本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
新產品需求預測的最佳實務
本節討論下列針對新產品需求預測的最佳實務:
符合資料驅動NPI需求預測的資料準備度需求
若要採用以資料為導向的方法進行NPI需求預測,您的組織應取得所有相關利益相關者的支援,例如資料科學或分析部門、供應鏈、行銷和 IT 的經理。您的組織接著應識別下列項目:
-
現有內部資料的來源和相關的外部資料
-
這些資料來源的擁有者
-
將資料來源用於 計畫所需的程序和許可
您可以針對以下類型的必要和選用資料集評估資料準備程度。盡可能使用包括選用類型的資料集,有助於機器學習模型產生更準確的NPI需求預測。
以下是必要內部資料來源的範例:
-
所有產品或產品子集的完整銷售歷史記錄 (從產品啟動到終止),其屬性與要啟動的新產品相似。銷售歷史記錄可以來自多個銷售管道,也可以跨所有管道組合。
-
產品屬性映射,以識別與所啟動新產品具有類似屬性的產品子集。
以下是選用內部資料來源的範例:
-
追蹤類似產品的促銷和折扣的行銷資料。此資料應該等於或大於銷售歷史記錄的長度。
-
產品評論、評分和 Web 流量資料。此資料應該等於或大於銷售歷史記錄的長度。
-
消費者人口統計資料
以下是可補充內部資料的選用外部資料來源範例:
-
消費者索引資料
-
競爭者銷售資料
-
調查資料
建置具成本效益的資料擷取機制
滿足資料準備需求後,您的組織可以選擇最適合的資料擷取和資料儲存機制。如果您組織的主要銷售資料來源是每天從不同的管道收集,請考慮批次資料擷取。如果您想要自助服務預測受益於擁有最新的資料,串流資料擷取是另一個選項。
原始資料擷取管道應使用擷取、轉換和載入 (ETL) 管道進行輕量轉換。管道應執行資料品質檢查,並將處理過的資料存放在資料庫中,以供下游使用。
您可以使用 AWS Glue、AWS Glue Data Catalog、Amazon Data Firehose 和 Amazon Simple Storage Service (Amazon S3) AWS 服務等 進行經濟實惠的資料擷取和儲存。 AWS Glue是一種全受管無伺服器ETL服務,可協助您分類、清理、轉換和可靠地在不同資料存放區之間傳輸資料。的核心元件 AWS Glue 包含稱為 的中央中繼資料儲存庫 AWS Glue Data Catalog,以及自動產生 Python 和 Scala 程式碼和管理ETL任務的任務ETL系統。