支援終止通知:2025 年 10 月 31 日, AWS 將停止對 Amazon Lookout for Vision 的支援。2025 年 10 月 31 日之後,您將無法再存取 Lookout for Vision 主控台或 Lookout for Vision 資源。如需詳細資訊,請造訪此部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Lookout for Vision 入門
在開始這些入門指示之前,我們建議您閱讀 了解 Amazon Lookout for Vision。
入門說明說明如何使用建立範例影像分割模型。如果您想要建立範例影像分類模型,請參閱 影像分類資料集。
如果您想要快速嘗試範例模型,我們會提供範例訓練影像和遮罩影像。我們也提供 Python 指令碼,可建立影像分割資訊清單檔案。您可以使用資訊清單檔案來建立專案的資料集,而且不需要在資料集中標記影像。當您使用自己的映像建立模型時,您必須在資料集中標記映像。如需詳細資訊,請參閱建立資料集。
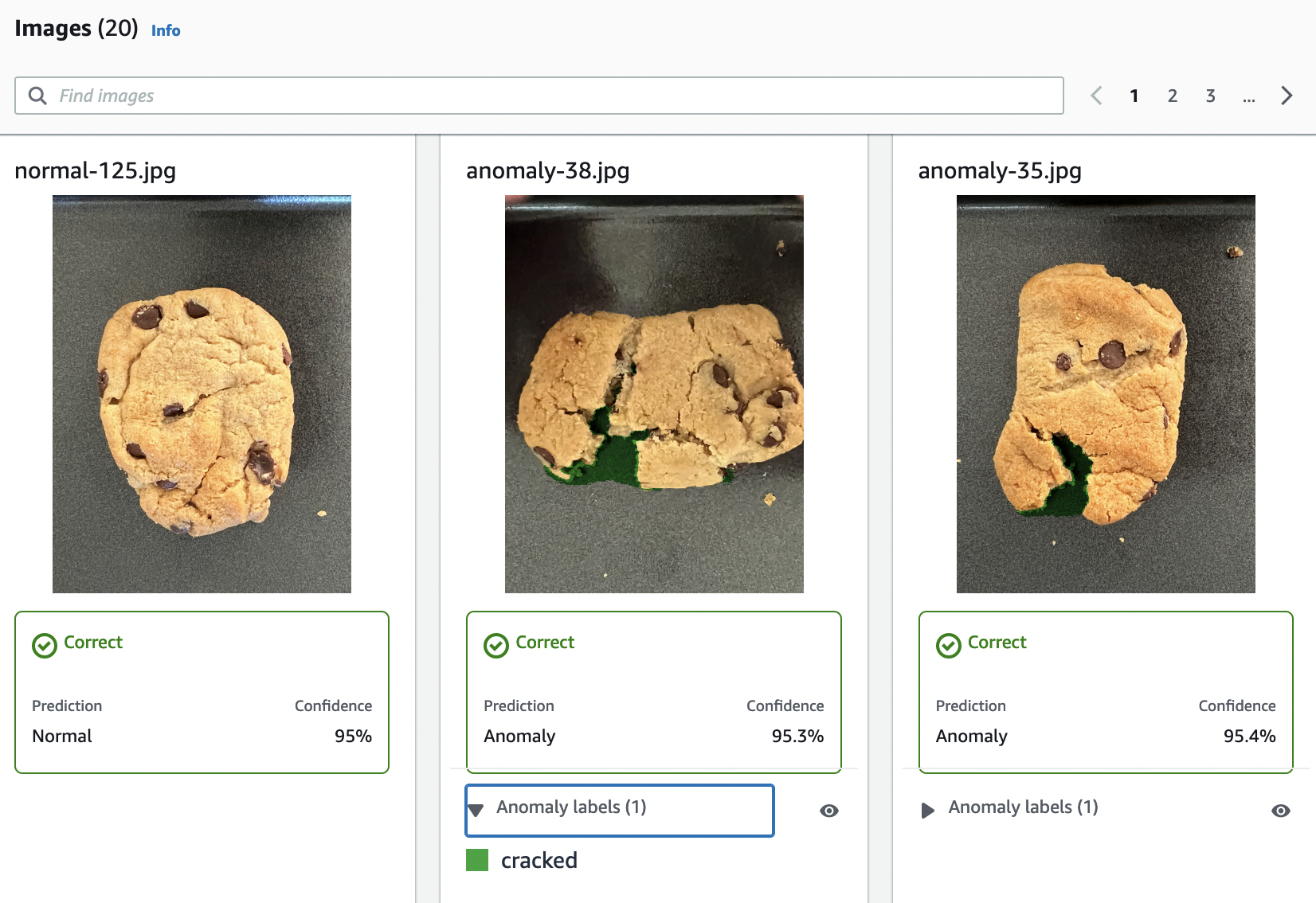
我們提供的影像是正常和異常 Cookie。異常 Cookie 跨 Cookie 形狀出現裂痕。您使用影像訓練的模型會預測分類 (正常或異常),並在異常 Cookie 中尋找裂痕區域 (遮罩),如下列範例所示。

步驟 1:建立資訊清單檔案並上傳映像
在此程序中,您將 Amazon Lookout for Vision 文件儲存庫複製到您的電腦。然後,您可以使用 Python (3.7 版或更新版本) 指令碼來建立資訊清單檔案,並將訓練映像和遮罩映像上傳到您指定的 Amazon S3 位置。您可以使用資訊清單檔案來建立模型。稍後,您會在本機儲存庫中使用測試映像來嘗試模型。
