本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
为通话后转录创建类别
通话后分析支持创建自定义类别,使您能够自定义转录分析,以便于极大程度地满足您的特定业务需求。
您可以根据需要创建任意数量的类别,以囊括一系列不同的场景。对于您创建的每个类别,必须创建 1 到 20 条规则。每条规则都基于以下四个标准之一:中断、关键字、非通话时间或情绪。有关在 CreateCallAnalyticsCategory 操作中使用这些条件的更多详细信息,请参阅通话后分析类别的规则标准一节。
如果您的媒体内容符合您在给定类别中指定的所有规则,则 Amazon Transcribe 会使用该类别标记您的输出。有关 JSON 输出中类别匹配的示例,请参阅呼叫分类输出。
以下是一些关于如何使用自定义类别的示例:
-
隔离具有特定特点的通话,例如以负面客户情绪结束的通话
-
通过标记和跟踪特定的一组关键字来识别客户问题的动态
-
监控合规性,例如座席在通话的最初几秒钟内说出(或省略)特定短语
-
通过标记多次出现座席中断和负面客户情绪的通话,深入了解客户体验
-
比较多个类别以衡量相关性,例如分析座席使用欢迎短语是否与积极的客户情绪相关
通话后类别与实时类别
创建新类别时,您可以指定是要将其创建为通话后分析类别 (POST_CALL),还是创建为实时呼叫分析类别 (REAL_TIME)。如果您没有指定选项,则默认情况下,您的类别将创建为通话后类别。通话后分析转录完成后,您的输出中就会显示通话后分析类别的匹配项。
要为通话后分析创建新类别,您可以使用AWS Management ConsoleAWS CLI、或 AWS SDKs;有关示例,请参阅以下内容:
-
在导航窗格的下方 Amazon Transcribe,选择Amazon Transcribe 呼叫分析。
-
选择呼叫分析类别,之后您将进入呼叫分析类别页面。选择创建类别。

-
您现在已进入创建类别页面。输入类别的名称,然后在类别类型下拉菜单中选择“批量呼叫分析”。
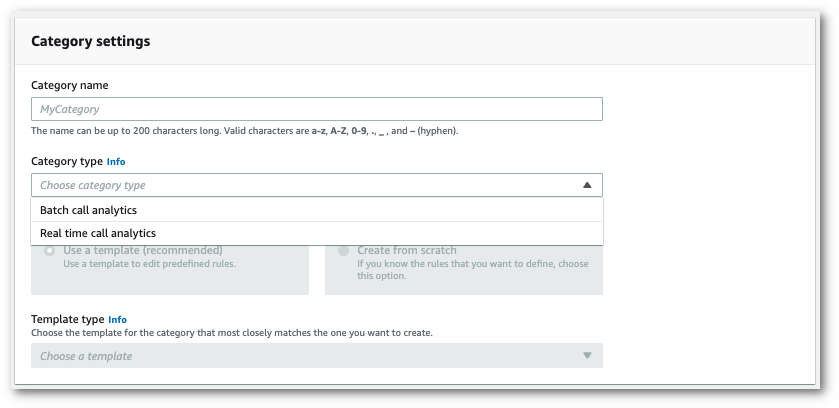
-
您可以选择一个模板来创建您的类别,也可以从头开始制作一个模板。
如果使用模板:选择使用模板(建议),选择所需的模板,然后选择创建类别。
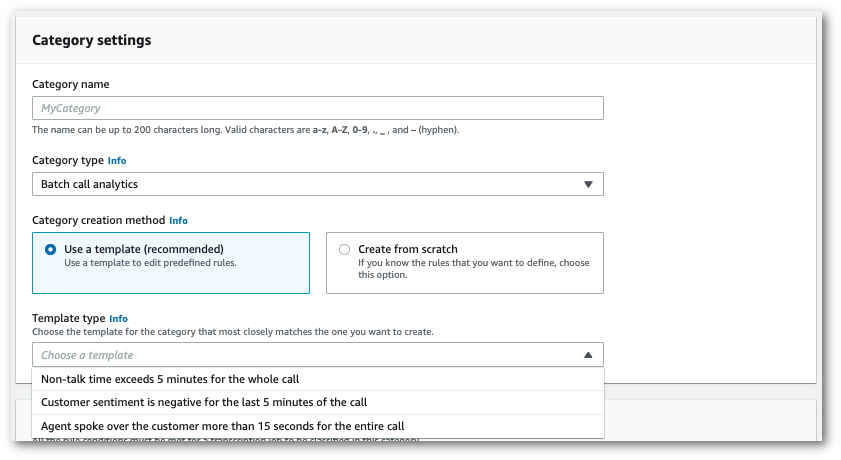
-
如果要创建自定义类别:请选择从头开始创建。
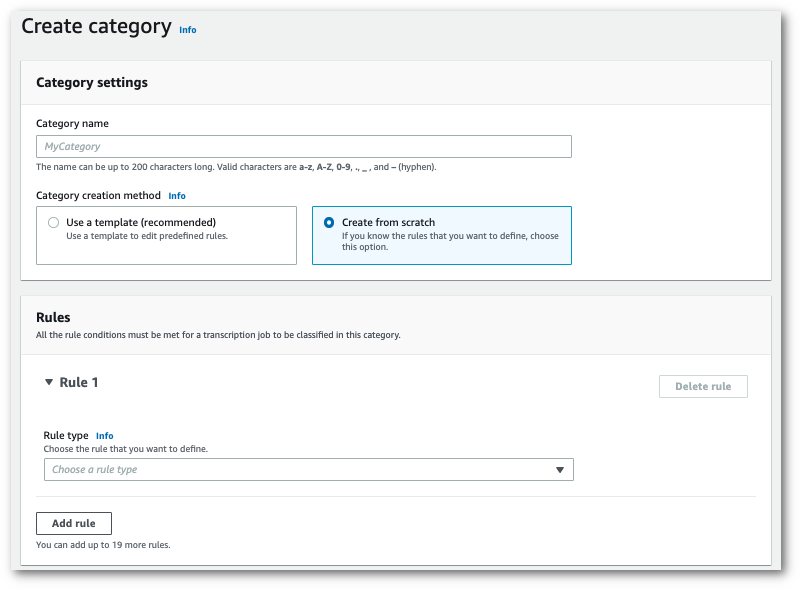
-
使用下拉菜单向您的类别添加规则。您最多可以为每个类别添加 20 条规则。
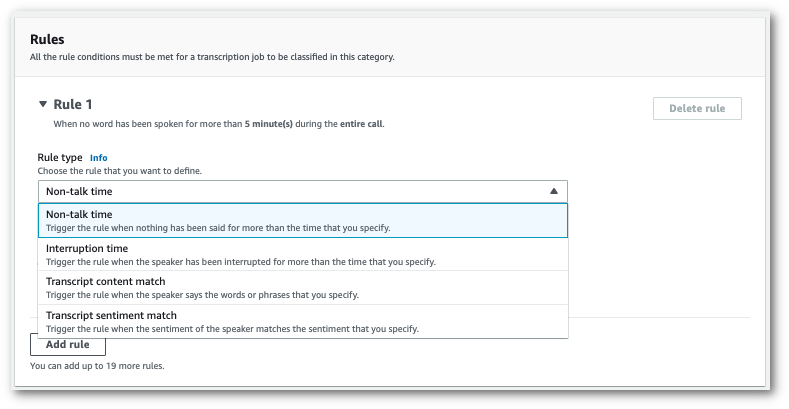
-
以下是包含两条规则的类别示例:座席在通话期间打断客户超过 15 秒,以及客户或座席在通话的最后两分钟内感受到负面情绪。
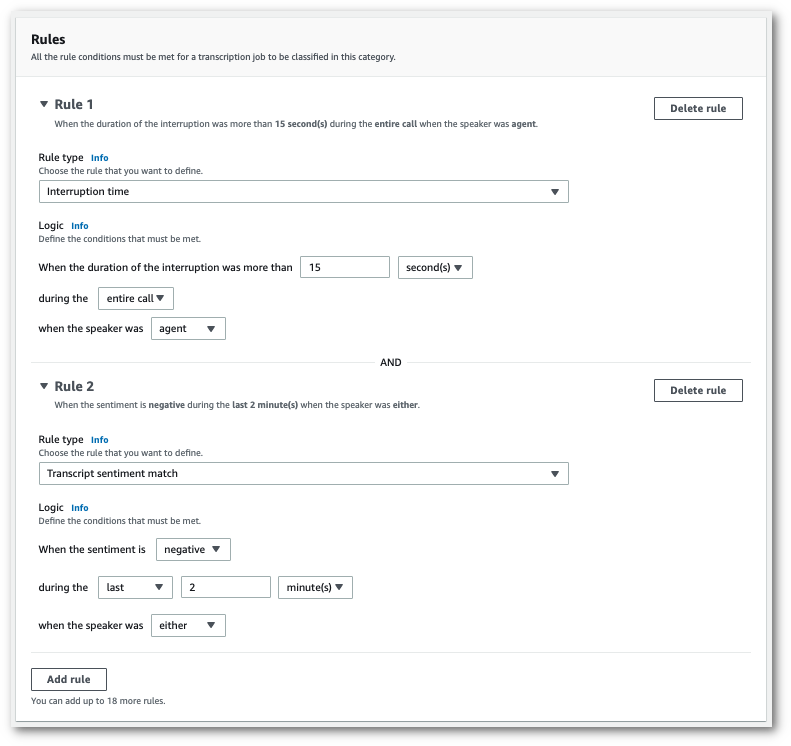
-
向类别添加完规则后,选择创建类别。
此示例使用create-call-analytics-categoryCreateCallAnalyticsCategory、CategoryProperties和Rule。
下面的示例创建了使用以下规则的类别:
-
客户在最初的 60000 毫秒被中断了。这些中断的持续时间至少持续了 10000 毫秒。
-
有一段沉默时间至少持续了 20000 毫秒,通话进行 10% 到通话进行 80% 之间。
-
该座席在通话中的某个时刻有负面情绪。
-
在通话的前 10000 毫秒内没有使用“欢迎”或“您好”这两个词。