Amazon Data Firehose 可協助您收集、處理和分析任何規模的即時串流資料。Firehose 可以直接將即時串流資料交付至資料湖 (例如 Amazon S3)、資料存放區和分析服務,以進行進一步處理。Amazon S3 是一種物件儲存服務,可提供可擴展性、資料可用性、安全性和效能。
判斷預測NPI需求的可行 ML 方法
根據特定的使用案例,您的組織可以考慮不同的預測選項。
統計預測方法,例如 Bass 擴散模型
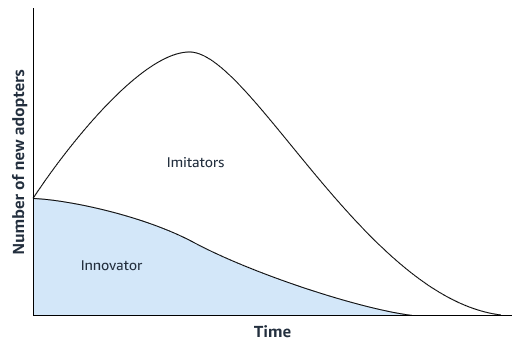
如果新產品沒有重大創新,您的組織可以使用時間序列預測模型,在與新產品最相似的產品銷售歷史記錄上運作。您可以使用 ML 型預測演算法,例如 Amazon SageMaker AI DeepAR 預測演算法,這些演算法可以使用多個類似產品的時間序列銷售資料。這非常適合冷啟動預測案例,也就是您想要產生時間序列的預測,但幾乎沒有或沒有現有歷史資料的時候。下圖顯示如何使用相關產品的時間序列資料來產生對類似新產品的預測。
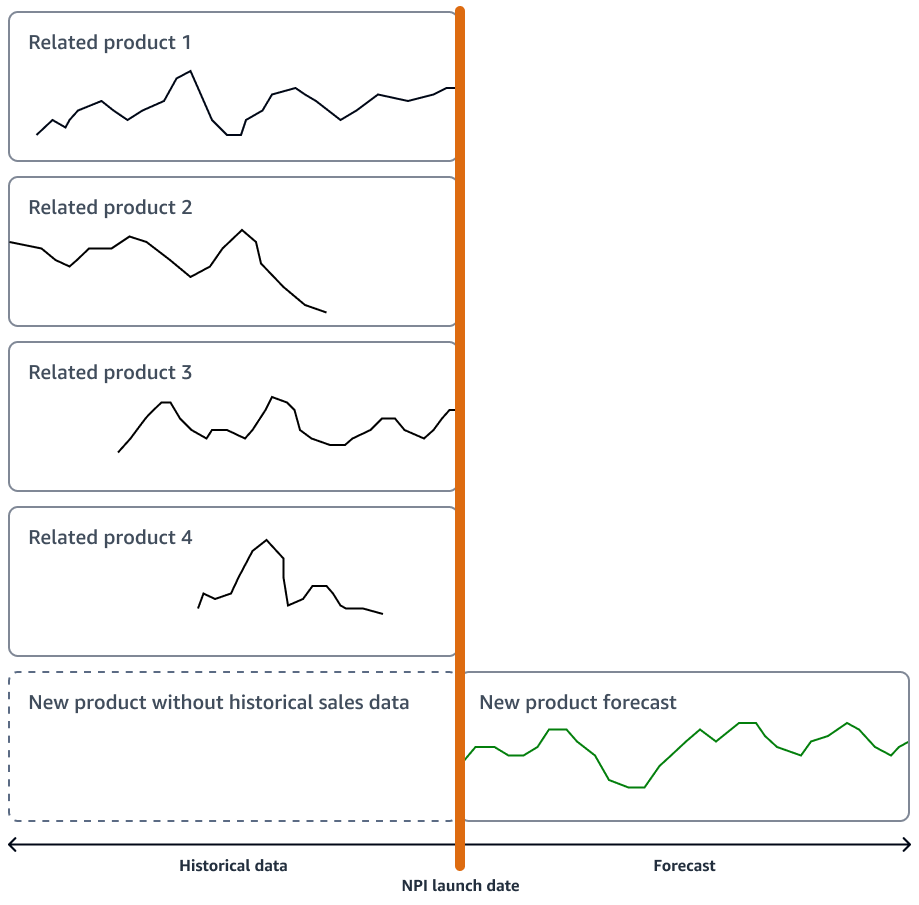
您應該考慮產生符合新產品啟動時間表的預測。提前產生預測,以允許任何邏輯校正有足夠的緩衝。
擴展和追蹤預測效果
完成NPI需求預測的概念驗證後,解決方案最終應擴展到包含其他產品和多個區域。使用人工智慧和機器學習 (AI/ML) 架構來準備資料,以及開發、部署和監控模型。
下圖示範隨著組織的NPI預測解決方案成熟,啟動和擴展策略。
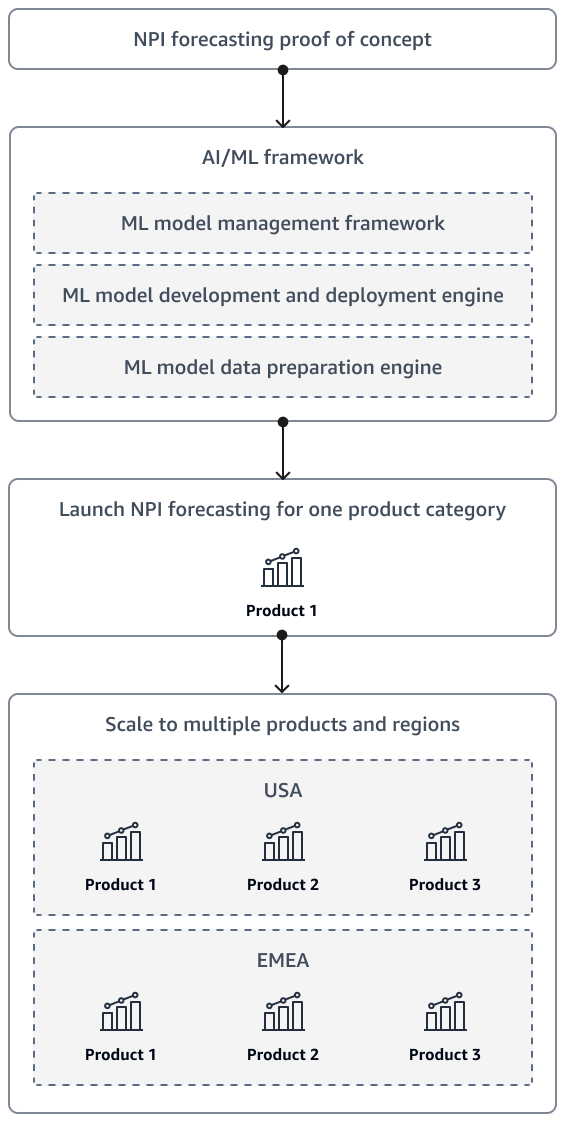
也建議您設計解決方案,讓執行人員和利益相關者可以自助預測。例如,您可以建立 Amazon QuickSight 儀表板,讓利益相關者可以隨需存取最新的預測。
密切監控預測準確性,並徹底調查偏差,以確保合理的投資回報 (ROI)。如果您使用 Amazon SageMaker AI Model Monitor 設定模型監控,您可以在模型對即時資料進行即時預測時追蹤模型的效能。您可以使用 Amazon SageMaker Model Dashboard 尋找違反您為資料品質、模型品質、偏差和可解釋性所設定閾值的模型。如需詳細資訊,請參閱《Amazon SageMaker AI 文件》中的使用控管來管理許可和追蹤模型效能。
