性化和重新排名的推荐
亚马逊 Web Services 的 Mason Cahill、Matthew Chasse 和 Tayo Olajide
摘要
此模式向您展示如何使用 Amazon Personalize 根据从这些用户那里摄取的实时用户互动数据,为用户生成个性化推荐(包括重新排名的推荐)。此模式中使用的示例场景基于宠物收养网站,该网站根据用户的互动(例如,用户访问的宠物)为其用户生成推荐。通过遵循示例场景,您将学习使用 Amazon Kinesis Data Streams 提取互动数据,使用 AWS Lambda 生成推荐并对推荐进行重新排名,以及使用 Amazon Data Firehose 将数据存储在亚马逊简单存储服务 (Amazon S3) 存储桶中。您还将学习使用 AWS Step Functions 来构建状态机以管理生成推荐的解决方案版本(即经过训练的模型)。
先决条件和限制
先决条件
一个有效的 Amazon Web Services account
,其中包含已引导的 AWS Cloud Development Kit(AWS CDK) AWS 命令行界面(AWS CLI),带有配置的凭证
产品版本
Python 3.9
AWS CDK 2.23.0 或更高版本
AWS CLI 2.7.27 或更高版本
架构
技术堆栈
Amazon Data Firehose
Amazon Kinesis Data Streams
Amazon Personalize
Amazon Simple Storage Service(Amazon S3)
AWS Cloud Development Kit (AWS CDK)
AWS 命令行界面(AWS CLI)
AWS Lambda
AWS Step Functions
目标架构
下图说明了将实时数据摄取到 Amazon Personalize 的管线。然后,该管线使用这些数据为用户生成个性化和重新排名的推荐。
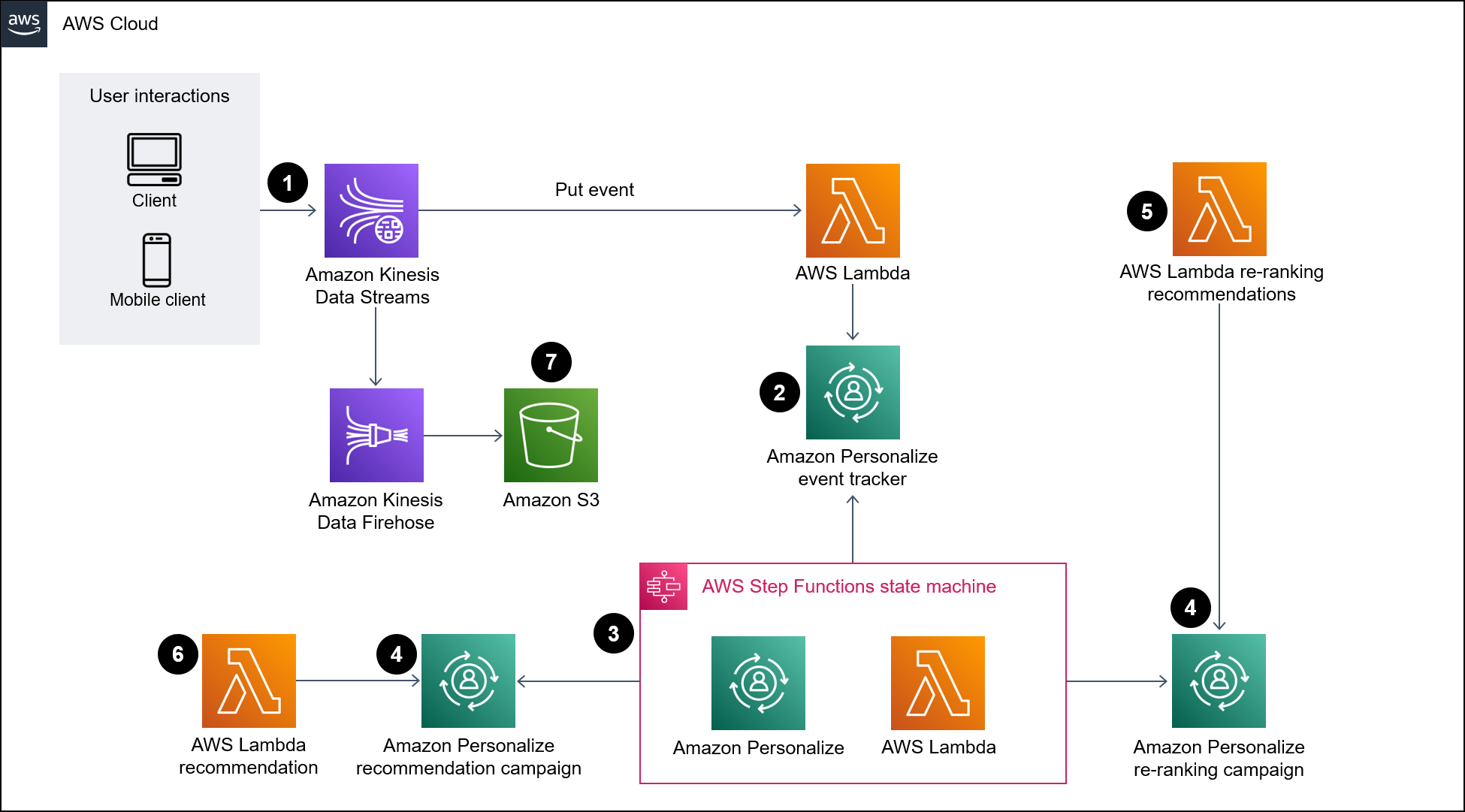
图表显示了以下工作流:
Kinesis Data Streams 提取实时用户数据(例如,拜访过的宠物之类的事件),由 Lambda 和 Firehose 处理。
Lambda 函数处理来自 Kinesis Data Streams 的记录,并发出 API 调用,将记录中的用户互动添加到 Amazon Personalize 中的事件跟踪器中。
基于时间的规则调用 Step Functions 状态机,并使用 Amazon Personalize 中事件跟踪器中的事件为推荐和重新排名模型生成新的解决方案版本。
Lambda 通过调用 Amazon Personalize 重新排名活动对推荐项目列表进行重新排名。
Lambda 通过调用 Amazon Personalize 推荐活动对推荐项目列表进行检索。
Firehose 将事件保存到 S3 存储桶中,在那里可以将其作为历史数据进行访问。
工具
AWS 工具
AWS Cloud Development Kit (AWS CDK) 是一个软件开发框架,可帮助您在代码中定义并预置 Amazon Web Services Cloud 基础设施。
AWS 命令行界面(AWS CLI)是一种开源工具,它可帮助您通过命令行 Shell 中的命令与 Amazon Web Services 交互。