此示例使用create-call-analytics-category
aws transcribe create-call-analytics-category \ --cli-input-json file://filepath/my-first-analytics-category.json
my-first-analytics-category.json 文件包含以下请求正文。
{ "CategoryName": "my-new-category", "InputType": "POST_CALL", "Rules": [ { "InterruptionFilter": { "AbsoluteTimeRange": { "First":60000}, "Negate":false, "ParticipantRole": "CUSTOMER", "Threshold":10000} }, { "NonTalkTimeFilter": { "Negate":false, "RelativeTimeRange": { "EndPercentage":80, "StartPercentage":10}, "Threshold":20000} }, { "SentimentFilter": { "ParticipantRole": "AGENT", "Sentiments": [ "NEGATIVE" ] } }, { "TranscriptFilter": { "Negate":true, "AbsoluteTimeRange": { "First":10000}, "Targets": [ "welcome", "hello" ], "TranscriptFilterType": "EXACT" } } ] }
此示例使用 create_call_an alytics_category 方法的CategoryName和Rules参数创建CreateCallAnalyticsCategory、CategoryProperties和Rule。
有关使用的其他示例 AWS SDKs,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
下面的示例创建了使用以下规则的类别:
-
客户在最初的 60000 毫秒被中断了。这些中断的持续时间至少持续了 10000 毫秒。
-
有一段沉默时间至少持续了 20000 毫秒,通话进行 10% 到通话进行 80% 之间。
-
该座席在通话中的某个时刻有负面情绪。
-
在通话的前 10000 毫秒内没有使用“欢迎”或“您好”这两个词。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') category_name = "my-new-category" transcribe.create_call_analytics_category( CategoryName = category_name, InputType =POST_CALL, Rules = [ { 'InterruptionFilter': { 'AbsoluteTimeRange': { 'First':60000}, 'Negate':False, 'ParticipantRole': 'CUSTOMER', 'Threshold':10000} }, { 'NonTalkTimeFilter': { 'Negate':False, 'RelativeTimeRange': { 'EndPercentage':80, 'StartPercentage':10}, 'Threshold':20000} }, { 