场景 4:设备传感器实时异常检测和通知
ABC4Logistics 公司将汽油、液态丙烷 (LPG) 和石脑油等高度易燃的石油产品从港口运输到各个城市。数百辆车上安装了多个传感器,用于监控位置、发动机温度、集装箱内的温度、行驶速度、停车位置、路况等情况。ABC4Logistics 的其中一项要求是实时监控发动机和集装箱的温度,并在出现任何异常情况时提示驾驶员和车队监控团队。为了实时检测此类情况并生成提示,ABC4Logistics 在 AWS 上实施了以下架构。
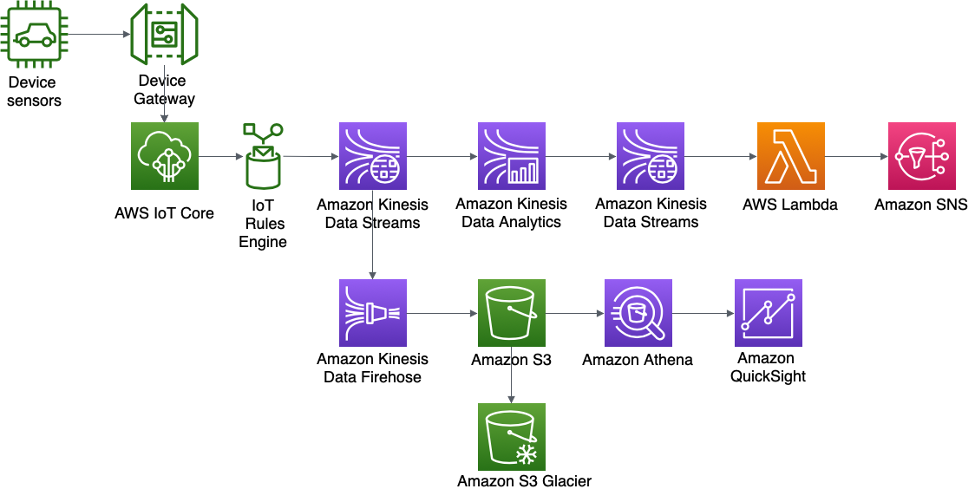
ABC4Logistics 的设备传感器实时异常检测和通知架构
来自设备传感器的数据由 AWS IoT Gateway 摄取,其中,AWS IoT 规则引擎将在 Amazon Kinesis Data Streams 中提供流数据。使用 Kinesis Data Analytics,ABC4Logistics 可以对 Kinesis Data Streams 中的流数据执行实时分析。
使用 Kinesis Data Analytics,ABC4Logistics 可以检测来自传感器的温度读数是否在十秒期间内偏离了正常读数,并将记录摄取到另一个 Kinesis Data Streams 实例中,从而识别异常记录。然后,Amazon Kinesis Data Streams 会调用 Lambda 函数,这些函数可以通过 Amazon SNS 向驾驶员和车队监控团队发送提示。
Kinesis Data Streams 中的数据也会向下推送到 Amazon Kinesis Data Firehose 中。Amazon Kinesis Data Firehose 将这些数据保留在 Amazon S3 中,从而允许 ABC4Logistics 对传感器数据执行批处理分析或近实时分析。ABC4Logistics 使用 Amazon Athena
接下来将详细介绍此架构的重要组成部分。
Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics
借助 Amazon Kinesis Data Analytics,您可以使用多个选项(包括标准 SQL 以及 Java、Python 和 Scala 中的 Apache Flink 应用程序)以交互方式查询流数据,还可以使用 Java 构建 Apache Beam 应用程序来分析数据流。
这些选项使您可以灵活地使用特定方法,具体取决于流式处理应用程序和源/目标支持的复杂程度。以下部分将讨论适用于 Flink 应用程序的 Kinesis Data Analytics 选项。
适用于 Apache Flink 应用程序的 Amazon Kinesis Data Analytics
Apache Flink
借助 Amazon Kinesis Data Analytics for Apache Flink,您可以在不管理复杂的分布式 Apache Flink 环境的情况下,针对流源编写和运行代码,以执行时间序列分析、向实时控制面板提供数据以及创建实时指标。您可以使用高级 Flink 编程功能,使用方式与自行托管 Flink 基础设施时一样。
借助 Kinesis Data Analytics for Apache Flink,您可以在 Java、Scala、Python 或 SQL 中创建应用程序来处理和分析流数据。典型的 Flink 应用程序从输入流或数据位置或源 读取数据,使用运算符或函数转换/筛选或联接数据,然后将数据存储在输出流或数据位置或接收器 上。