Amazon Data Firehose 可帮助您将实时流数据传输
到其他 AWS 服务、自定义 HTTP 终端节点以及受支持的第三方服务提供商拥有的 HTTP 终端节点。 Amazon Kinesis Data Streams 可帮助您实时收集和处理大型数据记录流。
AWS Lambda 是一项计算服务,可帮助您运行代码,而无需预置或管理服务器。它仅在需要时运行您的代码,并且能自动扩缩,因此您只需为使用的计算时间付费。
Amazon Personalize 是一项完全托管的机器学习(ML)服务,可帮助您根据数据为用户生成项目推荐。
AWS Step Functions 是一项无服务器编排服务,可帮助您搭配使用 Lambda 函数和其他 Amazon Web Services 来构建业务关键型应用程序。
其他工具
代码
此模式的代码可在 GitHub 动物推荐器
注意
Amazon Personalize 解决方案版本、事件跟踪器和活动由基于原生资源的自定义资源(在基础设施内) CloudFormation 提供支持。
操作说明
| Task | 描述 | 所需技能 |
|---|---|---|
创建一个隔离的 Python 环境。 | Mac/Linux 安装程序
Windows 设置 要手动创建虚拟环境,请从终端运行该 | DevOps 工程师 |
合成 CloudFormation 模板。 |
注意在步骤 2 中, | DevOps 工程师 |
部署资源并创建基础设施。 | 要部署解决方案资源,请从终端运行该 此命令安装所有必需的 Python 依赖项。Python 脚本创建 S3 存储桶和 AWS Key Management Service(AWS KMS)密钥,然后添加用于创建初始模型的种子数据。最后,该脚本运行 注意初始模型训练发生在堆栈创建期间。堆栈最长可能需要两个小时才能完成创建。 | DevOps 工程师 |
相关资源
动物推荐者
() GitHub 使用 Amazon Personalize 针对您选择的业务指标优化个性化推荐
(AWS 机器学习博客)
其他信息
有效负载和响应示例
推荐 Lambda 函数
要检索推荐,请使用以下格式的有效负载向推荐 Lambda 函数提交请求:
{ "userId": "3578196281679609099", "limit": 6 }
以下示例响应包含动物组列表:
[{"id": "1-domestic short hair-1-1"}, {"id": "1-domestic short hair-3-3"}, {"id": "1-domestic short hair-3-2"}, {"id": "1-domestic short hair-1-2"}, {"id": "1-domestic short hair-3-1"}, {"id": "2-beagle-3-3"},
如果省略该 userId 字段,则该函数将返回一般建议。
重新排名 Lambda 函数
要使用重新排名,请向重新排名 Lambda 函数提交请求。有效载荷包含所有 IDs 要重新排名的项目及其元数据。userId以下示例数据使用 Oxford Pets 类表示 animal_species_id(1=猫,2=狗),使用整数 1-5 表示 animal_age_id 和 animal_size_id:
{ "userId":"12345", "itemMetadataList":[ { "itemId":"1", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } }, { "itemId":"2", "animalMetadata":{ "animal_species_id":"1", "animal_primary_breed_id":"Egyptian_Mau", "animal_size_id":"1", "animal_age_id":"1" } }, { "itemId":"3", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } } ] }
Lambda 函数对这些商品进行重新排名,然后返回包含该商品和来自 Amazon Personalize 的直接回复的排序列表。 IDs 这是项目所属动物群及其分数的排名列表。Amazon Personalize 使用 User-Personalization 和 Personalized-Ranking 食谱,在推荐中包含每件项目的分数。这些分数表示 Amazon Personalize 对于用户接下来将选择哪个项目的相对确定性。分数越高,意味着确定性越大。
{ "ranking":[ "1", "3", "2" ], "personalizeResponse":{ "ResponseMetadata":{ "RequestId":"a2ec0417-9dcd-4986-8341-a3b3d26cd694", "HTTPStatusCode":200, "HTTPHeaders":{ "date":"Thu, 16 Jun 2022 22:23:33 GMT", "content-type":"application/json", "content-length":"243", "connection":"keep-alive", "x-amzn-requestid":"a2ec0417-9dcd-4986-8341-a3b3d26cd694" }, "RetryAttempts":0 }, "personalizedRanking":[ { "itemId":"2-Saint_Bernard-3-2", "score":0.8947961 }, { "itemId":"1-Siamese-1-1", "score":0.105204 } ], "recommendationId":"RID-d97c7a87-bd4e-47b5-a89b-ac1d19386aec" } }
Amazon Kinesis 有效负载
发送到 Amazon Kinesis 的有效负载采用以下格式:
{ "Partitionkey": "randomstring", "Data": { "userId": "12345", "sessionId": "sessionId4545454", "eventType": "DetailView", "animalMetadata": { "animal_species_id": "1", "animal_primary_breed_id": "Russian_Blue", "animal_size_id": "1", "animal_age_id": "2" }, "animal_id": "98765" } }
注意
对于未经身份验证的用户,该userId字段已被删除。