建立資訊清單檔案並上傳映像
遵循設定 Amazon Lookout for Vision 中的指示來設定 Amazon Lookout for Vision。請務必安裝AWS 適用於 Python 的 SDK
。 在您要使用 Lookout for Vision 的 AWS 區域中,建立 S3 儲存貯體。
在 Amazon S3 儲存貯體中,建立名為 的資料夾
getting-started。請注意資料夾的 Amazon S3 URI 和 Amazon Resource name (ARN)。您可以使用它們來設定許可和執行指令碼。
確定呼叫指令碼的使用者具有呼叫
s3:PutObject操作的許可。您可以使用以下政策。如要指派權限,請參閱 指派權限。{ "Version": "2012-10-17", "Statement": [{ "Sid": "Statement1", "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3::: ARN for S3 folder in step 4/*" ] }] }-
請確定您擁有名為 的本機設定檔,
lookoutvision-access且設定檔使用者具有上一個步驟的許可。如需詳細資訊,請參閱在本機電腦上使用設定檔。 -
下載 zip 檔案,get-started.zip。zip 檔案包含入門資料集和設定指令碼。
解壓縮
getting-started.zip檔案。在命令提示字元中,執行下列動作:
導覽至
getting-started資料夾。-
執行下列命令來建立資訊清單檔案,並將訓練映像和映像遮罩上傳到您在步驟 4 中記下的 Amazon S3 路徑。