'SentimentFilter': { 'ParticipantRole': 'AGENT', 'Sentiments': [ 'NEGATIVE' ] } }, { 'TranscriptFilter': { 'Negate':True, 'AbsoluteTimeRange': { 'First':10000}, 'Targets': [ 'welcome', 'hello' ], 'TranscriptFilterType': 'EXACT' } } ] ) result = transcribe.get_call_analytics_category(CategoryName = category_name) print(result)
通话后分析类别的规则标准
本节概述了您可以使用 CreateCallAnalyticsCategory API 操作创建的自定义 POST_CALL 规则的类型。
中断匹配
使用中断(InterruptionFilter 数据类型)的规则旨在匹配:
-
座席打断客户的情况
-
客户打断座席的情况
-
任何参与者打断对方的情况
-
没有中断
以下是 InterruptionFilter 可用参数的示例:
"InterruptionFilter": { "AbsoluteTimeRange": {Specify the time frame, in milliseconds, when the match should occur}, "RelativeTimeRange": {Specify the time frame, in percentage, when the match should occur}, "Negate":Specify if you want to match the presence or absence of interruptions, "ParticipantRole":Specify if you want to match speech from the agent, the customer, or both, "Threshold":Specify a threshold for the amount of time, in seconds, interruptions occurred during the call},
有关这些参数以及与每个参数关联的有效值的更多信息,请参阅 CreateCallAnalyticsCategory 和 InterruptionFilter。
关键字匹配
使用关键字(TranscriptFilter 数据类型)的规则旨在匹配:
-
座席、客户或两者都说了的自定义单词或短语
-
座席、客户或两者都没说的自定义单词或短语
-
在特定时间范围内出现的自定义单词或短语
以下是 TranscriptFilter 可用参数的示例:
"TranscriptFilter": { "AbsoluteTimeRange": {Specify the time frame, in milliseconds, when the match should occur}, "RelativeTimeRange": {Specify the time frame, in percentage, when the match should occur}, "Negate":Specify if you want to match the presence or absence of your custom keywords, "ParticipantRole":Specify if you want to match speech from the agent, the customer, or both, "Targets": [The custom words and phrases you want to match], "TranscriptFilterType":Use this parameter to specify an exact match for the specified targets}