下面的架构图显示了 Kinesis Data Analytics Flink 应用程序支持的一些源和接收器。除了用于源/接收器的预先捆绑的连接器之外,还可以为 Kinesis Data Analytics 上的 Flink 应用程序的各种其他源/接收器引入自定义的连接器。
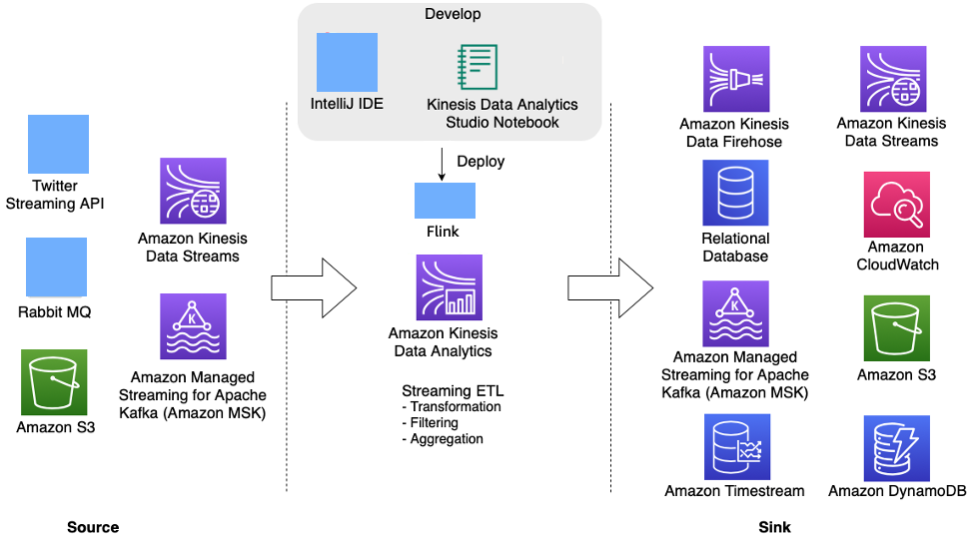
Kinesis Data Analytics 上用于实时流式处理的 Apache Flink 应用程序
开发人员可以使用他们首选的 IDE 来开发 Flink 应用程序,并通过 AWS Management Console
Amazon Kinesis Data Analytics Studio
作为 Kinesis Data Analytics 服务的一部分,Kinesis Data Analytics Studio
使用 Studio 笔记本,您可以在笔记本环境中开发 Flink 应用程序代码,实时查看代码的结果,并在笔记本中将其可视化。只需在 Kinesis Data Streams 和 Amazon MSK 控制台中单击一下,即可创建由 Apache Zeppelin 和 Apache Flink 提供支持的 Studio 笔记本,也可以从 Kinesis Data Analytics 控制台启动它。
将代码作为 Kinesis Data Analytics Studio 的一部分迭代进行开发后,您可以将笔记本部署为 Kinesis 数据分析应用程序,以便在流模式下持续运行,同时从源读取数据、写入目标位置、维护长时间运行的应用程序状态以及基于源流的吞吐量自动扩缩。早些时候,客户已使用适用于 SQL 应用程序的 Kinesis Data Analytics 对 AWS 上的实时流式处理数据进行此类交互式分析。
适用于 SQL 应用程序的 Kinesis Data Analytics 仍然可用,但对于新项目,AWS 建议您使用新的 Kinesis Data Analytics Studio
为了使 Kinesis Data Analytics Flink 应用程序具有容错性,您可以利用检查点操作和快照,如在 Kinesis Data Analytics for Apache Flink 中实施容错能力中所述。
Kinesis Data Analytics Flink 应用程序对于编写复杂的流式分析应用程序(例如数据处理精确一次 (exactly-once) 语义
在 Flink 应用程序中处理流数据后,您可以将数据保存到各种接收器或目标位置,例如 Amazon Kinesis Data Streams、Amazon Kinesis Data Firehose、Amazon DynamoDB、Amazon OpenSearch Service、Amazon Timestream、Amazon S3 等。此外,Kinesis Data Analytics Flink 应用程序还提供亚秒级性能保证。
适用于 Kinesis Data Analytics 的 Apache Beam 应用程序
Apache Beam
您可以将 Apache Beam 框架与 Kinesis 数据分析应用程序结合使用,以处理流数据。使用 Apache Beam 的 Kinesis 数据分析应用程序使用 Apache Flink 运行器
总结
通过利用 AWS 流式处理服务 Amazon Kinesis Data Streams 、Amazon Kinesis Data Analytics 和 Amazon Kinesis Data Firehose,
ABC4Logistics 可以检测温度读数中的异常模式,并实时通知驾驶员和车队管理团队,防止发生如整车故障或火灾等重大事故。