python getting_started.pyS3-URI-from-step-4 當指令碼完成時,請注意指令碼在 之後顯示
train.manifest的檔案路徑Create dataset using manifest file:。路徑應類似於s3://。path to getting started folder/manifests/train.manifest
步驟 2:建立模型
在此程序中,您會使用先前上傳至 Amazon S3 儲存貯體的影像和資訊清單檔案來建立專案和資料集。然後,您可以建立模型並檢視模型訓練的評估結果。
由於您從入門資訊清單檔案建立資料集,因此您不需要標記資料集的影像。當您使用自己的映像建立資料集時,您需要標記映像。如需詳細資訊,請參閱標記檔案。
重要
您需要為模型的成功訓練付費。
建立裝置
-
開啟 Amazon Lookout for Vision 主控台,網址為 https://https://console.aws.amazon.com/lookoutvision/
。 請確定您位於您在 中建立 Amazon S3 儲存貯體的相同 AWS 區域步驟 1:建立資訊清單檔案並上傳映像。若要變更區域,請在導覽列中選擇目前顯示區域的名稱。然後選擇您要切換的區域。
-
選擇開始使用。

在專案區段中,選擇建立專案。
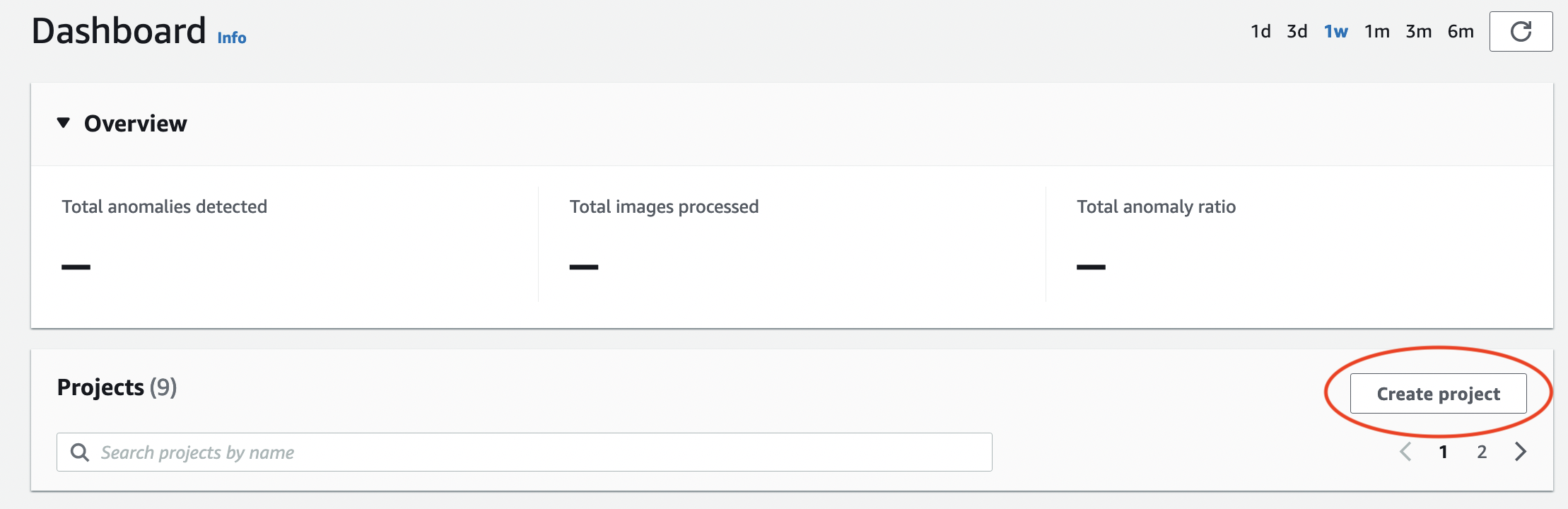
-
在建立專案頁面上,執行下列動作:
-
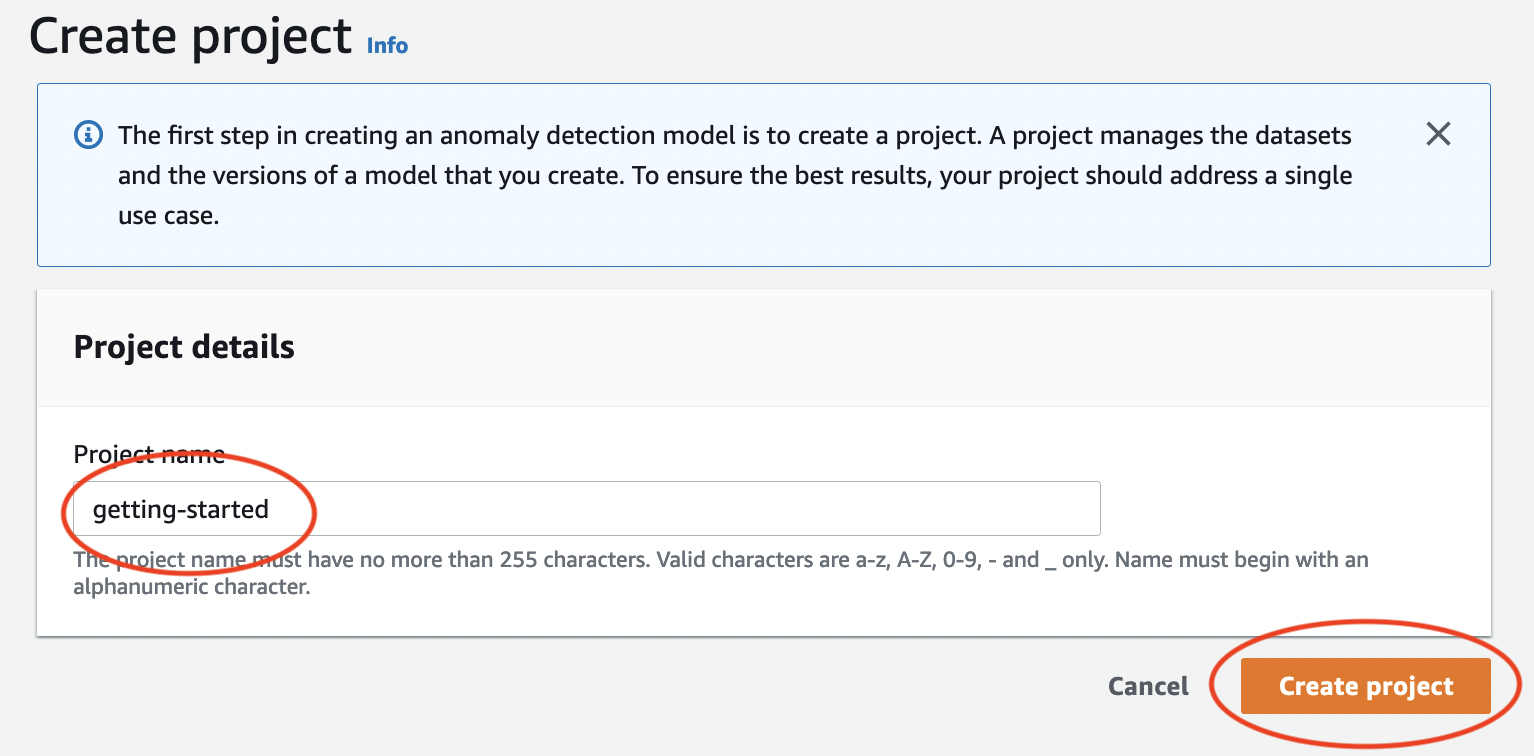
在專案名稱中,輸入
getting-started。 -
選擇建立專案。
-
-
在專案頁面上的 運作方式 區段中,選擇建立資料集。
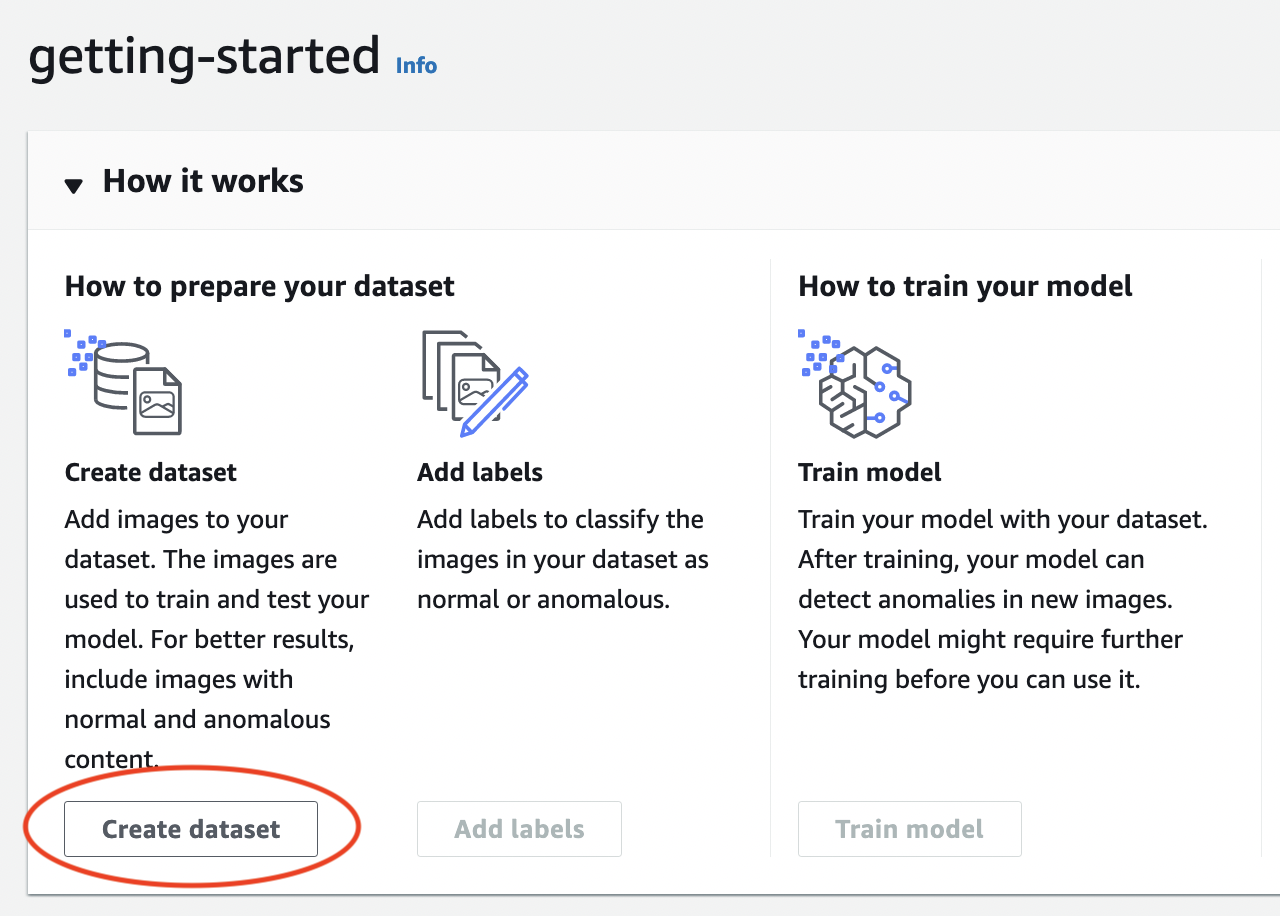
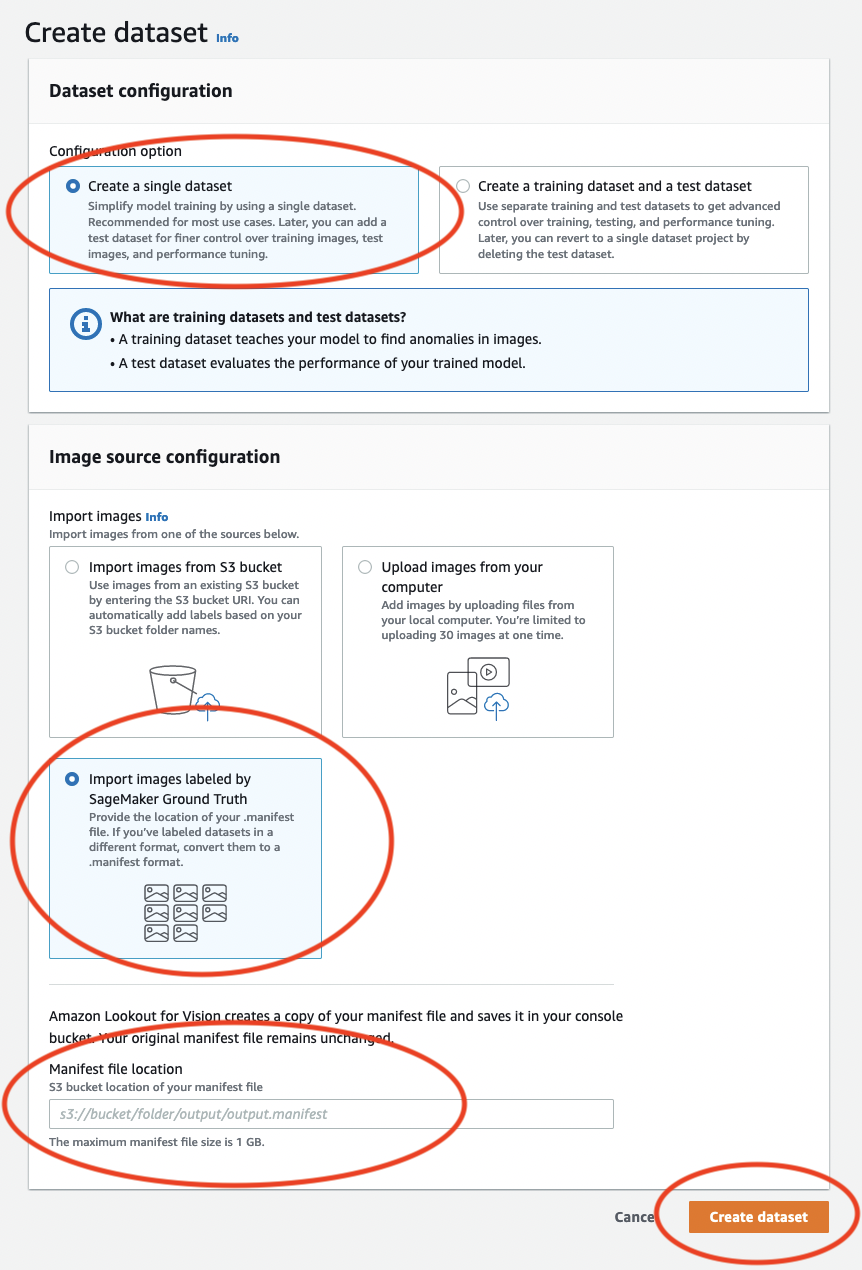