有关这些参数以及与每个参数关联的有效值的更多信息,请参阅 CreateCallAnalyticsCategory 和 TranscriptFilter。
非通话时间匹配
使用非通话时间(NonTalkTimeFilter 数据类型)的规则旨在匹配:
-
在整个通话过程中,在指定时段存在沉默的情况
-
在整个通话过程中,在指定时段有语音的情况
以下是 NonTalkTimeFilter 可用参数的示例:
"NonTalkTimeFilter": { "AbsoluteTimeRange": {Specify the time frame, in milliseconds, when the match should occur}, "RelativeTimeRange": {Specify the time frame, in percentage, when the match should occur}, "Negate":Specify if you want to match the presence or absence of speech, "Threshold":Specify a threshold for the amount of time, in seconds, silence (or speech) occurred during the call},
有关这些参数以及与每个参数关联的有效值的更多信息,请参阅 CreateCallAnalyticsCategory 和 NonTalkTimeFilter。
情绪匹配
使用情绪(SentimentFilter 数据类型)的规则旨在匹配:
-
客户、座席或两者在通话的指定时刻是否存在正面情绪的情况
-
客户、座席或两者在通话中的指定时刻是否存在负面情绪的情况
-
客户、座席或两者在通话的指定时刻是否存在中性情绪的情况
-
客户、座席或两者在通话的指定时刻是否正负面情绪兼有的情况
以下是 SentimentFilter 可用参数的示例:
"SentimentFilter": { "AbsoluteTimeRange": {Specify the time frame, in milliseconds, when the match should occur}, "RelativeTimeRange": {Specify the time frame, in percentage, when the match should occur}, "Negate":Specify if you want to match the presence or absence of your chosen sentiment, "ParticipantRole":Specify if you want to match speech from the agent, the customer, or both, "Sentiments": [The sentiments you want to match] },
有关这些参数以及与每个参数关联的有效值的更多信息,请参阅 CreateCallAnalyticsCategory 和 SentimentFilter。