在建立資料集頁面上,執行下列動作:
-
選擇建立單一資料集。
-
在映像來源組態區段中,選擇匯入由 SageMaker Ground Truth 標記的映像。
-
針對 .manifest 檔案位置,輸入您在 的步驟 6.c. 中記下的資訊清單檔案的 Amazon S3 位置。 步驟 1:建立資訊清單檔案並上傳映像Amazon S3 位置應類似於
s3://path to getting started folder/manifests/train.manifest -
選擇建立資料集。
-
-
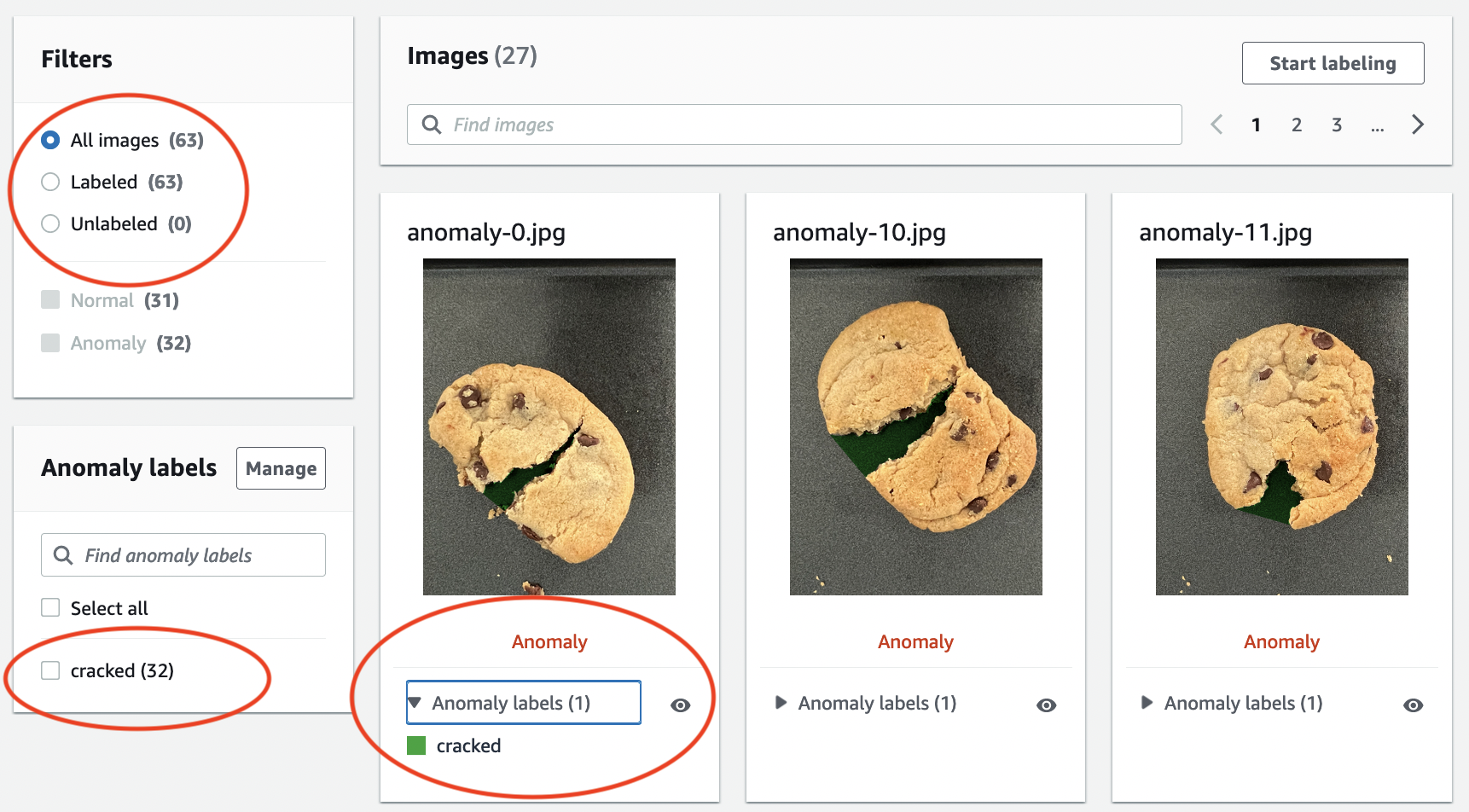
在專案詳細資訊頁面上的影像區段中,檢視資料集影像。您可以檢視每個資料集影像的分類和影像分割資訊 (遮罩和異常標籤)。您也可以搜尋影像、依標籤狀態 (已標記/未標記) 篩選影像,或依指派給影像的異常標籤篩選影像。
-
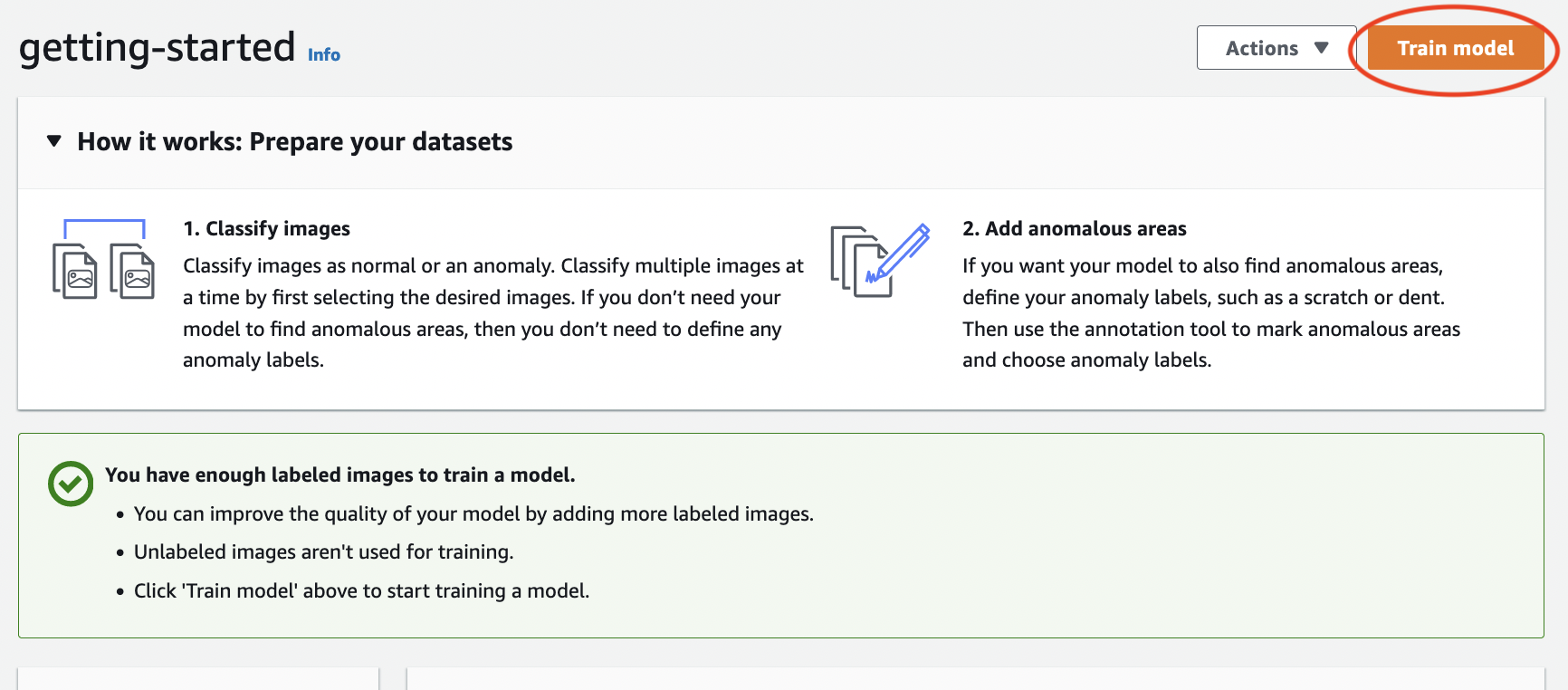
在專案詳細資訊頁面上,選擇訓練模型。
-
在訓練模型詳細資訊頁面上,選擇訓練模型。
-
在您是否要訓練模型?的對話框中,選擇訓練模型。
-
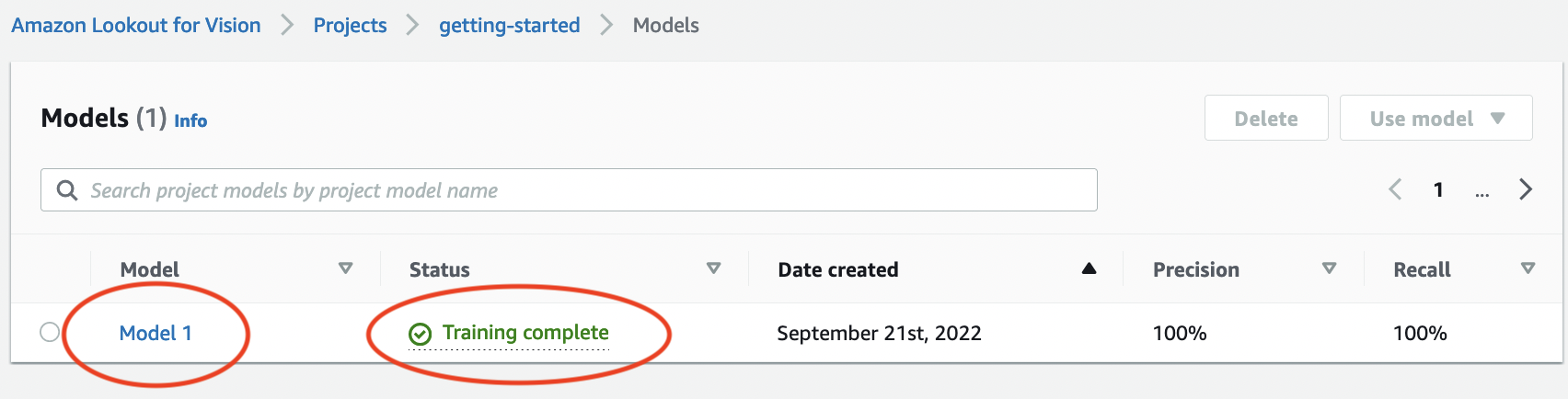
在專案模型頁面中,您可以看到訓練已開始。檢視模型版本的狀態欄,以檢查目前狀態。模型完成訓練至少需要 30 分鐘。當狀態變更為訓練完成時,訓練已成功完成。
-
訓練完成後,請在模型頁面中選擇模型模型 1。
-
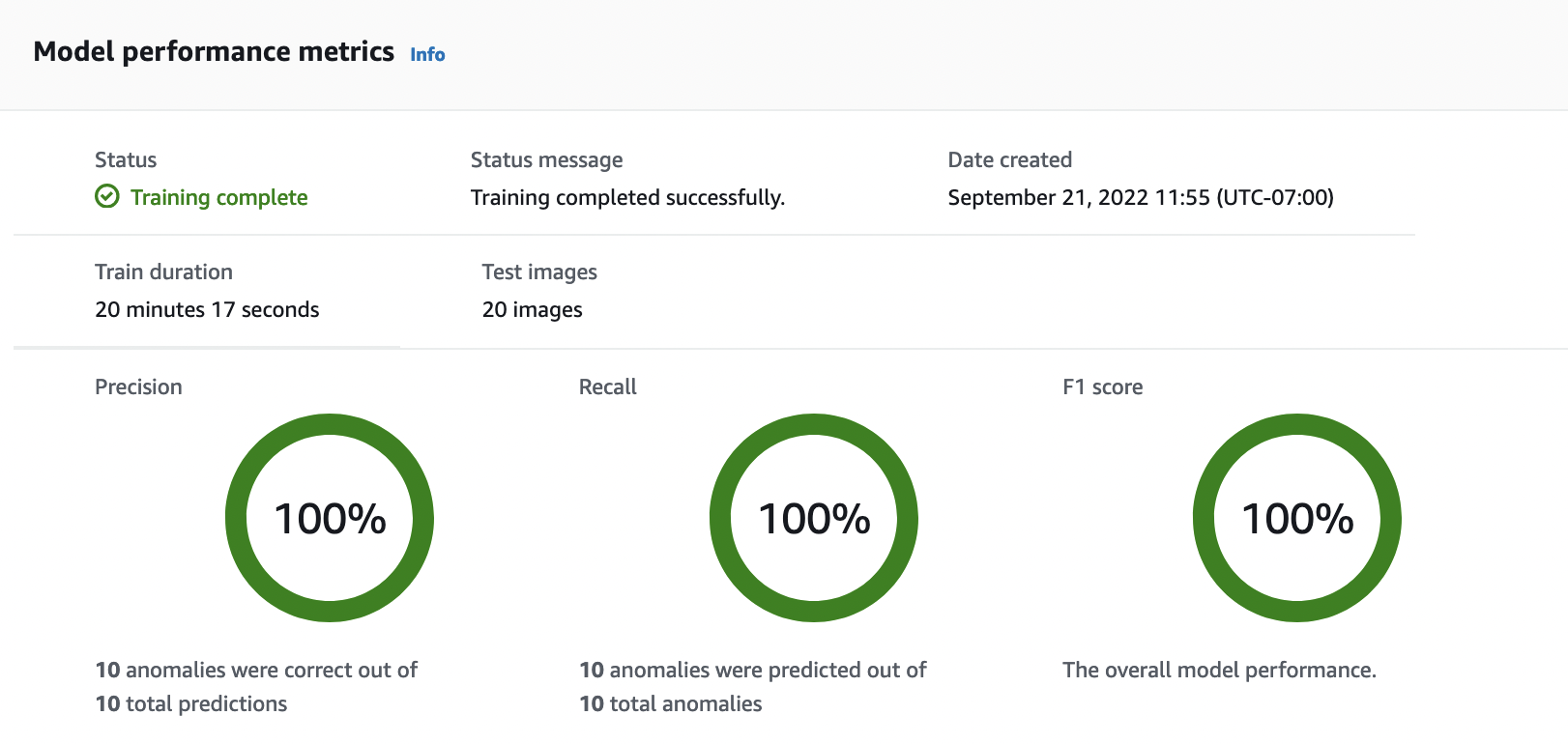
在模型的詳細資訊頁面中,在效能指標索引標籤中檢視評估結果。有下列指標:
由於模型訓練是非確定性的,您的評估結果可能與此頁面顯示的結果不同。如需詳細資訊,請參閱改善您的 Amazon Lookout for Vision 模型。

步驟 3:啟動模型
在此步驟中,您會開始託管模型,以便準備好分析映像。如需詳細資訊,請參閱執行訓練過的 Amazon Lookout for Vision 模型。
注意
您需要根據模型執行時間付費。您可以在 中停止模型步驟 5:停止模型。
啟動模型。
在模型的詳細資訊頁面上,選擇使用模型,然後選擇將 API 整合到雲端。

在AWS CLI 命令區段中,複製
start-modelAWS CLI 命令。
-
請確定 AWS CLI 已設定為在您使用 Amazon Lookout for Vision 主控台的相同 AWS 區域中執行。若要變更 AWS CLI 使用的 AWS 區域,請參閱 安裝 AWS SDKS。
-
在命令提示字元中,輸入
start-model命令來啟動模型。如果您使用lookoutvision設定檔來取得登入資料,請新增--profile lookoutvision-access參數。例如:aws lookoutvision start-model \ --project-name getting-started \ --model-version 1 \ --min-inference-units 1 \ --profile lookoutvision-access如果呼叫成功,會顯示下列輸出:
{ "Status": "STARTING_HOSTING" } 返回主控台,在導覽窗格中選擇模型。

等待狀態欄中的模型狀態 (模型 1) 顯示託管。如果您先前已在專案中訓練模型,請等待最新的模型版本完成。

步驟 4:分析映像
在此步驟中,您會使用模型分析映像。我們提供範例映像,您可以在電腦上 Lookout for Vision 文件儲存庫的入門test-images資料夾中使用。如需詳細資訊,請參閱偵測映像中的異常。
分析映像
-
在模型頁面上,選擇模型模型 1。
-
在模型的詳細資訊頁面上,選擇使用模型,然後選擇將 API 整合到雲端。
-
在AWS CLI 命令區段中,複製
detect-anomaliesAWS CLI 命令。
-
在命令提示中,輸入上一個步驟的
detect-anomalies命令來分析異常映像。針對--body參數,從電腦上的入門test-images資料夾指定異常映像。如果您使用lookoutvision設定檔來取得登入資料,請新增--profile lookoutvision-access參數。例如:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-anomaly-1.jpg\ --profile lookoutvision-access輸出格式應類似以下內容:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": true, "Confidence": 0.983975887298584, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 0.9818974137306213, "Color": "#FFFFFF" } }, { "Name": "cracked", "PixelAnomaly": { "TotalPercentageArea": 0.018102575093507767, "Color": "#23A436" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAAMACA......" } } -
在輸出中,請注意下列事項:
-
IsAnomalous是預測分類的布林值。true如果映像異常,否則false。 -
Confidence是浮點數,代表 Amazon Lookout for Vision 在預測中的可信度。0 是最低的可信度,1 是最高可信度。 -
Anomalies是影像中找到的異常清單。Name是異常標籤。PixelAnomaly包含異常標籤的總百分比區域 (TotalPercentageArea) 和異常標籤的顏色 (Color)。該清單也包含「背景」異常,涵蓋影像上異常以外的區域。 -
AnomalyMask是一種遮罩影像,可顯示分析影像上異常的位置。
您可以在回應中使用資訊來顯示分析影像和異常遮罩的混合,如下列範例所示。如需範例程式碼,請參閱 顯示分類和分割資訊。

-
-
在命令提示中,分析入門
test-images資料夾中的正常映像。如果您使用lookoutvision設定檔來取得登入資料,請新增--profile lookoutvision-access參數。例如:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-normal-1.jpg\ --profile lookoutvision-access輸出格式應類似以下內容:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": false, "Confidence": 0.9916400909423828, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 1.0, "Color": "#FFFFFF" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAA....." } } -
在輸出中,請注意
false的值會將映像IsAnomalous分類為沒有異常。使用Confidence來協助判斷您對分類的信心。此外,Anomalies陣列只有background異常標籤。
步驟 5:停止模型
在此步驟中,您會停止託管模型。您需要根據模型執行時間付費。如果您未使用模型,您應該停止它。您可以在下次需要時重新啟動模型。如需詳細資訊,請參閱啟動 Amazon Lookout for Vision 模型。
停止模型。
-
在導覽窗格中選擇模型。
在模型頁面中,選擇模型模型 1。
在模型的詳細資訊頁面上,選擇使用模型,然後選擇將 API 整合到雲端。
在AWS CLI 命令區段中,複製
stop-modelAWS CLI 命令。
-
在命令提示中,輸入上一個步驟的
stop-modelAWS CLI 命令來停止模型。如果您使用lookoutvision設定檔來取得登入資料,請新增--profile lookoutvision-access參數。例如:aws lookoutvision stop-model \ --project-name getting-started \ --model-version 1 \ --profile lookoutvision-access如果呼叫成功,會顯示下列輸出:
{ "Status": "STOPPING_HOSTING" } 返回主控台,在左側導覽頁面中選擇模型。
當狀態欄中的模型狀態為訓練完成時,模型已停止。
後續步驟
當您準備好使用自己的映像建立模型時,請先遵循 中的指示建立您的專案。這些指示包括使用 Amazon Lookout for Vision 主控台和 AWS SDK 建立模型的步驟。
如果您想要嘗試其他範例資料集,請參閱 程式碼和資料集範例。
